Esta página descreve como alterar a versão da imagem do Dataproc usada pela sua instância do Cloud Data Fusion. Pode alterar a imagem ao nível da instância, do espaço de nomes ou do pipeline.
Antes de começar
Pare todos os pipelines em tempo real e tarefas de replicação na instância do Cloud Data Fusion. Se uma pipeline ou uma replicação em tempo real estiver em execução quando alterar a versão da imagem do Dataproc, as alterações não são aplicadas à execução da pipeline.
Para pipelines em tempo real, se a criação de pontos de verificação estiver ativada, a paragem dos pipelines não causa perda de dados. Para tarefas de replicação, desde que os registos da base de dados estejam disponíveis, a paragem e o início da tarefa de replicação não causam perda de dados.
Consola
Aceda à página Instances do Cloud Data Fusion e abra a instância onde tem de parar um pipeline.
Abra cada pipeline em tempo real no Pipeline Studio e clique em Parar.
Abra cada tarefa de replicação na página Replicar e clique em Parar.
API REST
Para obter todas as pipelines, use a seguinte chamada da API REST:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps"Substitua
NAMESPACE_IDpelo nome do seu espaço de nomes.Para parar um pipeline em tempo real, use a seguinte chamada da API REST:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/PIPELINE_NAME/spark/DataStreamsSparkStreaming/stop"Substitua NAMESPACE_ID pelo nome do seu espaço de nomes e PIPELINE_NAME pelo nome do pipeline em tempo real.
Para parar uma tarefa de replicação, use a seguinte chamada da API REST:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/REPLICATION_JOB_NAME/workers/DeltaWorker/stop"Substitua NAMESPACE_ID pelo nome do seu espaço de nomes e REPLICATION_JOB_NAME pelo nome da tarefa de replicação.
