本頁說明如何變更 Cloud Data Fusion 執行個體使用的 Dataproc 映像檔版本。您可以在執行個體、命名空間或管道層級變更圖片。
事前準備
停止 Cloud Data Fusion 執行個體中的所有即時管道和複寫工作。如果您變更 Dataproc 映像檔版本時,有即時管道或複製作業正在執行,系統不會將變更套用至管道執行作業。
如果是即時管道,啟用檢查點功能後,停止管道不會造成任何資料遺失。如果是複製工作,只要資料庫記錄可用,停止及啟動複製工作就不會導致資料遺失。
控制台
前往 Cloud Data Fusion 的「Instances」(執行個體) 頁面,然後開啟需要停止管道的執行個體。
在 Pipeline Studio 中開啟每個即時管道,然後按一下「停止」。
在「Replicate」(複製) 頁面開啟每個複製作業,然後按一下「Stop」(停止)。
REST API
如要擷取所有管道,請使用下列 REST API 呼叫:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps"將
NAMESPACE_ID替換成命名空間名稱。如要停止即時管道,請使用下列 REST API 呼叫:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/PIPELINE_NAME/spark/DataStreamsSparkStreaming/stop"將 NAMESPACE_ID 替換為命名空間名稱,並將 PIPELINE_NAME 替換為即時管道名稱。
如要停止複製作業,請使用下列 REST API 呼叫:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/REPLICATION_JOB_NAME/workers/DeltaWorker/stop"將 NAMESPACE_ID 替換為您的命名空間名稱,並將 REPLICATION_JOB_NAME 替換為複寫作業的名稱。
