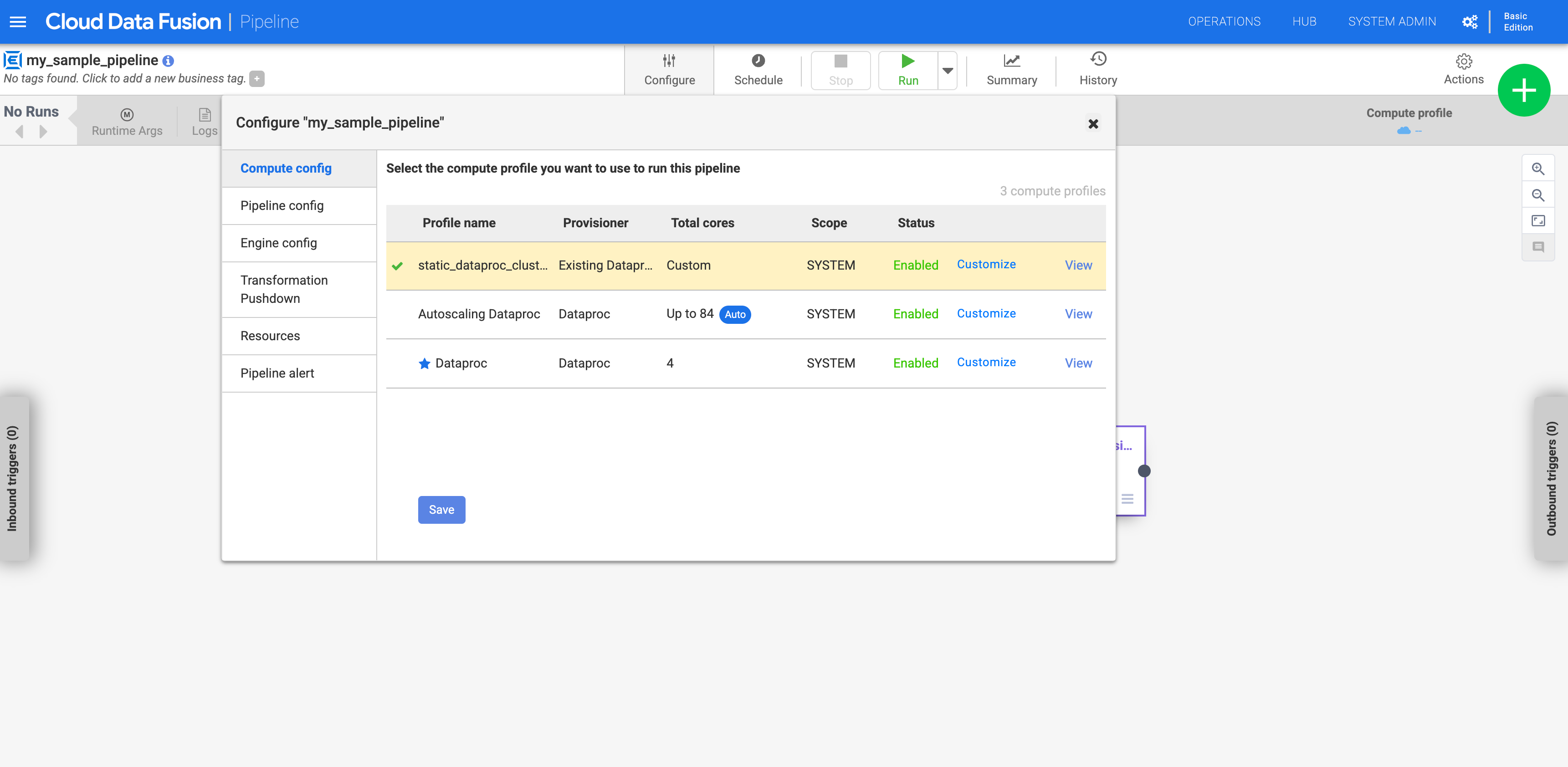
Menjalankan pipeline pada cluster Dataproc yang ada
Tetap teratur dengan koleksi
Simpan dan kategorikan konten berdasarkan preferensi Anda.
Halaman ini menjelaskan cara menjalankan pipeline di Cloud Data Fusion terhadap
cluster Dataproc yang ada.
Secara default, Cloud Data Fusion membuat cluster sementara untuk setiap pipeline:
Cloud Data Fusion membuat cluster di awal operasi pipeline, lalu menghapusnya
setelah operasi pipeline selesai. Meskipun perilaku ini menghemat biaya dengan memastikan bahwa resource hanya dibuat saat diperlukan, perilaku default ini mungkin tidak diinginkan dalam skenario berikut:
Jika waktu yang diperlukan untuk membuat cluster baru untuk setiap pipeline terlalu lama untuk kasus penggunaan Anda.