Para mais informações, consulte os artigos sobre como parar pipelines em tempo real e parar tarefas de replicação.
Verifique e substitua a versão predefinida do Dataproc no Cloud Data Fusion
Clique em Administrador do sistema > Configuração > Preferências do sistema.
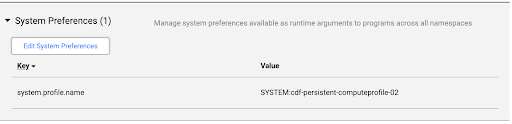
Se não for especificada uma imagem do Dataproc nas Preferências do sistema, ou para alterar a preferência, clique em Editar Preferências do sistema.
Introduza o seguinte texto no campo Chave:
system.profile.properties.imageVersionIntroduza a imagem do Dataproc escolhida no campo Valor, como
2.1.Clique em Guardar e fechar.
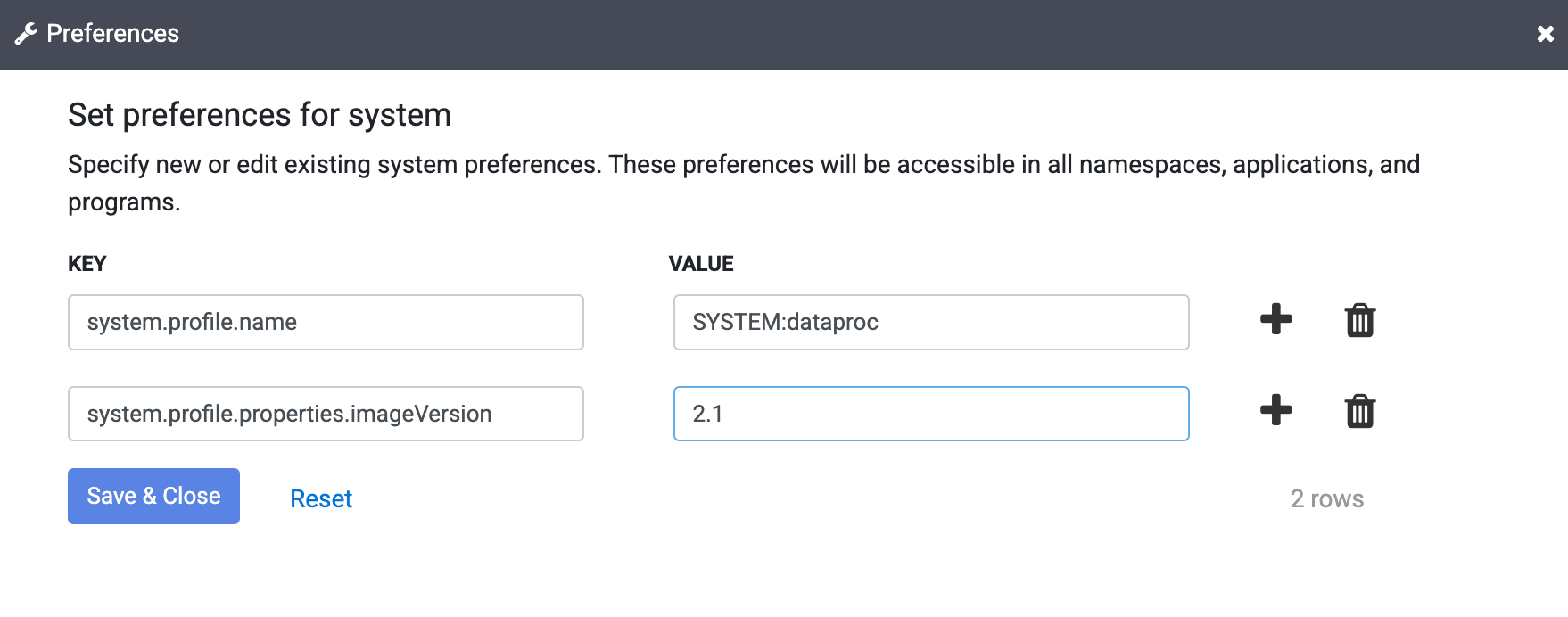
Esta alteração afeta toda a instância do Cloud Data Fusion, incluindo todos os respetivos espaços de nomes e execuções de pipelines, a menos que a propriedade da versão da imagem seja substituída num espaço de nomes, num pipeline ou num argumento de tempo de execução na sua instância.
Altere a versão da imagem do Dataproc
A versão da imagem pode ser definida na interface Web do Cloud Data Fusion nas configurações de computação, nas preferências de espaço de nomes ou nos argumentos de tempo de execução do pipeline.
Altere a imagem nas preferências do espaço de nomes
Se tiver substituído a versão da imagem nas propriedades do espaço de nomes, siga estes passos:
Clique em Administrador do sistema > Configuração > Espaços de nomes.
Abra cada espaço de nomes e clique em Preferências.
Certifique-se de que não existe uma substituição com a chave
system.profile.properties.imageVersioncom um valor de versão da imagem incorreto.Clique em Concluir.
Altere a imagem nos perfis de computação do sistema
