Che cos'è l'architettura dei microservizi?
L'architettura dei microservizi (spesso abbreviata in microservizi) si riferisce a uno stile architetturale per lo sviluppo di applicazioni. I microservizi consentono alle applicazioni di grandi dimensioni di essere separate in parti indipendenti più piccole, ognuna con un proprio ambito di responsabilità. Per gestire una singola richiesta utente, un'applicazione basata su microservizi può coinvolgere molti microservizi interni per scrivere la sua risposta.
I container sono un esempio di architettura di microservizi ideale, poiché ti consentono di concentrarti sullo sviluppo dei servizi senza preoccuparti delle dipendenze. Le moderne applicazioni cloud-native vengono in genere create come microservizi utilizzando i container.
Scopri in che modo Google Kubernetes Engine può aiutarti a creare applicazioni basate su microservizi utilizzando i container.
Iniziamo? I nuovi clienti ricevono 300 $ di crediti gratuiti da spendere su Google Cloud.
Definizione di architettura dei microservizi
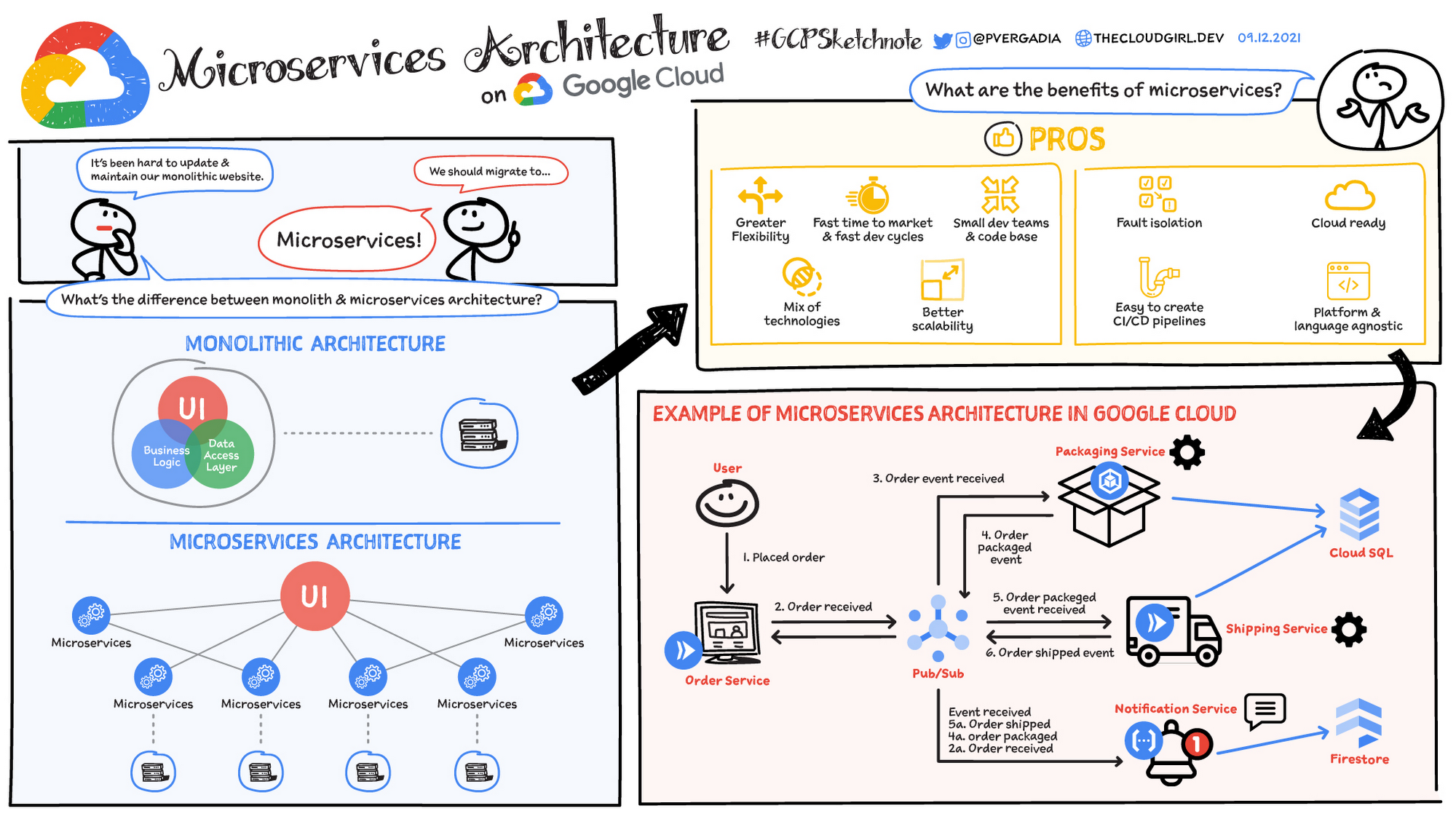
Un'architettura di microservizi è un tipo di architettura di applicazioni in cui l'applicazione viene sviluppata come raccolta di servizi. Fornisce il framework per sviluppare, eseguire il deployment e gestire in modo indipendente i diagrammi e i servizi di architettura dei microservizi.
All'interno di un'architettura di microservizi, ogni microservizio è un singolo servizio creato per ospitare una funzionalità dell'applicazione e gestire attività discrete. Ogni microservizio comunica con altri servizi attraverso interfacce semplici per risolvere problemi aziendali.
Architettura monolitica e dei microservizi
Le applicazioni monolitiche tradizionali sono create come una singola unità unificata. Tutti i componenti sono ad alto accoppiamento e condividono risorse e dati. Questo può comportare problemi di scalabilità, deployment e manutenzione dell'applicazione, soprattutto man mano che la sua complessità aumenta. Al contrario, l'architettura dei microservizi scompone un'applicazione in una suite di servizi più piccoli e indipendenti. Ogni microservizio è autonomo, con codice, dati e dipendenze propri. Questo approccio offre diversi potenziali vantaggi:
- Scalabilità migliorata: i singoli microservizi possono essere scalati in modo indipendente in base alle loro esigenze specifiche
- Maggiore agilità: i microservizi possono essere sviluppati, implementati e aggiornati in modo indipendente, consentendo cicli di rilascio più rapidi
- Resilienza migliorata: se un microservizio non funziona, non ha necessariamente un impatto sull'intera applicazione
- Diversità tecnologica: la flessibilità dei microservizi consente ai team di utilizzare la tecnologia più adatta per ciascun servizio
Esempi di settore
Molte organizzazioni in vari settori hanno adottato l'architettura dei microservizi per affrontare sfide aziendali specifiche e promuovere l'innovazione. Ecco alcuni esempi:
- E-commerce: molte piattaforme di e-commerce utilizzano i microservizi per gestire diversi aspetti delle loro operazioni, come il catalogo dei prodotti, il carrello degli acquisti, l'elaborazione degli ordini e gli account dei clienti. Questa architettura aiuta a scalare i singoli servizi in base alla domanda, a personalizzare le customer experience e a eseguire rapidamente il deployment di nuove funzionalità.
- Servizi di streaming: i servizi di streaming spesso si affidano ai microservizi per gestire attività come la codifica dei video, la distribuzione dei contenuti, l'autenticazione degli utenti e i motori per suggerimenti. Questo consente loro di offrire esperienze di streaming di alta qualità a milioni di utenti contemporaneamente.
- Servizi finanziari: gli istituti finanziari utilizzano i microservizi per gestire vari aspetti delle loro operazioni, come il rilevamento delle frodi, l'elaborazione dei pagamenti e la gestione dei rischi. Ciò consente loro di rispondere rapidamente alle mutevoli condizioni del mercato, migliorare la sicurezza e rispettare i requisiti normativi.
A che cosa serve l'architettura dei microservizi?
In genere, i microservizi vengono utilizzati per accelerare lo sviluppo di applicazioni. Le architetture di microservizi create con Java sono comuni, in particolare quelle di Spring Boot. È inoltre comune confrontare i microservizi con l'architettura orientata ai servizi. Entrambi hanno lo stesso obiettivo, ovvero suddividere le applicazioni monolitiche in componenti più piccoli, ma utilizzano approcci diversi. Ecco alcuni esempi di architettura di microservizi:
Migrazione di siti web
Migrazione di siti web
È possibile eseguire la migrazione di un sito web complesso ospitato su una piattaforma monolitica verso una piattaforma di microservizi basata su cloud e container.
Contenuti multimediali
Contenuti multimediali
Utilizzando l'architettura dei microservizi, le immagini e i file video possono essere archiviati in un sistema di archiviazione di oggetti scalabile e pubblicati direttamente sul web o su dispositivi mobili.
Transazioni e fatture
Transazioni e fatture
L'elaborazione e l'ordinamento dei pagamenti possono essere separati come unità di servizio indipendenti, in modo che i pagamenti continuino a essere accettati se la fatturazione non avviene correttamente.
Trattamento dati
Trattamento dati
Una piattaforma di microservizi può estendere il supporto cloud per i servizi di trattamento dati modulari esistenti.
Prodotti e servizi correlati
Quando utilizzi Google Cloud, puoi eseguire facilmente il deployment dei microservizi tramite il servizio container gestito, Google Kubernetes Engine, o l'offerta serverless completamente gestita, Cloud Run.
A seconda del caso d'uso, Cloud SQL e altri prodotti e servizi Google Cloud possono essere integrati immediatamente per supportare le architetture dei microservizi.
 Google Kubernetes EngineServizio Kubernetes protetto e gestito con scalabilità automatica a quattro vie e supporto multi-cluster.
Google Kubernetes EngineServizio Kubernetes protetto e gestito con scalabilità automatica a quattro vie e supporto multi-cluster. Cloud RunPiattaforma di computing completamente gestita per eseguire il deployment e scalare applicazioni containerizzate in modo rapido e sicuro.
Cloud RunPiattaforma di computing completamente gestita per eseguire il deployment e scalare applicazioni containerizzate in modo rapido e sicuro. Cloud SQLServizio di database relazionale completamente gestito per MySQL, PostgreSQL e SQL Server.
Cloud SQLServizio di database relazionale completamente gestito per MySQL, PostgreSQL e SQL Server. AnthosModernizza le applicazioni esistenti e crea app cloud-native ovunque per promuovere l'agilità e il risparmio sui costi.
AnthosModernizza le applicazioni esistenti e crea app cloud-native ovunque per promuovere l'agilità e il risparmio sui costi.Soluzione
Sviluppo di applicazioni cloud-nativeCrea, esegui e gestisci app cloud-native con Google Cloud. Adotta approcci moderni come serverless, microservizi e container. Scrivi codice, crea, esegui il deployment e gestisci rapidamente senza compromettere sicurezza o qualità.Soluzione
Sblocco di applicazioni legacy con l'utilizzo delle APIEstendi la durata delle applicazioni legacy, crea servizi moderni e offri rapidamente nuove esperienze con la piattaforma di gestione delle API Google come livello di astrazione superiore ai servizi esistenti.
Fai il prossimo passo
Inizia a creare su Google Cloud con 300 $ di crediti gratuiti e oltre 20 prodotti Always Free.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti











