Life of a BigQuery streaming insert
Seth Hollyman
Developer Relations Engineer, BigQuery
Editor's Note (August, 2018): When this article was originally written, DML statements such as UPDATE and DELETE would never succeed when modifying a table with an active streaming buffer. BigQuery now allows DML modifications to proceed in certain situations. Look here for more information.
Understanding how BigQuery streaming inserts work makes it easier to build real-time applications.
Google BigQuery, the fully managed cloud-native data warehouse for Google Cloud Platform (GCP) customers, supports several ways to ingest data into its managed storage, including explicit load jobs or via queries against external sources. These methods share a common theme, in that they're used to transfer and append this new storage as part of a (potentially large) single commit to a table. BigQuery also supports a method of ingestion known as streaming, which is intended to service the needs of users who need a more open-ended, continuous style of ingestion. In this post, you’ll learn how the streaming system works, which should help aid understanding of observed behaviors and make it easier to reason about building integrations with BigQuery.
Basic concepts
As a kickstart, the following diagram illustrates the components that interact with streaming inserts in some fashion.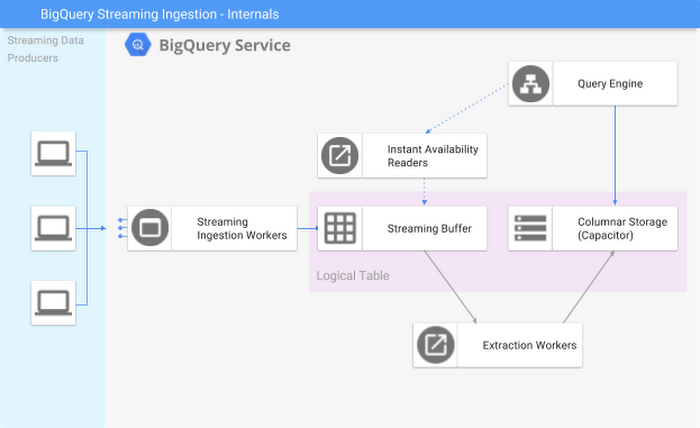
- Streaming data producers: The applications that are sending the data for streaming into BigQuery. Typically this is user code, but may also be generated by other cloud services such as Google Cloud Dataflow or Cloud Logging.
- Streaming ingestion workers: The portion of the API surface that handles streaming insert traffic. Its primary responsibilities are to take the JSON representation of the streamed records, insert them into the streaming buffer and report on the success/failure of the operation.
- Streaming buffer: The buffer that retains recently inserted rows, and is optimized for high-throughput writes rather than columnar access.
- Instant availability reader: Allows the query engine to read records directly from the streaming buffer.
- Columnar storage: Data associated with a table that's in columnar format. Most tables of reasonable size comprise many individual columnar files.
- Extraction worker: The process that collect groups of buffered records, converts them to columnar format, and commits that data to BigQuery's managed storage.
- Query engine: Represents the query engine itself (aka Dremel).
Stage 1: Data source to initial ingestion
The user sends a streaming insert into BigQuery via thetabledata.insertAll method. This insert is sent to the API in JSON format, along with other details such as authorization headers and details about the intended destination. A single insertAll call may have one or more individual records within it. We refer to number of rows per insertAll call as the batch factor.The insert is received and processed by the Streaming Worker, which makes the necessary calls to persist each record in the insertAll payload into the streaming buffer and uses the optionally provided insertId property to construct a well-formed key to reference the record in the buffer. The worker then reports on the success and/or failure of the insertAll request as a whole, and for successful insertAll requests, the payload will contain more detailed status for individual records. It’s possible for the group insertion to report success but still have individual records that report issues such as timeout.
Once the insert worker confirms it, the data has been committed to the streaming buffer. The stream buffer storage is optimized for high-throughput writes rather than in a columnar format. At this point the data is considered durable but has more limited availability compared to managed storage.
(Optional) Stage 2: Query while buffered
A record that arrives in the streaming buffer will remain there for some minimum amount of time (minutes). During this period while the record is buffered, it's possible that you may issue a query that will reference the table. The Instant Availability Reader allows workers from the query engine to read the buffered records prior to being committed to managed storage.Note: Reads via instant availability are sometimes slower than reading the equivalent data from managed storage. This performance variation is due to factors including data location issues (the streaming buffer may be further from the query tree), storage format and available parallelism.
Due to many of these same reasons, it's possible for the streaming readers to be unable to service query requests that want to read records from the streaming buffer. In these cases you may observe that the buffered data does not contribute to the query's results. (We're working on improving visibility into instant availability contributions to query results.)
Final stage: Extraction
Over time, the extraction workers will collect records from a given table's buffer and write them out into columnar format. The extraction workers try to balance recency against making efficient batches of columnar storage, so the age of a given record as well as the overall volume of streaming records arriving into a table influence the rate at which these extractions occur. As records are extracted, they're marked garbage and removed from the streaming buffer. As groups of records are committed into managed storage, they're replicated to multiple datacenters and thus achieve a higher level of availability.Additional considerations
DeduplicationAs with any large distributed system, care must be taken to consider failure modes. When streaming records to BigQuery, transient failures such as network issues can occur. BigQuery exposes the insertId field to help users build write-once semantics: when multiple inserts bearing the same insertId arrive within minutes of one another, only a single version of the record will be persisted. After a record bearing a specific insertId is extracted from the streaming buffer, arrival of new records bearing the same insertId will be treated as a new record rather than being deduplicated against the original insert.
Consistency and caching
To support the high throughput of individual inserts via streaming, the streaming system caches metadata information aggressively, particularly around table existence and schema information. In practice, that means that some interactions exhibit eventually consistent behaviors. For example, if you attempt streaming data to a table before it exists, create the table and then resume streaming, the streaming system may still reject subsequent inserts with “table not found” errors for some period of time after the table creation. Similarly, changes such as widening a table's schema may require some period of time before streamed inserts can reference the new columns.
Table copies, extracts and data availability
Records in the streaming buffer are not considered when a copy or extract job runs, as those jobs attempt to work with managed storage exclusively. We're working to make this clearer, and details like the streamingBuffer stats provided via tables.get can help you identify when these operations may omit data that's still in the buffer.
Data Manipulation Language (DML)
BigQuery supports bulk modification of tables via data manipulation statements such as UPDATE and DELETE. To avoid consistency issues, DML statements are not allowed on a table with an active streaming buffer. After a table has received no inserts for an extended interval of time, the buffer is detached and DML is allowed.
Partitioned tables
Streaming works with partitioned tables, as well. Tables defined with natural partitioning use ingestion time as the partitioning element, and streaming to a naturally partitioned table will by default deliver streamed data to the partition representing the current day. You can, however, also choose to deliver streaming inserts to recent partitions via the existing $YYYYMMDD suffix.
Other paths
While the existing streaming system addresses the needs of many users, your processing needs may differ from the functionality the streaming system provides. In particular, some users require a storage system that supports frequent row-level mutations as well as needing to do large-scale analytic processing, which is where BigQuery excels. In this case, one strategy to consider is to use a combination of Google Cloud Bigtable and BigQuery's support for federated queries to read data.
Cloud Bigtable provides the mechanism and ability to support high throughput of small mutations, as well as allowing the notion of row keys that allow greater ability to express unique deduplication needs. Federated query from BigQuery then allows you to periodically scan your existing Cloud Bigtable data, optionally write it to BigQuery managed storage and perform aggregate analysis across the data as a whole.



