Organízate con las colecciones
Guarda y clasifica el contenido según tus preferencias.
En esta página se describe cómo se usan las cuentas de servicio en Cloud Data Fusion. Para obtener más información, consulta Usar cuentas de servicio.
Proyectos de inquilinos y clientes
Cloud Data Fusion configura cuentas de servicio para acceder a los recursos de los siguientes proyectos:
Proyecto de cliente
Cloud Data Fusion crea un proyecto de arrendatario para alojar los recursos y los servicios que necesita para gestionar los flujos de procesamiento en tu nombre. Por ejemplo, ejecutar flujos de procesamiento en tus clústeres de Dataproc que residen en tu proyecto de cliente. No tienes acceso a los proyectos de inquilino, pero, cuando creas una instancia privada, es posible que tengas que usar el nombre del proyecto de inquilino para configurar el peering de VPC.
Para obtener más información, consulta la documentación de Service Infrastructure sobre los proyectos de propietario.
Proyecto de cliente
Tú creas este proyecto y eres su propietario. De forma predeterminada, Cloud Data Fusion crea un clúster de Dataproc efímero en este proyecto para ejecutar tus flujos de procesamiento.
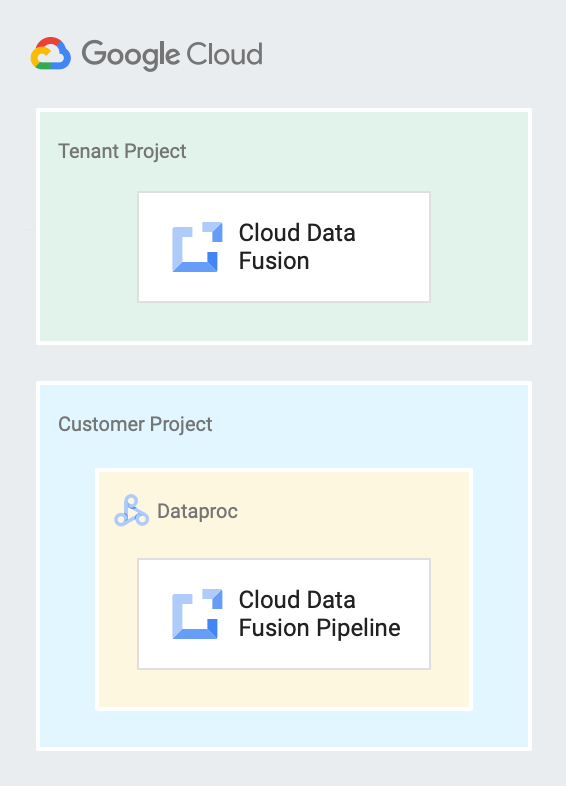
En el siguiente diagrama se muestra una instancia de Cloud Data Fusion que se ejecuta en un proyecto de arrendatario y un flujo de procesamiento que se ejecuta en un clúster de Dataproc en un proyecto de cliente.
Cuentas de servicio en Cloud Data Fusion
Una cuenta de servicio proporciona una identidad a Cloud Data Fusion, lo que le da acceso a tus recursos.
Cuando habilitas la API de Cloud Data Fusion y creas una instancia de Cloud Data Fusion, se añade una cuenta de servicio a tu proyecto para acceder a recursos como redes de servicios, Dataproc, Cloud Storage, BigQuery, Spanner y Bigtable. Esta cuenta de servicio se llama agente de servicio de la API de Cloud Data Fusion.
Los roles se conceden automáticamente a este agente de servicio.
Las cuentas de servicio se identifican por su dirección de correo, que es única para cada cuenta.
En Cloud Data Fusion se usan los siguientes tipos de cuentas de servicio. Para obtener más información, consulta Tipos de cuentas de servicio.
El agente de servicio, llamado agente de servicio de la API Cloud Data Fusion, que Cloud Data Fusion crea para obtener acceso a los recursos del cliente y poder actuar en su nombre. Se usa en el proyecto de inquilino para acceder a los recursos del proyecto de cliente. Por ejemplo,
La vista previa se ejecuta en la memoria en lugar de en un clúster de Dataproc.
El rol de Gestión de Identidades y Accesos Agente de servicio de la API de Cloud Data Fusion (roles/datafusion.serviceAgent) asignado a la cuenta de servicio de Cloud Data Fusion de forma predeterminada incluye permisos adicionales para garantizar una experiencia de usuario óptima. Para mejorar la seguridad, puedes crear un rol personalizado con un conjunto de permisos mínimos necesarios para una tarea y asignarlo a la cuenta de servicio de Cloud Data Fusion.