在 Cloud Data Fusion 中檢查及覆寫 Dataproc 的預設版本
依序點選「系統管理」>「設定」>「系統偏好設定」。
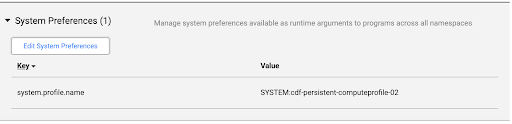
如未在「系統偏好設定」中指定 Dataproc 映像檔,或要變更偏好設定,請按一下「編輯系統偏好設定」。
在「Key」欄位中輸入下列文字:
system.profile.properties.imageVersion在「Value」欄位中輸入所選 Dataproc 映像檔,例如
2.1。按一下「Save & Close」。
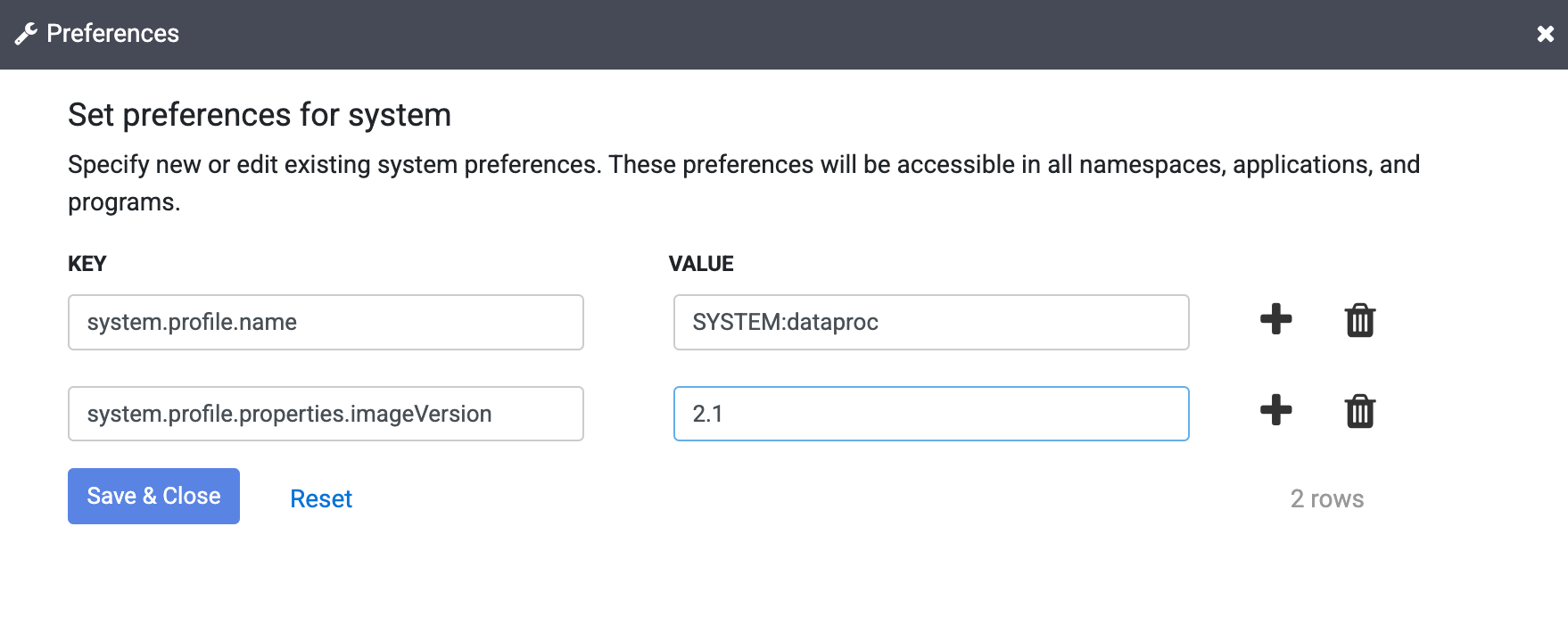
這項變更會影響整個 Cloud Data Fusion 執行個體,包括所有命名空間和管道執行作業,除非您在執行個體的命名空間、管道或執行階段引數中覆寫映像檔版本屬性。
變更 Dataproc 映像檔版本
您可以在 Cloud Data Fusion 網頁介面的「Compute Configurations」、「Namespace Preferences」或「Pipeline Runtime Arguments」中設定映像檔版本。
在命名空間偏好設定中變更圖片
如果您已在命名空間屬性中覆寫圖片版本,請按照下列步驟操作:
依序點選「系統管理員」>「設定」>「命名空間」。
開啟每個命名空間,然後按一下「偏好設定」。
確認沒有以鍵
system.profile.properties.imageVersion覆寫,且圖片版本值不正確。按一下「完成」。
變更系統運算設定檔中的圖片
依序點選「系統管理」>「設定」。
