보안 권장사항
강력한 보안 경계 또는 격리가 필요한 워크로드의 경우 다음을 고려하세요.
엄격한 격리를 적용하려면 보안에 민감한 워크로드를 다른 Google Cloud 프로젝트에 배치합니다.
특정 리소스에 대한 액세스를 제어하려면 Cloud Data Fusion 인스턴스에서 역할 기반 액세스 제어를 사용 설정합니다.
인스턴스에 공개적으로 액세스할 수 없게 하면서 민감한 정보 유출 위험을 줄이려면 인스턴스에서 내부 IP 주소 및 VPC 서비스 제어(VPC- SC)를 사용 설정합니다.
인증
Cloud Data Fusion 웹 UI는 Identity and Access Management를 통해 액세스가 제어되는 Google Cloud console에서 지원되는 인증 메커니즘을 지원합니다.
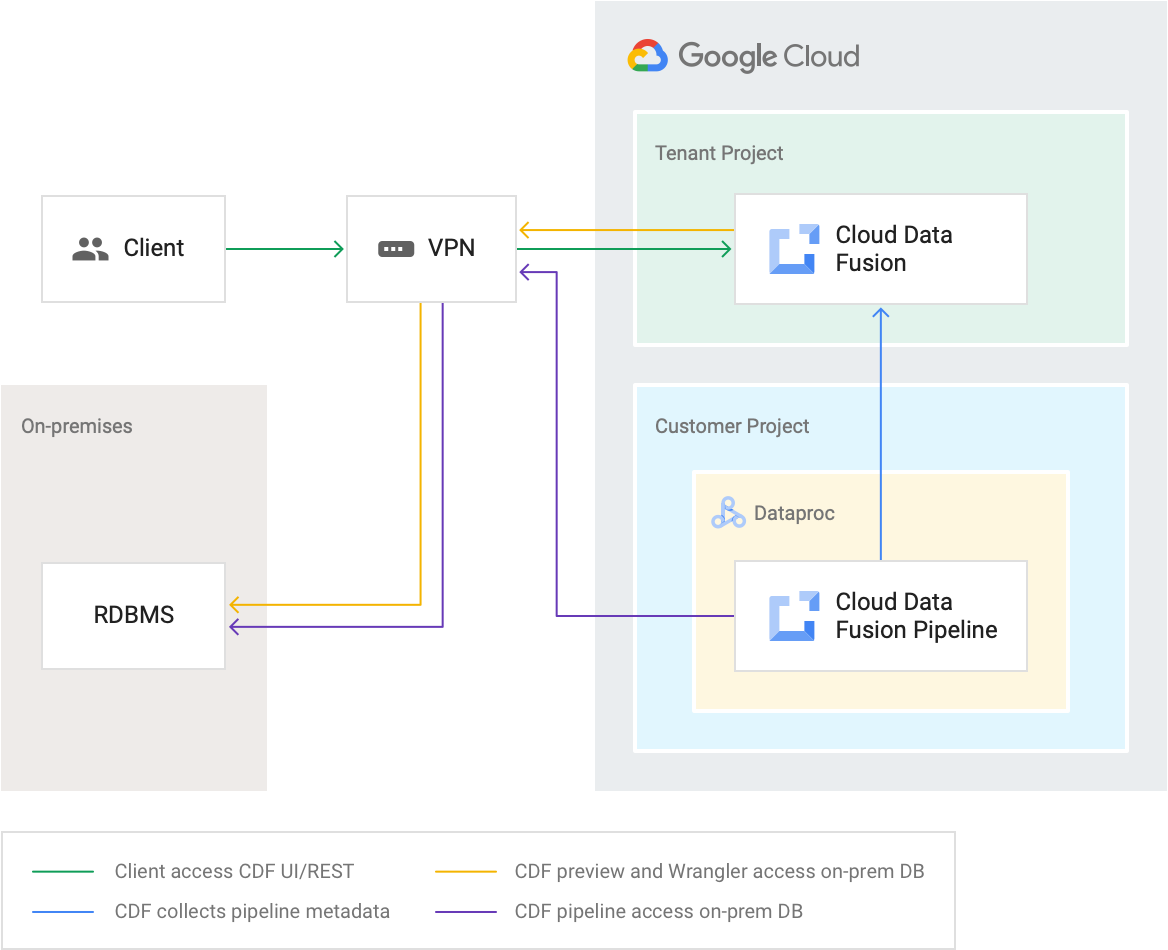
네트워킹 제어 기능
VPC 피어링 또는 Private Service Connect를 통해 VPC 네트워크에 연결할 수 있는 비공개 Cloud Data Fusion 인스턴스를 만들 수 있습니다. 비공개 Cloud Data Fusion 인스턴스에는 내부 IP 주소가 있으며 공개 인터넷에 노출되지 않습니다. VPC 서비스 제어를 사용하면 Cloud Data Fusion 비공개 인스턴스 주위에 보안 경계를 설정해 보안을 강화할 수 있습니다.
