Nesta página, descrevemos como mudar a versão da imagem do Dataproc usada pela sua instância do Cloud Data Fusion. É possível mudar a imagem no nível da instância, do namespace ou do pipeline.
Antes de começar
Interrompa todos os pipelines em tempo real e jobs de replicação na instância do Cloud Data Fusion. Se um pipeline ou uma replicação em tempo real estiver em execução quando você mudar a versão da imagem do Dataproc, as mudanças não serão aplicadas à execução do pipeline.
Para pipelines em tempo real, se houver checkpoints ativos, interromper os pipelines não causa perda de dados. Para jobs de replicação, interromper e iniciar o job não causa perda de dados se os registros de banco de dados estiverem disponíveis.
Console
Acesse a página Instâncias do Cloud Data Fusion e abra a instância em que você precisa interromper um pipeline.
Abra cada pipeline em tempo real no Pipeline Studio e clique em Parar.
Abra cada job de replicação na página Replicar e clique em Parar.
API REST
Para recuperar todos os pipelines, use a seguinte chamada da API REST:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps"Substitua
NAMESPACE_IDpelo nome do namespace.Para interromper um pipeline em tempo real, use a seguinte chamada da API REST:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/PIPELINE_NAME/spark/DataStreamsSparkStreaming/stop"Substitua NAMESPACE_ID pelo nome do namespace e PIPELINE_NAME pelo nome do pipeline em tempo real.
Para interromper um job de replicação, use a seguinte chamada da API REST:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/REPLICATION_JOB_NAME/workers/DeltaWorker/stop"Substitua NAMESPACE_ID pelo nome do namespace e REPLICATION_JOB_NAME pelo nome do job de replicação.
