O Artifact Registry não monitora registros de terceiros para atualizações de imagens copiadas para o Artifact Registry. Se você quiser incorporar uma versão mais recente de uma imagem ao seu pipeline, envie-a para o Artifact Registry.
Visão geral da migração
A migração das imagens de contêiner inclui as seguintes etapas:
- Pré-requisitos.
- Identifique imagens para migrar.
- Pesquisar nos arquivos do Dockerfile e nos manifestos de implantação para fins de referência a registros de terceiros
- Determine a frequência de pull de imagens de registros de terceiros usando o Cloud Logging e o BigQuery.
- Copie imagens identificadas para o Artifact Registry.
- Verifique se as permissões ao registro estão configuradas corretamente, especialmente se o Artifact Registry e o ambiente de implantação do Google Cloudestiverem em projetos diferentes.
- Atualize os manifestos das implantações.
- Reimplante as cargas de trabalho.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
-
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
- Se você não tiver um repositório do Artifact Registry, crie um e configure a autenticação para clientes de terceiros que precisam de acesso ao repositório.
- Verifique suas permissões. Você precisa ter o papel de Proprietário ou Editor do IAM nos projetos em que está migrando imagens para o Artifact Registry.
- Exporte as seguintes variáveis de ambiente:
export PROJECT=$(gcloud config get-value project)
- Verifique se o Go versão 1.13 ou mais recente está instalado.
go version - No diretório com seus manifestos do GKE ou do Cloud Run, execute o comando a seguir:
grep -inr -H --include \*.yaml "image:" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
./code/deploy/k8s/ubuntu16-04.yaml:63: image: busybox:1.31.1-uclibc ./code/deploy/k8s/master.yaml:26: image: kubernetes/redis:v1 - Para listar as imagens em execução em um cluster, execute o seguinte comando:
kubectl get all --all-namespaces -o yaml | grep image: | grep -i -v -E 'docker.pkg.dev|gcr.io'
- image: nginx image: nginx:latest - image: nginx - image: nginx -
No console Google Cloud , acesse a página Análise de registros.
Acessar a Análise de registros
Se você usar a barra de pesquisa para encontrar essa página, selecione o resultado com o subtítulo Logging.
Escolha um projeto do Google Cloud .
Na guia Criador de consultas, insira a seguinte consulta:
resource.type="k8s_pod" jsonPayload.reason="Pulling"Filtro do histórico de alterações de Lastltima hora para Lastltimos sete dias.

Selecione Executar consulta.
Depois de verificar se os resultados aparecem corretamente, clique em Ações > Criar coletor.
Na caixa de diálogo Detalhes do coletor, faça o seguinte:
- No campo Nome do coletor, digite
image_pull_logs. - Em Descrição do coletor, insira uma descrição do coletor.
- No campo Nome do coletor, digite
Clique em Próxima.
Na caixa de diálogo Destino do coletor, selecione os seguintes valores:
- No campo Selecionar serviço do coletor, escolha Conjunto de dados do BigQuery.
- No campo Selecionar conjunto de dados do BigQuery, escolha Criar um novo conjunto de dados do BigQuery e preencha as informações necessárias na caixa de diálogo que será aberta. Para mais informações sobre como criar um conjunto de dados do BigQuery, consulte Criar conjuntos de dados.
- Clique em Criar conjunto de dados.
Clique em Próxima.
Na seção Escolher registros a serem incluídos no coletor, a consulta corresponde à consulta executada na guia Criador de consultas.
Clique em Próxima.
Opcional: escolha os registros para excluir do coletor. Para mais informações sobre como consultar e filtrar dados do Cloud Logging, consulte Linguagem de consulta do Logging.
Clique em Criar coletor.
O coletor de registros é criado.
Execute os comandos a seguir no Cloud Shell:
PROJECTS="PROJECT-LIST" DESTINATION_PROJECT="DATASET-PROJECT" DATASET="DATASET-NAME" for source_project in $PROJECTS do gcloud logging --project="${source_project}" sinks create image_pull_logs bigquery.googleapis.com/projects/${DESTINATION_PROJECT}/datasets/${DATASET} --log-filter='resource.type="k8s_pod" jsonPayload.reason="Pulling"' doneem que
- PROJECT-LIST é uma lista de IDs de projeto Google Cloud , separados por espaços. Por exemplo:
project1 project2 project3 - DATASET-PROJECT é o projeto em que você quer armazenar o conjunto de dados.
- DATASET-NAME é o nome do conjunto de dados, por exemplo,
image_pull_logs;
- PROJECT-LIST é uma lista de IDs de projeto Google Cloud , separados por espaços. Por exemplo:
Execute a seguinte consulta:
SELECT REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName, COUNT(*) AS numberOfPulls FROM `DATASET-PROJECT.DATASET-NAME.events_*` GROUP BY imageName ORDER BY numberOfPulls DESCem que
- DATASET-PROJECT é o projeto que contém seu conjunto de dados.
- DATASET-NAME é o nome do conjunto de dados.
Crie um arquivo de texto
images.txtcom os nomes das imagens identificadas. Exemplo:ubuntu:18.04 debian:buster hello-world:latest redis:buster jupyter/tensorflow-notebookFaça o download de gcrane.
GO111MODULE=on go get github.com/google/go-containerregistry/cmd/gcraneCrie um script chamado
copy_images.shpara copiar sua lista de arquivos.#!/bin/bash images=$(cat images.txt) if [ -z "${AR_PROJECT}" ] then echo ERROR: AR_PROJECT must be set before running this exit 1 fi for img in ${images} do gcrane cp ${img} LOCATION-docker.pkg.dev/${AR_PROJECT}/${img} doneSubstitua
LOCATIONpelo local regional ou multirregional do repositório.Torne o script executável:
chmod +x copy_images.shExecute o script para copiar os arquivos:
AR_PROJECT=${PROJECT} ./copy_images.sh
Custos
Neste guia, usamos os seguintes componentes faturáveis do Google Cloud:
Identificar imagens para migrar
Pesquise os arquivos que você usa para criar e implantar as imagens de contêiner para se referir a referências a registros de terceiros. Depois, verifique a frequência com que você extrai as imagens.
Identificar referências em Dockerfiles
Execute esta etapa em um local em que seus Dockerfiles estão armazenados. Pode ser aqui que o código será verificado localmente ou no Cloud Shell se os arquivos estiverem disponíveis em uma VM.No diretório com Dockerfiles, execute o comando:
grep -inr -H --include Dockerfile\* "FROM" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
A resposta tem a aparência do exemplo a seguir.
./code/build/baseimage/Dockerfile:1:FROM debian:stretch
./code/build/ubuntubase/Dockerfile:1:FROM ubuntu:latest
./code/build/pythonbase/Dockerfile:1:FROM python:3.5-buster
Esse comando pesquisa todos os Dockerfiles no seu diretório e identifica a linha "FROM". Ajuste o comando conforme necessário para corresponder à maneira como você armazena os Dockerfiles.
Identificar referências em manifestos
Execute estas etapas em um local em que seus manifestos do GKE ou do Cloud Run estão armazenados. Pode ser aqui que o código será disponibilizado localmente ou no Cloud Shell se os arquivos estiverem disponíveis em uma VM.Execute os comandos anteriores para todos os clusters do GKE em todos os projetos doGoogle Cloud para cobertura total.
Identificar a frequência de pull de um registro de terceiros
Em projetos que extraem registros de terceiros, use informações sobre a frequência de extração de imagens para determinar se o uso está próximo ou acima do limite de taxa que o registro de terceiros impõe.
Coletar dados do registro
Crie um coletor de registros para exportar dados para o BigQuery. Um coletor de registro inclui um destino e uma consulta que seleciona as entradas de registro a serem exportadas. É possível criar um coletor consultando projetos individuais ou usar um script para coletar dados entre projetos.
Para criar um coletor para um único projeto:
Para criar um coletor para vários projetos:
Depois de criar um coletor, leva um tempo para que os dados fluam para as tabelas do BigQuery, dependendo da frequência com que imagens são extraídas.
Consultar frequência de pull
Depois que você tiver uma amostra representativa de pulls de imagens feitas por suas compilações, execute uma consulta para a frequência de pull.
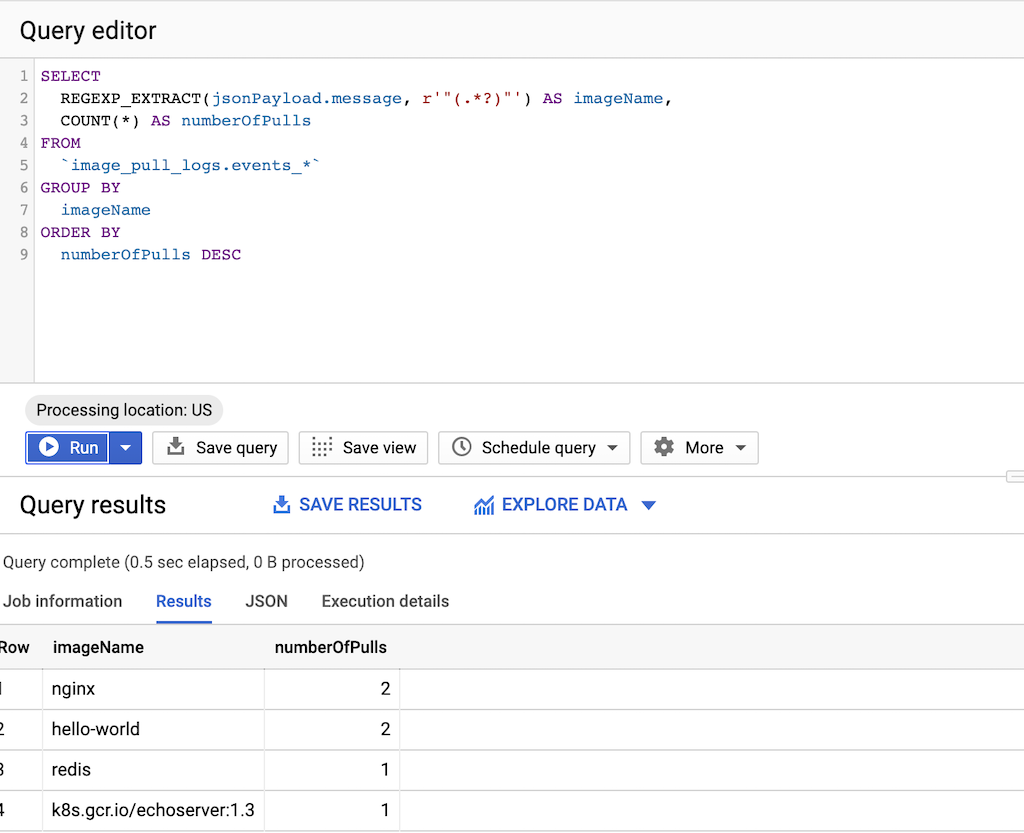
Copie imagens para o Artifact Registry
Depois de identificar imagens de registros de terceiros, será possível copiá-las para o Artifact Registry. A ferramenta gcrane ajuda no processo de cópia.
Verifique as permissões
Verifique se as permissões estão configuradas corretamente antes de atualizar e reimplantar as cargas de trabalho.
Para mais informações, consulte a documentação de controle de acesso.
Atualizar manifestos para referenciar o Artifact Registry
Atualize seus Dockerfiles e seus manifestos para se referir ao Artifact Registry em vez do registro de terceiros.
O exemplo a seguir mostra o manifesto que referencia um registro de terceiros:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Essa versão atualizada do manifesto aponta para uma imagem em
us-docker.pkg.dev.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: us-docker.pkg.dev/<AR_PROJECT>/nginx:1.14.2
ports:
- containerPort: 80
Para um grande número de manifestos, use sed ou outra ferramenta que processe atualizações em vários arquivos de texto.
Reimplantar cargas de trabalho
Reimplante as cargas de trabalho com os manifestos atualizados.
Acompanhe os novos pulls de imagem executando a seguinte consulta no console do BigQuery:
SELECT`
FORMAT_TIMESTAMP("%D %R", timestamp) as timeOfImagePull,
REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName,
COUNT(*) AS numberOfPulls
FROM
`image_pull_logs.events_*`
GROUP BY
timeOfImagePull,
imageName
ORDER BY
timeOfImagePull DESC,
numberOfPulls DESC
Todos os novos pulls de imagem precisam ser do Artifact Registry e conter a string
docker.pkg.dev.