자세한 내용은 Cloud Data Fusion 네트워킹 개요를 참조하세요.
사전 생성된 내부 IP Dataproc 클러스터에서 파이프라인 실행
비공개 Cloud Data Fusion 인스턴스는 원격 Hadoop 프로비저닝 도구와 함께 사용할 수 있습니다. Dataproc 클러스터는 Cloud Data Fusion과 피어링된 VPC 네트워크에 있어야 합니다. 원격 Hadoop 프로비저닝 도구는 Dataproc 클러스터의 마스터 노드에 대한 내부 IP 주소로 구성됩니다.
액세스 제어
Cloud Data Fusion 인스턴스에 대한 액세스 관리: RBAC가 사용 설정된 인스턴스는 Identity and Access Management를 통해 네임스페이스 수준에서 액세스 관리를 지원합니다. RBAC가 사용 중지된 인스턴스는 인스턴스 수준에서 액세스 관리만 지원합니다. 인스턴스에 대한 액세스 권한이 있으면 해당 인스턴스의 모든 파이프라인 및 메타데이터에 액세스할 수 있습니다.
데이터에 대한 파이프라인 액세스: 데이터에 대한 파이프라인 액세스는 사용자가 지정하는 커스텀 서비스 계정일 수 있는 서비스 계정에 대한 액세스 권한을 부여하여 제공합니다.
방화벽 규칙
파이프라인 실행의 경우 파이프라인이 실행되는 고객 VPC에 적절한 방화벽 규칙을 설정하여 인그레스 및 이그레스를 제어합니다.
자세한 내용은 방화벽 규칙을 참조하세요.
키 저장
비밀번호, 키, 기타 데이터가 Cloud Data Fusion에 안전하게 저장되고 Cloud Key Management Service에 저장된 키를 사용하여 암호화됩니다. 런타임 시 Cloud Data Fusion은 Cloud Key Management Service를 호출하여 저장된 보안 비밀을 복호화하는 데 사용되는 키를 가져옵니다.
암호화
기본적으로 저장 데이터는 Google-owned and Google-managed encryption keys를 사용하여 암호화되며 전송 중인 데이터는 TLS v1.2를 사용하여 암호화됩니다. 고객 관리 암호화 키 (CMEK)를 사용하여 Dataproc 클러스터 메타데이터와 Cloud Storage, BigQuery, Pub/Sub 데이터 소스와 싱크를 포함하여 Cloud Data Fusion 파이프라인에서 작성한 데이터를 제어합니다.
서비스 계정
Cloud Data Fusion 파이프라인은 고객 프로젝트의 Dataproc 클러스터에서 실행되며 고객 지정(커스텀) 서비스 계정을 사용하여 실행되도록 구성할 수 있습니다. 커스텀 서비스 계정에는 서비스 계정 사용자 역할이 부여되어야 합니다.
프로젝트
Cloud Data Fusion 서비스는 사용자가 액세스할 수 없는 Google 관리 테넌트 프로젝트에서 생성됩니다. Cloud Data Fusion 파이프라인은 고객 프로젝트 내의 Dataproc 클러스터에서 실행됩니다. 고객은 수명 기간 동안 이 클러스터에 액세스할 수 있습니다.
감사 로그
Cloud Data Fusion 감사 로그는 Logging에서 사용할 수 있습니다.
플러그인 및 아티팩트
운영자와 관리자는 신뢰할 수 없는 플러그인이나 아티팩트를 설치할 경우 보안 위험을 초래할 수 있으므로 주의해야 합니다.
직원 ID 제휴
직원 ID 제휴 사용자는 인스턴스 생성, 삭제, 업그레이드, 나열과 같은 작업을 Cloud Data Fusion에서 수행할 수 있습니다. 제한사항에 대한 자세한 내용은 직원 ID 제휴: 지원되는 제품 및 제한사항을 참조하세요.