Para mais informações, consulte como interromper pipelines em tempo real e como interromper jobs de replicação.
Verificar e substituir a versão padrão do Dataproc no Cloud Data Fusion
Clique em Administrador do sistema > Configuração > Preferências do sistema.
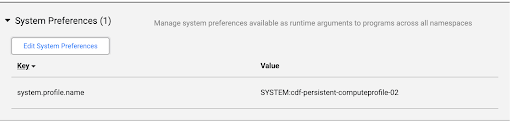
Se uma imagem do Dataproc não for especificada nas Preferências do Sistema ou se você quiser mudar a preferência, clique em Editar preferências do sistema.
Insira o seguinte texto no campo Chave:
system.profile.properties.imageVersionInsira a imagem do Dataproc escolhida no campo "Valor", como
2.1.Clique em Salvar e fechar.
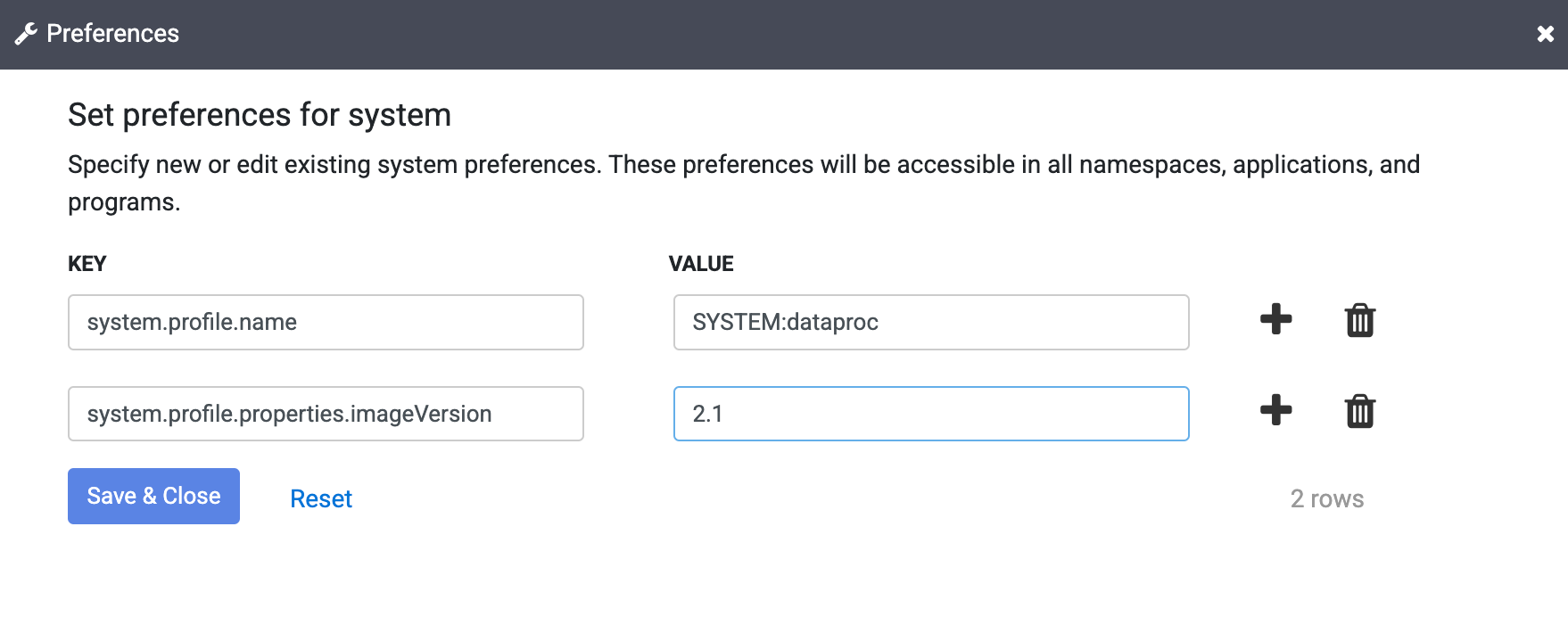
Essa mudança afeta toda a instância do Cloud Data Fusion, incluindo todos os namespaces e execuções de pipeline, a menos que a propriedade da versão da imagem seja substituída em um namespace, pipeline ou argumento de ambiente de execução na sua instância.
Mudar a versão da imagem do Dataproc
A versão da imagem pode ser definida na interface da Web do Cloud Data Fusion em Configurações de computação, Preferências de namespace ou Argumentos de execução de pipeline.
Mudar a imagem em "Preferências de namespace"
Se você tiver substituído a versão da imagem nas propriedades do namespace, siga estas etapas:
Clique em Administrador do sistema > Configuração > Namespaces.
Abra cada namespace e clique em Preferências.
Verifique se não há substituição com a chave
system.profile.properties.imageVersione um valor de versão da imagem incorreto.Clique em Concluir.
Mudar a imagem em "Perfis de computação do sistema"
Clique em Administrador do sistema > Configuração.
Clique em Sistema Perfis de computação > Criar novo perfil.
Selecione o provisionador Dataproc.
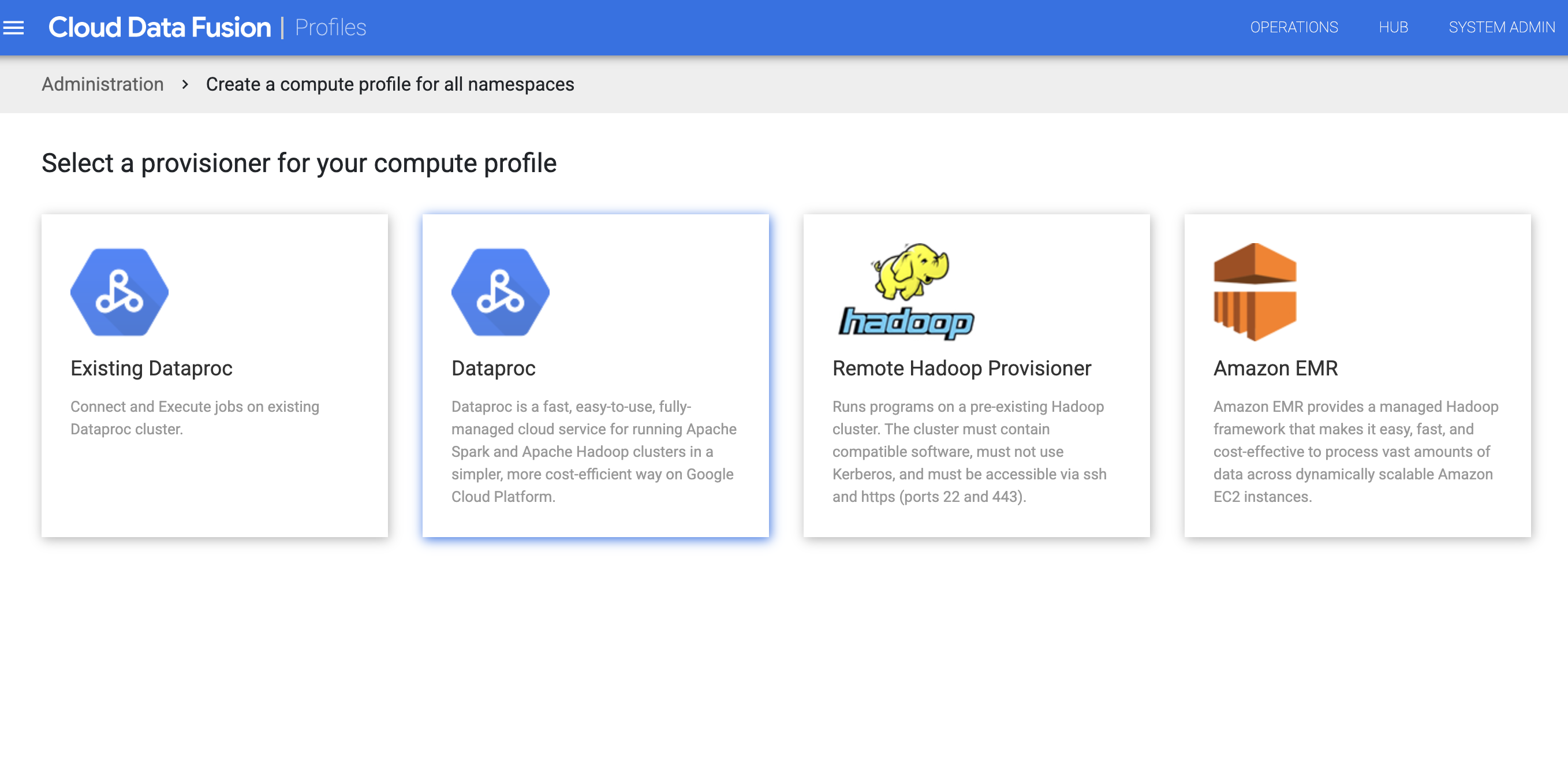
Crie o perfil para o Dataproc. No campo Versão da imagem, insira uma versão de imagem do Dataproc.
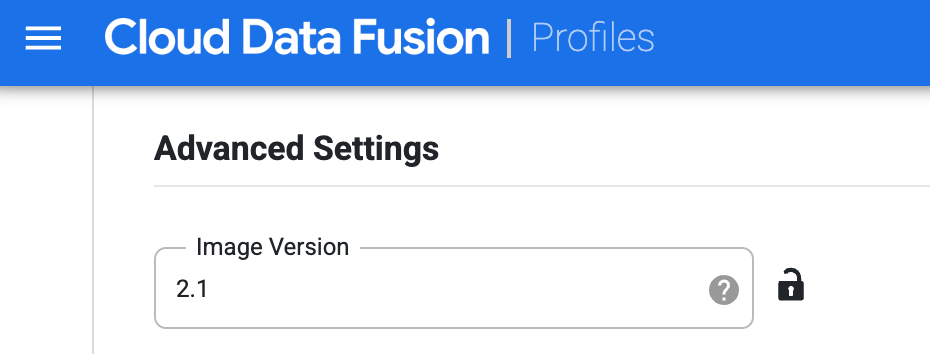
Selecione esse perfil de computação ao executar o pipeline na página do Studio. Na página de execução do pipeline, clique em Configurar > Configuração de computação e selecione esse perfil.
Selecione o perfil do Dataproc e clique em Salvar.
Clique em Concluir.
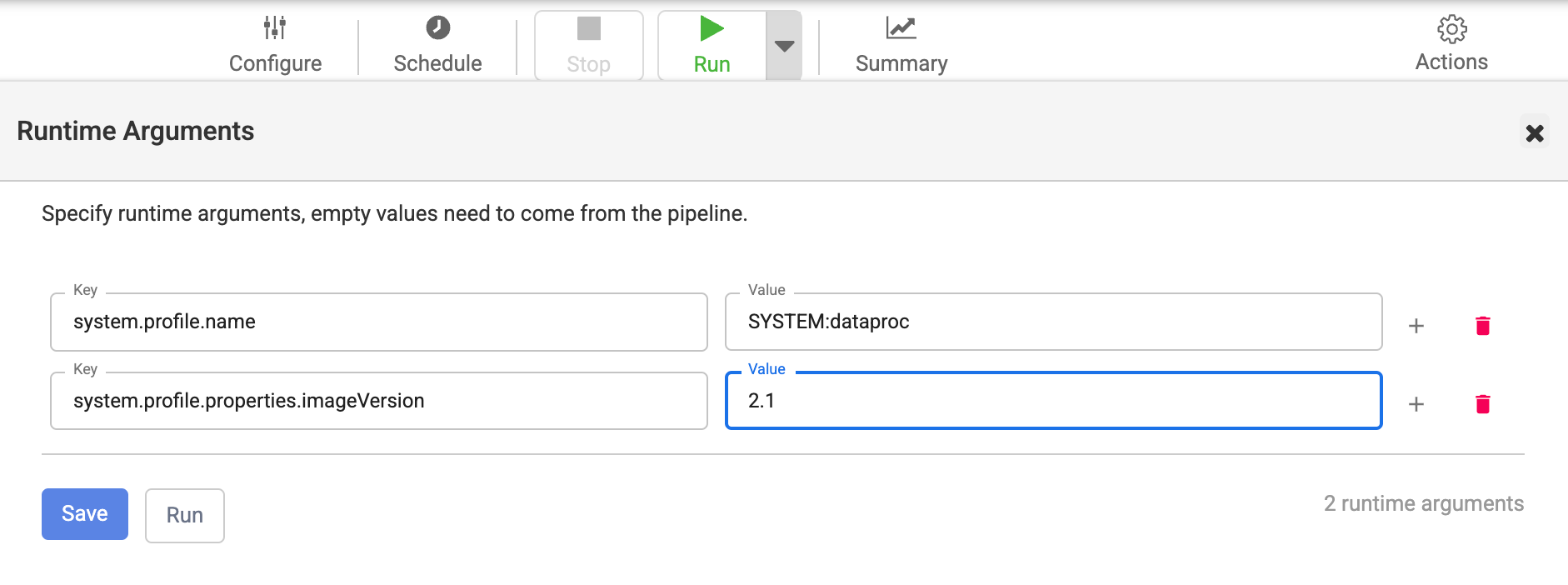
Mudar a imagem em "Argumentos de execução do pipeline"
Se você substituiu a versão da imagem por uma propriedade nos argumentos de tempo de execução do pipeline, siga estas etapas:
Clique no menu Menu > Lista.
Na página Lista, selecione o pipeline que você quer atualizar.
O pipeline é aberto na página do Studio.
Para expandir as opções de Executar, clique na seta de expansão .
A janela Argumentos de execução é aberta.
Verifique se não há substituição com a chave
system.profile.properties.imageVersioncom uma versão de imagem incorreta como valor.Clique em Salvar.
Recrie os clusters estáticos do Dataproc usados pelo Cloud Data Fusion com a versão da imagem escolhida
Se você usa clusters do Dataproc com o Cloud Data Fusion, siga o guia do Dataproc para recriar os clusters com a versão da imagem do Dataproc escolhida para sua versão do Cloud Data Fusion.
Também é possível criar um cluster do Dataproc com a versão da imagem escolhida e excluir e recriar o perfil de computação no Cloud Data Fusion com o mesmo nome e o nome atualizado do cluster do Dataproc. Assim, a execução de pipelines em lote pode ser concluída no cluster atual, e as execuções de pipeline subsequentes ocorrem no novo cluster do Dataproc. Você pode excluir o cluster antigo do Dataproc depois de confirmar que todas as execuções de pipeline foram concluídas.
Verificar se a versão da imagem do Dataproc está atualizada
Console
No Google Cloud console, acesse a página Clusters do Dataproc.
Abra a página Detalhes do cluster do novo cluster que o Cloud Data Fusion criou quando você especificou a nova versão.
O campo Versão da imagem tem o novo valor especificado no Cloud Data Fusion.
API REST
Receba a lista de clusters com os metadados:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION_ID/clustersSubstitua:
PROJECT_IDpelo nome do namespaceREGION_IDpelo nome da região em que os clusters estão localizados.
Pesquise o nome do pipeline (nome do cluster).
Abaixo desse objeto JSON, confira a imagem em
config > softwareConfig > imageVersion.
Mudar a imagem do Dataproc para a versão 2.1 ou mais recente
As versões 6.9.1 e mais recentes do Cloud Data Fusion são compatíveis com a imagem 2.1 do Dataproc no Compute Engine, que é executada em Java 11. Nas versões 6.10.0 e mais recentes, a imagem 2.1 é a padrão.
Se você mudar para a imagem 2.1 ou mais recente de uma imagem anterior, os drivers JDBC usados pelos plug-ins de banco de dados nessas instâncias precisarão ser compatíveis com o Java 11 para que os jobs de replicação e os pipelines em lote sejam concluídos.
As imagens 2.2 e 2.1 do Dataproc têm as seguintes limitações no Cloud Data Fusion:
- Jobs do MapReduce não são compatíveis.
- As versões do driver JDBC usadas nos plug-ins de banco de dados na sua instância precisam ser atualizadas para ter suporte ao Java 11. Consulte a tabela a seguir para ver as versões de driver que funcionam com o Dataproc 2.2, 2.1 e Java 11:
| Drivers JDBC | Versões anteriores removidas do Cloud Data Fusion 6.9.1 | Versões compatíveis com Java 8 e Java 11 que funcionam com Dataproc 2.2, 2.1 ou 2.0 |
|---|---|---|
| Driver JDBC do Cloud SQL para MySQL | - | 1.0.16 |
| Driver JDBC do Cloud SQL para PostgreSQL | - | 1.0.16 |
| Driver JDBC do Microsoft SQL Server | Driver JDBC 6.0 da Microsoft | Driver JDBC 9.4 da Microsoft |
| Driver JDBC do MySQL | 5.0.8, 5.1.39 | 8.0.25 |
| Driver JDBC do PostgreSQL | 9.4.1211.jre7, 9.4.1211.jre8 | 42.6.0.jre8 |
| Driver JDBC da Oracle | ojdbc7 | ojdbc8 (12c e versões mais recentes) |
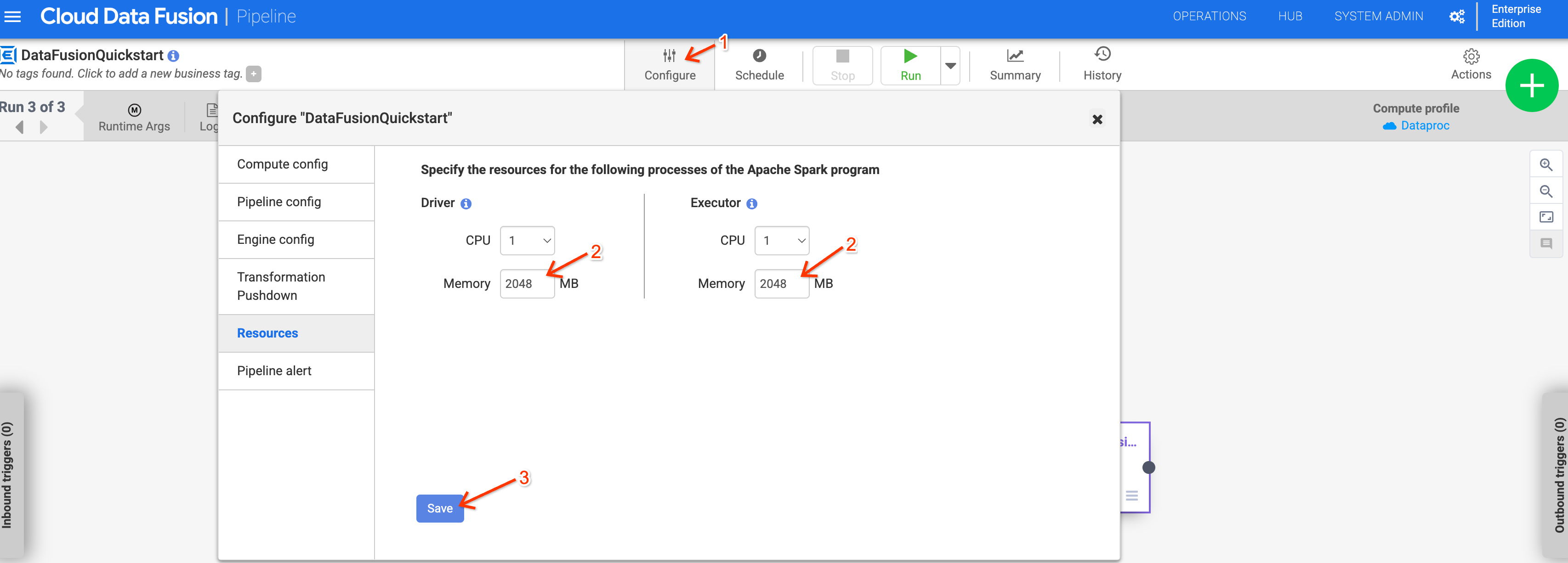
Uso de memória ao usar o Dataproc 2.1 ou versões mais recentes
O uso de memória pode aumentar para pipelines que usam o Dataproc 2.1
ou versões mais recentes. Se você fizer upgrade da instância para a versão 6.10 ou mais recente e os pipelines anteriores falharem devido a problemas de memória, aumente a memória do driver e do executor para 2.048 MB na configuração Resources do pipeline.
Como alternativa, é possível substituir a versão do Dataproc definindo
o argumento de ambiente de execução system.profile.properties.imageVersion como 2.0-debian10.