[新しいブログシリーズ] BigQuery 特集: 概要
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
2011 年に一般提供が開始された Google BigQuery は、ビジネスのアジリティを高めるように設計された、Google Cloud のエンタープライズ データ ウェアハウスです。そのサーバーレス アーキテクチャは、大規模かつ高速な動作を可能にし、大量のデータセットに対して驚くべき速度で SQL 解析を実行できます。提供開始以来、パフォーマンス、セキュリティ、信頼性を高めるために数多くの機能や改善が追加され、より簡単に分析情報を得ることができるようになっています。
この最初の投稿では、データ ウェアハウスによってビジネス上の意思決定を変える方法、従来のデータ ウェアハウスの問題を BigQuery で解決する方法、BigQuery アーキテクチャの概要、そして BigQuery をすぐに使い始める方法について説明します。
データ ウェアハウスをビジネス上の意思決定に活かす方法
データ ウェアハウスは、異なるソースからのデータを統合し、集計データに対する分析を行い、分析情報を提供することで、事業運営に付加価値をもたらします。データ ウェアハウスは過去 20 年間、企業における特に重要なビジネスデータを管理してきました。企業がますますデータドリブンになるにつれ、データ ウェアハウスはデジタル変革に向けた取り組みにおいて、ますます重要な役割を担うようになっています。Gartner によると、データ ウェアハウスは多くの場合、企業の分析戦略の基盤となっています。データ ウェアハウスのユースケースは、従来の運用レポートにとどまるものではなくなっています。今日の企業には次のことが求められます。
ビジネスにおいて全方位の視野を持つ: データは貴重です。ストレージやデータ処理の費用の低下に伴い、企業は関連するすべてのデータセット(組織の内部と外部のデータセット)を処理、保存、分析することを望んでいます。
状況に応じて、リアルタイムのビジネス イベントを認識して対応する: 企業はリアルタイムのイベントから分析情報を得て、数日、数週間かけることなく、データを分析する必要があります。データ ウェアハウスは常に、ビジネスの現在の状況を反映している必要があります。
情報分析の時間を短縮する: 企業は、ハードウェアやソフトウェアのインストールや構成に数日、数か月かけることなく、すぐに稼働させる必要があります。
ビジネス ユーザーが分析情報を使用できるようにして、企業全体でデータドリブンな意思決定を可能にする: データドリブンな社風を取り入れるには、誰もがデータにアクセスできるようにする必要があります。
データを保護し、その使用を管理する: データを保護し、企業内外の適切な関係者がデータにアクセスできるようにする必要があります。
増加するデータ容量に対処するために従来のデータ ウェアハウスを使い続けると、TCO(総所有コスト)の増加により費用が手に負えなくなるため、企業は大きな困難に直面します。従来のデータ ウェアハウスは、データの急激な増加や新たなデータ処理パターンに対応できるように設計されていません。
BigQuery - クラウド データ ウェアハウス
Google BigQuery は、クラウドネイティブのデータ ウェアハウスとして設計されています。クラウド ファーストの世界において、データドリブンな組織のニーズに応えるために構築されています。
BigQuery は、サーバーレスでスケーラビリティと費用対効果に優れた、GCP のクラウド データ ウェアハウスです。Google のインフラストラクチャの処理能力を利用して、ペタバイト規模のクエリを超高速で実行できます。インフラストラクチャの管理が不要なため、有意義なインサイトを見つける作業に集中できます。また、データベースの操作には使い慣れた SQL を使用できるほか、データベース管理者も必要ありません。また、利用した処理とストレージの分のみ課金されるため経済的です。
データ ライフサイクルにおける BigQuery の位置付け
BigQuery は、データの取り込みから処理、格納、高度な分析、コラボレーションまでの分析バリュー チェーンをカバーする、包括的な Google Cloud データ分析プラットフォームの構成プロダクトです。BigQuery は GCP の分析サービスやデータ処理サービスと緊密に統合されているため、お客様はエンタープライズ対応のクラウドネイティブ データ ウェアハウスを設定できます。
データ ライフサイクルの各段階で、GCP はデータを管理するための複数のサービスを提供します。その中から、使用する一連のサービスをデータとワークロードに合わせて選択できます。

BigQuery へのデータの取り込み
BigQuery では、管理するストレージにデータを取り込むためにいくつかの方法がサポートされています。具体的な取り込み方法は、データのオリジンによって異なります。たとえば、GCP の一部のデータソース(Cloud Logging や Google Analytics など)は、BigQuery に直接エクスポートできます。
BigQuery Data Transfer Service は、Google SaaS アプリ(Google 広告、Cloud Storage)、Amazon S3、その他のデータ ウェアハウス(Teradata、Redshift)から BigQuery へのデータ転送を可能にします。
ストリーミング データ(ログや IoT デバイスデータなど)は Cloud Dataflow パイプライン、Cloud Dataproc ジョブを使用するか、BigQuery のストリーム取り込み API を直接使用して、BigQuery に書き込むことができます。
BigQuery アーキテクチャ
BigQuery のサーバーレス アーキテクチャでは、ストレージとコンピューティングが分離しているので、それぞれオンデマンドでスケールできます。この構造により、高額なコンピューティング リソースを常に稼働する必要がなくなるため、優れた柔軟性を実現し、経費も抑えることができます。従来のノードベースのクラウド データ ウェアハウス ソリューションやオンプレミスの超並列処理(MPP)システムとは非常に異なるアプローチです。このアプローチを使用すると、データベースの運用やシステム エンジニアリングを気にすることなく、あらゆる規模のお客様がデータ ウェアハウスにデータを取り込み、標準 SQL を使用してデータを分析できます。
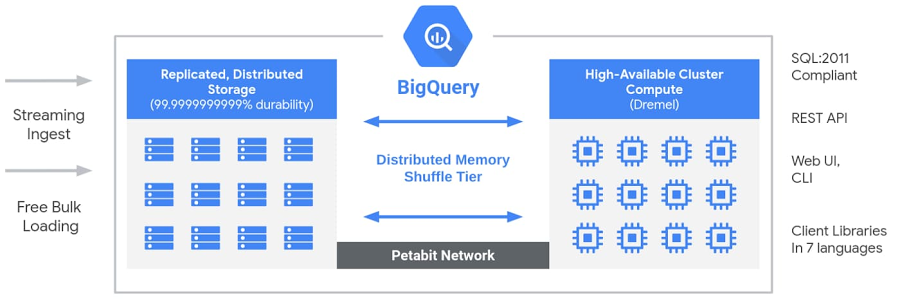
BigQuery の内部では、低レベルの Google インフラストラクチャ テクノロジー(Dremel、Colossus、Jupiter、Borg など)によって実現する、さまざまなマルチテナント サービスが採用されています。
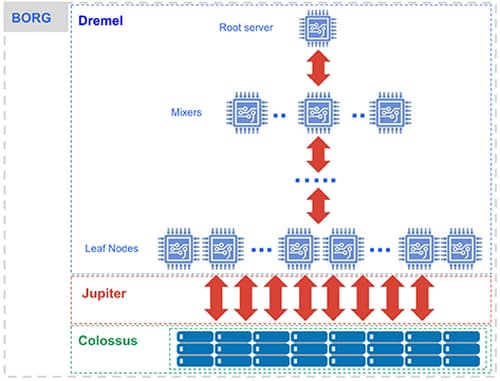
BigQuery: 仕組み [ソース]
コンピューティングを担う Dremel(SQL クエリを実行する大規模なマルチテナント クラスタ)。
Dremel は、SQL クエリを実行ツリーに変換します。ツリーのリーフはスロットと呼ばれ、ストレージからデータを読み込むという手間のかかる処理と必要な計算を行います。ツリーのブランチは、集計を行うミキサーの役割を担います。
Dremel は、必要に応じてスロットをクエリに動的に割り当て、複数のユーザーからの同時実行クエリに対する公平性を保ちます。1 人のユーザーが数千のスロットを取得してクエリを実行できます。
ストレージを担う Colossus(Google のグローバル ストレージ システム)。
BigQuery は、カラム型ストレージ形式と圧縮アルゴリズムを利用して、大規模な構造化データの読み込み用に最適化された Colossus にデータを格納します。
Colossus はレプリケーションや(ディスク クラッシュ時の)復元のほか、分散型管理も行います(そのため単一障害点がありません)。Colossus を使用すると、BigQuery ユーザーは保存データを数十ペタバイトまでシームレスにスケールできます。従来のデータ ウェアハウスのように高額なコンピューティング リソースに接続するといったコストをかける必要もありません。
ペタビット規模の Jupiter ネットワークを介したコンピューティングとストレージの相互通信。
ストレージとコンピューティングの間では「シャッフル」が行われます。これは、Google の Jupiter ネットワークを活かして、極めて高速にデータを移動するものです。
BigQuery のオーケストレーションを担う Borg(Google による Kubernetes の前身)。
ミキサーとスロットはすべて Borg により実行されます。Borg は、ハードウェア リソースを割り振ります。
Google では、これらのテクノロジーを継続的に改善していることを強調しています。BigQuery ユーザーは、ダウンタイムや従来のテクノロジーに関連するアップグレードなしで、パフォーマンス、耐久性、効率性、スケーラビリティの継続的な改善から恩恵を受けます。BigQuery アーキテクチャについて詳しくは、こちらの記事で詳細なトポロジの図をご覧ください。
BigQuery を使い始める方法
BigQuery は、データを読み込んで SQL コマンドを実行するだけで、使い始めることができます。クラスタのビルド、デプロイ、プロビジョニングは必要ありません。VM、ストレージ、ハードウェア リソースのサイズ設定も必要ありません。ディスクの設定、レプリケーションの定義、圧縮と暗号化の構成、従来のデータ ウェアハウスの構築に必要な設定や構成の作業も必要ありません。
BigQuery を使い始めるときに役立つ BigQuery サンドボックス を使用すると、BigQuery の機能に自由にアクセスできます。毎月 10 GB のストレージと 1 TB のクエリデータの分析が無料で提供されます。BigQuery サンドボックスを設定して無料でクエリを実行する方法を確認するには、BigQuery Spotlight のこちらのエピソードをご覧ください。

BigQuery にアクセスする方法は複数あります。
GCP Console を使用する
コマンドライン ツール bq を使用する
BigQuery REST API を呼び出す
各種クライアント ライブラリ(Java、.NET、Python など)を使用する
早速試してみましょう。Google Cloud Console の BigQuery ウェブ UI に移動し、次のクエリをコピーして貼り付けてから、[実行] ボタンを押します。
このクエリは、BigQuery の一般公開データセットで 2008 年から 2016 年までの約 30 GB の StackOverflow の投稿を処理して、少なくとも 1 つの回答が投稿された投稿の数を特定し、年と月の単位でグループ化します。
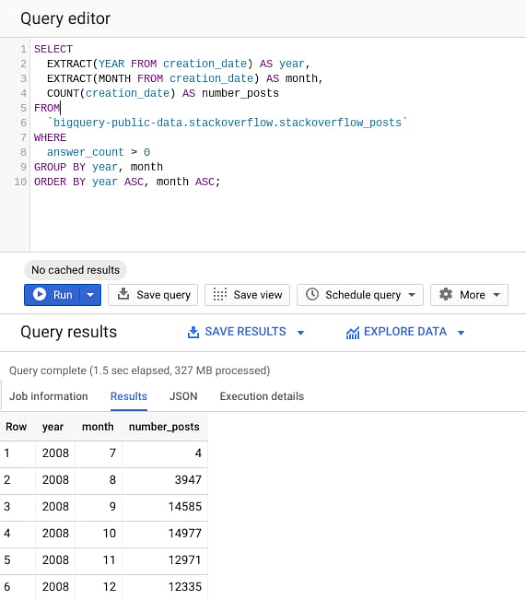
クエリ結果からわかるように、28GB のデータを分析して結果を返すのにかかった時間は 2 秒未満です。BigQuery エンジンは、クエリを実行する必要がある列のみを読み込み、全体で 28GB のデータセットから 327MB のデータのみを処理しています。
ユーザーは数十ペタバイトまでシームレスにスケールできます。これは、BigQuery エンジニアがこのスケーリングに見合ったリソースをすでにデプロイしているからです。したがって、スケーリングは、より大規模なクラスタをプロビジョニングするのではなく、単に BigQuery をさらに使用することを意味します。もちろん、ベスト プラクティスや使用量の割り当てに留意する必要があります。これについては、このシリーズの今後の投稿で取り上げます。
大規模なデータセットでの BigQuery の使用
実際に大規模なデータセットを使用した BigQuery のデモについては、Jordan Tigani による こちらの講演をご覧ください。BigQuery で約 1 PB のデータセットを数秒で分析します。また、BigQuery のパフォーマンスを高めるために長年にわたり行われた改善についても示します。

次のステップ
この記事では、データ ライフサイクルにおける BigQuery の位置付け、BigQuery が高速でスケーラブルな理由、BigQuery の使い方について確認しました。
BigQuery を使用して GitHub データのクエリを実行するには、BigQuery サンドボックスでこちらの Codelab をお試しください。
このシリーズの今後の投稿では、BigQuery のストレージと取り込みのオプション、基本的なクエリと高度なクエリ、クエリ結果の可視化、データの保護、費用の管理、最適化とパフォーマンスのための BigQuery のベスト プラクティスのほか、BigQuery の新機能についても説明します。
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットを希望する場合は、Twitter または LinkedIn でアクセスしてください。
この投稿に協力してくれた Yuri Grinshsteyn と Alicia Williams に感謝します。
-Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam