BigQuery 特集: ストレージの概要
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery 特集シリーズの前回の投稿では、BigQuery アーキテクチャの概要を確認し、BigQuery の使い方について説明しました。この投稿では、BigQuery のストレージ構成やストレージ形式について説明するほか、BigQuery のベスト プラクティスの 1 つである最適なパフォーマンスのためのデータのパーティショニングとクラスタ化をご紹介します。詳しく見ていきましょう。
BigQuery リソースモデル
BigQuery は、データセットと呼ばれる単位でデータテーブルを整理します。これらのデータセットは GCP プロジェクトを範囲とします。プロジェクト、データセット、テーブルという複数の範囲を対象とすると、情報を論理的に構造化するのに役立ちます。複数のデータセットを使用して、それぞれの分析領域に関連するテーブルに分けることができます。また、プロジェクト レベルで範囲を設定し、ビジネスニーズに応じてデータセットを分割することも可能です。
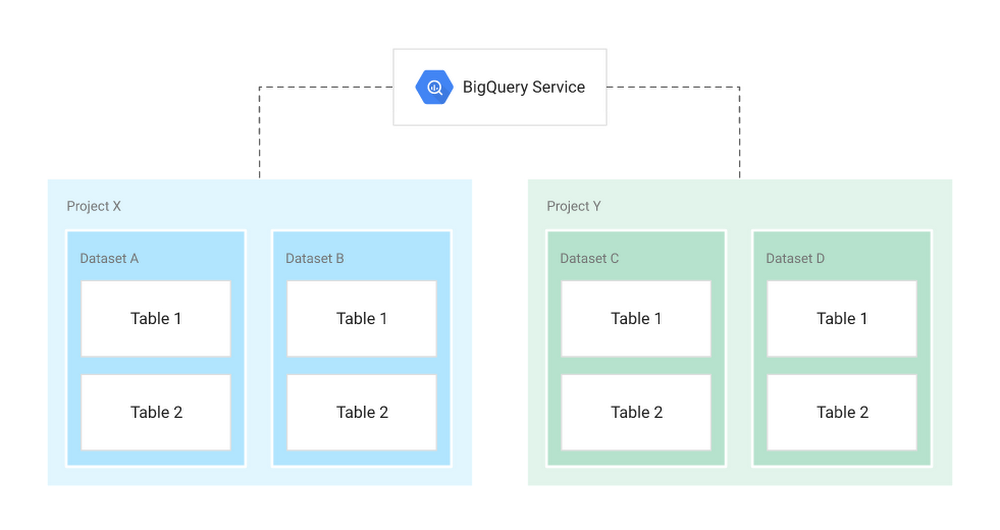
プロジェクト
オブジェクトのルート名前空間です。
複数のデータセット、ジョブ、アクセス制御リスト、IAM ロールが含まれます。
課金、ユーザー、ユーザー権限を管理します。
データセット
ラベルと説明を含む「関連する」テーブルやビューのコレクションです。
データセット レベルのストレージ アクセス制御を許可します。
データのロケーションの定義です(マルチリージョン(US、EU など)やリージョン(asia-northeast1 など))。
テーブル
ビュー
SQL クエリによって定義される仮想テーブルです。
ビューレベルのアクセス制御を許可します。
ジョブ
データの読み込み、データのエクスポート、データのコピー、データのクエリなど、BigQuery がユーザーに代わって実行するアクションのことです。
ジョブは非同期で実行されます。

ストレージ管理
では、データを保持するストレージを BigQuery がどのようにして管理しているのか確認してみましょう。MySQL のような従来のリレーショナル データベースでは、データは行単位で格納(レコード指向のストレージ)されるため、トランザクションの更新や OLTP(オンライン トランザクション処理)のユースケースに適しています。