
Lowered overall infrastructure costs by 15% on Compute Engine versus another hyperscaler
Up to 50% lower TCO and improved performance with Axion (Arm) C4A versus previous generation
Reduced recovery time to ~10 mins with GKE custom ComputeClass and Cloud SQL, mitigating risk
Processed 7 million peak qps performing >50M ML inferences daily with zero downtime
Achieved 99.99% availability across global marketplace
InMobi drives global growth and lowers infrastructure costs by 15% by scaling millions of real-time auctions with zero business-level disruptions.
InMobi drives global growth and lowers infrastructure costs by 15% by scaling millions of real-time auctions with zero business-level disruptions.
Balancing extreme scale with strict latency and availability
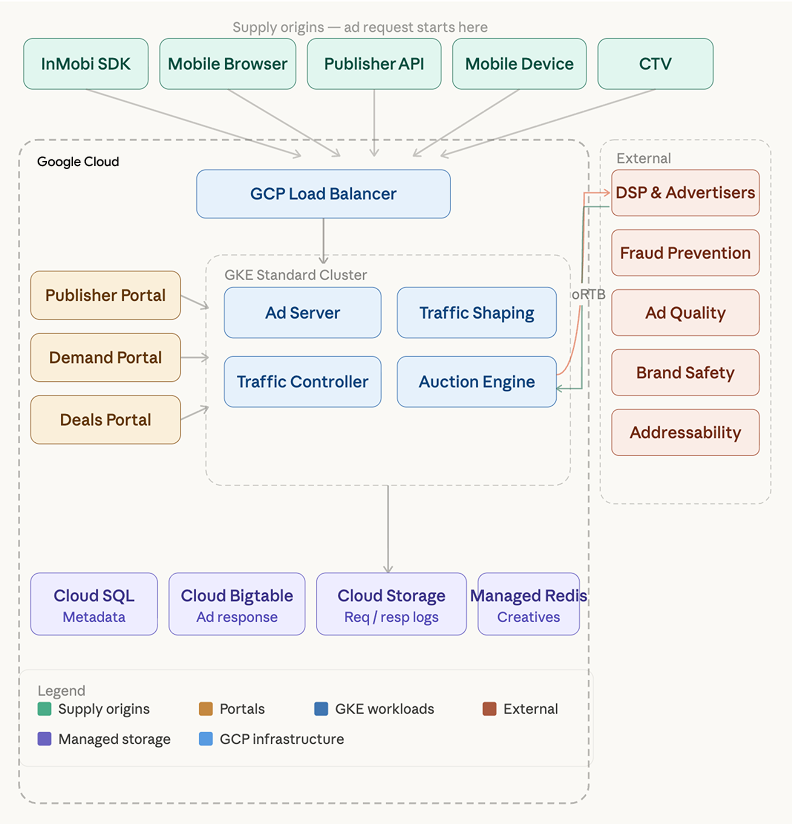
InMobi operates one of the largest real-time advertising marketplaces in the world. Every bid request moves through a pipeline of services where latency and availability directly determine revenue. Its Unified Marketplace receives millions of bid requests within a 500-millisecond bidding window, while the Geo Traffic Manager routes traffic globally to support real-time auctions. Downstream, the auction layer must complete bid evaluation within a few hundred milliseconds. In this environment, even a moment of downtime carries financial impact, with infrastructure scaling dynamically to support up to 750,000 compute cores during peak demand.
Roughly 90% of its workloads run on spot compute to keep unit economics aligned with revenue in a low-margin marketplace. However, when spot eviction waves occurred, failover mechanisms could not always switch capacity quickly. “At our scale, systems are sensitive,” says Anshul Garg, Senior Director of Engineering at InMobi. “If one service goes down, it creates a domino effect.”
Infrastructure flexibility was another limitation. Standardized virtual machine shapes limited InMobi’s ability to tune core-to-memory ratios and constrained cost optimization.
Google Cloud offered the integrated, end-to-end capabilities required to support our performance and reliability goals at scale.
Anshul Garg
Senior Director of Engineering, InMobi
Processing more than a petabyte of data per day and maintaining several petabytes of supply-side platform data placed pressure on InMobi to modernize its data architecture.
As InMobi evaluated cloud platforms, it prioritized an environment that could deliver both compute flexibility and a tightly integrated stack. With peak traffic exceeding 7 million queries per second (QPS) across regions, a static infrastructure model required overprovisioning to maintain availability, leading to off-peak inefficiencies. The platform needed to support large-scale analytics, model training, and live inference within the strict latency boundaries of real-time auctions, while sustaining 99.99% availability. “We looked for a cohesive data-to-AI pipeline that could power real-time bidding with sub-100 millisecond inference,” Garg says. “Google Cloud offered the integrated, end-to-end capabilities required to support our performance and reliability goals at scale.”
