Halaman ini menjelaskan cara menyiapkan pipeline data untuk membaca data dari tabel Microsoft SQL Server.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, BigQuery, Cloud Storage, and Dataproc APIs.
- Buat instance Cloud Data Fusion.
- Database SQL Server Anda harus menerima koneksi dari Cloud Data Fusion. Untuk alasan keamanan, gunakan instance Cloud Data Fusion pribadi.
Di konsol Google Cloud , buka halaman Instances Cloud Data Fusion.
Di kolom Tindakan untuk instance, klik Lihat instance untuk membuka instance di Cloud Data Fusion.
Membuka instance Cloud Data Fusion
Menyimpan sandi SQL Server Anda sebagai kunci aman
Tambahkan sandi SQL Server Anda sebagai kunci aman di instance Cloud Data Fusion.
Dari Cloud Data Fusion, klik System Admin.
Klik tab Configuration.
Klik Make HTTP Calls.

Pilih PUT.
Di kolom jalur, masukkan
namespaces/NAMESPACE_ID/securekeys/password.Di kolom Body, masukkan
{"data":"password"}. Ganti password dengan sandi SQL Server Anda.Klik Kirim.
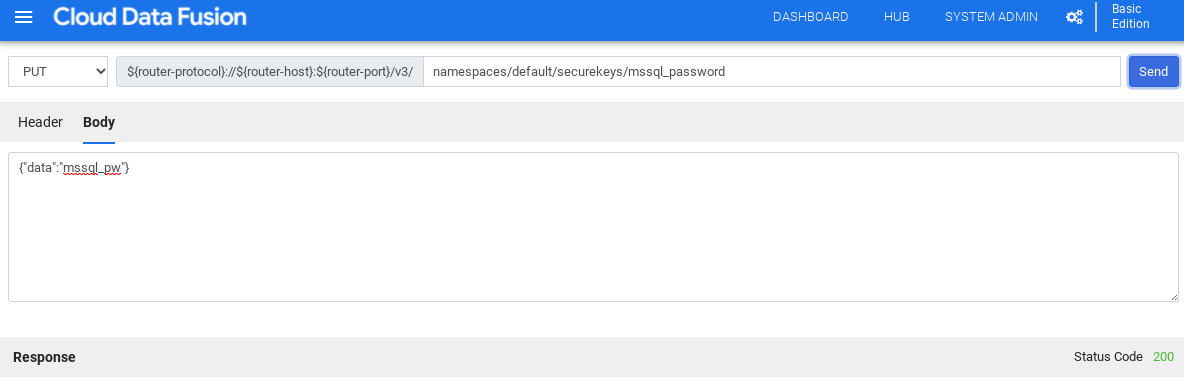
Respons harus memiliki kode status 200 untuk melanjutkan.
Mendapatkan driver JDBC untuk SQL Server
Anda bisa mendapatkan driver dari Hub atau di Pipeline Studio di Cloud Data Fusion.
Hub
Di UI Cloud Data Fusion, klik Hub.
Di kotak penelusuran, masukkan
SQL Server JDBC Driverdan pilih driver.Klik Download. Ikuti langkah-langkah download yang ditampilkan.
Klik Deploy. Upload file JAR dari langkah sebelumnya.
Klik Selesai.
Pipeline Studio
Buka Microsoft.com.
Pilih download Anda, lalu klik Download.
Di Cloud Data Fusion, klik menu Menu, lalu buka halaman Pipeline Studio.
Klik Add.
Untuk driver, klik Upload.
Pilih file JAR, yang berada di folder
jre7.Klik Berikutnya.
Untuk mengonfigurasi driver, masukkan Name dan Class name.
Klik Selesai.
Men-deploy Plugin SQL Server
Di Cloud Data Fusion, klik Hub.
Di kotak penelusuran, masukkan
SQL Server Plugins.Klik SQL server plugins.
Klik Deploy.
Klik Selesai.
Klik Buat pipeline.
Menghubungkan ke SQL Server
Anda dapat terhubung ke SQL Server dari Cloud Data Fusion di Wrangler atau Pipeline Studio.
Wrangler
Di Cloud Data Fusion, klik menu Menu, lalu buka halaman Wrangler.
Klik Tambahkan koneksi.
Jendela Tambahkan koneksi akan terbuka.
Klik SQL Server untuk memverifikasi bahwa driver telah diinstal.

Masukkan detail di kolom koneksi yang diperlukan. Di kolom Password, pilih kunci aman yang Anda simpan sebelumnya. Hal ini memastikan bahwa sandi Anda diambil menggunakan Cloud KMS.
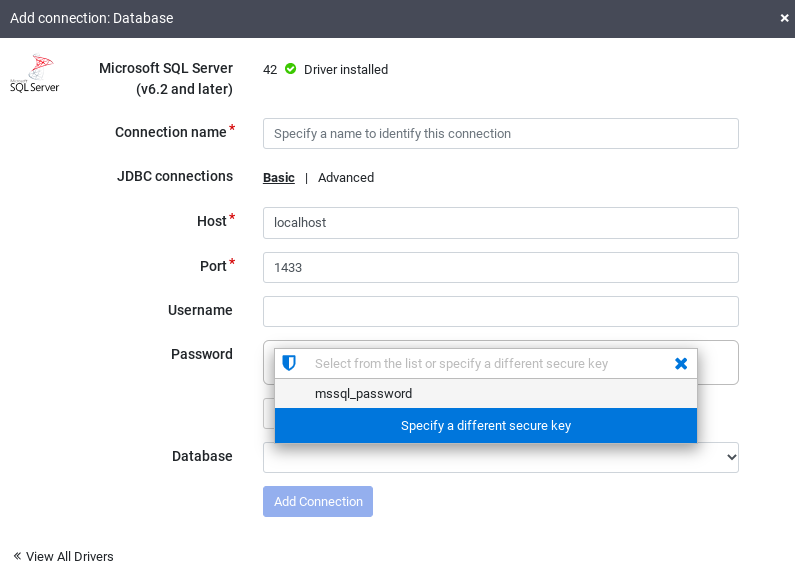
Untuk memeriksa apakah koneksi dapat dibuat dengan database, klik Uji koneksi.
Klik Tambahkan koneksi.
Setelah database SQL Server Anda terhubung dan Anda telah membuat pipeline yang membaca dari tabel SQL Server, Anda dapat menerapkan transformasi dan menulis output ke sink.
Pipeline Studio
Buka instance Cloud Data Fusion Anda dan buka halaman Pipeline Studio.
Luaskan menu Sumber, lalu klik SQL Server.

Di node SQL Server, klik Properties.
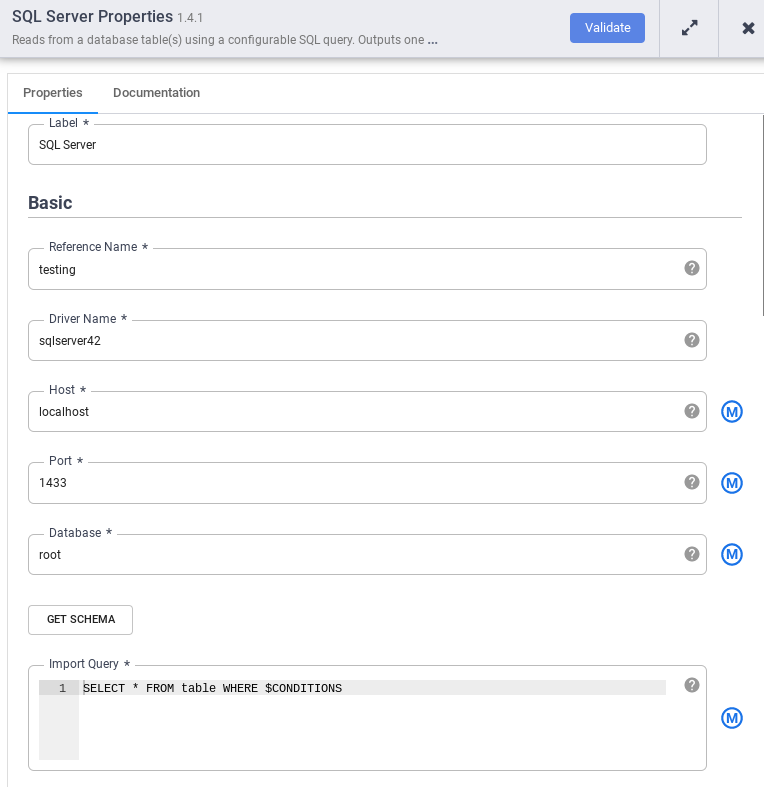
Di kolom Nama referensi, masukkan nama yang mengidentifikasi sumber SQL Server Anda.
Di kolom Database, masukkan nama database yang akan dihubungkan.
Di kolom Import query, masukkan kueri yang akan dijalankan. Contoh,
SELECT * FROM table WHERE $CONDITIONS.Klik Validasi.
Klik tutup .
Setelah database SQL Server Anda terhubung dan Anda telah membuat pipeline yang membaca dari tabel SQL Server, tambahkan transformasi yang diinginkan dan tulis output ke sink.
Langkah berikutnya
- Pelajari cara membaca data dari beberapa tabel SQL Server.
- Pelajari lebih lanjut Cloud Data Fusion.
- Ikuti salah satu tutorial.