一方、BigQuery は、従来のデータベースとは異なるカラム型ストレージを使用していて、各列は別々のファイル ブロックに保存されるため、OLAP(オンライン分析処理)のユースケースの理想的なソリューションとなっています。BigQuery テーブルにデータを簡単にストリーミング(追加)したり、既存の値を更新または削除したりできます。BigQuery では、制限なしでミューテーションをサポートしています(INSERT、UPDATE、MERGE、DELETE)。
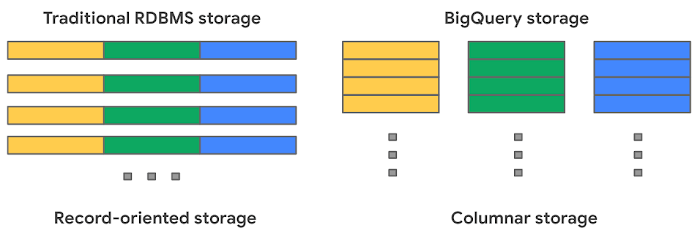
BigQuery は、カラム型ストレージにバリエーションと改良を加えています。BigQuery の内部では、Capacitor という独自のカラム型でデータが保存されます。Capacitor には、データ ウェアハウスのワークロードに対する多くの利点があります。BigQuery が独自の形式を使用する理由は、ストレージ エンジンが、データ レイアウトに関する深い知識を活用してクエリの実行を最適化するクエリエンジンと連携して発展できる可能性があるためです。テーブルの各列は別々のファイル ブロックに保存され、すべての列は 1 つの Capacitor ファイルに保存されます。これらは、ディスク上で圧縮、暗号化されます。BigQuery はクエリ アクセス パターンを使用して、物理シャードの最適な数とデータのエンコード方法を決定します。
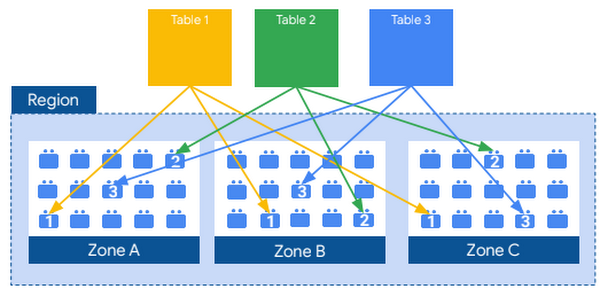
実際の永続的なレイヤは、Google の分散ファイル システムである Colossus によって提供され、データの圧縮、暗号化、複製、分散が自動的に行われます。Colossus では、消失訂正符号を使用して複数の物理ディスクに冗長なデータのチャンクを保存することで、耐久性を確保しています。これらの作業は、クエリに使用できる処理能力に影響しません。ストレージをコンピューティングから切り離すことで、高額なコンピューティング リソースを追加する必要なく、ストレージをペタバイト規模までシームレスにスケールできます。コンピューティングとストレージの分離によりもたらされるその他のメリットは数多くあります。
長期保存を活用する
BigQuery のストレージの料金は、格納されているデータ量(毎月 10 GB まで無料)と、ストレージがアクティブまたは長期とみなされるかに基づいて決まるため、データを無料(一括読み込みの場合)で BigQuery に読み込むことができます。
