BigQuery explained: How to ingest data into BigQuery so you can analyze it
Rajesh Thallam
Solutions Architect, Generative AI Solutions
Previously in the BigQuery Explained series, we have reviewed how the decoupled storage and compute architecture helps BigQuery to scale seamlessly. We looked into BigQuery’s storage management, partitioning and clustering tables to improve query performance and optimize cost. So far we have only queried or used datasets that already existed within BigQuery. In this post, we will see how to load or ingest data into BigQuery and analyze them. Let’s dive into it!
Before we start, let’s look at the difference between loading data into BigQuery and querying directly from an external data source without loading into BigQuery.
Direct Import (Managed Tables): BigQuery can ingest datasets from a variety of different formats directly into its native storage. BigQuery native storage is fully managed by Google—this includes replication, backups, scaling out size, and much more.
Query without Loading (External Tables): Using a federated query is one of the options to query external data sources directly without loading into BigQuery storage. You can query across Google services such as Google Sheets, Google Drive, Google Cloud Storage, Cloud SQL or Cloud BigTable without having to import the data into BigQuery.
One key difference is that performance of querying external data sources may not be equivalent to querying data in a native BigQuery table. If query speed is a priority, then load the data into BigQuery. The performance of a federated query depends on the performance of the external storage engine that actually holds the data.
Loading Data into BigQuery
There are multiple ways to load data into BigQuery depending on data sources, data formats, load methods and use cases such as batch, streaming or data transfer. At a high level following are the ways you can ingest data into BigQuery:
Batch Ingestion
Streaming Ingestion
Data Transfer Service (DTS)
Query Materialization
Partner Integrations

In this post, we will dig into batch ingestion and introduce other methods at a high level. We will have dedicated blog posts in future for other ingestion mechanisms.
Batch Ingestion
Batch ingestion involves loading large, bounded, data sets that don’t have to be processed in real-time. They are typically ingested at specific regular frequencies, and all the data arrives at once or not at all. The ingested data is then queried for creating reports or combined with other sources including real-time.
BigQuery batch load jobs are free. You only pay for storing and querying the data but not for loading the data.
For batch use cases, Cloud Storage is the recommended place to land incoming data. It is a durable, highly available, and cost effective object storage service. Loading from Cloud Storage to BigQuery supports multiple file formats—CSV, JSON, Avro, Parquet, and ORC.
Load Compressed or Uncompressed Files?
BigQuery can ingest both compressed (GZIP) and uncompressed files from Cloud Storage. Highly parallel load operations allow uncompressed files to load significantly faster than compressed files. Since uncompressed files are larger, there could be possible bandwidth limitations, and it’s more expensive to store them. On the other hand, compressed files are faster to transmit and cheaper to store, but slower to load into BigQuery. Weigh compression options based on your use case—customers usually choose compressed files when they’re constrained by network speeds.
Choosing File Format for Loading Data
With support for a wide-variety of file formats for data ingestion some are naturally faster than others. Following are recommendations on the file formats when loading data into BigQuery:
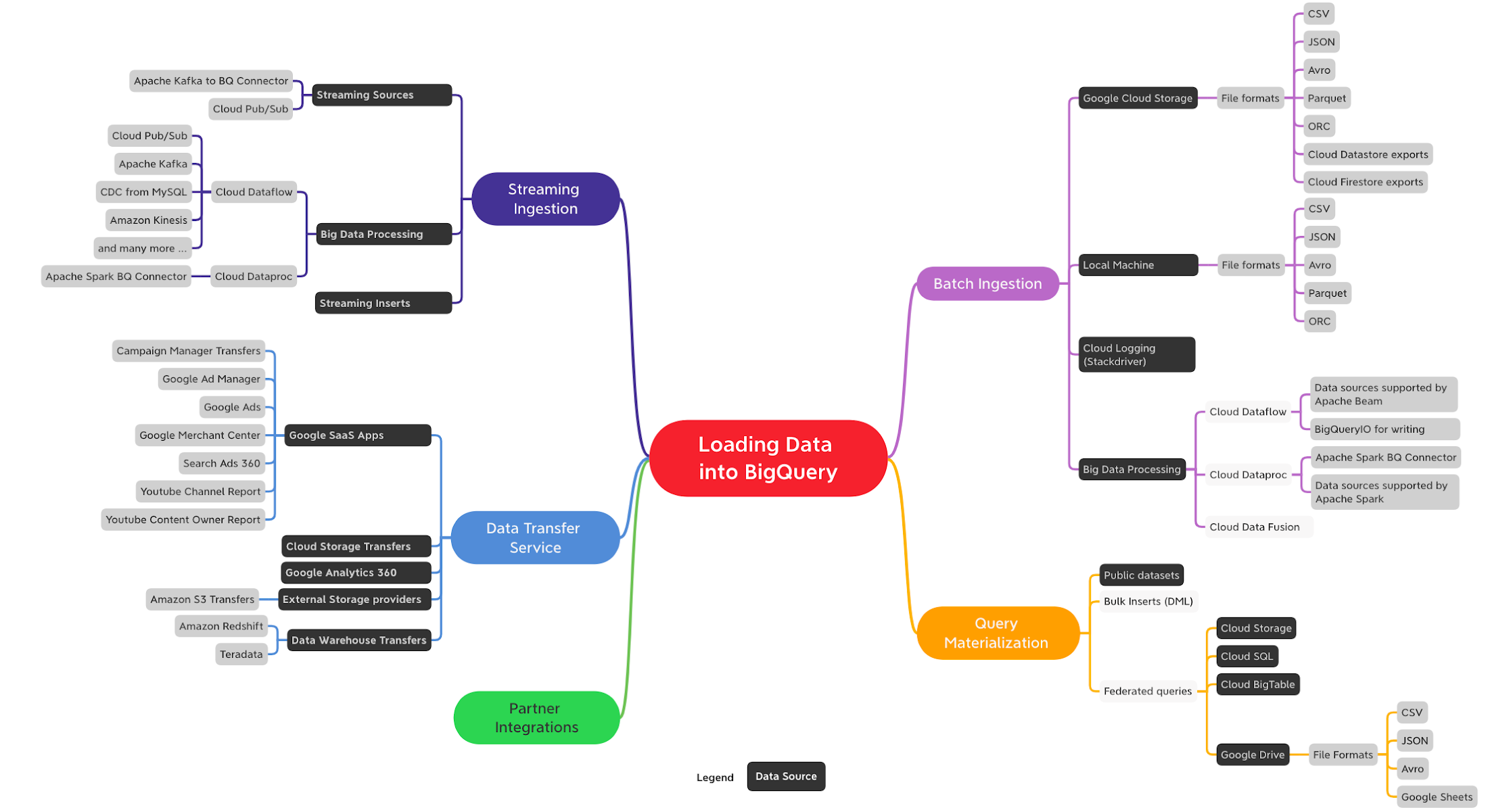
When optimizing for load speed, Avro file format is preferred. Avro is a binary row-based format which can be split and read in parallel by multiple slots including compressed files.
Parquet and ORC are binary and columnar formats. When ingesting data into BigQuery, the entire record needs to be read and because they are columnar formats they will tend to load slower than Avro.
Compressed CSV and JSON will perform slower relatively because Gzip compression is non-splittable and thus each compressed file has to be decompressed before the work can be parallelized.
Following picture ranks different formats based on their load performance.
Load Methods
When loading data into BigQuery, you can create a new table or append to or overwrite an existing table. You need to specify the table or partition schema, or, for supported data formats, you can use schema auto-detection.