La cuenta de servicio predeterminada de Compute Engine que crea Cloud Data Fusion para desplegar tareas que acceden a otros Google Cloud recursos. De forma predeterminada, se adjunta a una máquina virtual de clúster de Dataproc para permitir que Cloud Data Fusion acceda a los recursos de Dataproc durante la ejecución de una canalización. En la edición Enterprise de Cloud Data Fusion, puedes ejecutar flujos de procesamiento desde una cuenta de servicio gestionada por el usuario. Para ello, crea un perfil en la consola de Cloud Data Fusion (Administrador del sistema > pestaña Configuración) y añade la cuenta de servicio personalizada. En las versiones 6.2.3 y posteriores, puedes elegir una cuenta de servicio personalizada para asociarla al clúster de Dataproc al crear una instancia de Cloud Data Fusion. Para obtener más información, consulta el artículo
Cuentas de servicio en Dataproc.
[[["Es fácil de entender","easyToUnderstand","thumb-up"],["Me ofreció una solución al problema","solvedMyProblem","thumb-up"],["Otro","otherUp","thumb-up"]],[["Es difícil de entender","hardToUnderstand","thumb-down"],["La información o el código de muestra no son correctos","incorrectInformationOrSampleCode","thumb-down"],["Me faltan las muestras o la información que necesito","missingTheInformationSamplesINeed","thumb-down"],["Problema de traducción","translationIssue","thumb-down"],["Otro","otherDown","thumb-down"]],["Última actualización: 2025-09-11 (UTC)."],[[["\u003cp\u003eCloud Data Fusion uses service accounts to access resources in both tenant and customer projects, enabling it to manage pipelines on the user's behalf.\u003c/p\u003e\n"],["\u003cp\u003eThe Cloud Data Fusion API Service Agent is a service account created automatically when enabling the Cloud Data Fusion API, granting it access to resources like Service Networking, Dataproc, Cloud Storage, and others.\u003c/p\u003e\n"],["\u003cp\u003eA default Compute Engine service account is also created to deploy jobs that access other Google Cloud resources, which can attach to a Dataproc cluster VM to enable Cloud Data Fusion to access Dataproc resources during pipeline runs.\u003c/p\u003e\n"],["\u003cp\u003eIn Cloud Data Fusion Enterprise edition, pipelines can run from a user-managed service account by creating a profile in the Cloud Data Fusion console, enhancing control and customization.\u003c/p\u003e\n"],["\u003cp\u003eCustomer project is owned by the customer and is the location where the ephemeral Dataproc cluster is located in order to run the user's pipelines.\u003c/p\u003e\n"]]],[],null,["# Service accounts in Cloud Data Fusion\n\nThis page describes how service accounts are used in Cloud Data Fusion. For\nmore information, see [Use service accounts](/iam/docs/service-accounts).\n\n### Tenant and customer projects\n\nCloud Data Fusion sets up service accounts to access resources in the\nfollowing projects:\n\nTenant project\n\n: Cloud Data Fusion creates a tenant project to hold the resources and\n services it needs to manage pipelines on your behalf. For example: running\n pipelines on your Dataproc clusters that reside in your customer\n project. A tenant project is not exposed to you, but when you create a\n private instance, you might need to use the tenant project name to set up VPC\n peering.\n\n For more information, see the Service Infrastructure documentation about\n [tenant projects](/service-infrastructure/docs/glossary#tenant).\n\nCustomer project\n\n: You create and own this project. By default, Cloud Data Fusion creates an\n ephemeral Dataproc cluster in this project to run the your\n pipelines.\n\nThe following diagram shows a Cloud Data Fusion instance running in a\ntenant project and a pipeline running on a Dataproc cluster in a\ncustomer project.\n\nService accounts in Cloud Data Fusion\n-------------------------------------\n\nA service account provides an identity for Cloud Data Fusion, which gives\nCloud Data Fusion access to your resources.\n\nWhen you enable the Cloud Data Fusion API and create a\nCloud Data Fusion instance, a service account is added to your project to\naccess resources like Service Networking,\nDataproc, Cloud Storage, BigQuery, Spanner,\nand Bigtable. This service account is called the\n[Cloud Data Fusion API Service Agent](/iam/docs/understanding-roles#datafusion.serviceAgent).\nRoles are automatically granted to this service agent.\n\nA service account is identified by its email address, which is unique to the\naccount.\n\nThe following types of service accounts are used in Cloud Data Fusion. For\nmore information, see [Types of service accounts](/iam/docs/service-account-types).\n\nWhat's next\n-----------\n\n- Learn about [controlling access to data](/data-fusion/docs/access-control).\n- [Give Service Account User permissions](/data-fusion/docs/how-to/granting-service-account-permission).\n- See Cloud Data Fusion [pricing](/data-fusion/pricing)."]]