Cette page explique comment les comptes de service sont utilisés dans Cloud Data Fusion. Pour en savoir plus, consultez Utiliser des comptes de service.
Projets clients et locataires
Cloud Data Fusion configure des comptes de service pour accéder aux ressources des projets suivants :
- Projet locataire
Cloud Data Fusion crée un projet locataire destiné à contenir les ressources et les services dont il a besoin pour gérer des pipelines en votre nom. Par exemple, pour exécuter des pipelines sur des clusters Dataproc résidant dans votre projet client. Un projet locataire ne vous est pas directement exposé. Cependant, lorsque vous créerez une instance privée, vous devrez peut-être utiliser le nom du projet locataire pour configurer l'appairage de VPC.
Pour en savoir plus, consultez la documentation Service Infrastructure concernant les projets locataires.
- Projet client
Vous créez ce projet et en êtes le propriétaire. Par défaut, Cloud Data Fusion crée un cluster Dataproc éphémère dans ce projet pour exécuter vos pipelines.
Le schéma suivant montre une instance Cloud Data Fusion s'exécutant dans un projet locataire et un pipeline s'exécutant sur un cluster Dataproc dans un projet client.
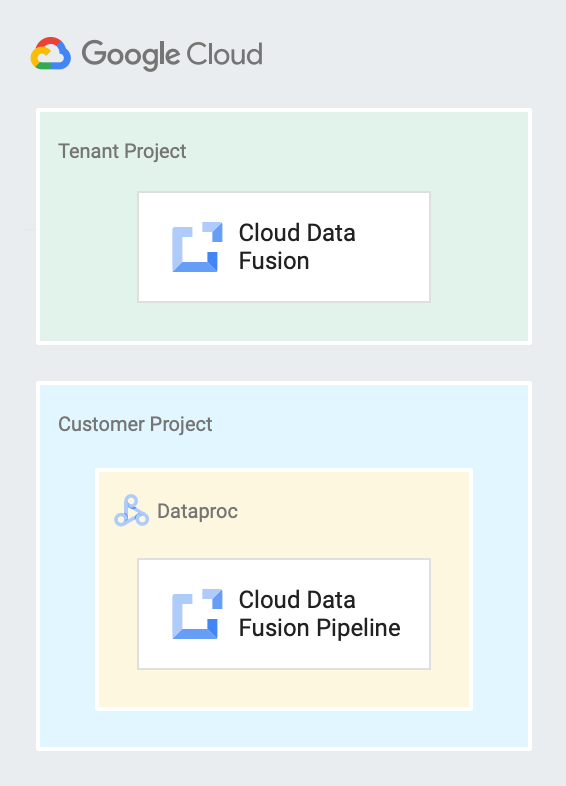
Comptes de service dans Cloud Data Fusion
Un compte de service fournit une identité à Cloud Data Fusion, lui permettant d'accéder à vos ressources.
Lorsque vous activez l'API Cloud Data Fusion et que vous créez une instance Cloud Data Fusion, un compte de service est ajouté à votre projet pour accéder à des ressources telles que Service Networking, Dataproc, Cloud Storage, BigQuery, Spanner et Bigtable. Ce compte de service est appelé Agent de service de l'API Cloud Data Fusion. Des rôles sont automatiquement attribués à cet agent de service.
Un compte de service est identifié par son adresse e-mail, qui est unique au compte.
Les types de comptes de service suivants sont utilisés dans Cloud Data Fusion. Pour en savoir plus, consultez Types de comptes de service.
| Compte de service | Description |
|---|---|
service-CUSTOMER_PROJECT_NUMBER@gcp-sa-
datafusion.iam.gserviceaccount.com |
L'agent de service, appelé Agent de service de l'API Cloud Data Fusion, que Cloud Data Fusion crée pour accéder aux ressources du client afin de pouvoir agir au nom de celui-ci. Il est utilisé dans le projet locataire pour accéder aux ressources du projet client. Par exemple, la version Bêta s'exécute en mémoire plutôt que dans un cluster Dataproc. Le rôle IAM (Identity and Access Management) Agent de service de l'API Cloud Data Fusion ( |
CUSTOMER_PROJECT_NUMBER-
compute@developer.gserviceaccount.com |
Le compte de service Compute Engine par défaut que Cloud Data Fusion crée pour déployer des jobs qui accèdent à d'autres ressources Google Cloud . Par défaut, il est associé à une VM de cluster Dataproc pour permettre à Cloud Data Fusion d'accéder aux ressources Dataproc pendant l'exécution d'un pipeline. Dans l'édition Enterprise de Cloud Data Fusion, vous pouvez exécuter des pipelines à partir d'un compte de service géré par l'utilisateur. Pour ce faire, créez un profil à partir de la console Cloud Data Fusion→Administrateur système→onglet Configuration, puis ajoutez le compte de service personnalisé. Dans les versions 6.2.3 et ultérieures, vous pouvez choisir un compte de service personnalisé à associer au cluster Dataproc lors de la création d'une instance Cloud Data Fusion. Pour en savoir plus, consultez la section Comptes de service dans Dataproc. |
Étapes suivantes
- Découvrez comment contrôler les accès aux données.
- Accordez des autorisations à l'utilisateur du compte de service.
- Consultez les tarifs de Cloud Data Fusion.