過去 90 日間で変更されたテーブルやパーティションはアクティブ ストレージとみなされ、格納されたデータに対して BigQuery のストレージ料金で月額料金が発生します。
90 日間連続して編集されていないテーブルやパーティションは長期保存とみなされ、そのテーブルに対するストレージ料金は自動的に約 50% 値引きされ、Cloud Storage Nearline と同じ費用になります。割引は、テーブル単位、パーティション単位で適用されます。テーブルのデータを変更すると、90 日のカウンタはリセットされます。

費用を最適化する際のベスト プラクティスは、データを BigQuery に保持することです。古いデータを別のストレージ オプション(Cloud Storage など)にエクスポートするのではなく、BigQuery の長期保存の料金を活用します。これにより、古いデータの削除や、データのアーカイブ プロセスの設計を行う必要がなくなります。また、データが BigQuery に保持されるため、同じインターフェースを使用して、同じ費用レベル、同じパフォーマンス特性で古いデータをクエリすることもできます。
パーティショニングとクラスタリング
費用とパフォーマンスの両方を最適化したい場合、BigQuery でのデータ保持がベスト プラクティスとなります。また、別のベスト プラクティスには、BigQuery のテーブル パーティショニングとテーブル クラスタリングの機能を使用して、一般的なデータアクセス パターンに合わせてデータを構造化することが挙げられます。
パーティショニング
パーティション分割テーブルは、パーティションと呼ばれるセグメントに分割された特殊なテーブルです。このテーブルを使用すると、データの管理や照会が簡単になります。通常、データの取り込み時間、TIMESTAMP/DATE 列、INTEGER 列を使用して、大きなテーブルを多数の小さなパーティションに分割できます。BigQuery の分離されたストレージ アーキテクチャとコンピューティング アーキテクチャは、列ベースのパーティショニングを活用して、スロット ワーカーがディスクから読み込むデータ量を最小限に抑えます。スロット ワーカーがディスクからデータを読み込んだ後、BigQuery は最適なデータ シャーディングを判断し、BigQuery のメモリ内シャッフル サービスを使用してデータのパーティションを再設定します。
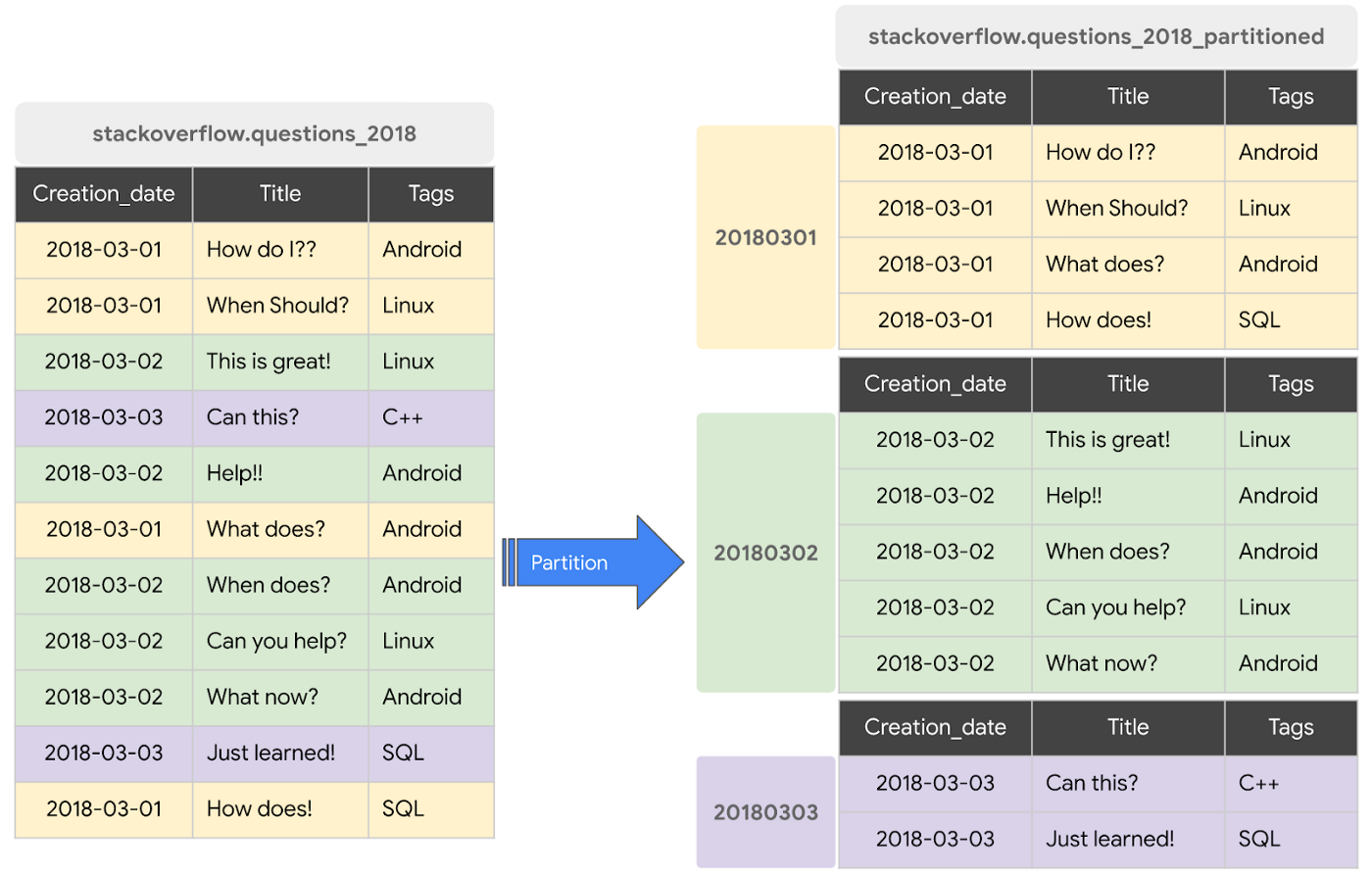
