Cloud Code für Cloud Shell wurde entwickelt, um die Konfiguration von Kubernetes und Cloud Build zu vereinfachen. Dazu wird das Schema per Linting auf ihre Struktur und auf zulässige Werte untersucht und es werden Fehlerbeschreibungen bereitgestellt. Zusammen mit Cloud Code erhalten Sie sofort einsatzbereite Lösungen für allgemeine Schemas, intelligente Vervollständigung und Dokumentation durch Mauszeigerbewegung.
Unterstützte YAML-Konfigurationsdateien
Cloud Code unterstützt auch gängige und sofort einsetzbare Kubernetes Custom Resource Definitions (CRDs) wie Kubeflow.
Benutzerdefiniertes Schema verwenden
Mit Cloud Code können Sie Ihr eigenes CRD-Schema mit der Einstellung cloudcode.yaml.crdSchemaLocations in Ihrer settings.json-Datei angeben.
Sie können entweder auf eine lokale Datei oder eine URL verweisen. URLs, die auf github.com verweisen, werden automatisch in raw.githubusercontent.com umgewandelt.
Schema aus einem Cluster abrufen
Wenn Sie in der Kubernetes-Ansicht zu einem Cluster mit Kubernetes v1.16 und höher wechseln, ruft Cloud Code automatisch das Schema aller installierten CRDs ab.
Mit Snippets konfigurieren
Sofort einsatzbereite Snippets für gängige YAML-Schemas (mit Command/Ctrl+Space zum Aufrufen von Optionen) vereinfachen das Starten einer neuen YAML-Datei und das fehlerfreie Hinzufügen zu einer vorhandenen Datei. Dabei werden Best Practices beachtet. Cloud Code erleichtert die Arbeit mit sich wiederholenden Feldern, da die verbleibenden Instanzen automatisch ausgefüllt werden, nachdem Sie das erste Feld ausgefüllt haben.
Cloud Code bietet die folgenden Snippets:
Anthos Config Management - ClusterAnthos Config Management - Cluster SelectorAnthos Config Management - Config ManagementAnthos Config Management - Namespace SelectorCloud Build - Cloud Run deploymentCloud Build - Docker container buildCloud Build - GKE deploymentCloud Build - GKE Skaffold deploymentCloud Build - Go buildCloud Build - Terraform plan + applyConfig Connector - BigQueryDatasetConfig Connector - BigQueryTableConfig Connector - BigtableClusterConfig Connector - BigtableInstanceConfig Connector - PubSubSubscriptionConfig Connector - PubSubTopicConfig Connector - RedisInstanceConfig Connector - SpannerInstanceKubernetes - ConfigMapKubernetes - DeploymentKubernetes - IngressKubernetes - PodKubernetes - SecretKubernetes - ServiceMigrate to Containers - ExportMigrate to Containers - PersistentVolumeClaimMigrate to Containers - StatefulSetSkaffold - BazelSkaffold - Getting-startedSkaffold - Helm deploymentSkaffold - Kaniko
Kontextbezogene Vervollständigung
Anhand des aktuellen Schemas stellt Cloud Code eine kontextbezogene Vervollständigung und entsprechende Dokumente für die Auswahl der richtigen Option bereit.
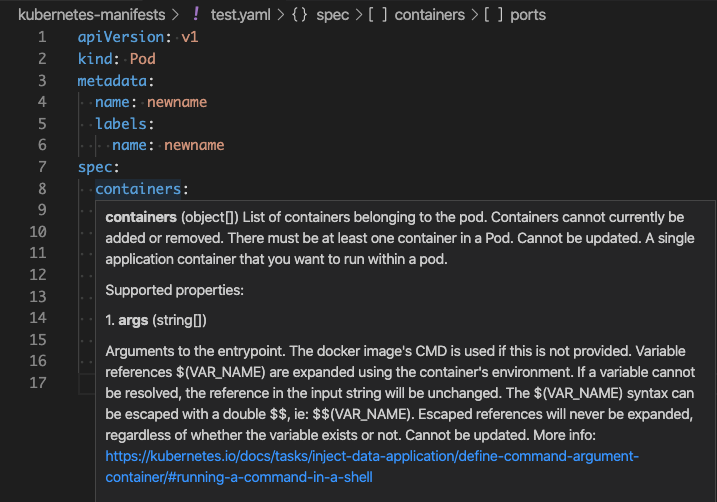
YAML-Schema prüfen
Cloud Code bietet Unterstützung für die Schemavalidierung. Dazu werden ungültige Tags und Werte in Ihren YAML-Dateien mit Flags versehen und es werden nach Möglichkeit Korrekturen empfohlen.
Dokumentation durch Mauszeigerbewegung finden
Wenn Sie den Mauszeiger auf einen Wert im Schema bewegen, wird relevante Dokumentation angezeigt.

