Artifact Registry non monitora i registri di terze parti per gli aggiornamenti delle immagini che copi in Artifact Registry. Se vuoi incorporare una versione più recente di un'immagine nella tua pipeline, devi eseguirne il push in Artifact Registry.
Panoramica della migrazione
La migrazione delle immagini container include i seguenti passaggi:
- Configura i prerequisiti.
- Identifica le immagini di cui eseguire la migrazione.
- Cerca nei file Dockerfile e nei manifest di deployment riferimenti a registri di terze parti
- Determina la frequenza di pull delle immagini dai registri di terze parti utilizzando Cloud Logging e BigQuery.
- Copia le immagini identificate in Artifact Registry.
- Verifica che le autorizzazioni per il registro siano configurate correttamente, soprattutto se Artifact Registry e l'ambiente di deployment Google Cloudsi trovano in progetti diversi.
- Aggiorna i manifest per i tuoi deployment.
- Esegui di nuovo il deployment dei carichi di lavoro.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
-
Install the Google Cloud CLI.
-
Se utilizzi un provider di identità (IdP) esterno, devi prima accedere a gcloud CLI con la tua identità federata.
-
Per inizializzare gcloud CLI, esegui questo comando:
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
- Se non hai un repository Artifact Registry, allora creane uno e configura l'autenticazione per i client di terze parti che richiedono l'accesso al repository.
- Verifica le tue autorizzazioni. Devi disporre del ruolo IAM Proprietario o Editor nei progetti in cui esegui la migrazione delle immagini ad Artifact Registry.
- Esporta le seguenti variabili di ambiente:
export PROJECT=$(gcloud config get-value project)
- Verifica che sia installata la versione 1.13 o successiva di Go.
go version - Nella directory con i manifest GKE o Cloud Run,
esegui questo comando:
grep -inr -H --include \*.yaml "image:" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
./code/deploy/k8s/ubuntu16-04.yaml:63: image: busybox:1.31.1-uclibc ./code/deploy/k8s/master.yaml:26: image: kubernetes/redis:v1 - Per elencare le immagini in esecuzione su un cluster, esegui questo comando:
kubectl get all --all-namespaces -o yaml | grep image: | grep -i -v -E 'docker.pkg.dev|gcr.io'
- image: nginx image: nginx:latest - image: nginx - image: nginx -
Nella Google Cloud console, vai alla pagina Esplora log:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Logging.
Scegli un Google Cloud progetto.
Nella scheda Query Builder, inserisci la seguente query:
resource.type="k8s_pod" jsonPayload.reason="Pulling"Modifica il filtro della cronologia delle modifiche da Ultima ora a Ultimi 7 giorni.

Fai clic su Esegui query.
Dopo aver verificato che i risultati vengano visualizzati correttamente, fai clic su Azioni > Crea sink.
Nella finestra di dialogo Dettagli sink, completa quanto segue:
- Nel campo Nome sink, inserisci
image_pull_logs. - In Descrizione sink, inserisci una descrizione del sink.
- Nel campo Nome sink, inserisci
Fai clic su Avanti.
Nella finestra di dialogo Destinazione sink, seleziona i seguenti valori:
- Nel campo Seleziona servizio sink, seleziona Set di dati BigQuery.
- Nel campo Seleziona set di dati BigQuery, seleziona Crea un nuovo set di dati BigQuery e completa le informazioni richieste nella finestra di dialogo che si apre. Per saperne di più su come creare un set di dati BigQuery, consulta Creare set di dati.
- Fai clic su Crea set di dati.
Fai clic su Avanti.
Nella sezione Scegli i log da includere nel sink, la query corrisponde a quella eseguita nella scheda Query Builder.
Fai clic su Avanti.
(Facoltativo) Scegli i log da escludere dal sink. Per saperne di più su come eseguire query e filtrare i dati di Cloud Logging, consulta Linguaggio di query di Logging.
Fai clic su Crea sink.
Il sink di log è stato creato.
Esegui questi comandi in Cloud Shell:
PROJECTS="PROJECT-LIST" DESTINATION_PROJECT="DATASET-PROJECT" DATASET="DATASET-NAME" for source_project in $PROJECTS do gcloud logging --project="${source_project}" sinks create image_pull_logs bigquery.googleapis.com/projects/${DESTINATION_PROJECT}/datasets/${DATASET} --log-filter='resource.type="k8s_pod" jsonPayload.reason="Pulling"' donedove
- PROJECT-LIST è un elenco di ID progetto
separati da spazi. Google Cloud Ad esempio
project1 project2 project3. - DATASET-PROJECT è il progetto in cui vuoi archiviare il set di dati.
- DATASET-NAME è il nome del set di dati, ad esempio
image_pull_logs.
- PROJECT-LIST è un elenco di ID progetto
separati da spazi. Google Cloud Ad esempio
Esegui questa query:
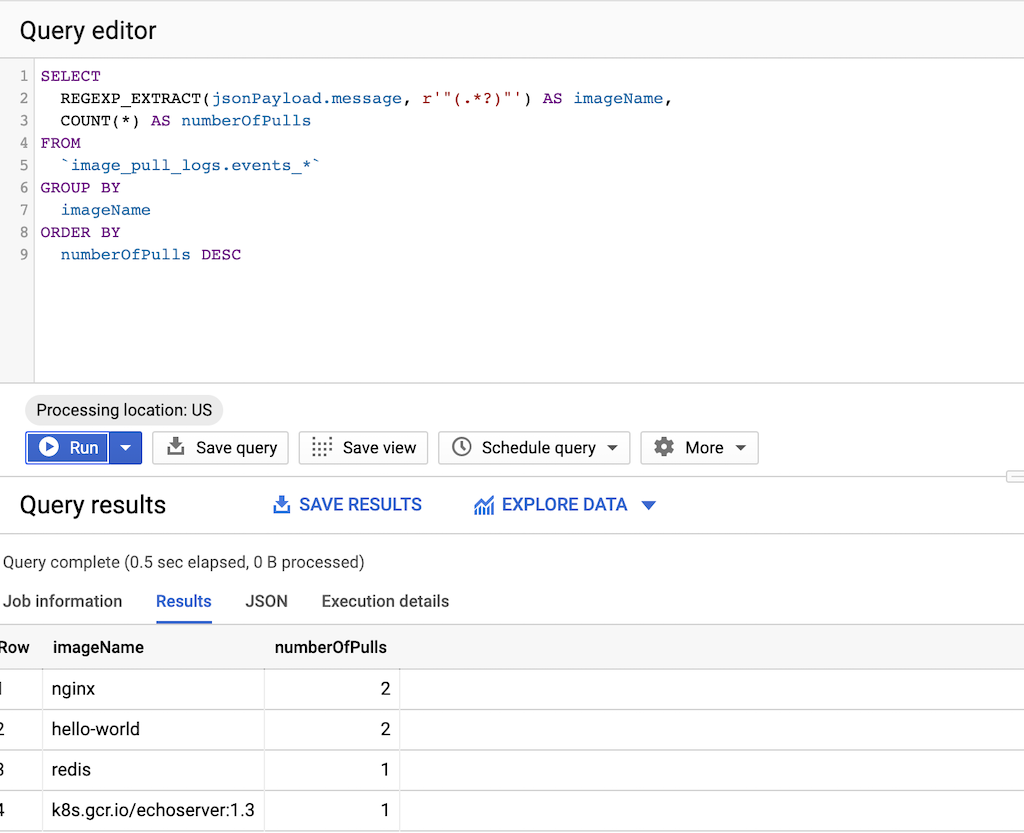
SELECT REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName, COUNT(*) AS numberOfPulls FROM `DATASET-PROJECT.DATASET-NAME.events_*` GROUP BY imageName ORDER BY numberOfPulls DESCdove
- DATASET-PROJECT è il progetto che contiene il set di dati.
- DATASET-NAME è il nome del set di dati.
Crea un file di testo
images.txtcon i nomi delle immagini che hai identificato. Ad esempio:ubuntu:18.04 debian:buster hello-world:latest redis:buster jupyter/tensorflow-notebookScarica gcrane.
GO111MODULE=on go get github.com/google/go-containerregistry/cmd/gcraneCrea uno script denominato
copy_images.shper copiare l'elenco dei file.#!/bin/bash images=$(cat images.txt) if [ -z "${AR_PROJECT}" ] then echo ERROR: AR_PROJECT must be set before running this exit 1 fi for img in ${images} do gcrane cp ${img} LOCATION-docker.pkg.dev/${AR_PROJECT}/${img} doneSostituisci
LOCATIONcon la posizione regionale o multi-regione del repository.Rendi eseguibile lo script:
chmod +x copy_images.shEsegui lo script per copiare i file:
AR_PROJECT=${PROJECT} ./copy_images.sh
Costi
Questa guida utilizza i seguenti componenti fatturabili di Google Cloud:
Identificare le immagini di cui eseguire la migrazione
Cerca nei file che utilizzi per creare e distribuire le immagini container riferimenti a registri di terze parti, poi controlla la frequenza con cui esegui il pull delle immagini.
Identificare i riferimenti nei Dockerfile
Esegui questo passaggio in una posizione in cui sono archiviati i Dockerfile. Potrebbe essere la posizione in cui il codice viene estratto localmente o in Cloud Shell se i file sono disponibili in una VM.Nella directory con i Dockerfile, esegui il comando:
grep -inr -H --include Dockerfile\* "FROM" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
L'output è simile al seguente esempio:
./code/build/baseimage/Dockerfile:1:FROM debian:stretch
./code/build/ubuntubase/Dockerfile:1:FROM ubuntu:latest
./code/build/pythonbase/Dockerfile:1:FROM python:3.5-buster
Questo comando cerca tutti i Dockerfile nella directory e identifica la riga "FROM". Modifica il comando in base alle tue esigenze per adattarlo al modo in cui memorizzi i Dockerfile.
Identificare i riferimenti nei manifest
Esegui questi passaggi in una posizione in cui sono archiviati i manifest di GKE o Cloud Run. Potrebbe essere la posizione in cui il codice viene estratto localmente o in Cloud Shell se i file sono disponibili in una VM.Esegui i comandi precedenti per tutti i cluster GKE in tutti i progettiGoogle Cloud per una copertura totale.
Identificare la frequenza di pull da un registry di terze parti
Nei progetti che eseguono il pull dai registri di terze parti, utilizza le informazioni sulla frequenza di pull delle immagini per determinare se il tuo utilizzo è vicino o superiore a eventuali limiti di frequenza imposti dal registro di terze parti.
Raccogliere i dati dei log
Crea un sink di log per esportare i dati in BigQuery. Un sink di log include una destinazione e una query che seleziona le voci di log da esportare. Puoi creare un sink eseguendo query su singoli progetti oppure puoi utilizzare uno script per raccogliere dati in più progetti.
Per creare un sink per un singolo progetto:
Per creare un sink per più progetti:
Dopo aver creato un sink, il flusso di dati verso le tabelle BigQuery richiede tempo, a seconda della frequenza con cui vengono estratte le immagini.
Query per la frequenza di pull
Una volta ottenuto un campione rappresentativo di pull di immagini effettuati dalle build, esegui una query per la frequenza di pull.
Copia le immagini in Artifact Registry
Dopo aver identificato le immagini dai registri di terze parti, puoi copiarle in Artifact Registry. Lo strumento gcrane ti aiuta nel processo di copia.
Verifica le autorizzazioni
Assicurati che le autorizzazioni siano configurate correttamente prima di aggiornare e ridistribuire i tuoi workload.
Per saperne di più, consulta la documentazione sul controllo dell'accesso.
Aggiorna i manifest per fare riferimento ad Artifact Registry
Aggiorna i Dockerfile e i manifest per fare riferimento ad Artifact Registry anziché al registro di terze parti.
L'esempio seguente mostra il manifest che fa riferimento a un registro di terze parti:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Questa versione aggiornata del manifest punta a un'immagine su
us-docker.pkg.dev.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: us-docker.pkg.dev/<AR_PROJECT>/nginx:1.14.2
ports:
- containerPort: 80
Per un numero elevato di manifest, utilizza sed o un altro strumento in grado di gestire gli aggiornamenti in molti file di testo.
Esegui di nuovo il deployment dei workload
Esegui nuovamente il deployment dei workload con i manifest aggiornati.
Tieni traccia dei nuovi pull di immagini eseguendo la seguente query nella console BigQuery:
SELECT`
FORMAT_TIMESTAMP("%D %R", timestamp) as timeOfImagePull,
REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName,
COUNT(*) AS numberOfPulls
FROM
`image_pull_logs.events_*`
GROUP BY
timeOfImagePull,
imageName
ORDER BY
timeOfImagePull DESC,
numberOfPulls DESC
Tutti i nuovi pull di immagini devono provenire da Artifact Registry e contenere la stringa
docker.pkg.dev.