BigQuery 特集: データの取り込み
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
前回の BigQuery 特集シリーズでは、ストレージ アーキテクチャとコンピューティング アーキテクチャを分離することが、BigQuery をシームレスにスケールするうえでどのように役立つかについて説明しました。また、クエリ パフォーマンスの向上と費用の最適化を目的とする BigQuery のストレージ管理や、テーブルのパーティショニングとクラスタリングについて説明しました。これまでのところでは、BigQuery 内にすでに存在するデータセットのみを対象にクエリを実行または使用してきましたが、この投稿では、BigQuery にデータを読み込むまたは取り込む方法、そのデータを分析する方法について説明します。では、詳しく見てみましょう。
まずは、BigQuery にデータを読み込むことと、BigQuery にデータを読み込まずに外部データソースに対して直接クエリを実行することの違いについて見てみましょう。
直接インポート(マネージド テーブル): さまざまな形式のデータセットを BigQuery のネイティブ ストレージに直接取り込むことができます。BigQuery のネイティブ ストレージは Google により完全に管理されます。これには、レプリケーション、バックアップ、サイズのスケールアウトなどが含まれます。
読み込まずにクエリを実行(外部テーブル): BigQuery ストレージにデータを読み込まずに外部データソースを直接クエリするには、連携クエリを使用することなどが考えられます。BigQuery にデータをインポートせずに、Google スプレッドシート、Google ドライブ、Google Cloud Storage、Cloud SQL、Cloud Bigtable などの Google サービスに対してクエリを実行できます。
主な相違点の一つとして、外部データソースに対するクエリ パフォーマンスが、ネイティブの BigQuery テーブルのデータに対するクエリの場合と等しくならない可能性がある点が挙げられます。クエリ速度を優先する場合は、データを BigQuery に読み込んでください。連携クエリのパフォーマンスは、実際にデータを保持している外部ストレージ エンジンのパフォーマンスに依存します。
BigQuery へのデータの読み込み
BigQuery にデータを読み込む方法は複数あり、データソース、データ形式、読み込み方法、ユースケース(バッチ、ストリーミング、データ移転など)に応じて使い分けることができます。BigQuery にデータを取り込む方法は大まかに以下のとおりです。
バッチ取り込み
ストリーミング取り込み
Data Transfer Service(DTS)
クエリの実体化
パートナーとの統合
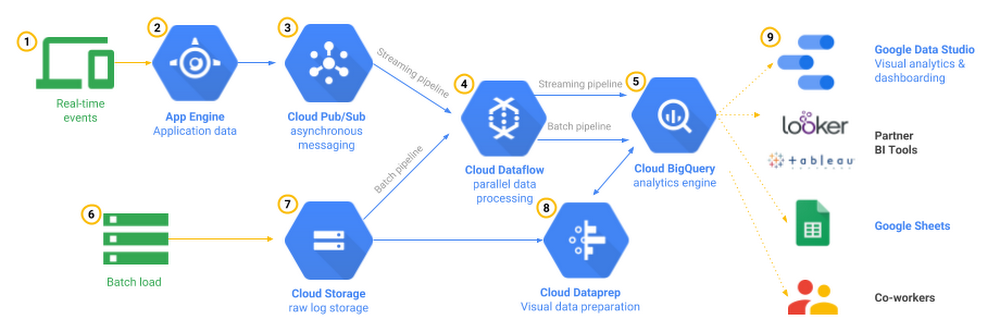
以下に掲載するのは、データを BigQuery に取り込むためのオプションを示すクイックマップです(完全な一覧ではありません)。
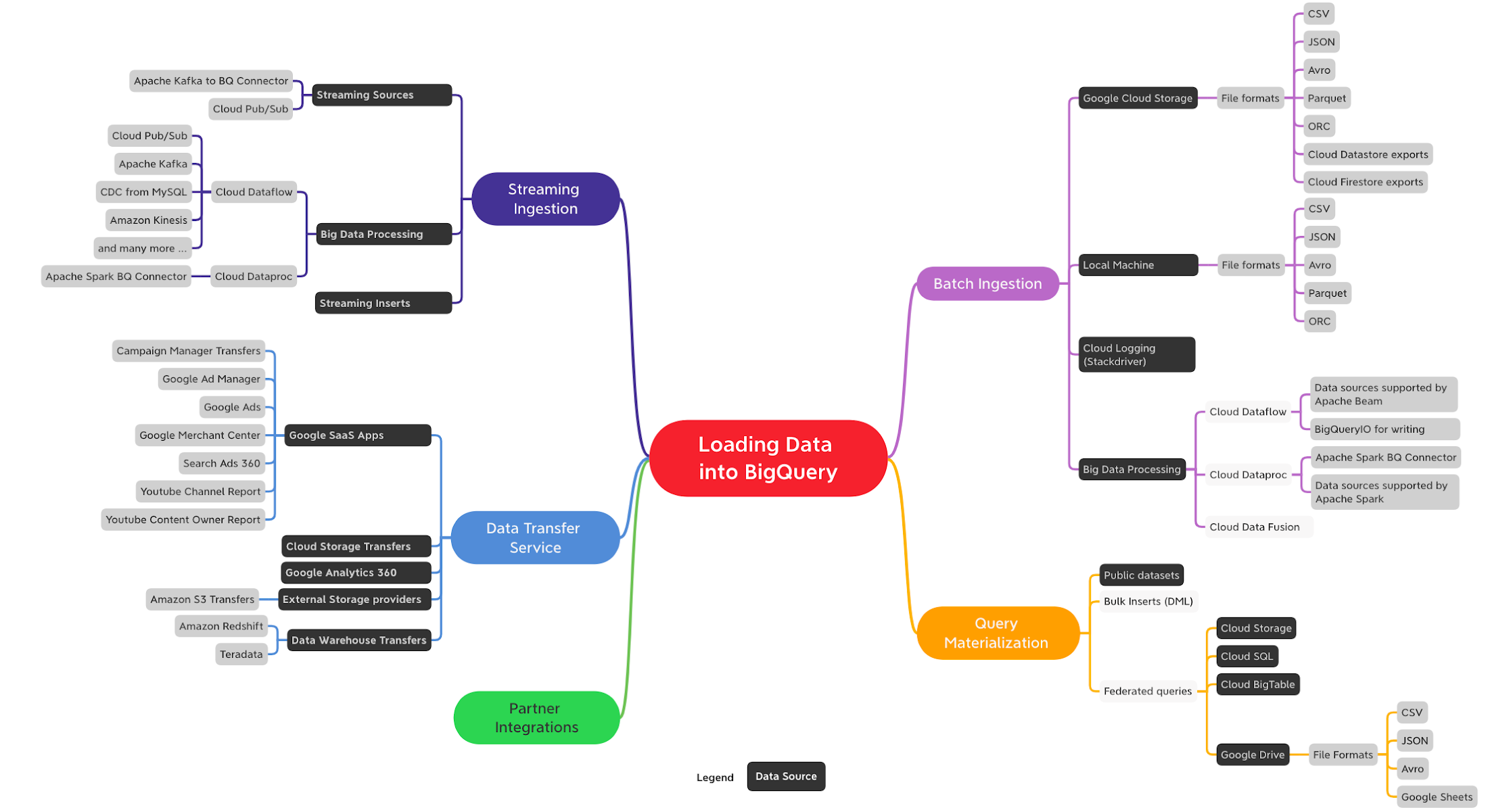
BigQuery へのデータの読み込み(ここをクリックすると高解像度画像を表示できます)

この投稿では、バッチ取り込みについて詳細に説明するほか、他の取り込み方法についても概説します。他の取り込み方法の詳細については、今後のブログ投稿で個別に特集します。