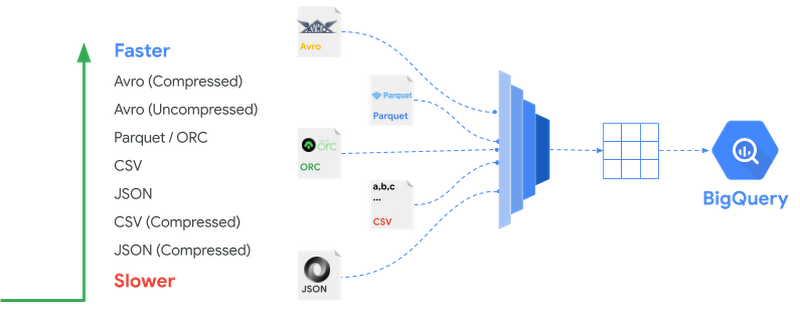
BigQuery supports loading data from various sources in a variety of formats. Apart from Google Services such as Cloud Storage, BigQuery also supports loading from external storage such as Amazon S3. Let’s look at the options to load these batch files from different data sources.
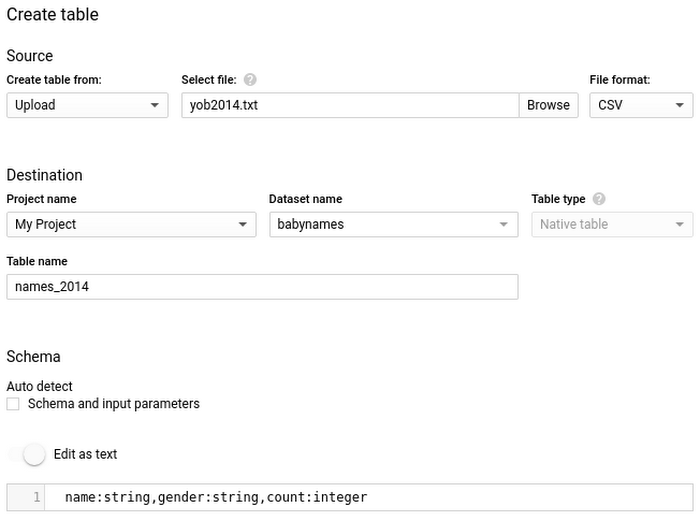
Load Using BigQuery UI
As you have seen before, you can use the same web UI used for examining tables and building queries to load data, as well. Once you have the data available to load on your local machine or Cloud Storage, you can load data into the destination table using the web UI. In the UI, you can enable schema auto-detection or specify it explicitly. Refer to the Quickstart guide for more details.
Using CLI—bq load
To load data into BigQuery using CLI you can use the bq load command. For example, to import a CSV file from Cloud Storage to BigQuery, specify the Cloud Storage URI or a comma separated list for multiple URIs pointing to the CSV files. The CLI supports the same options you saw in the web UI — schema detection or manually specifying a schema, appending or overwriting, and ingesting files from your local machine are all available.Load Using REST API
The REST API can be used from runtimes such as Java or Python to communicate with BigQuery. The service receives HTTP requests and returns JSON responses. Both the web UI and the CLI use this API to communicate with BigQuery. For example, take a look at using Python API to load data into BigQuery table from Cloud Storage:Apart from using above tools, you also have following data pipeline options to load data into BigQuery:
Dataflow is a fully managed service on GCP built using the open source Apache Beam API with support for various data sources — files, databases, message based and more. With Dataflow you can transform and enrich data in both batch and streaming modes with the same code. Google provides prebuilt Dataflow templates for batch jobs.
Dataproc is a fully managed service on GCP for Apache Spark and Apache Hadoop services. Dataproc provides BigQuery connector enabling Spark and Hadoop applications to process data from BigQuery and write data to BigQuery using its native terminology.
This is not a data pipeline option but Cloud Logging (previously known as Stackdriver) provides an option to export log files into BigQuery. See Exporting with the Logs Viewer for more information and reference guide on exporting logs to BigQuery for security and access analytics.
Behind the Scenes
Behind the scenes, when BigQuery receives request to load a file into its managed storage it does the following:
Encoding, Compressing and Statistics: BigQuery optimally encodes the data after analyzing data types, value frequencies and compresses the data in the most optimal way for reading large amounts of structured data.
Sharding: BigQuery distributes data into optimal shards and based on how the table is defined it loads data into specific partitions, clusters and reclusters the data.