Jika organisasi Anda mewajibkan pembuatan cluster dikelola secara terpusat; misalnya, saat Anda ingin menerapkan kebijakan tertentu untuk semua cluster Dataproc.
Untuk skenario ini, Anda akan menjalankan pipeline terhadap cluster yang ada dengan
langkah-langkah berikut.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-10 UTC."],[[["\u003cp\u003eThis guide explains how to run Cloud Data Fusion pipelines against a pre-existing Dataproc cluster, instead of the default behavior of creating and deleting ephemeral clusters.\u003c/p\u003e\n"],["\u003cp\u003eUsing an existing cluster can be beneficial when cluster creation time is prohibitive or when centralized cluster management is required by the organization.\u003c/p\u003e\n"],["\u003cp\u003eTo use an existing Dataproc cluster, a Cloud Data Fusion instance and a pre-created Dataproc cluster are needed, and if running version 6.2 of Cloud Data Fusion, an older Dataproc image or an upgrade is required.\u003c/p\u003e\n"],["\u003cp\u003eConnecting to the existing cluster involves creating a new Compute Engine profile within Cloud Data Fusion and selecting the "Existing Dataproc" option, then providing the required information.\u003c/p\u003e\n"],["\u003cp\u003eAfter creating the custom profile, the pipeline must be configured in the Studio to use the custom profile, and then the pipeline will run against the designated Dataproc cluster.\u003c/p\u003e\n"]]],[],null,["# Run a pipeline against an existing Dataproc cluster\n\nThis page describes how to run a pipeline in Cloud Data Fusion against\nan existing Dataproc cluster.\n\nBy default, Cloud Data Fusion creates ephemeral clusters for each pipeline:\nit creates a cluster at the beginning of the pipeline run, and then deletes it\nafter the pipeline run completes. While this behavior saves costs by ensuring\nthat resources are only created when required, this default behavior might not\nbe desirable in the following scenarios:\n\n- If the time it takes to create a new cluster for every pipeline is\n prohibitive for your use case.\n\n- If your organization requires cluster creation to be managed centrally; for\n example, when you want to enforce certain policies for all\n Dataproc clusters.\n\nFor these scenarios, you instead run pipelines against an existing cluster with\nthe following steps.\n\nBefore you begin\n----------------\n\nYou need the following:\n\n- A Cloud Data Fusion instance.\n\n [Create a Cloud Data Fusion instance](/data-fusion/docs/how-to/create-instance)\n- An existing Dataproc cluster.\n\n [Create a Dataproc cluster](/dataproc/docs/guides/create-cluster)\n- If you run your pipelines in Cloud Data Fusion version 6.2, use an\n older [Dataproc image](/dataproc/docs/concepts/versioning/dataproc-versions)\n that runs with Hadoop 2.x (for example, 1.5-debian10), or [upgrade to the\n latest Cloud Data Fusion version](/data-fusion/docs/how-to/upgrading).\n\nConnect to the existing cluster\n-------------------------------\n\nIn Cloud Data Fusion versions 6.2.1 and later, you can connect to an\nexisting Dataproc cluster when you create a new Compute Engine\nprofile.\n\n1. Go to your instance:\n\n\n 1. In the Google Cloud console, go to the Cloud Data Fusion page.\n\n 2. To open the instance in the Cloud Data Fusion Studio,\n click **Instances** , and then click **View instance**.\n\n [Go to Instances](https://console.cloud.google.com/data-fusion/locations/-/instances)\n\n \u003cbr /\u003e\n\n2. Click **System admin**.\n\n3. Click the **Configuration** tab.\n\n4. Click\n expand_more\n **System compute profiles**.\n\n5. Click **Create new profile**. A page of provisioners opens.\n\n6. Click **Existing Dataproc**.\n\n7. Enter the profile, cluster, and monitoring information.\n\n8. Click **Create**.\n\nConfigure your pipeline to use the custom profile\n-------------------------------------------------\n\n1. Go to your instance:\n\n\n 1. In the Google Cloud console, go to the Cloud Data Fusion page.\n\n 2. To open the instance in the Cloud Data Fusion Studio,\n click **Instances** , and then click **View instance**.\n\n [Go to Instances](https://console.cloud.google.com/data-fusion/locations/-/instances)\n\n \u003cbr /\u003e\n\n2. Go to your pipeline on the **Studio** page.\n\n3. Click **Configure**.\n\n4. Click **Compute config**.\n\n5. Click the profile that you created.\n\n **Figure 1**: Click the custom profile\n6. Run the pipeline. It runs against the existing Dataproc\n cluster.\n\nWhat's next\n-----------\n\n- Learn more about [configuring clusters](/data-fusion/docs/concepts/configure-clusters).\n- Troubleshoot [deleting clusters](/data-fusion/docs/troubleshoot-deleting-clusters)."]]