BigQuery 特集: データのクエリ
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
以前の BigQuery 特集では BigQuery のアーキテクチャ、ストレージ管理、BigQuery へのデータの取り込みについて確認しました。今回の投稿では、SQL を使用した BigQuery でのデータセットのクエリ実行方法、クエリの保存と共有方法、標準ビューとマテリアライズド ビューの作成方法について説明します。さっそく始めましょう。
標準 SQL
BigQuery は標準 SQL とレガシー SQL の 2 つの SQL 言語をサポートしています。標準 SQL は ANSI SQL 2011 標準を遵守していることから、BigQuery に保存されているデータのクエリに適しています。他にも、レガシー SQL と比較すると、結合処理の自動述語プッシュダウンを使用できることや、相関サブクエリをサポートしていることなどのメリットがあります。詳細については、標準 SQL の要点を参照してください。
BigQuery で SQL クエリを実行する場合は、クエリジョブが自動的に作成、スケジュール設定、実行されます。BigQuery は、インタラクティブ(デフォルト)とバッチの 2 つのモードでクエリジョブを実行します。
インタラクティブ(オンデマンド)クエリは、可能な限り速やかに実行され、同時実行のレート上限と 1 日あたりの上限の対象としてカウントされます。
バッチクエリはキューに入れられ、BigQuery 共有リソースプールのアイドル状態のリソースが利用可能になると直ちに(通常は数分以内に)開始されます。BigQuery が 24 時間以内にクエリを開始しない場合は、ジョブの優先度が「インタラクティブ」に変更されます。バッチクエリは同時実行のレート上限にはカウントされません。バッチクエリは、インタラクティブ クエリと同じリソースを使用します。
この投稿に掲載しているクエリは、標準 SQL 言語を遵守しており、別途明記していない限りインタラクティブ モードで実行されます。

BigQuery テーブルのタイプ