依序點選「系統」>「運算設定檔」>「建立新設定檔」。
選取 Dataproc 供應商。
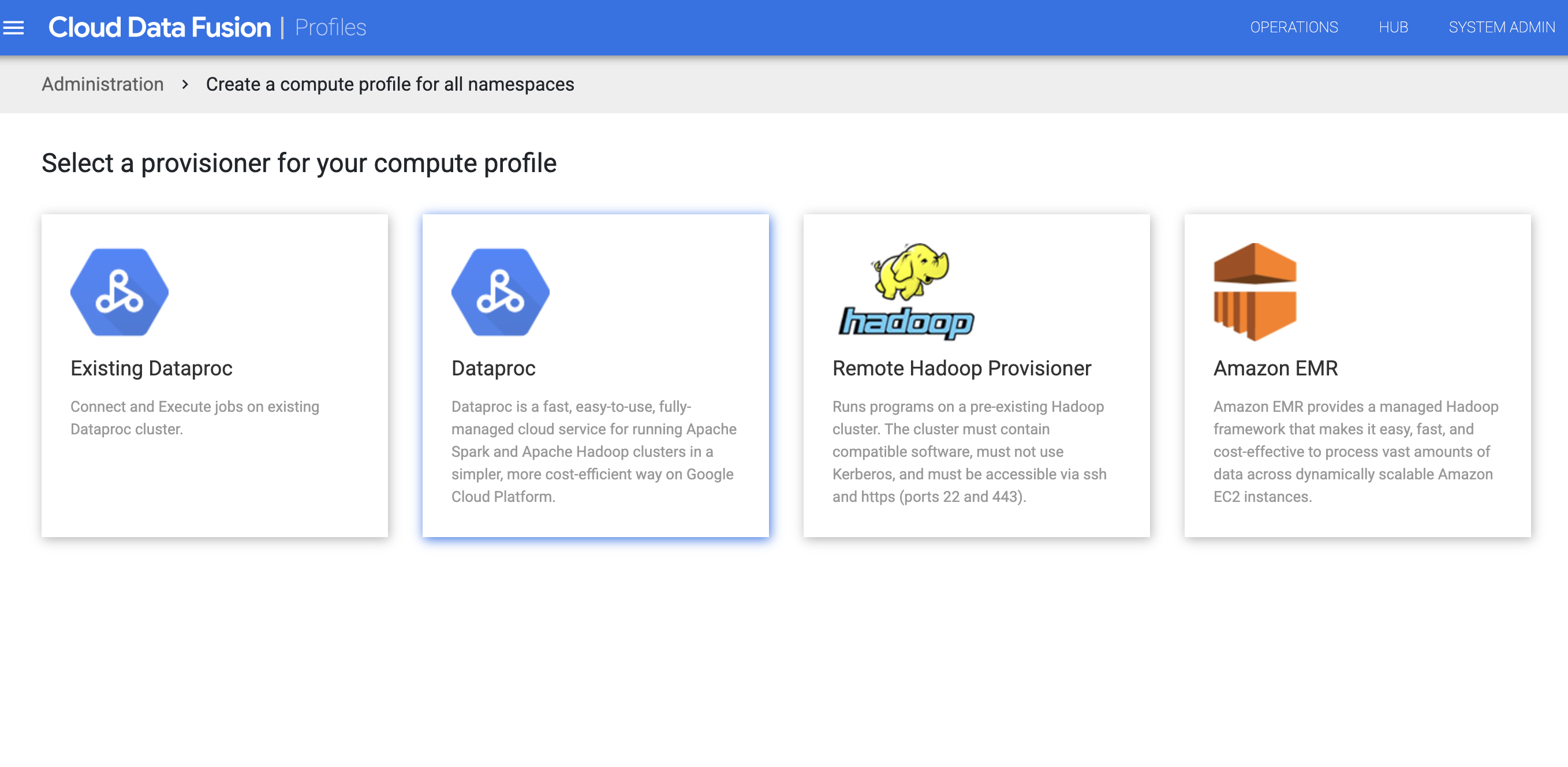
為 Dataproc 建立設定檔。在「映像檔版本」欄位中,輸入 Dataproc 映像檔版本。
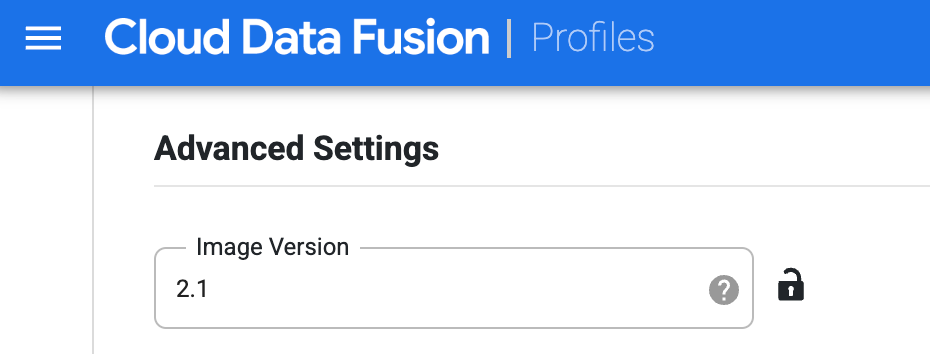
在 Studio 頁面執行管道時,請選取這個運算設定檔。在管道執行頁面中,依序點選「設定」>「運算設定」,然後選取這個設定檔。
選取 Dataproc 設定檔,然後按一下「儲存」。
按一下「完成」。
變更 Pipeline 執行階段引數中的映像檔
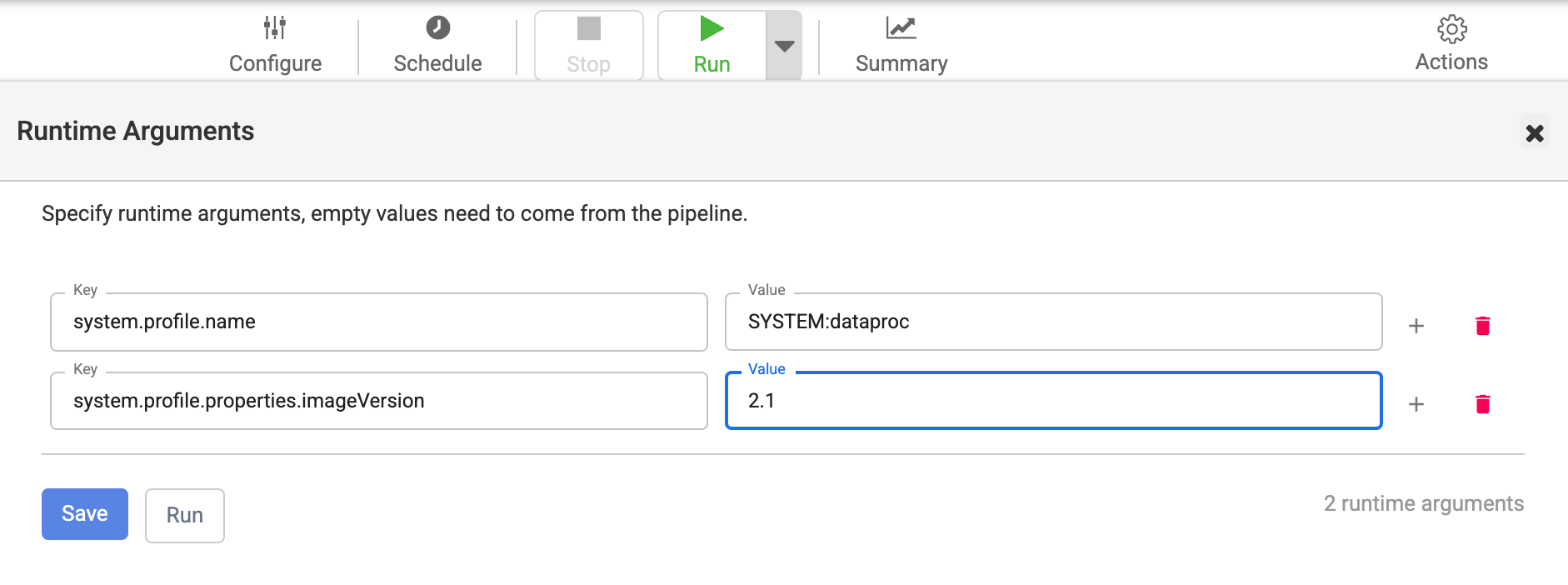
如果您已使用管道的 Runtime Arguments 中的屬性覆寫圖片版本,請按照下列步驟操作:
依序按一下「選單」 「選單」>「清單」。
在「清單」頁面中,選取要更新的管道。
管道會在「Studio」(工作室) 頁面中開啟。
如要展開「執行」選項,請按一下 展開箭頭。
「Runtime Arguments」視窗隨即開啟。
確認沒有以錯誤的圖片版本做為值,覆寫
system.profile.properties.imageVersion鍵。按一下 [儲存]。
使用所選映像檔版本,重新建立 Cloud Data Fusion 使用的靜態 Dataproc 叢集
如果您搭配 Cloud Data Fusion 使用現有 Dataproc 叢集,請按照 Dataproc 指南操作,使用適用於 Cloud Data Fusion 版本的 Dataproc 映像檔版本,重新建立叢集。