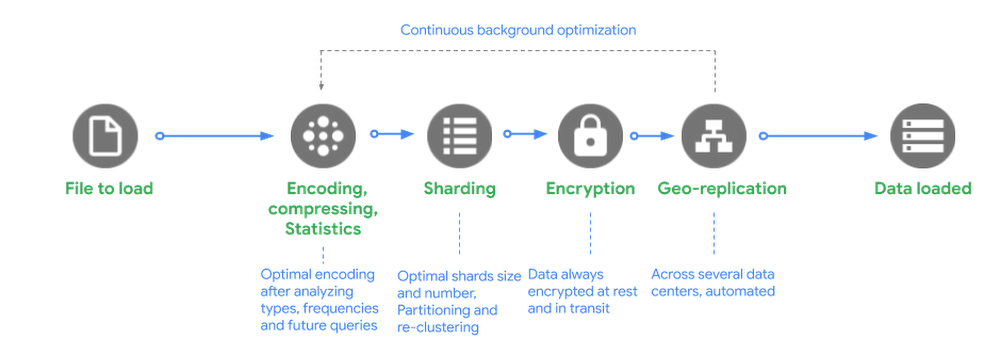
Encryption: BigQuery always encrypts data by default before it is written to disk with no additional action required from you. The data is automatically decrypted when read by an authorized user. For data in transit, your data is encrypted within Google data centers when it is transferred between machines.
Geo-replication: BigQuery automatically replicates data across multiple data centers depending on how you have defined your dataset locations—regional or multi-regional.
BigQuery users get the benefit of continuous improvements in performance, durability, efficiency, and scalability, without downtime and upgrade as BigQuery continuously optimizes its backend.
Key Points on BigQuery Load Jobs
Batch ingest is free
There is no charge for loading data into BigQuery with the batch ingest options mentioned. However, quotas and limits apply.
Load performance is best effort
Since the compute used for loading data is made available from a shared pool at no cost to the user, BigQuery does not make guarantees on performance and available capacity of this shared pool. This is governed by the fair scheduler allocating resources among load jobs that may be competing with loads from other users or projects. Quotas for load jobs are in place to minimize the impact.
Tip: To guarantee ingestion speed for any critical loads, you might want to purchase dedicated slots (reservations) and assign pipeline jobs to them. More on reservations in a future blog post.
Load jobs do not consume query capacity
Slots used for querying data are distinct from the slots used for ingestion. Hence, data ingestion does not impact query performance.
ACID semantics
For data loaded through the
bq loadcommand, queries will either reflect the presence of all or none of the data. Queries never scan partial data.
Streaming Ingestion
Streaming ingestion supports use cases that require analyzing high volumes of continuously arriving data with near-real-time dashboards and queries. Tracking mobile app events is one example of this pattern . The app itself or the servers supporting its backend could record user interactions to an event ingestion system such as Cloud Pub/Sub and stream them into BigQuery using data pipeline tools such as Cloud Dataflow or you can go serverless with Cloud Functions for low volume events. You could then analyze this data to determine overall trends, such as areas of high interaction or problems, and monitor error conditions in real-time.
BigQuery streaming ingestion allows you to stream your data into BigQuery one record at a time by using the tabledata.insertAll method. The API allows uncoordinated inserts from multiple producers. Ingested data is immediately available to query from the streaming buffer within a few seconds of the first streaming insertion. It might take up to 90 min for data to be available for copy and export operations, however. You can read our blog post about how streaming insert works and our docs for more information.
One of the common patterns to ingest real-time data on Google Cloud Platform is to read messages from Cloud Pub/Sub topic using Cloud Dataflow pipeline that runs in streaming mode and writes to BigQuery tables after the required processing is done. The best part with Cloud Dataflow pipeline is you can also reuse the same code for both streaming and batch processing and Google will manage the work of starting, running and stopping compute resources to process your pipeline in parallel. This reference architecture covers the use case in much detail.