Auf Ressourcendefinitionen zugreifen
Wenn Sie Definitionen für eine Ressource aufrufen möchten, klicken Sie mit der rechten Maustaste auf die Ressource und wählen Sie Zur Definition oder Definitionsvorschau aus.
YAML-Datei anwenden
Wenn Sie eine Konfigurationsänderung mit der aktuellen Datei anwenden möchten, öffnen Sie die Befehlspalette (drücken Sie Ctrl/Cmd + Shift + P oder klicken Sie auf Ansicht > Befehlspalette) und führen Sie dann Cloud Code: Aktuelle JSON/YAML-Datei auf bereitgestellte K8s-Ressource anwenden aus.
Mit diesem Befehl wird eine Unterschiedsansicht angezeigt, mit der Sie Änderungen prüfen können. Klicken Sie auf Anwenden, wenn Sie gefragt werden, ob Sie diese Änderung anwenden möchten. Dadurch wird kubectl apply -f ausgeführt.
Unterschiede zwischen YAML-Dateien ansehen
Wenn Sie die Unterschiede zwischen einer YAML-Datei in der Versionsverwaltung und einer bereitgestellten YAML-Datei sehen möchten, öffnen Sie die Befehlspalette (drücken Sie Ctrl/Cmd + Shift + P oder klicken Sie auf Ansicht > Befehlspalette) und führen Sie dann Cloud Code: Diff Current JSON/YAML File with K8s Deployed Resource aus.
Probelauf einer YAML-Datei ausführen
Cloud Code führt automatisch einen Probelauf durch, während Sie Informationen in Ihre YAML-Datei eingeben, und unterstreicht alle Fehler mit einer gelben gepunkteten Linie.
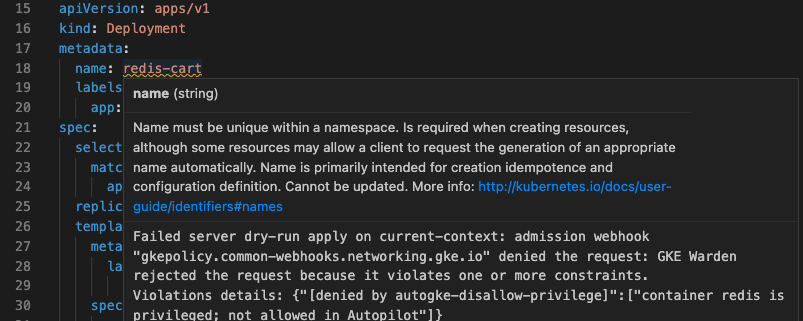
Gelbe gewundene Linien werden angezeigt, wenn der Server einen Teil Ihres Codes aufgrund des Ergebnisses eines Trockenlaufs als Fehler betrachtet. Dazu gehören Richtlinienverstöße, doppelte Namen oder Validierungen, die Cloud Code nicht clientseitig durchführt (z. B. maximale Portnummern).
Wenn Sie die Beschreibung des Fehlers in Ihrer YAML-Datei aufrufen möchten, bewegen Sie den Mauszeiger auf den Code mit der gelben Unterstreichung.
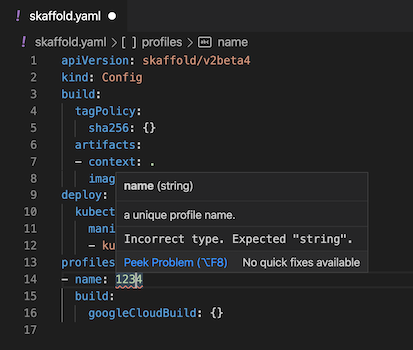
Rote gestrichelte Linien werden für erkannte Fehler angezeigt, bevor Cloud Code den Kubernetes-Server überprüft. Wenn Sie beispielsweise eine Zahl an einer Stelle eingeben, an der ein String erwartet wird, wird eine rote gestrichelte Linie angezeigt.
Mit Secrets arbeiten
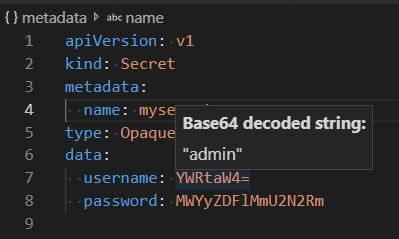
Die Verwendung von Konfigurationsplänen und Secrets ist ein wesentlicher Bestandteil der Arbeit mit Kubernetes. Wenn Sie den Kontext eines base64-Secrets mit Cloud Code aufrufen möchten, bewegen Sie zur Decodierung den Mauszeiger auf das Secret.
Nächste Schritte
- Erstellen Sie eine
skaffold.yaml-Datei mit einer Cloud Code-Kubernetes-Ausführungskonfiguration. - Erstellen Sie eine Skaffold-Konfiguration für Ihre Anwendung.
- Referenzdokumente zu
Skaffold.yaml