Clique em Administrador do sistema > Configuração.
Clique em Sistema Perfis de computação > Criar novo perfil.
Selecione o aprovisionador Dataproc.
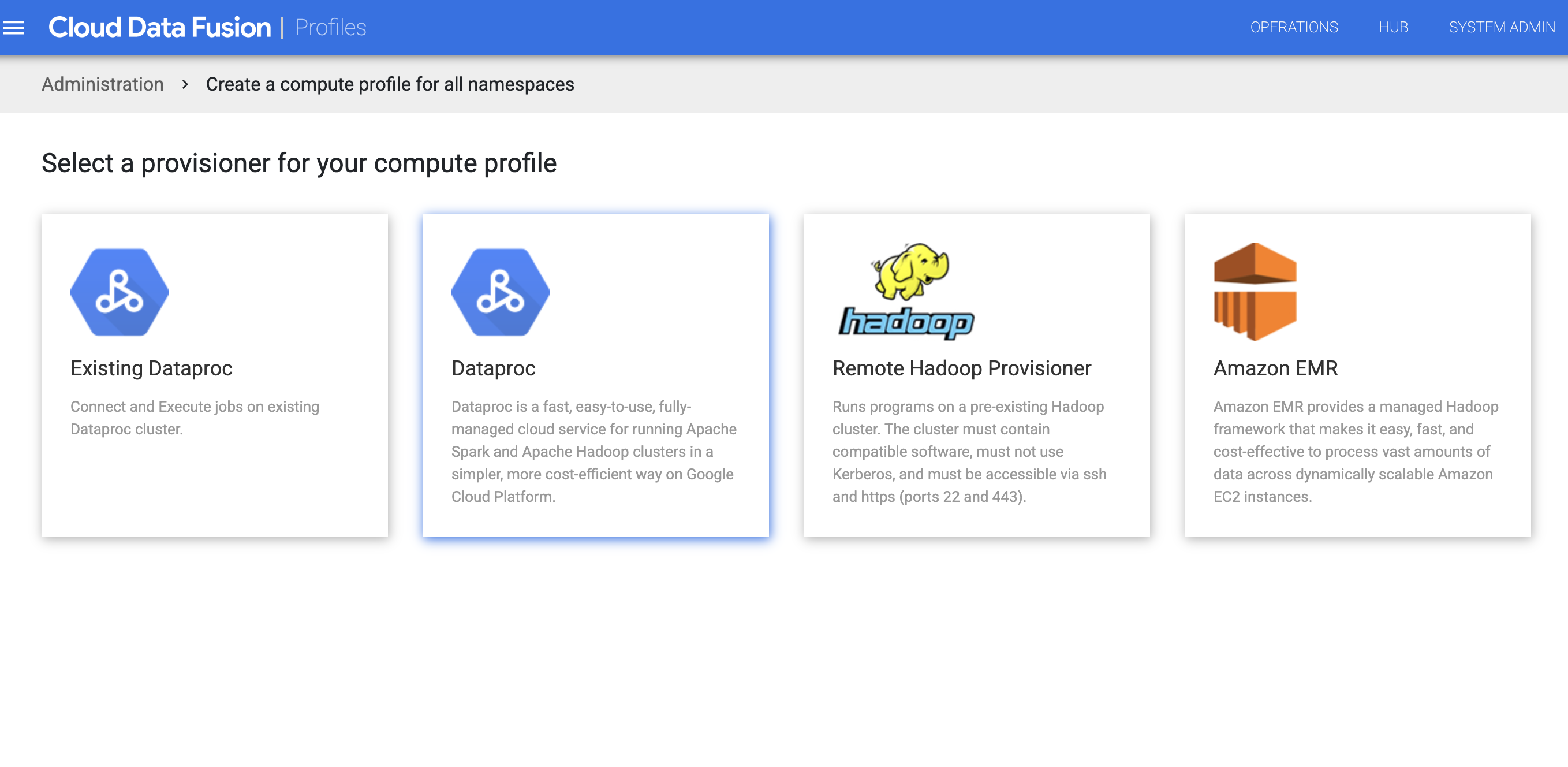
Crie o perfil para o Dataproc. No campo Versão da imagem, introduza uma versão da imagem do Dataproc.
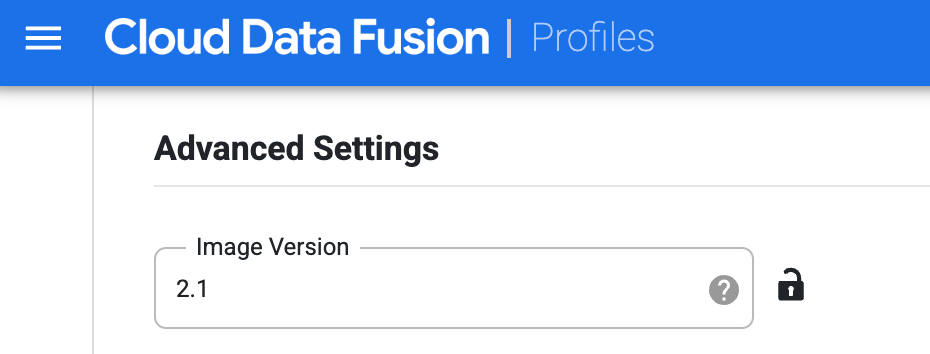
Selecione este perfil de computação enquanto executa o pipeline na página Studio. Na página de execução do pipeline, clique em Configurar > Configuração de computação e selecione este perfil.
Selecione o perfil do Dataproc e clique em Guardar.
Clique em Concluir.
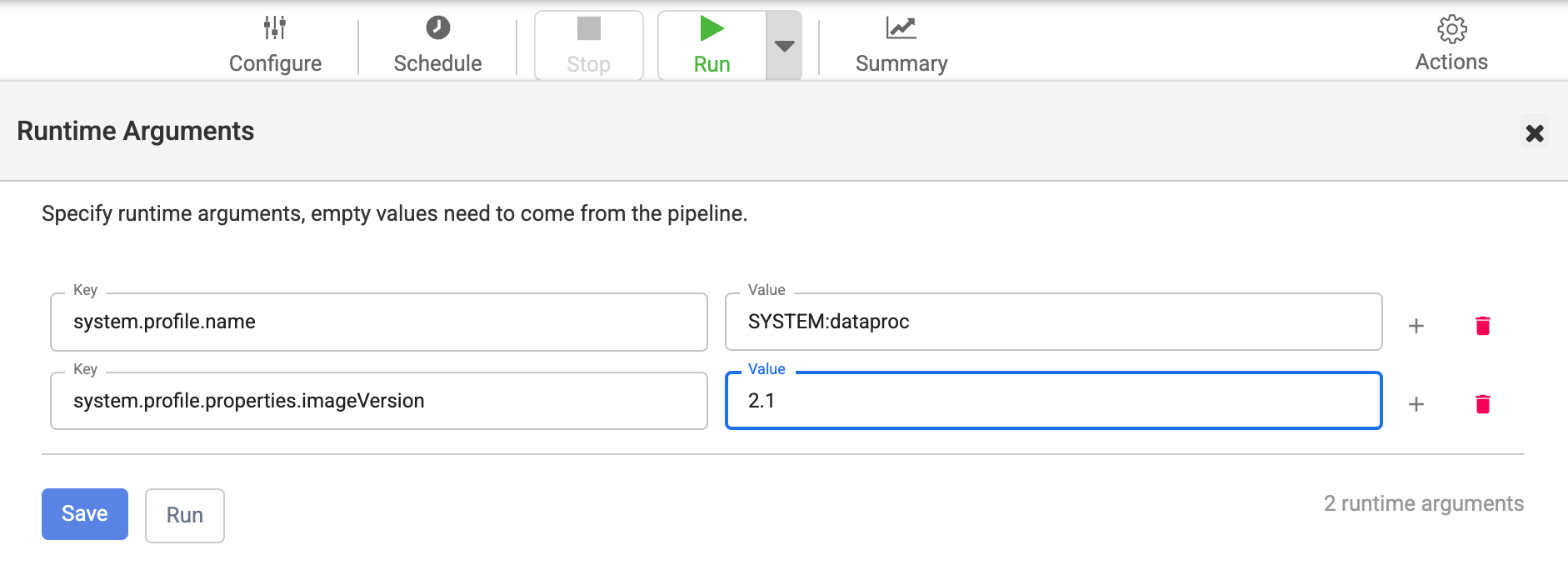
Altere a imagem nos argumentos de tempo de execução do pipeline
Se tiver substituído a versão da imagem por uma propriedade nos argumentos de tempo de execução do seu pipeline, siga estes passos:
Clique no menu Menu > Lista.
Na página Lista, selecione o pipeline que quer atualizar.
O pipeline é aberto na página Studio.
Para expandir as opções de Execução, clique na seta do expansor .
É aberta a janela Argumentos de tempo de execução.
Verifique se não existe uma substituição com a chave
system.profile.properties.imageVersioncom uma versão da imagem incorreta como valor.Clique em Guardar.
Recrie clusters estáticos do Dataproc usados pelo Cloud Data Fusion com a versão da imagem escolhida
Se usar clusters do Dataproc existentes com o Cloud Data Fusion, siga o guia do Dataproc para recriar os clusters com a versão da imagem do Dataproc escolhida para a sua versão do Cloud Data Fusion.