Architecting a unified data-to-AI platform for real-time auctions
InMobi executed a hybrid migration strategy from another hyperscaler that combined lift-and-shift with targeted modernization. Core services from another hyperscaler were mapped to Google Cloud equivalents, including migrating orchestration to Google Kubernetes Engine (GKE), compute to Compute Engine, and relational databases to Cloud SQL. Rather than performing a full cutover, production traffic was migrated incrementally to validate latency and autoscaling behavior under live auction load.
We leverage Kubernetes autoscaling and custom ComputeClasses heavily inside our serving stack. Axion C4A delivered up to 50% price-performance gains for our Ad exchange workload that flexibility across the Google Cloud stack allows us to optimize for both performance and capacity availability.
Nagesh Sahu
Senior Staff Engineer, InMobi
At the heart of the serving architecture, containerized workloads run directly in the real-time serving path, with GKE custom ComputeClasses used to dynamically manage capacity across instance types and respond to large-scale volatility in spot compute availability. “We leverage Kubernetes autoscaling heavily inside our serving stack,” says Nagesh Sahu, Staff Engineer at InMobi. “Having GKE as the first-party platform gives us confidence in the maturity of those features and the velocity at which they evolve.” Memorystore and Bigtable supports the serving flow by providing in-memory caching of ad creatives and ad responses enabling ad serving.
Serving systems were architected across multiple Compute Engine families to provide flexible capacity across instance types, including N-series machines as well as Axion C4A machines.
“Axion C4A delivered up to 50% price-performance gains for our Ad exchange workload. We made our workloads compatible across x86 and Arm so that we can move intelligently across instance families,” Sahu says. “That flexibility allows us to optimize for both performance characteristics and capacity availability.”
As the data layer, Cloud Storage houses several petabytes of supply-side platform data and supports analytics and model development workflows. Hyperdisk provides high-throughput, low-latency block storage for performance-critical services, supporting workloads that require consistent I/O behavior in the real-time serving path and data pipelines. Spark workloads run on GKE, Databricks operates on Google Cloud for distributed processing, and Cloud Composer orchestrates hundreds of production data pipelines within a managed Airflow environment.
Scaling to 7 million QPS with zero peak-season outages
Following migration, InMobi sustained 99.99% availability across its marketplace, including during high-traffic events like Black Friday and Cyber Monday. “We did not experience a single outage during peak season,” Jayaram says. “At our scale, that level of stability directly protects revenue.” When rare capacity-related incidents occurred, mean time to recovery was reduced to approximately five to ten minutes, limiting downstream impact across the serving path. “Bringing recovery into single-digit minutes is a major operational win for us,” says Preetham Jayaram, Senior Engineering Manager at InMobi.
The serving stack continues to operate at scale. The Unified Marketplace processes 5 to 7 million QPS under 500 millisecond service-level objective (SLO). The CAS layer forwards over 10 million ad requests per second and performs auctions within 270 to 350 millisecond SLO. Post-serving event servers process approximately 800,000 to one million QPS. The supply-side platform data footprint stands at 4 to 5 petabytes, with more than one petabyte processed daily, with peak traffic exceeding 7 million QPS across regions during major events.
We did not experience a single outage during peak season. At our scale, that level of stability directly protects revenue.
Preetham Jayaram
Senior Engineering Manager, InMobi
Operational efficiency improved alongside reliability. By engineering multi-level fallback across N-series and C-series instance families, InMobi maintained its spot-first operating model while preparing for up to 50% additional capacity during peak periods at lower cost, helping align infrastructure spend more closely with revenue. “The system is engineered to absorb spot volatility and reallocate capacity seamlessly, without revenue disruption,” Jayaram says.
Looking ahead, InMobi plans to deepen its GenAI advertising stack on Vertex AI, extending from model deployment into full agentic advertising to reduce launch times from weeks to minutes. Even as the company expands its use of AI, performance inside the auction path remains a priority. “In advertising technology, latency is everything,” Jayaram says. “If we can reduce a process from 500 milliseconds to 250milliseconds, it changes the game.”
InMobi is a global advertising technology platform specializing in mobile in-app advertising and real-time bidding, processing millions of ad requests per second across its exchange.
Industry: Technology
Location: India
Products: Google Kubernetes Engine (GKE), Compute Engine, Cloud Storage, Cloud SQL, Memorystore, Cloud Composer, Databricks on Google Cloud, Bigtable, Google Cloud Hyperdisk


