バッチ取り込み
バッチ取り込みでは、リアルタイムで処理する必要のない、大容量の有界データセットを読み込みます。データは通常、特定の頻度で定期的に取り込まれます。結果は、すべてのデータが一度に取り込まれるか、まったく取り込まれないかのいずれかになります。取り込まれたデータをクエリしてレポートを作成する、またはリアルタイム データなどの他のソースと組み合わせて使用することができます。
BigQuery のバッチ読み込みジョブは無料です。データの保存とクエリに対してのみ料金が発生します。データの読み込みに関する料金は発生しません。
バッチ取り込みを使用する場合、読み込むデータの保存場所として Cloud Storage を使用することをおすすめします。Cloud Storage は永続的で、可用性が高く、コスト効率の良いオブジェクト ストレージ サービスです。Cloud Storage から BigQuery へのデータの読み込みでは、複数のファイル形式(CSV、JSON、Avro、Parquet、ORC)がサポートされます。
圧縮ファイルと非圧縮ファイルのどちらを読み込むか
Cloud Storage から BigQuery へのデータの読み込みでは、圧縮(GZIP)ファイルと非圧縮ファイルの両方を読み込めます。高度に並列化された読み込みオペレーションにより、非圧縮ファイルを圧縮ファイルより格段に速く読み込めます。非圧縮ファイルはサイズが大きいことから帯域幅の上限に達し、保存に伴う費用が増大する可能性があります。一方、圧縮ファイルはより高速な送信が可能であり、保存に要する費用を抑制できますが、BigQuery への読み込み速度の面では劣ります。圧縮オプションについては、ユースケースに基づいて比較検討してください。ネットワーク速度に制約がある場合は、多くのお客様が圧縮ファイルの使用を選択されています。
データ読み込み時のファイル形式の選択
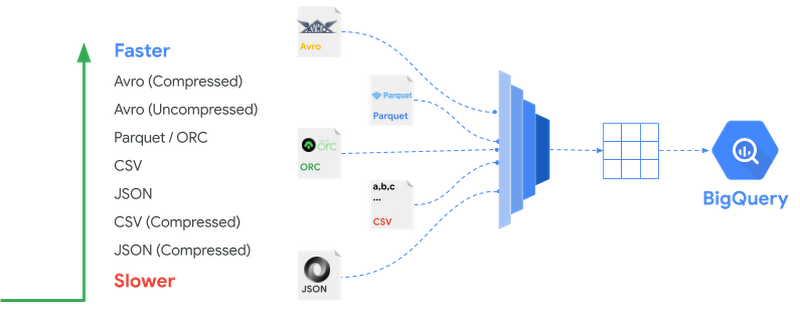
BigQuery はさまざまなファイル形式のデータ取り込みをサポートしていますが、ファイル形式によって取り込み速度は異なります。BigQuery にデータを取り込む際のファイル形式に関する推奨事項は次のとおりです。
読み込み速度を最適化する場合は、Avro ファイル形式の使用をおすすめします。Avro は行ベースのバイナリ形式で、圧縮ファイルを含む複数のスロットに分割して同時に読み取ることができます。
Parquet と ORC は、カラム型のバイナリ形式です。BigQuery にデータを取り込む際にはレコード全体を読み取る必要があります。また、カラム型であるため Avro よりも読み込み速度が低下する傾向があります。
圧縮した CSV と JSON ファイルの読み込みには比較的時間がかかります。圧縮された Gzip ファイルは分割できないため、同時に読み込む前に各圧縮ファイルを解凍する必要があるためです。
次の図は、さまざまなファイル形式を読み込みパフォーマンス順に並べたものです。
読み取り方法
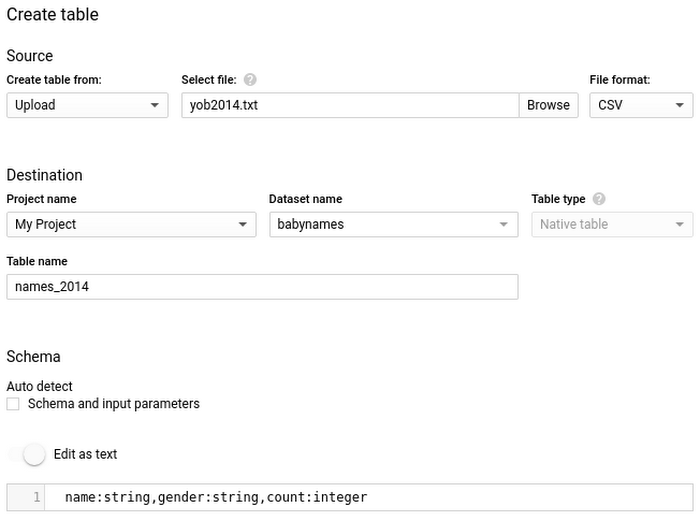
BigQuery にデータを読み込むには、新しいテーブルを作成するか、既存のテーブルに追加または上書きします。テーブル スキーマまたはパーティション スキーマを指定する必要がありますが、サポートされているデータ形式であれば、スキーマの自動検出を使用できます。