Em alternativa, pode criar um novo cluster do Dataproc com a versão da imagem do Dataproc escolhida e eliminar e recriar o perfil de computação no Cloud Data Fusion com o mesmo nome do perfil de computação e o nome do cluster do Dataproc atualizado. Desta forma, a execução de pipelines em lote pode ser concluída no cluster existente e as execuções de pipelines subsequentes ocorrem no novo cluster do Dataproc. Pode eliminar o cluster do Dataproc antigo depois de confirmar que todas as execuções da pipeline foram concluídas.
Verifique se a versão da imagem do Dataproc está atualizada
Consola
Na Google Cloud consola, aceda à página Clusters do Dataproc.
Abra a página Detalhes do cluster para o novo cluster que o Cloud Data Fusion criou quando especificou a nova versão.
O campo Versão da imagem tem o novo valor que especificou no Cloud Data Fusion.
API REST
Apresente a lista de clusters com os respetivos metadados:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION_ID/clustersSubstitua o seguinte:
PROJECT_IDcom o nome do seu espaço de nomesREGION_IDcom o nome da região onde os seus clusters estão localizados
Pesquise o nome do seu pipeline (nome do cluster).
Nesse objeto JSON, veja a imagem em
config > softwareConfig > imageVersion.
Altere a imagem do Dataproc para a versão 2.1 ou posterior
As versões 6.9.1 e posteriores do Cloud Data Fusion suportam a imagem 2.1 do Dataproc Compute Engine, que é executada no Java 11. Nas versões 6.10.0 e posteriores, a imagem 2.1 é a predefinição.
Se mudar para a imagem 2.1 ou posterior a partir de uma imagem anterior, para que os pipelines em lote e os trabalhos de replicação sejam bem-sucedidos, os controladores JDBC que os plug-ins de base de dados usam nessas instâncias têm de ser compatíveis com o Java 11.
As imagens 2.2 e 2.1 do Dataproc têm as seguintes limitações no Cloud Data Fusion:
- Os trabalhos de redução de mapas não são suportados.