列ベースで時間ごとにパーティション分割したテーブルに書き込んだデータは、データ値に基づいて適切なパーティションに配信されます。同様に、パーティション分割する列のフィルタを表現するクエリを使用することで、スキャンするデータの全体量を減らし、オンデマンド クエリのパフォーマンス向上と費用削減が可能になります。
BigQuery のパーティション分割テーブルの作成には以下のようなものがあります。
取り込み時間パーティション分割テーブル
データの取り込み時間や受信時間に基づいてパーティション分割されたテーブルです。
BigQuery は、データの取り込み時間または受信時間を反映した、日付に基づく日単位のパーティションにデータを自動的に読み込みます。
BigQuery は、2 つの疑似列を取り込み時間パーティション分割テーブルに追加します。_PARTITIONTIME 疑似列にはデータの日付ベースのタイムスタンプが格納され、_PARTITIONDATE 疑似列には日付表記が格納されます。
DATE/TIMESTAMP 列のパーティション分割テーブル
TIMESTAMP 列または DATE 列に基づいてパーティション分割されたテーブルです。
BigQuery は、パーティショニングする列の日付値(UTC で表される)に基づいて、適切なパーティションにデータを転送します。
BigQuery は 2 つの特殊パーティションを作成します。__NULL__ パーティションは、パーティショニングする列で NULL 値の行を取得し、__UNPARTITIONED__ パーティションは、日付の許容範囲外にあるデータのために使用されます。
時間単位のパーティショニングの粒度からパーティションを作成できます。
整数範囲パーティション分割テーブル
開始、終了、間隔の値を持つ整数列に基づいてパーティション分割されたテーブルです。
BigQuery は 2 つの特殊パーティションを作成します。__NULL__ パーティションは、パーティショニングする列で NULL 値の行を取得し、__UNPARTITIONED__ パーティションは、整数の許容範囲外にあるデータのために使用されます。
次に、パーティショニングの実用例を確認してみましょう。パーティション分割されていないテーブルとパーティション分割されたテーブルのパフォーマンスの違いを確認するために、同じデータセットを使用してこの 2 つのテーブルを作成し、クエリのパフォーマンスを確認します。
パーティショニングの前に
次の SQL クエリを実行すると、既存のテーブルから新しいテーブルを作成し、StackOverflow の投稿に基づいて一般公開データセットから読み込まれたデータを使用してパーティション分割されていないテーブルを作成します。このテーブルには、2018 年に作成された StackOverflow の投稿が含まれます。
パーティション分割されていないテーブルに対してクエリを実行し、2018 年 1 月に「android」でタグ付けされた StackOverflow のすべての質問を取得してみましょう。
クエリを実行する前に、キャッシュ保存を無効にして、パーティション分割テーブルやクラスタ化テーブルを使用したパフォーマンスの比較が公平になるようにします。
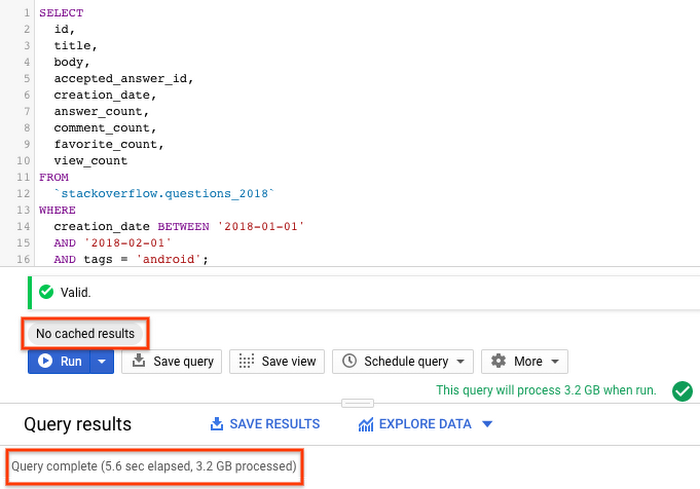
クエリ結果からわかるように、2018 年に作成された StackOverflow の投稿を使用したパーティション分割されていないテーブルに対するクエリの実行では、3.2 GB のデータ全体をスキャンし、5.6 秒かかりました。
テーブルのパーティショニング
では、パーティション分割テーブルのパフォーマンスを確認してみましょう。パーティション分割テーブルは、複数の方法で作成できます。ここでは、BigQuery の DDL ステートメントを使用して DATE/TIMESTAMP パーティション分割テーブルを作成します。また、クエリのアクセス パターンに基づいて、パーティショニング列を creation_date とします。
それでは、キャッシュ保存を無効にして、パーティション分割テーブルに対して前のクエリを実行し、2018 年 1 月に「android」でタグ付けされた StackOverflow のすべての質問を取得してみましょう。
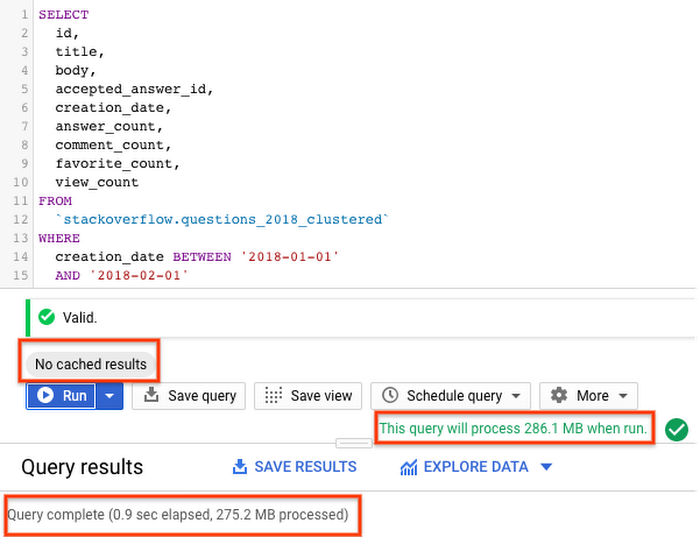
3.2 GB を処理したパーティション分割されていないテーブルに対するクエリの実行と比較して、パーティション分割テーブルでは、クエリは必要なパーティションのみスキャンし、約 290 MB のデータを 2 秒未満で処理しました。
特定の範囲でクエリを実行すると、クエリごとにスキャンするデータ量を減らせるだけでなく、クエリの開始前にプルーニングを決定できるため、パーティション管理は BigQuery のパフォーマンスと費用を完全に最適化するための重要な要因といえます。パーティショニングにより、費用の削減やパフォーマンスの向上を実現すると同時に、ユーザーが極めて大規模なテーブル全体に対して誤ってクエリを実行した場合の費用の急増も防ぐことができます。
ヒント: テーブルの有効期限の設定を使用して、不要なテーブルとパーティションを削除することで、ストレージ費用を管理し最適化できます。
