이 페이지에서는 Cloud Data Fusion에서 서비스 계정이 사용되는 방법을 설명합니다. 자세한 내용은 서비스 계정 사용을 참조하세요.
테넌트 및 고객 프로젝트
Cloud Data Fusion은 서비스 계정을 설정하여 다음 프로젝트의 리소스에 액세스합니다.
- 테넌트 프로젝트
Cloud Data Fusion은 사용자를 대신하여 파이프라인을 관리하는 데 필요한 리소스와 서비스를 보관할 테넌트 프로젝트를 만듭니다. 예를 들어 고객 프로젝트에 있는 Dataproc 클러스터에서 파이프라인을 실행합니다. 테넌트 프로젝트는 사용자에게 노출되지 않지만 비공개 인스턴스를 만들 때 테넌트 프로젝트 이름을 사용하여 VPC 피어링을 설정해야 할 수 있습니다.
자세한 내용은 테넌트 프로젝트에 대한 Service Infrastructure 문서를 참조하세요.
- 고객 프로젝트
사용자가 이 프로젝트를 만들고 소유합니다. 기본적으로 Cloud Data Fusion은 파이프라인을 실행하기 위해 이 프로젝트에 임시 Dataproc 클러스터를 만듭니다.
다음 다이어그램은 테넌트 프로젝트에서 실행 중인 Cloud Data Fusion 인스턴스와 고객 프로젝트의 Dataproc 클러스터에서 실행되는 파이프라인을 보여줍니다.
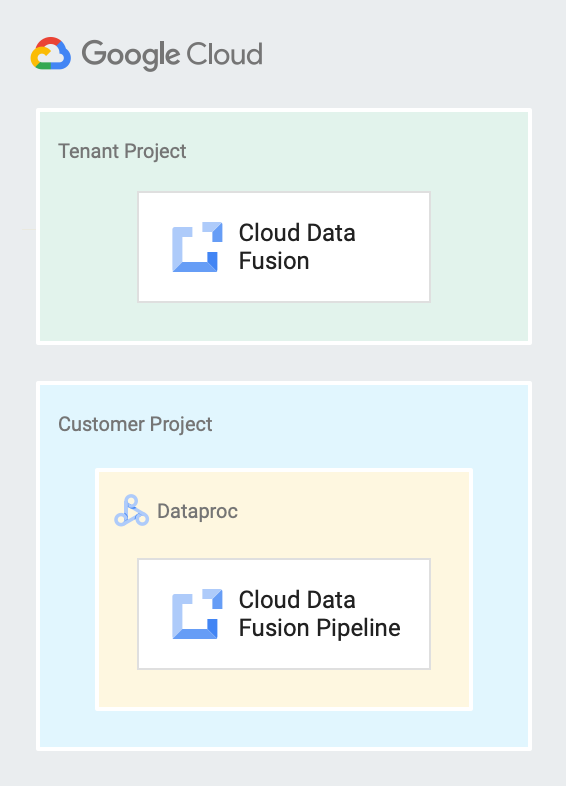
Cloud Data Fusion의 서비스 계정
서비스 계정은 Cloud Data Fusion에 ID를 제공하여 Cloud Data Fusion이 리소스에 액세스할 수 있게 합니다.
Cloud Data Fusion API를 사용 설정하고 Cloud Data Fusion 인스턴스를 만들면 서비스 네트워킹, Dataproc, Cloud Storage, BigQuery, Spanner, Bigtable과 같은 리소스에 액세스할 수 있도록 서비스 계정이 프로젝트에 추가됩니다. 이 서비스 계정을 Cloud Data Fusion API 서비스 에이전트라고 합니다. 역할은 이 서비스 에이전트에 자동으로 부여됩니다.
서비스 계정은 계정 고유의 이메일 주소로 식별됩니다.
Cloud Data Fusion에서는 다음 유형의 서비스 계정이 사용됩니다. 자세한 내용은 서비스 계정 유형을 참고하세요.
| 서비스 계정 | 설명 |
|---|---|
service-CUSTOMER_PROJECT_NUMBER@gcp-sa-
datafusion.iam.gserviceaccount.com |
서비스 에이전트, 즉 Cloud Data Fusion이 고객을 대신하여 작업할 수 있도록 고객 리소스에 대한 액세스 권한을 얻기 위해 만드는 Cloud Data Fusion API 서비스 에이전트입니다. 테넌트 프로젝트에서 고객 프로젝트 리소스에 액세스하는 데 사용됩니다. 예를 들어 미리보기는 Dataproc 클러스터 대신 메모리에서 실행됩니다. 기본적으로 Cloud Data Fusion 서비스 계정에 할당된 Cloud Data Fusion API 서비스 에이전트( |
CUSTOMER_PROJECT_NUMBER-
compute@developer.gserviceaccount.com |
Cloud Data Fusion이 다른 Google Cloud 리소스에 액세스하는 작업을 배포하기 위해 만드는 기본 Compute Engine 서비스 계정입니다. 기본적으로 Dataproc 클러스터 VM에 연결하여 파이프라인 실행 중에 Cloud Data Fusion이 Dataproc 리소스에 액세스할 수 있도록 합니다. Cloud Data Fusion 콘솔→시스템 관리자→구성 탭에서 프로필을 만들고 커스텀 서비스 계정을 추가하여 Cloud Data Fusion Enterprise 버전에서 사용자 관리 서비스 계정으로 파이프라인을 실행할 수 있습니다. 버전 6.2.3 이상에서는 Cloud Data Fusion 인스턴스를 만들 때 Dataproc 클러스터에 연결할 커스텀 서비스 계정을 선택할 수 있습니다. 자세한 내용은 Dataproc의 서비스 계정을 참고하세요. |
다음 단계
- 데이터에 대한 액세스 제어에 대해 알아보기
- 서비스 계정 사용자 권한 부여
- Cloud Data Fusion 가격 책정 참조