或者,您也可以使用所選的 Dataproc 映像檔版本建立新的 Dataproc 叢集,然後刪除並重新建立 Cloud Data Fusion 中的運算設定檔,使用相同的運算設定檔名稱和更新後的 Dataproc 叢集名稱。這樣一來,批次管道就能在現有叢集上完成執行作業,後續的管道執行作業則會在新的 Dataproc 叢集上進行。確認所有管道執行作業都已完成後,即可刪除舊的 Dataproc 叢集。
確認 Dataproc 映像檔版本已更新
控制台
前往 Google Cloud 控制台的 Dataproc「Clusters」(叢集) 頁面。
開啟 Cloud Data Fusion 在您指定新版本時建立的新叢集「叢集詳細資料」頁面。
「映像檔版本」欄位會顯示您在 Cloud Data Fusion 中指定的新值。
REST API
取得叢集清單和中繼資料:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION_ID/clusters更改下列內容:
PROJECT_ID改為您的命名空間名稱REGION_ID:叢集所在的區域名稱
搜尋管道名稱 (叢集名稱)。
在該 JSON 物件下方,查看
config > softwareConfig > imageVersion中的圖片。
將 Dataproc 映像檔變更為 2.1 以上版本
Cloud Data Fusion 6.9.1 以上版本支援 Dataproc 映像檔 2.1 Compute Engine,該引擎在 Java 11 中執行。在 6.10.0 以上版本中,預設為 2.1 版。
如果從舊版映像檔改用 2.1 以上版本的映像檔,資料庫外掛程式在這些執行個體中使用的 JDBC 驅動程式必須與 Java 11 相容,批次管道和複製作業才能成功。
在 Cloud Data Fusion 中,Dataproc 映像檔 2.2 和 2.1 有下列限制:
- 不支援 MapReduce 工作。