BigQuery のすべてのテーブルは、列名、データ型、その他のメタデータを記述するスキーマによって定義されます。BigQuery は次のテーブルタイプをサポートしています。
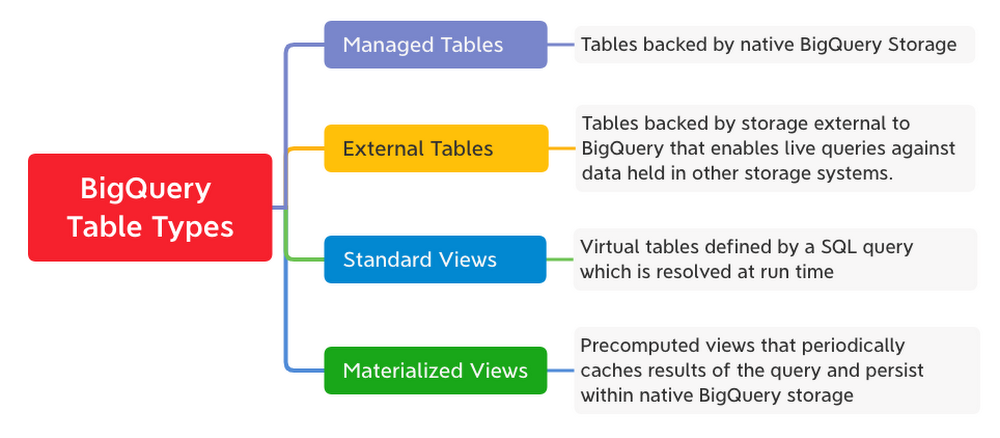
BigQuery のスキーマ
BigQuery では、スキーマがテーブルレベルで定義され、データの構造を指定します。スキーマは名前、データ型、説明、モードなどにより列を定義します。
データ型については、整数などの単純なデータ型を指定できます。ネストされた値と繰り返し値に対しては ARRAY や STRUCT などのより複雑なデータ型を指定可能です。
列モードは NULLABLE、REQUIRED、REPEATED に設定できます。
テーブル スキーマは、テーブルへのデータの読み込み時、または空のテーブルを作成する際に指定します。または、データの読み込み時に、自己記述型のソースデータ形式(Avro、Parquet、ORC、Cloud Firestore、Cloud Datastore のエクスポート ファイルなど)に対しては、スキーマの自己検出機能を使用できます。スキーマは以下に示すように、手動または JSON ファイルで定義できます。
分析を目的とした SQL の使用
それでは、SQL を使用して NCAA バスケットボールの試合と選手に関連付けられている BigQuery の一般公開データセットの一つを分析してみましょう。試合データには、2009 年以降のプレイバイプレイとボックススコアが含まれます。ここでは、2014 年シーズン以降のケンタッキー ワイルドキャッツとノートルダム ファイティング アイリッシュの試合について見てみます。この試合は、最終局面で手に汗を握る展開となりましたが、そのような劇的な内容となった要因を探ります。
BigQuery サンドボックスで、一般公開データセットから NCAA バスケットボール データセットを開きます。[データセットを表示] ボタンをクリックして、BigQuery ウェブ UI でデータセットを開きます。
ncaa_basketball にあるテーブル mbb_pbp_sr に移動してスキーマを確認します。このテーブルには、2013 年から 2014 年のシーズンにかけての、男子の全試合のプレイバイプレイ情報が格納されており、テーブルの各行は試合中の 1 つのイベントを表しています。
