O que é a arquitetura de microsserviços?
A arquitetura de microsserviços (geralmente chamada de microsserviços) refere-se a um estilo de arquitetura para o desenvolvimento de aplicativos. Os microsserviços permitem que um aplicativo grande seja separado em partes independentes menores, com cada parte tendo sua própria responsabilidade. Para atender a uma única solicitação do usuário, um aplicativo baseado em microsserviços pode chamar muitos microsserviços internos para compor a resposta.
Contêineres são um exemplo de arquitetura de microsserviços bem organizada e permitem que você se concentre no desenvolvimento dos serviços sem se preocupar com as dependências. Os aplicativos nativos da nuvem geralmente são criados como microsserviços usando contêineres.
Saiba como o Google Kubernetes Engine pode ajudar você a criar aplicativos baseados em microsserviços usando contêineres.
Tudo pronto para começar? Clientes novos recebem US$ 300 em créditos para usar no Google Cloud.
Definição da arquitetura de microsserviços
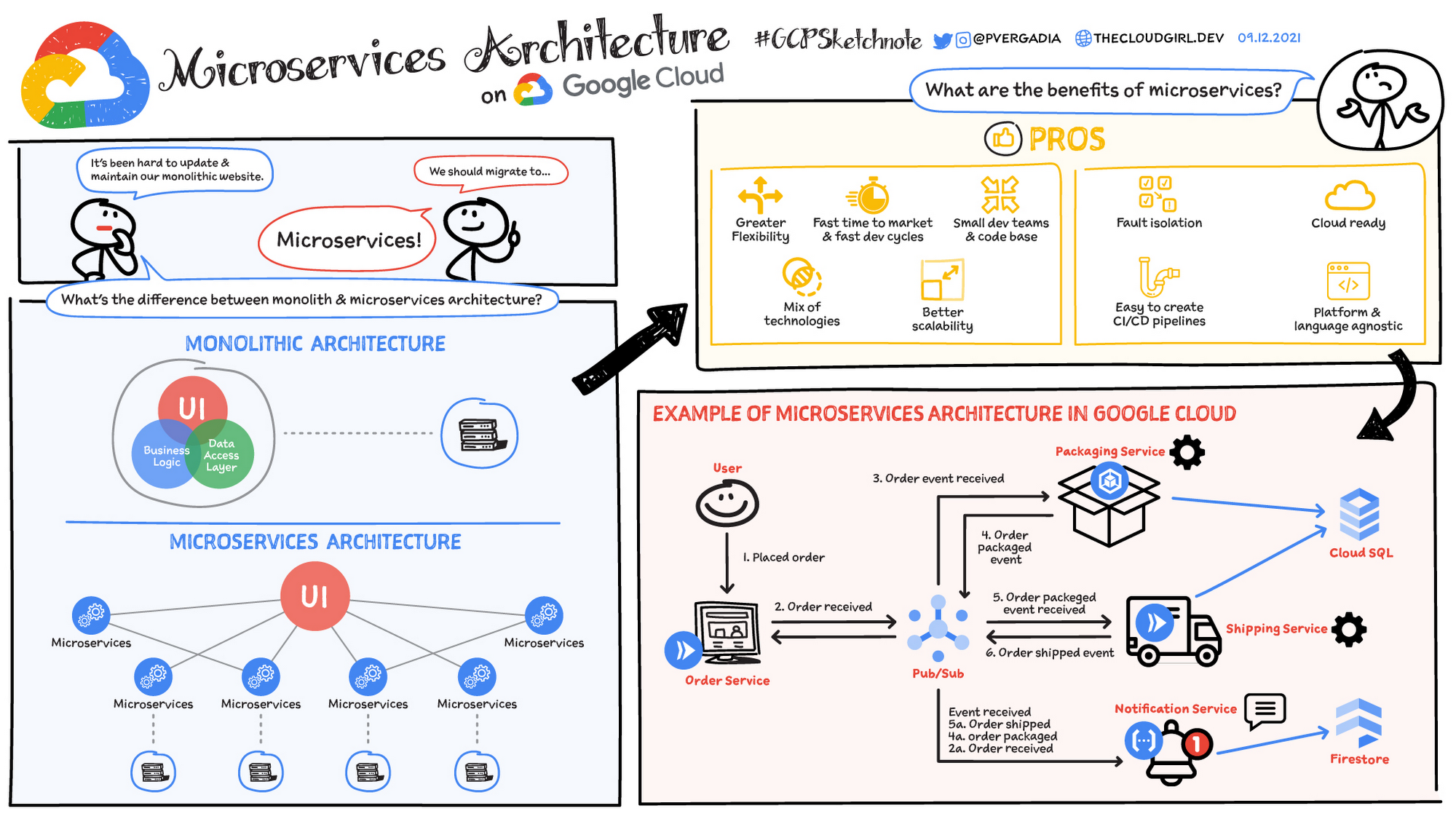
Uma arquitetura de microsserviços é um tipo de arquitetura em que o aplicativo é desenvolvido como uma coleção de serviços. Ela fornece o framework para desenvolver, implantar e manter diagramas e serviços de arquitetura de microsserviços de maneira independente.
Em uma arquitetura de microsserviços, cada microsserviço é um serviço único criado para acomodar um recurso do aplicativo e processar tarefas distintas. Cada microsserviço se comunica com outros serviços por meio de interfaces simples para resolver problemas comerciais.
Arquitetura monolítica x arquitetura de microsserviços
Os aplicativos monolíticos tradicionais são criados como uma unidade única e unificada. Todos os componentes estão acoplados de forma rígida, compartilhando recursos e dados. Isso pode gerar desafios na escalonabilidade, implantação e manutenção do aplicativo, especialmente à medida que ele se torna mais complexo. Em contraste, a arquitetura de microsserviços decompõe um aplicativo em um pacote de serviços pequenos e independentes. Cada microsserviço é independente, com código, dados e dependências próprios. Essa abordagem oferece várias vantagens em potencial:
- Escalonabilidade aprimorada: microsserviços individuais podem ser escalonados de forma independente com base nas necessidades específicas
- Mais agilidade: os microsserviços podem ser desenvolvidos, implantados e atualizados de forma independente, o que permite ciclos de lançamento mais rápidos.
- Resistência aprimorada: se um microsserviço falhar, isso não vai necessariamente afetar todo o aplicativo
- Diversidade de tecnologia: a flexibilidade dos microsserviços permite que as equipes usem a tecnologia mais adequada para cada serviço
Exemplos do setor
Muitas organizações de vários setores adotaram a arquitetura de microsserviços para enfrentar desafios específicos dos negócios e impulsionar a inovação. Confira alguns deles:
- E-commerce: muitas plataformas de e-commerce usam microsserviços para gerenciar diferentes aspectos das operações, como catálogo de produtos, carrinho de compras, processamento de pedidos e contas de clientes. Isso ajuda a empresa a escalonar serviços individuais com base na demanda, personalizar as experiências dos clientes e implantar novos recursos com rapidez.
- Serviços de streaming: os serviços de streaming geralmente dependem de microsserviços para lidar com tarefas como codificação de vídeo, entrega de conteúdo, autenticação de usuário e mecanismos de recomendação. Isso ajuda a oferecer experiências de streaming de alta qualidade para milhões de usuários ao mesmo tempo.
- Serviços financeiros: as instituições financeiras usam microsserviços para gerenciar vários aspectos das operações, como detecção de fraudes, processamento de pagamentos e gerenciamento de riscos. Isso permite que eles respondam rapidamente às mudanças nas condições do mercado, melhorem a segurança e sigam os requisitos regulatórios.
Para que a arquitetura de microsserviços é usada?
Normalmente, os microsserviços são usados para acelerar o desenvolvimento de aplicativos. Arquiteturas de microsserviços criadas usando Java são comuns, especialmente as do Spring Boot. Também é comum comparar microsserviços com a arquitetura orientada a serviços. Ambos têm o mesmo objetivo, que é dividir aplicativos monolíticos em componentes menores, mas usam abordagens diferentes. Veja alguns exemplos de arquitetura de microsserviços:
Migração de sites
Migração de sites
É possível migrar um site complexo hospedado em uma plataforma monolítica para uma plataforma de microsserviços baseada em nuvem e em contêiner.
Conteúdo de mídia
Conteúdo de mídia
Usando a arquitetura de microsserviços, os recursos de imagem e vídeo podem ser armazenados em um sistema de armazenamento de objetos escalonável e exibidos diretamente na Web ou em dispositivos móveis.
Transações e faturas
Transações e faturas
O processamento e a ordem de pagamentos podem ser separados como unidades de serviço independentes. Dessa forma, os pagamentos continuarão sendo aceitos se o faturamento não estiver funcionando.
Processamento de dados
Processamento de dados
Uma plataforma de microsserviços pode estender o suporte à nuvem para serviços de processamento de dados modulares existentes.
Produtos e serviços relacionados
Ao usar o Google Cloud, é possível implantar facilmente os microsserviços usando o serviço de contêiner gerenciado, o Google Kubernetes Engine ou a oferta totalmente gerenciada sem servidor, Cloud Run.
Dependendo do caso de uso, o Cloud SQL e outros produtos e serviços do Google Cloud podem ser totalmente integrados para dar suporte a arquiteturas de microsserviços.
 Google Kubernetes EngineServiço seguro e gerenciado do Kubernetes com escalonamento automático de quatro direções e suporte para vários clusters.
Google Kubernetes EngineServiço seguro e gerenciado do Kubernetes com escalonamento automático de quatro direções e suporte para vários clusters. Cloud RunPlataforma de computação totalmente gerenciada para implantação e escalonamento de aplicativos em contêineres com rapidez e segurança.
Cloud RunPlataforma de computação totalmente gerenciada para implantação e escalonamento de aplicativos em contêineres com rapidez e segurança. Cloud SQLServiço de banco de dados relacional totalmente gerenciado para MySQL, PostgreSQL e SQL Server.
Cloud SQLServiço de banco de dados relacional totalmente gerenciado para MySQL, PostgreSQL e SQL Server. AnthosModernize os aplicativos atuais e crie aplicativos nativos da nuvem em qualquer lugar para promover agilidade e reduzir custos.
AnthosModernize os aplicativos atuais e crie aplicativos nativos da nuvem em qualquer lugar para promover agilidade e reduzir custos.Solução
Desenvolvimento de aplicativos nativos da nuvemCrie, execute e opere aplicativos nativos da nuvem com o Google Cloud. Adote abordagens modernas como opções sem servidor, microsserviços e contêineres. Programe, crie, implante e gerencie rapidamente sem comprometer a segurança ou a qualidade.Solução
Como desbloquear aplicativos legados usando APIsProlongue a vida de aplicativos legados, crie serviços modernos e tenha agilidade para oferecer novas experiências usando a plataforma de gerenciamento de API do Google como uma camada de abstração sobre os serviços antigos.
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos do programa Sempre gratuito.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