- 您執行個體中資料庫外掛程式使用的 JDBC 驅動程式版本必須更新,才能支援 Java 11。下表列出適用於 Dataproc 2.2、2.1 和 Java 11 的驅動程式版本:
| JDBC 驅動程式 | Cloud Data Fusion 6.9.1 移除的舊版 | 支援 Java 8 和 Java 11 的版本,可與 Dataproc 2.2、2.1 或 2.0 搭配使用 |
|---|---|---|
| MySQL 適用的 Cloud SQL JDBC 驅動程式 | - | 1.0.16 |
| PostgreSQL 適用的 Cloud SQL JDBC 驅動程式 | - | 1.0.16 |
| Microsoft SQL Server JDBC 驅動程式 | Microsoft JDBC 驅動程式 6.0 | Microsoft JDBC 驅動程式 9.4 |
| MySQL JDBC 驅動程式 | 5.0.8、5.1.39 | 8.0.25 |
| PostgreSQL JDBC 驅動程式 | 9.4.1211.jre7、9.4.1211.jre8 | 42.6.0.jre8 |
| Oracle JDBC 驅動程式 | ojdbc7 | ojdbc8 (12c 以上版本) |
使用 Dataproc 2.1 以上版本時的記憶體用量
如果管道使用 Dataproc 2.1 以上版本,記憶體用量可能會增加。如果將執行個體升級至 6.10 以上版本,且先前的管道因記憶體問題而失敗,請在管道的 Resources 設定中,將驅動程式和執行器記憶體增加至 2048 MB。
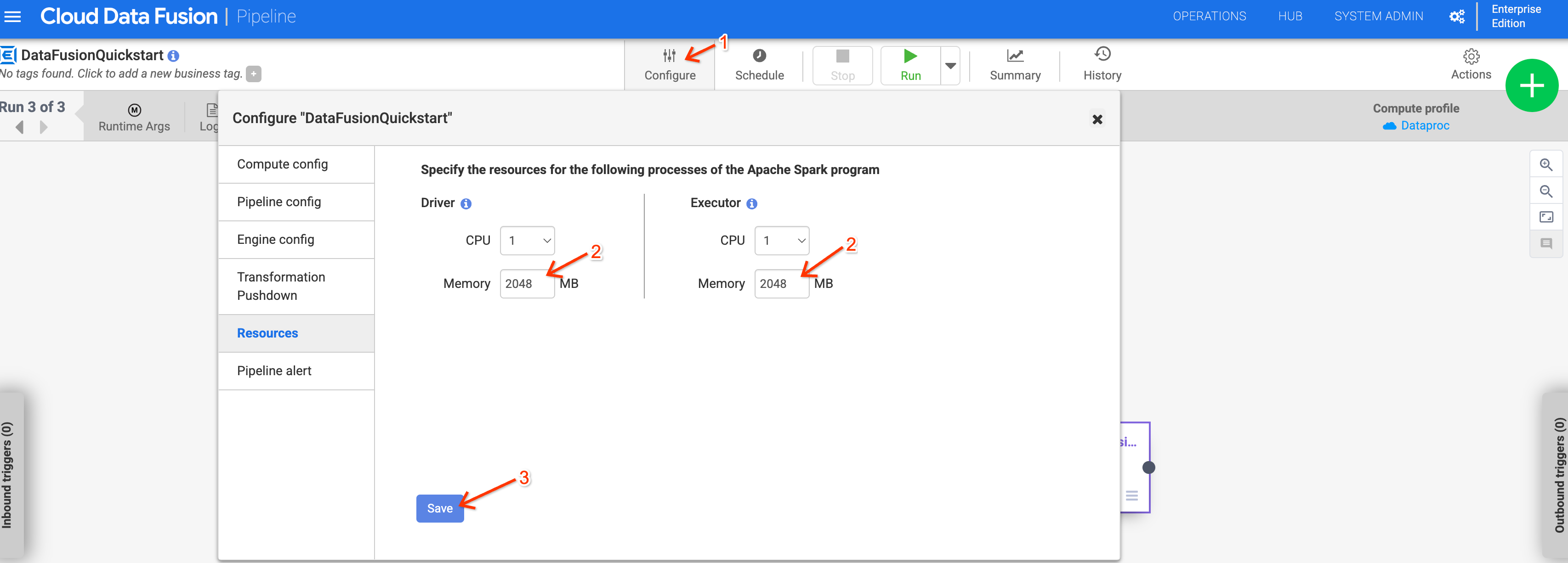
或者,您也可以將 system.profile.properties.imageVersion 執行階段引數設為 2.0-debian10,藉此覆寫 Dataproc 版本。