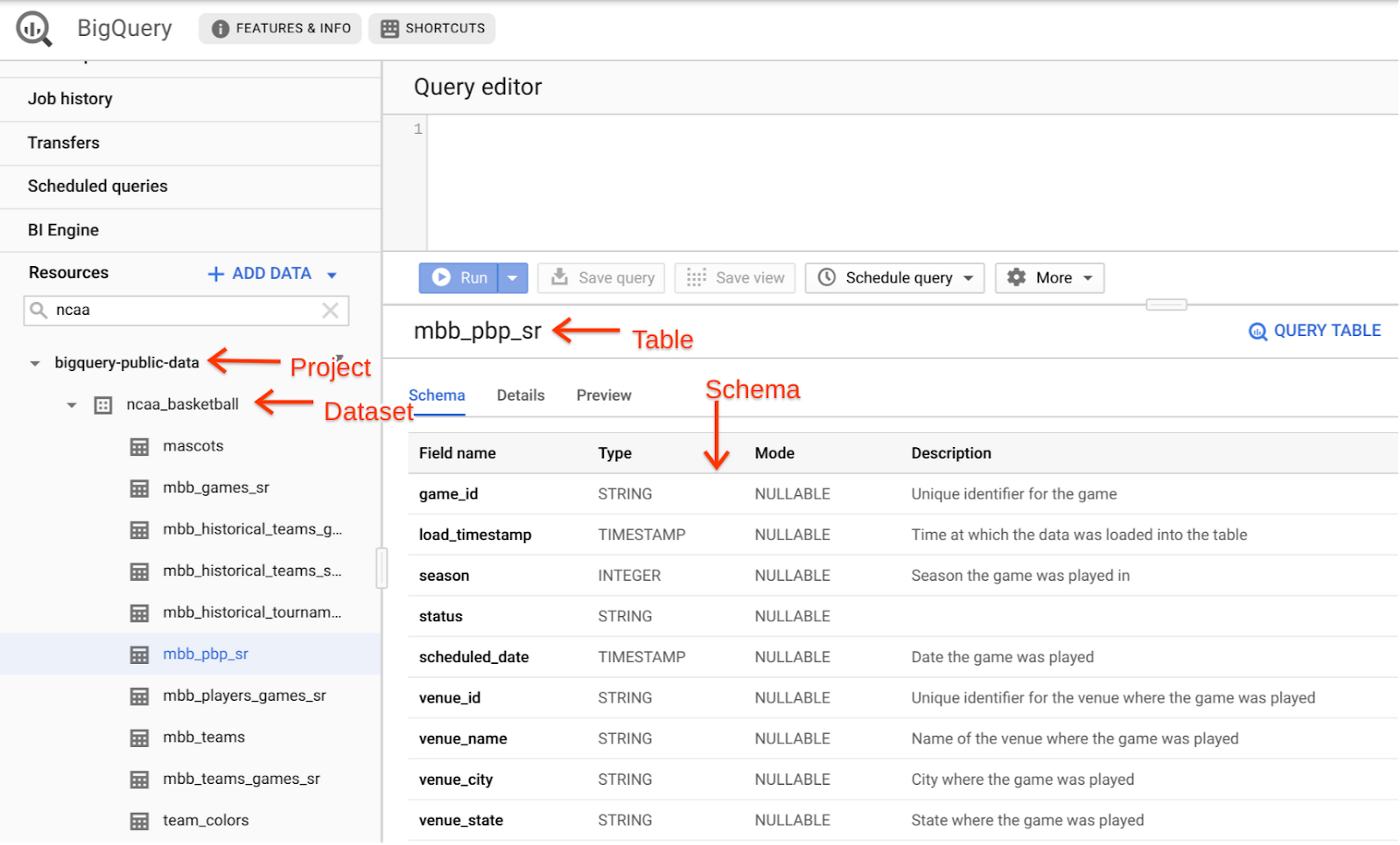
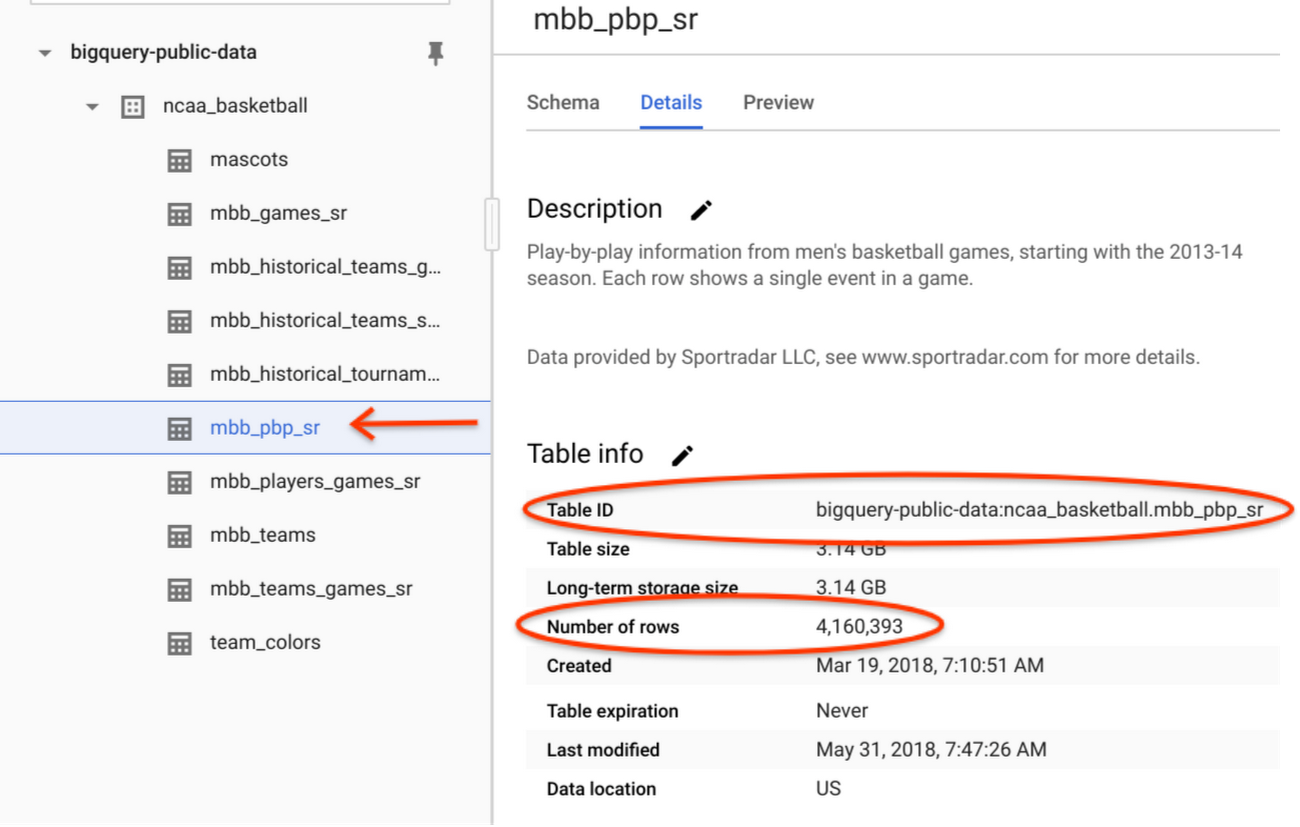
テーブル mbb_pbp_sr の詳細セクションを確認します。400 万件もの試合イベントが存在し、合計容量は 3 GB に達しています。
クエリを実行してフィルタを適用し、注目すべき試合のイベントを抽出してみましょう。クエリによって mbb_pbp_sr テーブルの以下の列が選択されます。
game_clock: 試合終了までの残り時間
points_scored: イベントで獲得された得点
team_name: 得点を挙げたチームの名前
event_description: イベントについての説明
timestamp: イベントが発生した時刻
このクエリの実行内容の詳細:
SELECT ステートメントはテーブルから(FROM)、行と指定された列を取得します。
WHERE 句は SELECT によって返された行をフィルタします。このクエリがフィルタを適用して、注目すべき試合の行を返します。
ORDER BY ステートメントによって結果セット内の行の順序が制御されます。このクエリは、SELECT によって取得した行をタイムスタンプで降順に並べ替えます。
最後に、LIMIT によってクエリから返されるデータ量が制御されます。このクエリは、行が並べ替えられた後に結果セットから 10 件のイベントを返します。LIMIT を追加しても、クエリエンジンによって処理されるデータ量は減少しません。
次に結果を見てみましょう。
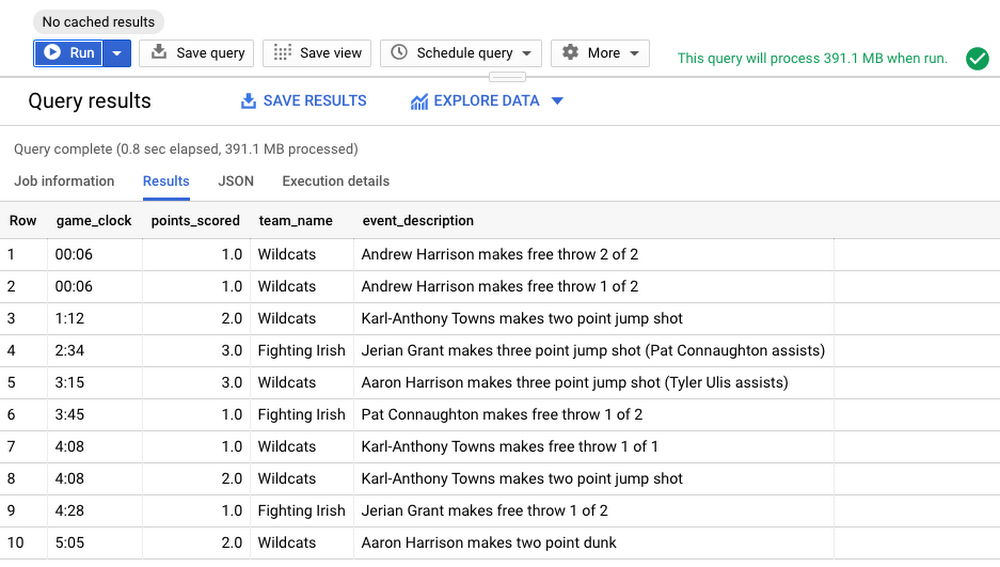
結果からは、試合の残り時間わずか 6 秒の時点で Andrew Harrison 選手がフリースローを決め、2 得点を挙げたことがわかります。ただし、試合の最終盤で得点された以外のことはわかりません。
ヒント: SELECT * の使用はクエリでは避け、必要な列のみをクエリします。特定の列だけを除外するには、SELECT * EXCEPT を使用します。