- As versões dos controladores JDBC usadas nos plug-ins de base de dados na sua instância têm de ser atualizadas para terem suporte para o Java 11. Consulte a seguinte tabela para ver as versões dos controladores compatíveis com o Dataproc 2.2, 2.1 e Java 11:
| Controladores JDBC | Versões anteriores removidas do Cloud Data Fusion 6.9.1 | Versões suportadas do Java 8 e Java 11 que funcionam com o Dataproc 2.2, 2.1 ou 2.0 |
|---|---|---|
| Controlador JDBC do Cloud SQL para MySQL | - | 1.0.16 |
| Controlador JDBC do Cloud SQL para PostgreSQL | - | 1.0.16 |
| Controlador JDBC do Microsoft SQL Server | Controlador JDBC da Microsoft 6.0 | Controlador JDBC da Microsoft 9.4 |
| Controlador JDBC do MySQL | 5.0.8 e 5.1.39 | 8.0.25 |
| Controlador JDBC do PostgreSQL | 9.4.1211.jre7, 9.4.1211.jre8 | 42.6.0.jre8 |
| Controlador JDBC da Oracle | ojdbc7 | ojdbc8 (12c e superior) |
Utilização de memória ao usar o Dataproc 2.1 ou posterior
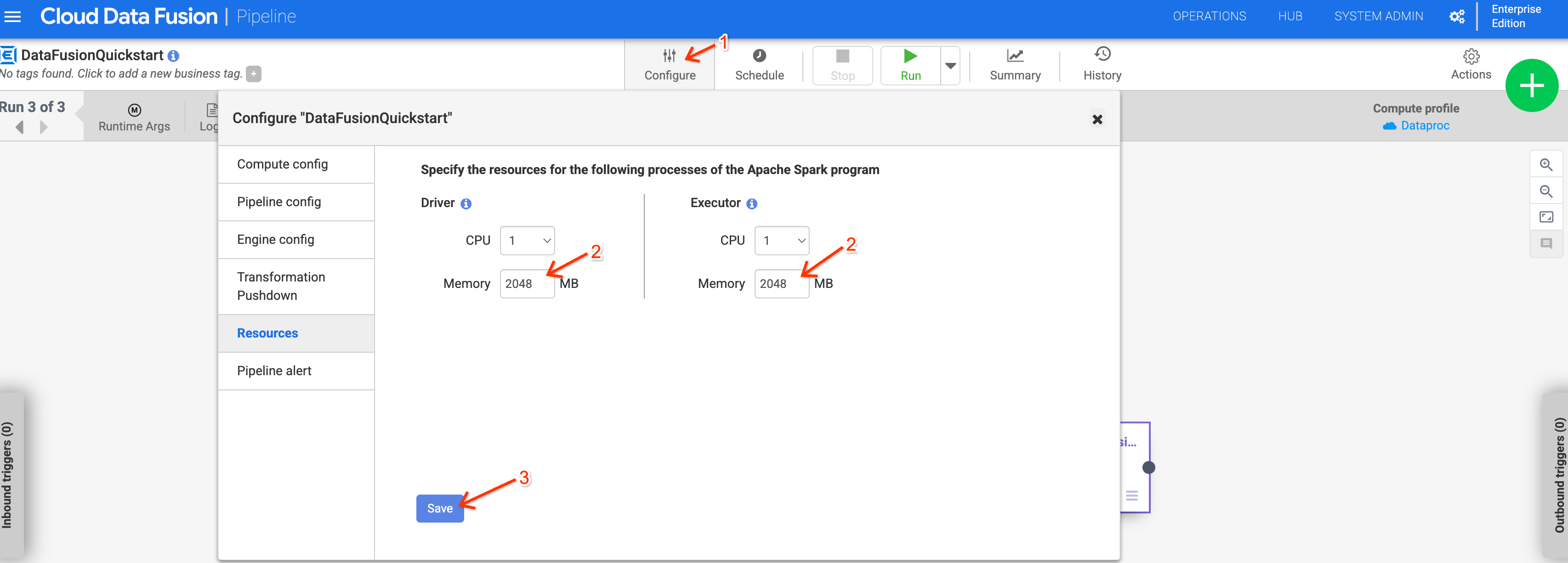
A utilização de memória pode aumentar para pipelines que usam o Dataproc 2.1 ou posterior. Se atualizar a sua instância para a versão 6.10 ou posterior e os pipelines anteriores estiverem a falhar devido a problemas de memória, aumente a memória do controlador e do executor para 2048 MB na configuração Resources para o pipeline.
Em alternativa, pode substituir a versão do Dataproc definindo o argumento de tempo de execução system.profile.properties.imageVersion como 2.0-debian10.