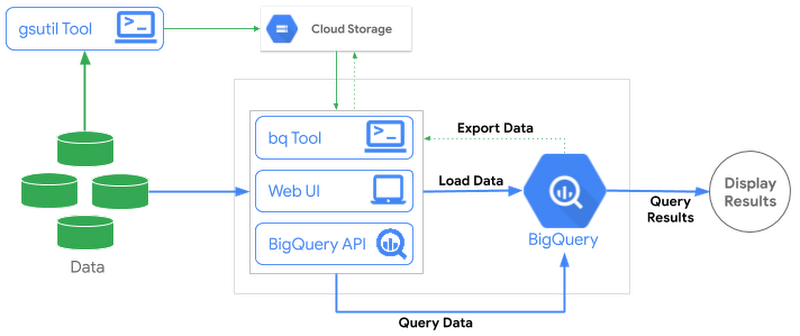
BigQuery には、さまざまなソースから、さまざまな形式のデータを読み込むことができます。Cloud Storage などの Google サービスや、Amazon S3 などの外部ストレージから BigQuery に読み込むことも可能です。複数の異なるデータソースからこれらのバッチファイルを読み込む方法を見てみましょう。
BigQuery UI を使用して読み込む
これまでのように、テーブルの確認やクエリの作成に使うウェブ UI を利用してデータを読み込むこともできます。ローカルマシンや Cloud Storage に読み込めるデータがある場合、ウェブ UI を使用してデータを宛先テーブルに読み込めます。UI でスキーマの自動検出を有効にすることも、明示的に指定することもできます。詳しくは、クイックスタート ガイドをご覧ください。
CLI で bq load を使用する
CLI でデータを BigQuery に読み込むには、 bq load コマンドを使用します。たとえば、Cloud Storage から BigQuery に CSV ファイルをインポートする場合は、Cloud Storage URI か、その CSV ファイルを指す複数の URI のカンマ区切りリストを指定します。CLI では、ウェブ UI の場合と同じオプションがサポートされます。スキーマ検出か手動でのスキーマ指定か、追加か上書きか、ローカルマシンからのファイルの取り込みというオプションをすべて選択できます。
REST API を使用して読み込む
REST API は、Java や Python などのランタイムから BigQuery と通信する際に使用できます。このサービスは、HTTP リクエストを受信して JSON レスポンスを返します。ウェブ UI と CLI はどちらも、この API を使用して BigQuery と通信します。例として、Python API を使用してデータを Cloud Storage から BigQuery テーブルに読み込む場合を見てみましょう。
上記のツールを使用せずに、次のデータ パイプライン オプションを使用して BigQuery にデータを読み込むこともできます。
Dataflow は、オープンソースの Apache Beam API を使用して構築された GCP のフルマネージド サービスで、さまざまなデータソース(ファイル、データベース、メッセージ ベースのソースなど)がサポートされます。Dataflow であれば、同一のコードを使用してバッチモードとストリーミング モードの両方のデータを変換、活用できます。Google は、バッチジョブ用の事前構築済み Dataflow テンプレートを提供しています。
Dataproc は、Apache Spark サービスと Apache Hadoop サービスを実行するための GCP のフルマネージド サービスです。Dataproc が提供する BigQuery コネクタは、Spark アプリケーションと Hadoop アプリケーションが BigQuery から取得したデータを処理し、ネイティブの用語を使用してデータを BigQuery に書き込めるようにします。
データ パイプライン オプションではありませんが、Cloud Logging(旧称: Stackdriver)を使用してログファイルを BigQuery にエクスポートできます。セキュリティとアクセス分析の要件を満たすためにログを BigQuery にエクスポートする方法の詳細とリファレンス ガイドについては、ログビューアによるエクスポートをご覧ください。
バックグラウンド
バックグラウンドでは、BigQuery がマネージド ストレージにファイルを読み込むリクエストを受信すると、次のことが行われます。
エンコード、圧縮、統計: BigQuery は、データ型と値の頻度を分析した後、データを最適にエンコードし、大規模な構造化データの読み取り用に最適化された方法でデータを圧縮します。
シャーディング: データを最適なシャードに分散し、テーブルの定義方法に基づいて、データを特定のパーティション、クラスタに読み込み、データを再クラスタ化します。
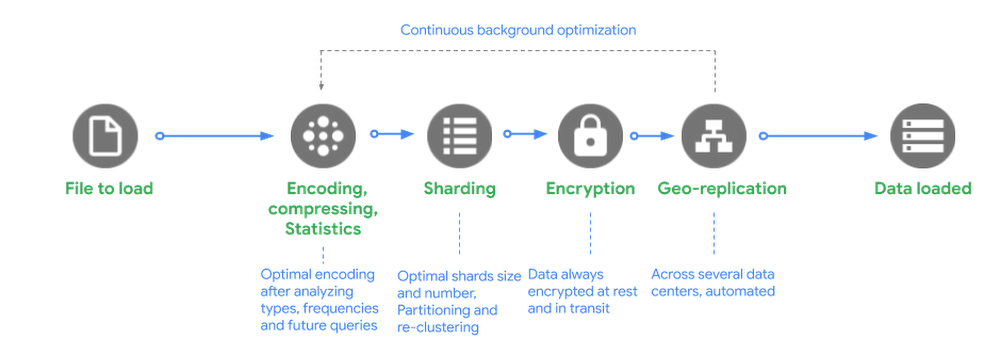
暗号化: BigQuery は、データをディスクに書き込む前に、デフォルトで常にデータを暗号化します。追加で操作を行う必要はありません。データは承認済みのユーザーが読み取りを行う際に、自動的に復号されます。転送中のデータの場合、マシン間でデータが転送されるときに Google データセンター内でデータが暗号化されます。
ジオレプリケーション: BigQuery は、データセットのロケーションをどのように定義したか(リージョン内かマルチリージョンか)に応じて、複数のデータセンターにデータを自動的に複製します。
バックエンドで継続的な最適化がなされるため、BigQuery のユーザーは、ダウンタイムやアップグレードなしで、パフォーマンス、耐久性、効率性、スケーラビリティを継続的に改善できるというメリットを享受できます。
BigQuery 読み込みジョブの主なポイント
バッチ取り込みは無料
読み込みパフォーマンスはベスト エフォート型
データの読み込みで使用されるコンピューティング能力は、共有プールから無料で利用できるものです。BigQuery は、この共有プールのパフォーマンスと使用可能な容量について保証しません。これは、他のユーザーやプロジェクトからの負荷と競合する可能性のある読み込みジョブ間でリソースを割り振るフェア スケジューリングにより管理されます。読み込みジョブの割り当ては、影響を最小限に抑えるために用意されています。
ヒント: 重要性の高い負荷の取り込み速度を保証する必要がある場合は、専用スロットを購入(予約)して、スロットにパイプライン ジョブを割り当てることをおすすめします。予約に関する詳細については、今後のブログ投稿でご確認ください。
読み込みジョブはクエリのキャパシティを使用しない
データのクエリに使用されるスロットは、取り込みに使用されるスロットとは異なります。そのため、データの取り込みはクエリのパフォーマンスに影響しません。
ACID セマンティクス
bq load コマンドで読み込まれたデータの場合、クエリ結果にすべてのデータの存在が反映されるか、まったく反映されないかのいずれかになります。クエリがデータを部分的にスキャンすることはありません。
ストリーミング取り込み