分析(ウィンドウ)関数を使用して、イベント時間ごとに各チームの累計得点が含まれるようクエリを変更しましょう。集計関数では、行のグループに対して算出される集計値は 1 つですが、分析関数の場合、ウィンドウによって定義された行のグループに対して、行ごとに集計値が算出されます。
wildcats_score と fighting_irish_score という 2 行を新たに追加して以下のクエリを実行し、points_scored 列を使用して同時に算出します。
このクエリの実行内容の詳細:
試合での各チームの得点の累計を算出(SUM)します。試合は CASE ステートメントで指定します。
OVER 句で定義されたウィンドウ内の得点の合計を算出(SUM)します。
OVER 句はウィンドウ(行のグループ)を参照して合計を算出します(SUM)。
ORDER BY は、パーティション内での並べ替え順を定義するウィンドウ指定の一部です。このクエリでは、行の並べ替えをタイムスタンプ順で行います(timestamp)。
UNBOUNDED PRECEDING で試合の開始時刻を指定し、CURRENT ROW までをウィンドウ フレームとして定めます。この範囲を対象として分析関数 SUM() が評価されます。
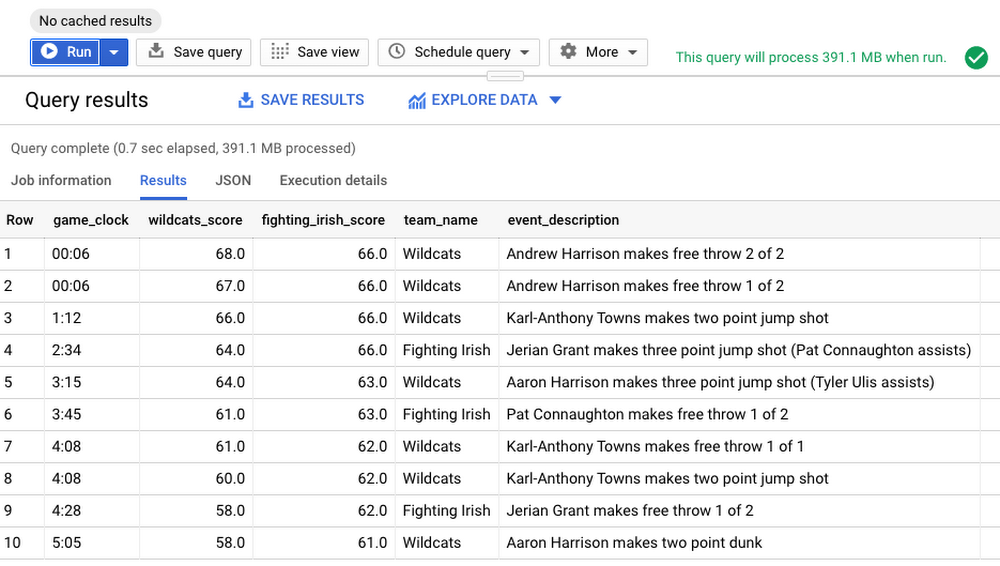
結果から、試合の最終盤の展開が確認できます。ファイティング アイリッシュは、残り時間 4 分 28 秒の時点で 4 点リードしていました。ワイルドキャッツの Karl-Anthony Towns 選手が残り時間 1 分 12 秒でレイアップ シュートを決めて試合を同点に持ち込み、残り 6 秒で Andrew Harrison 選手が 2 本のフリースローでワイルドキャッツの勝利を決定付けました。まさに劇的な結末です。
BigQuery は、集計関数と分析関数に加え、以下に示す文字列操作関数、日付 / 時間関数、算術演算関数、JSON 抽出などの関数と演算子もサポートしています。
すべての関数の一覧については、BigQuery SQL 関数のリファレンスを参照してください。近日公開予定の投稿では、ユーザー定義関数や空間関数など、BigQuery におけるその他の高度なクエリ機能について紹介します。
BigQuery SQL クエリのライフサイクル
SQL クエリの実行時には、内部で次の処理が行なわれています。
クエリジョブが BigQuery サービスに送信されます。BigQuery アーキテクチャで確認したように、BigQuery のコンピューティングは、BigQuery ストレージから切り離されており、連携して動作することにより膨大な量のデータセットに対して、効率的にクエリを実行できるようにデータを整理することを目的として設計されています。
実行された各クエリはいくつかのステージに分割された後、ワーカー(スロット)によって処理され、シャッフルのために書き戻されます。シャッフルにより、クエリの処理中に発生した問題など、ワーカー自体の内部で発生した障害から復旧できるようになります。
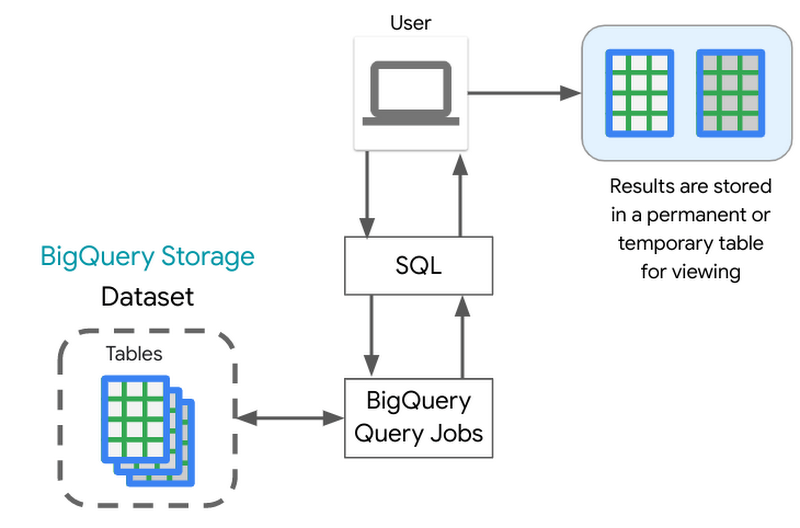
BigQuery エンジンは BigQuery のカラム型ストレージ形式を利用して、クエリの実行に必要な列のみをスキャンします。費用を管理するうえでおすすめの方法は、必要とする列のみをクエリすることです。
クエリの実行が完了すると、クエリサービスは結果を一時テーブルに保持し、そのデータがウェブ UI に表示されます。永続テーブルへの結果の書き込みをリクエストすることもできます。
クエリの保存と共有
クエリの保存
ここまでで SQL クエリを実行して分析を実施できるようになりましたが、結果はどのようにして保存すればよいでしょうか。BigQuery はすべてのクエリ結果をテーブルに書き込みます。テーブルは、ユーザーが宛先テーブルとして明示的に指定したテーブル、または一時的なキャッシュ結果テーブルのいずれかです。この一時テーブルは 24 時間保存されるため、まったく同一のクエリ(文字列が完全に同じ)を再度実行して同じ結果となる場合には、BigQuery はキャッシュに保存されている結果へのポインタを返します。キャッシュからレスポンスを返すクエリに関して、料金は発生しません。クエリのキャッシュ保存に関する制限と例外の詳細については、ドキュメントをご覧ください。
キャッシュに保存されたクエリ結果は、BigQuery UI のクエリ履歴タブで確認できます。この履歴には、ウェブ UI を介して送信されたクエリだけでなく、ユーザーによってサービスに送信されたすべてのクエリが含まれます。