パーティション分割テーブルについて詳しくは、こちらをご覧ください。
クラスタリング
BigQuery でテーブルがクラスタ化されると、テーブルのスキーマ内の 1 つ以上の列のコンテンツに基づいて、テーブルデータが自動的に編成されます。指定した列は、関連するデータを配置するために使用されます。クラスタリングには通常、カーディナリティの高い非時間列が推奨されます。
データがクラスタ化テーブルに書き込まれると、BigQuery はクラスタリング列の値を使用してデータを並べ替えます。これらの値は、BigQuery ストレージ内の複数のブロックにデータを整理するために使用されます。クラスタ化列の順序によって、データの並べ替え順序が決まります。新しいデータがテーブルまたは特定のパーティションに追加されると、BigQuery はバック グラウンドで自動再クラスタリングを行い、テーブルまたはパーティションのソート プロパティを復元します。ユーザーの皆様は、自動再クラスタリングを完全に無料で自由にご使用いただけます。
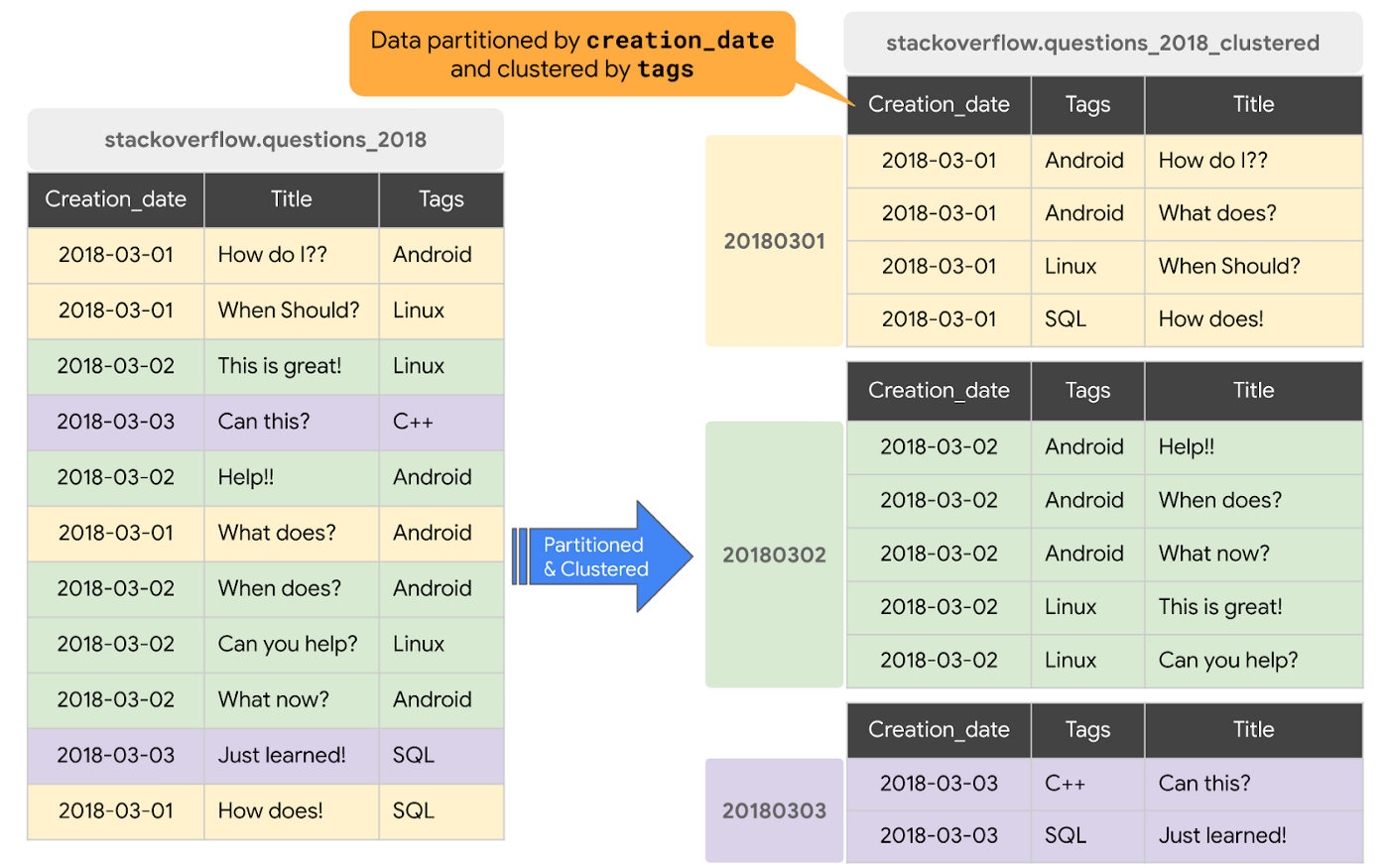
クラスタリングは、フィルタ句を使用するクエリやデータを集計するクエリなど、特定のタイプのクエリのパフォーマンスを向上させることができます。
クラスタリング列に基づいてデータをフィルタリングするフィルタ句がクエリに含まれる場合、BigQuery は並べ替えられたブロックを使用して不要なデータのスキャンを回避します。
クラスタリング列の値に基づいてデータを集計するクエリの場合、ブロックの並べ替えによって類似の値を持つ行が配置されるためパフォーマンスが向上します。
BigQuery は、パーティション分割テーブルと分割されていないテーブルの両方で、クラスタリングをサポートします。クラスタリングとパーティショニングを併用すると、データは DATE 列または TIMESTAMP 列でパーティション分割された後、異なる列のセットにクラスタ化されます(最大 4 列)。
前のクエリに戻って、クラスタ化テーブルを使用したクエリがどのように実行されるか見てみましょう。
テーブルのクラスタ化
クラスタ化テーブルは、複数の方法で作成できます。ここでは、BigQuery の DDL ステートメントを使用して DATE/TIMESTAMP パーティション分割テーブルとクラスタ化テーブルを作成します。また、クエリのアクセス パターンに基づいて、パーティショニング列を creation_date、クラスタキーを tag とします。
それでは、キャッシュ保存を無効にして、パーティション分割テーブルとクラスタ化テーブルに対してクエリを実行し、2018 年 1 月に「android」でタグ付けされた StackOverflow のすべての質問を取得してみましょう。
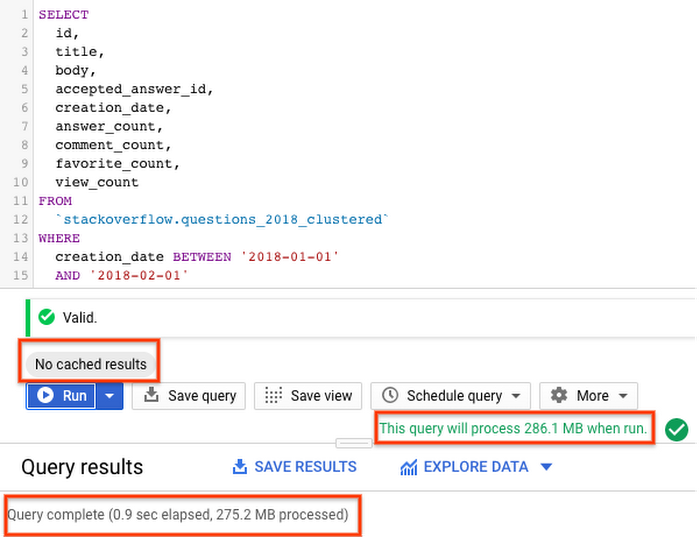
パーティション分割テーブルとクラスタ化テーブルに対するクエリの実行は、約 275 MB のデータを 1 秒未満でスキャンし、パーティション分割テーブルよりも優れた結果が得られました。パーティショニングとクラスタリングによるデータの編成では、スロット ワーカーがスキャンするデータ量を最小限に抑えられるため、クエリのパフォーマンスが向上し、費用が最適化されます。
クラスタリングを使用する場合は、以下の点に注意する必要があります。
クラスタリングでは、クエリを実行する前に厳密な費用保証を確約することはできません。クラスタリングを使用した上記の結果では、クエリの検証で 286.1 MB の処理が報告されましたが、実際には 275.2 MB のデータしか処理されていません。
クラスタリングは、パーティショニングだけで許容されるよりも細かい粒度が必要な場合にのみ使用します。
クラスタ化テーブルの操作の詳細については、こちらをご覧ください。
次のステップ
この記事では、BigQuery がデータを保持するストレージを構成し管理する方法、テーブルのパーティショニングやクラスタリングを行うことでクエリのパフォーマンスを向上させる方法、非アクティブなデータの長期保存の料金を使用して BigQuery にデータを保持する方法を学びました。
BigQuery を使用したパーティショニングとクラスタリングのデモを視聴する。
クラスタリングとパーティショニングを使用するタイミングについて学習する。
Codelab で、BigQuery のパーティショニングとクラスタリングを BigQuery サンドボックスで試してみる。
次回の投稿では、BigQuery にデータを取り込み、そのデータを分析する方法について説明します。
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットを希望する場合は、Twitter または LinkedIn でアクセスしてください。
この投稿に協力してくれた Yuri Grinshsteyn と Alicia Williams に感謝します。
-Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam



