Halaman ini menjelaskan cara menjalankan transformasi ke BigQuery, bukan Spark, di Cloud Data Fusion.
Untuk informasi selengkapnya, lihat Ringkasan Pushdown Transformasi.
Sebelum memulai
Pushdown Transformasi tersedia di versi 6.5.0 dan yang lebih baru. Jika pipeline berjalan di lingkungan sebelumnya, Anda dapat mengupgrade instance ke versi terbaru.
Mengaktifkan Pushdown Transformasi di pipeline Anda
Konsol
Untuk mengaktifkan Pushdown Transformasi pada pipeline yang di-deploy, lakukan tindakan berikut:
Buka instance Anda:
Di konsol Google Cloud , buka halaman Cloud Data Fusion.
Untuk membuka instance di Cloud Data Fusion Studio, klik Instance, lalu klik View instance.
Klik Menu > Daftar.
Tab pipeline yang di-deploy akan terbuka.
Klik pipeline yang di-deploy yang diinginkan untuk membukanya di Pipeline Studio.
Klik Konfigurasi > Pushdown Transformasi.
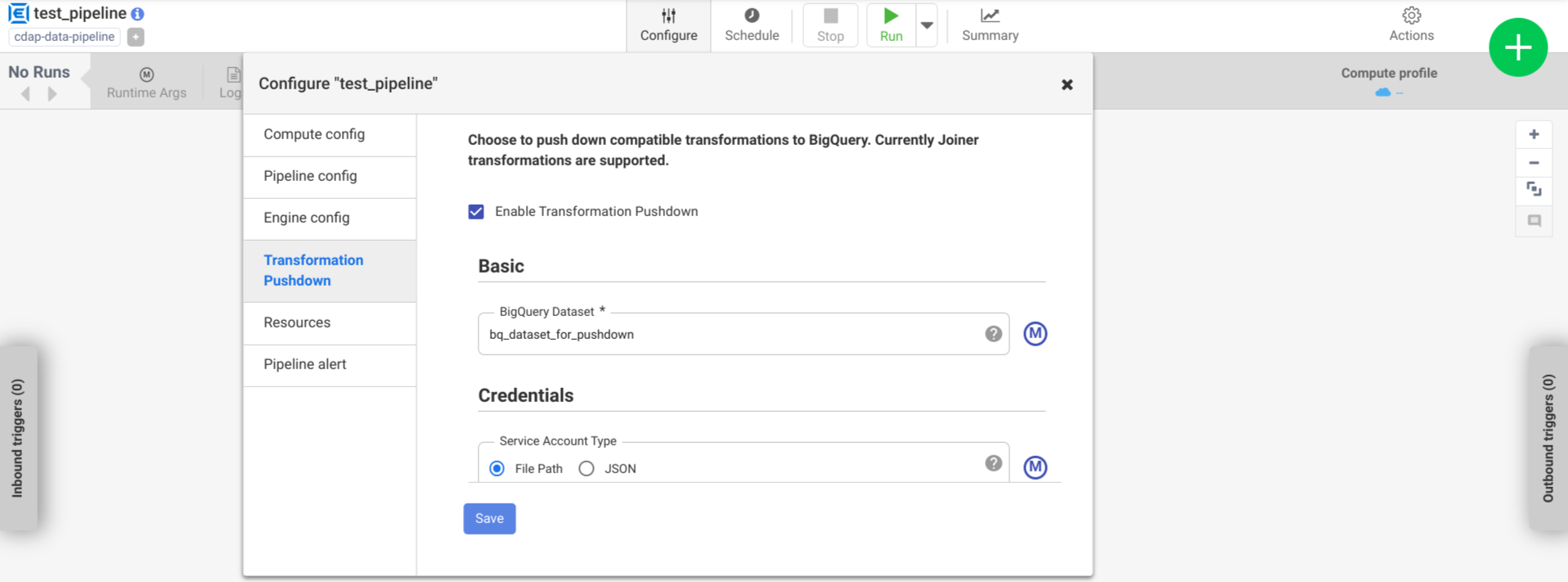
Klik Aktifkan Pushdown Transformasi.
Di kolom Dataset, masukkan nama set data BigQuery.
Opsional: Untuk menggunakan makro, klik M. Untuk mengetahui informasi selengkapnya, lihat Set data.
Opsional: Konfigurasikan opsi, jika diperlukan.
Klik Save.
Konfigurasi opsional
.| Properti | Mendukung makro | Versi Cloud Data Fusion yang didukung | Deskripsi |
|---|---|---|---|
| Menggunakan koneksi | Tidak | 6.7.0 dan yang lebih baru | Apakah akan menggunakan koneksi yang ada. |
| Koneksi | Ya | 6.7.0 dan yang lebih baru | Nama koneksi. Koneksi ini memberikan informasi project dan akun layanan. Opsional: Gunakan makro fungsi, ${conn(connection_name)}. |
| ID Project Set Data | Ya | 6.5.0 | Jika set data berada di project yang berbeda dengan tempat tugas BigQuery dijalankan, masukkan project ID set data. Jika tidak ada nilai yang diberikan, secara default, project ID tempat tugas dijalankan akan digunakan. |
| ID Project | Ya | 6.5.0 | Google Cloud Project ID. |
| Jenis Akun Layanan | Ya | 6.5.0 | Pilih salah satu opsi berikut:
|
| Jalur File Akun Layanan | Ya | 6.5.0 | Jalur di sistem file lokal ke kunci akun layanan yang digunakan
untuk otorisasi. Nilai ini ditetapkan ke auto-detect saat dijalankan
di cluster Dataproc. Saat berjalan di cluster lain, file harus ada di setiap node dalam cluster. Default-nya adalah
auto-detect. |
| JSON Akun Layanan | Ya | 6.5.0 | Konten file JSON akun layanan. |
| Nama Bucket Sementara | Ya | 6.5.0 | Bucket Cloud Storage yang menyimpan data sementara. Grup ini akan otomatis dibuat jika belum ada, tetapi tidak akan dihapus secara otomatis. Data Cloud Storage akan dihapus setelah dimuat ke BigQuery. Jika nilai ini tidak diberikan, bucket unik akan dibuat, lalu dihapus setelah operasi pipeline selesai. Akun layanan harus memiliki izin untuk membuat bucket di project yang dikonfigurasi. |
| Lokasi | Ya | 6.5.0 | Lokasi tempat set data BigQuery dibuat.
Nilai ini diabaikan jika set data atau bucket sementara sudah ada. Defaultnya adalah multi-region
US. |
| Nama Kunci Enkripsi | Ya | 6.5.1/0.18.1 | kunci enkripsi yang dikelola pelanggan (CMEK) yang mengenkripsi data yang ditulis ke bucket, set data, atau tabel apa pun yang dibuat oleh plugin. Jika bucket, set data, atau tabel sudah ada, nilai ini akan diabaikan. |
| Mempertahankan Tabel BigQuery setelah Selesai | Ya | 6.5.0 | Apakah akan mempertahankan semua tabel sementara BigQuery yang dibuat selama pipeline dijalankan untuk tujuan proses debug dan validasi. Setelan default-nya adalah Tidak. |
| TTL Tabel Sementara (dalam jam) | Ya | 6.5.0 | Menetapkan TTL tabel untuk tabel sementara BigQuery, dalam
jam. Hal ini berguna sebagai failsafe jika pipeline dibatalkan dan proses pembersihan terganggu (misalnya, jika cluster eksekusi dimatikan secara tiba-tiba). Menetapkan nilai ini ke 0 akan menonaktifkan TTL tabel. Defaultnya adalah
72 (3 hari). |
| Prioritas Tugas | Ya | 6.5.0 | Prioritas yang digunakan untuk menjalankan tugas BigQuery. Pilih
salah satu opsi berikut:
|
| Tahapan untuk memaksa pushdown | Ya | 6.7.0 | Tahap yang didukung untuk selalu dieksekusi di BigQuery. Setiap nama tahap harus berada di baris terpisah. |
| Tahapan untuk melewati pushdown | Ya | 6.7.0 | Tahap yang didukung agar tidak pernah dieksekusi di BigQuery. Setiap nama tahap harus berada di baris terpisah. |
| Menggunakan BigQuery Storage Read API | Ya | 6.7.0 | Apakah akan menggunakan BigQuery Storage Read API saat mengekstrak data dari BigQuery selama eksekusi pipeline. Opsi ini dapat meningkatkan performa Pushdown Transformasi, tetapi menimbulkan biaya tambahan. Hal ini mengharuskan Scala 2.12 diinstal di lingkungan eksekusi. |
Memantau perubahan performa dalam log
Log runtime pipeline menyertakan pesan yang menampilkan kueri SQL yang berjalan di BigQuery. Anda dapat memantau tahap mana dalam pipeline yang didorong ke BigQuery.
Contoh berikut menunjukkan entri log saat eksekusi pipeline dimulai. Log menunjukkan bahwa operasi JOIN di pipeline Anda telah didorong ke BigQuery untuk dieksekusi:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
Contoh berikut menunjukkan nama tabel yang akan ditetapkan untuk setiap set data yang terlibat dalam eksekusi pushdown:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
Saat eksekusi berlanjut, log akan menampilkan penyelesaian tahap push, dan
akhirnya eksekusi operasi JOIN. Contoh:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
Setelah semua tahap selesai, pesan akan menunjukkan bahwa operasi Pull telah
selesai. Hal ini menunjukkan bahwa proses ekspor BigQuery telah dipicu dan kumpulan data akan mulai dibaca ke dalam pipeline setelah tugas ekspor ini dimulai. Contoh:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
Jika eksekusi pipeline mengalami error, error tersebut akan dijelaskan dalam log.
Untuk mengetahui detail tentang eksekusi operasi JOIN BigQuery, seperti penggunaan resource, waktu eksekusi, dan penyebab error, Anda dapat melihat data Tugas BigQuery menggunakan ID Tugas, yang muncul dalam log tugas.
Meninjau metrik pipeline
Untuk informasi selengkapnya tentang metrik yang disediakan Cloud Data Fusion untuk bagian pipeline yang dieksekusi di BigQuery, lihat Metrik pipeline pushdown BigQuery.
Langkah selanjutnya
- Pelajari Pushdown Transformasi di Cloud Data Fusion lebih lanjut.