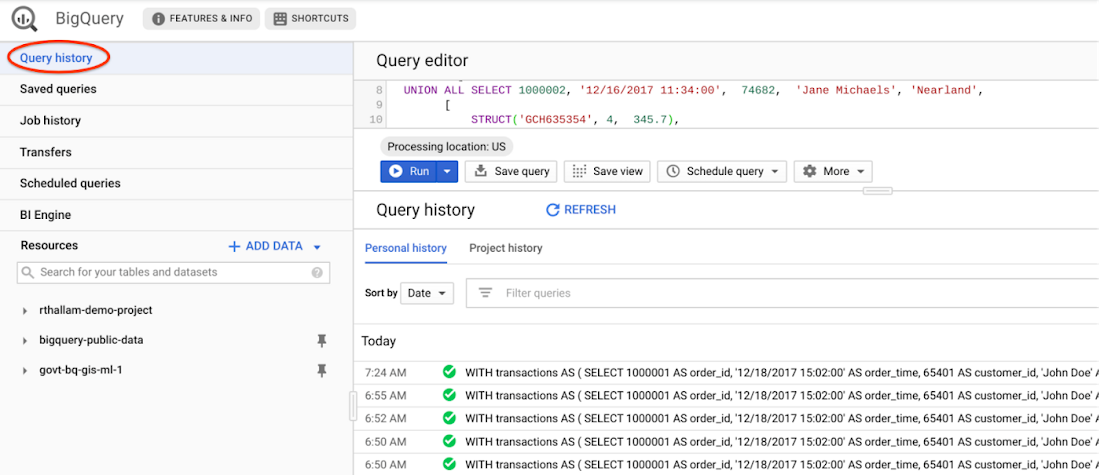
クエリの実行時にキャッシュに保存された結果を取得する機能は、クエリ設定で無効にすることができます。この場合、BigQuery がクエリ結果について演算を行う必要があり、クエリの実行に対して料金が発生します。以前の投稿でも触れたように、このような設定は、テーブルのパーティション分割やクラスタ化を行う場合と、パーティション分割を行わない場合のパフォーマンスを比較するベンチマークなどで使用します。
クエリ結果の宛先テーブルへの書き込みをリクエストすることもできます。テーブルが削除されるタイミングも管理可能です。宛先テーブルは永続テーブルであるため、結果が保存される際に料金が発生します。
クエリの共有
BigQuery を使用すると他のユーザーとクエリを共有できます。クエリを保存する際には、非公開(自分にのみ表示可能)、プロジェクト レベルで共有(プロジェクト メンバーに表示可能)、一般公開(任意のユーザーに表示可能)のいずれかを選択できます。
BigQuery でクエリを保存して共有する方法については、こちらの動画を確認してください。

標準ビュー
ビューは SQL クエリによって定義される仮想テーブルです。ビューにはテーブルと同様のプロパティを設定でき、テーブルとしてクエリ可能です。ビューのスキーマは、クエリの実行によって生成されるスキーマです。ビューのクエリ結果には、ビューを定義するクエリで指定されたテーブルとフィールドのデータのみが含まれます。
[ビューを保存] ボタン、または BigQuery DDL の CREATE VIEWステートメントを使用して、BigQuery UI からクエリを保存することでビューを作成できます。クエリをビューとして保存すると一時テーブルにキャッシュとして保存されますが、結果は保持されません。一時テーブルの有効期限は 24 時間です。この動作はテーブルで実行されるクエリの動作と類似しています。
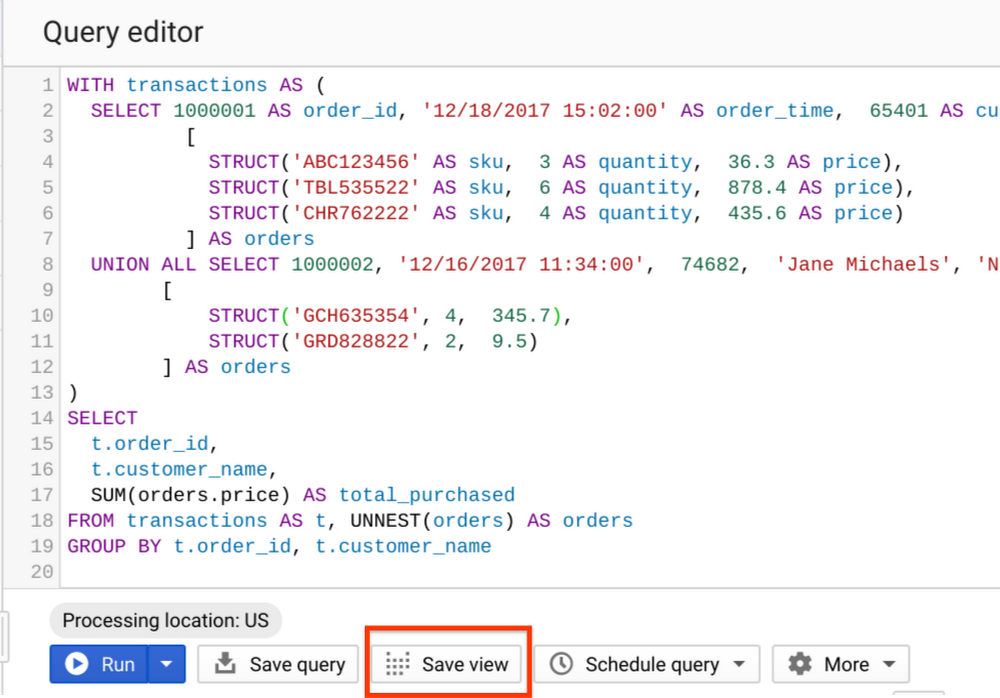
標準ビューを使用すべき場合
複雑なロジックを使用するクエリをユーザーに公開するが、ユーザーがロジックを都度確認する必要がないようにする場合。このようなユースケースでは、クエリをビューに組み込みます。
元のテーブルへのアクセス権を付与することなく、特定のユーザーおよびグループとデータセットを共有する場合。このようなユースケースでは、ビューをデータセットに配置し、詳細なアクセス制御を行います。このようなビューは、承認済みビューと呼ばれます。データセットへのアクセスと保護の詳細については、別の投稿で説明する予定です。
標準ビューの作成と管理については、BigQuery のドキュメントをご覧ください。
マテリアライズド ビュー
BigQuery は、ベータ版の機能であるマテリアライズド ビュー(MV)をサポートしています。MV は、クエリ結果をキャッシュとして定期的に保存して表示するビューです。表示データが算出済みであるため、パフォーマンスと効率を改善するというメリットがあります。一般的に MV を使用するクエリは高速で、同一のデータをベーステーブルのみから取得する場合と比較して消費するリソース量が少なくなります。一般的なクエリを繰り返し実行するようなワークロードでは、大幅なパフォーマンスの向上が見込めます。
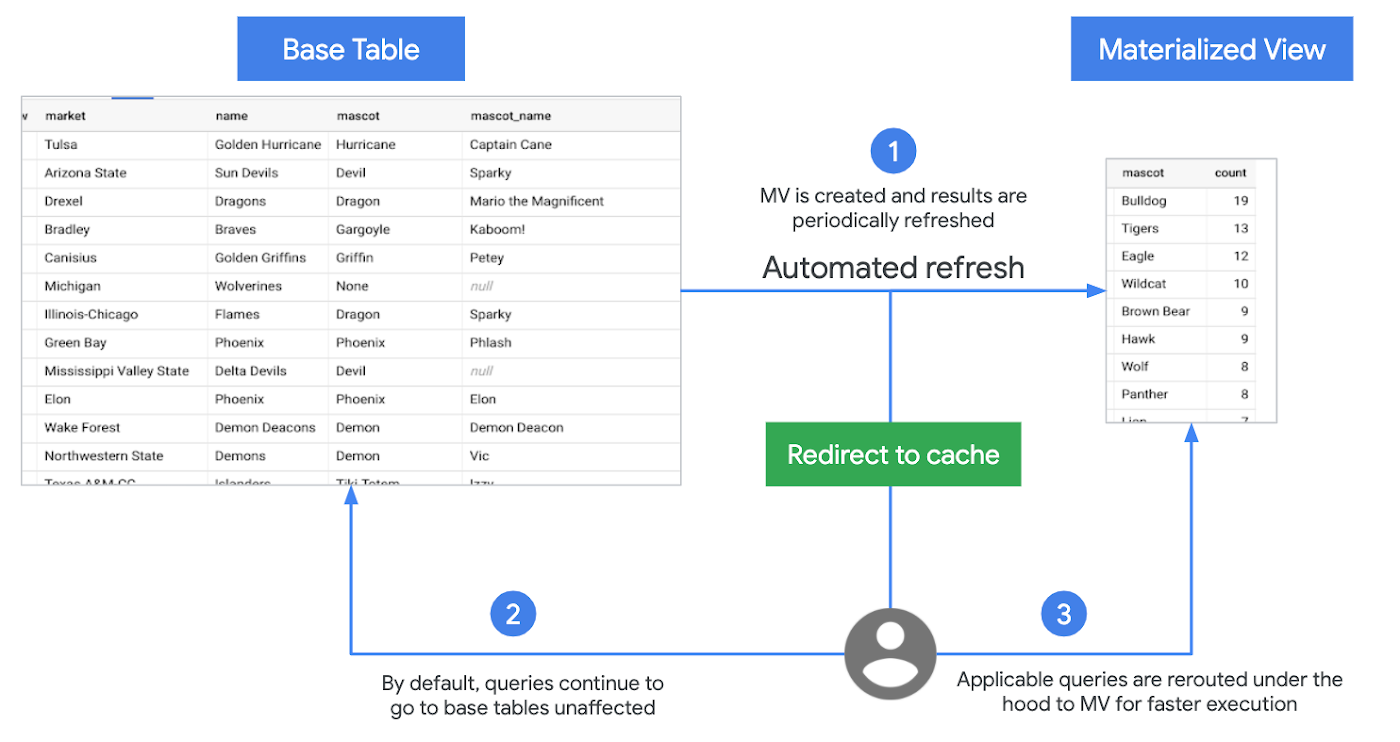
マテリアライズド ビューの主な特長を以下に示します。
メンテナンス不要
BigQuery は、事前に算出された MV の結果を利用し、可能な場合にはベーステーブルからの差分のみを読み取って最新の結果を算出します。自動的にベーステーブルでのデータ変更を同期してデータを更新します。ユーザー入力は不要です。ビューの手動更新をトリガーして、更新ジョブの費用を管理することもできます。
常に最新
MV は常にソーステーブルとの整合性を維持します。直接クエリを処理することもできますが、BigQuery オプティマイザーで使用してベーステーブルに対するクエリを処理することも可能です。
スマートな調整
MV はクエリの書き換えをサポートします。ソーステーブルに対するクエリが MV へのクエリで代替できる場合には、BigQuery は MV へのクエリの書き換え(再ルーティング)を行って、パフォーマンスと効率性を向上させます。
MV は、BigQuery DDL の CREATE MATERIALIZED VIEW ステートメントを使用して作成します。
マテリアライズド ビューを使用すべき場合
MV は、最新データをクエリで取得しながら、算出済みの結果を再利用してレイテンシとコストを抑える必要がある場合に適しています。MV は疑似インデックスとして動作し、既存のワークフローを更新することなくベーステーブルに対するクエリを高速化できます。
マテリアライズド ビューの制限事項
この投稿の執筆時点で、結合は MV でサポートされていません。ただし、結合に加えて集計を行うクエリには MV を利用でき、クエリの費用とレイテンシの低減が可能です。
MV は一部の集計関数と制限された SQL にのみ対応しています。マテリアライズド ビューによってサポートされているクエリパターンを参照してください。
マテリアライズド ビューの操作とベスト プラクティスについては、BigQuery のドキュメントをご覧ください。
次のステップ
今回の投稿では、BigQuery での SQL クエリのライフサイクル、ウィンドウ関数の操作方法、標準ビューとマテリアライズド ビューの作成方法、クエリの保存と共有方法について確認しました。
参考資料
BigQuery 関数リファレンス
BigQuery での分析(ウィンドウ)関数
BigQuery の標準ビュー [ドキュメント]
BigQuery のマテリアライズド ビュー [ドキュメント]
BigQuery のクエリ パフォーマンスに関するベスト プラクティス
Codelab
この Codelab では、GitHub のアーカイブをベースとして大規模な一般公開データセットに対してクエリを実行します。
次回の投稿では、ネストされた繰り返し構造での結合、結合パターンの最適化、データの非正規化について詳しく説明します。
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットをご希望の場合は、Twitter または LinkedIn でアクセスしてください。
この投稿に協力してくれた Yuri Grinshsteyn と Alicia Williams に感謝します。
-Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam