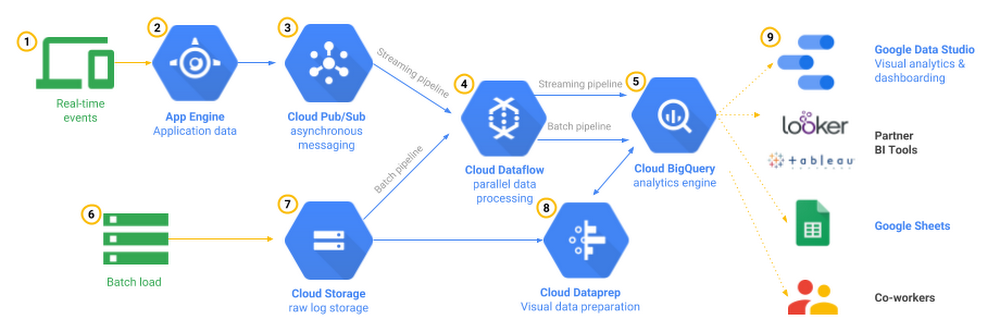
Please note that you have options beyond Cloud Dataflow to stream data to BigQuery. For example, you can write streaming pipelines in Apache Spark and run on a Hadoop cluster such as Cloud Dataproc using Apache Spark BigQuery Connector. You can also call the Streaming API in any client library to stream data to BigQuery.
Data Transfer Service
The BigQuery Data Transfer Service (DTS) is a fully managed service to ingest data from Google SaaS apps such as Google Ads, external cloud storage providers such as Amazon S3 and transferring data from data warehouse technologies such as Teradata and Amazon Redshift . DTS automates data movement into BigQuery on a scheduled and managed basis. DTS can be used for data backfills to recover from any outages or gaps.
Think of Data Transfer Service as an effortless data delivery service to import data from applications to BigQuery.
Query Materialization
When you run queries in BigQuery their result sets can be materialized to create new tables. We have seen this pattern in the previous post on partitioning and clustering where we created new tables from the results of queries on Stack Overflow public data set.
Query results materialization is a great way to simplify ETL (Extract, Transform and Load) or ELT (Extract, Load and Transform) patterns in BigQuery. For example, when carrying out exploratory work or prototyping on files staged in Cloud Storage using federated queries in BigQuery, you can persist those analysis results in BigQuery to derive any insights. Please note that you are charged for the number of bytes read by the query and the number of bytes stored in BigQuery storage after the tables are written.
Query Without Loading Data
As mentioned in the beginning of this post, you don’t need to load data into BigQuery before running queries in the following situations:
Public Datasets: Public datasets are datasets stored in BigQuery and shared with the public. For more information, see BigQuery public datasets.
Shared Datasets: You can share datasets stored in BigQuery. If someone has shared a dataset with you, you can run queries on that dataset without loading the data.
External data sources (Federated): You can skip the data loading process by creating a table based on an external data source.
Partner Integrations
Apart from the solutions available natively in BigQuery, you can also check data integration options from Google Cloud partners who have integrated their industry-leading tools with BigQuery.
What Next?
In this article, we learned different ways to get data into BigQuery based on your use case . Specifically we dived into ingesting batch data sources and formats into BigQuery with a glimpse into streaming ingestion, Data Transfer Service and querying external data sources without loading data into BigQuery.
Check out video on loading CSV data in batch, and analyzing data in BigQuery.
Learn more about loading data into BigQuery
Try this codelab to ingest files from Google Cloud Storage to BigQuery on your BigQuery Sandbox

In the next post, we will look at querying data in BigQuery and schema design. In the upcoming posts we will delve deep into other ingestion mechanisms—Streaming and Data Transfer Service.
Stay tuned. Thank you for reading! Have a question or want to chat? Find me on Twitter or LinkedIn.
Thanks to Yuri Grinshsteyn and Alicia Williams for helping with the post.
The complete BigQuery Explained series
- BigQuery explained: An overview of BigQuery's architecture
- BigQuery explained: Storage overview, and how to partition and cluster your data for optimal performance
- BigQuery explained: How to ingest data into BigQuery so you can analyze it
- BigQuery explained: How to query your data
- BigQuery explained: Working with joins, nested & repeated data
- BigQuery explained: How to run data manipulation statements to add, modify and delete data stored in BigQuery