ストリーミング取り込みであれば、ほぼリアルタイムのダッシュボードとクエリを使用して、連続的に取り込まれる大量のデータを分析しなければならないユースケースに対応できます。モバイルアプリのイベントの追跡は、このパターンの一例です。アプリ自体、またはそのアプリのバックエンドをサポートするサーバーで、Cloud Pub/Sub などのイベント取り込みシステムに対するユーザー操作を記録して、Cloud Dataflow などのデータ パイプライン ツールを使って BigQuery にストリーミングできます。また、イベント ボリュームが少ない場合には、Cloud Functions を使用してサーバーレスにすることもできます。管理者はこのデータを分析して、全般的な傾向(インタラクションまたは問題が増加している領域など)を判断し、エラーの状態をリアルタイムにモニタリングすることが可能です。
ストリーミング取り込みで BigQuery にデータを取り込む場合、tabledata.insertAll メソッドを使用して、一度に 1 レコードずつ BigQuery にデータをストリーミングできます。この API を使用すれば、複数のプロデューサーからのデータが統合されていない場合でもその挿入を許可できます。取り込まれたデータは、最初のストリーミング挿入から数秒以内に、ストリーミング バッファからクエリできるようになります。ただし、データがコピーやエクスポートのオペレーションで使用可能になるまでに、最大で 90 分を要する場合があります。詳細については、ストリーミング挿入の仕組みに関する Google のブログ投稿、および Google のドキュメントをご覧ください。
Google Cloud Platform でリアルタイム データを取り込むにはいくつかの方法がありますが、ストリーミング モードで稼働し、必要な処理が完了した後に BigQuery テーブルに書き込む Cloud Dataflow パイプラインを使用して、Cloud Pub/Sub トピックからメッセージを読み取るのが一般的です。Cloud Dataflow パイプラインの最も良い点は、ストリーミング処理とバッチ処理の両方に対して同じコードを再利用できることです。パイプラインを並行処理するために行うコンピューティング リソースの開始、実行、停止作業は、Google により管理されます。こちらのリファレンス アーキテクチャで、ユースケースを詳細に説明しています。
BigQuery にデータをストリーミングする方法は Cloud Dataflow 以外にもあります。たとえば、Apache Spark でストリーミング パイプラインを記述し、Apache Spark BigQuery Connector を使用して Cloud Dataproc などの Hadoop クラスタで実行できます。また、任意のクライアント ライブラリで Streaming API を呼び出して、BigQuery にデータをストリーミングすることもできます。
Data Transfer Service
BigQuery の Data Transfer Service(DTS)は、Google 広告などの Google SaaS アプリ、Amazon S3 などの外部クラウド ストレージ プロバイダからデータを取り込み、Teradata や Amazon Redshift などのデータ ウェアハウス技術からデータを転送するためのフルマネージド サービスです。DTS では、あらかじめ設定されたスケジュールに基づいて BigQuery に自動的にデータを転送できます。また、データのバックフィルを開始して、停止やギャップから回復することもできます。
Data Transfer Service は、アプリケーションから BigQuery にデータをインポートするための手間いらずなデータ配信サービスと考えてください。
クエリの実体化
BigQuery でクエリを実行する際、その結果セットを実体化して新しいテーブルを作成できます。このパターンについては、Stack Overflow 一般公開データセットに対するクエリ実行結果から新しいテーブルを作成した、パーティショニングとクラスタリングに関する前回の投稿で説明しています。
クエリ結果の実体化は、BigQuery の ETL(抽出、変換、読み込み)パターンや ELT(抽出、読み込み、変換)パターンを簡素化する優れた方法です。たとえば、BigQuery の連携クエリを使用して Cloud Storage でステージングされたファイルの調査関連作業やプロトタイピングを実行する場合は、分析結果を BigQuery に保持して分析情報を引き出すことができます。クエリにより読み取られたデータのバイト数と、テーブルが書き込まれた後に BigQuery ストレージに保存されたデータのバイト数に対して料金が発生します。
データを読み込まずにクエリを実行する
この投稿の冒頭で述べたように、以下の状況でクエリを実行する場合、BigQuery にデータを読み込む必要はありません。
一般公開データセット: BigQuery に保存されて、一般公開されるデータセットです。詳細については、BigQuery 一般公開データセットをご覧ください。
共有データセット: BigQuery に保存したデータセットを共有できます。別のユーザーのデータセットを共有している場合は、そのデータを読み込まなくても、データセットに対してクエリを実行できます。
外部データソース(連携): 外部データソースにテーブルを作成すると、データの読み込みプロセスを省略できます。
パートナーとの統合
BigQuery でネイティブに利用できるソリューションとは別に、業界をリードするツールを BigQuery と統合した Google Cloud パートナーのデータ統合オプションを利用することもできます。
次のステップ
この記事では、BigQuery にデータを取り込むいくつかの方法について、ユースケースに基づき説明しました。具体的には、バッチ データソースの BigQuery への取り込みとその形式について、ストリーミング取り込みと Data Transfer Service の概要について、BigQuery にデータを読み込まずに外部データソースに対してクエリを実行することについて説明しました。
CSV データをバッチデータとして読み込み、BigQuery でデータを分析する方法に関する動画を見る
BigQuery へのデータの読み込みについて学習する
Codelab で、Google Cloud Storage から BigQuery サンドボックスの BigQuery にファイルを取り込む

次回の投稿では、BigQuery のデータに対するクエリの実行とスキーマの設計について説明します。今後の投稿では、他のデータ取り込み方法(ストリーミング、Data Transfer Service)について詳しく説明します。
今後の情報にご注目ください。ご精読ありがとうございました。私に質問がある場合やチャットをご希望の場合は、Twitter または LinkedIn でご連絡ください。
本投稿に協力してくれた Yuri Grinshsteyn と Alicia Williams に感謝します。
-Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam


