Qu'est-ce que l'architecture de microservices ?
L'architecture de microservices (ou microservices) désigne un style d'architecture utilisé dans le développement d'applications. Elle permet de décomposer une application volumineuse en composants indépendants, chaque élément ayant ses propres responsabilités. Pour diffuser la requête d'un utilisateur unique, une application basée sur des microservices peut appeler plusieurs microservices internes pour composer sa réponse.
Les conteneurs sont un exemple parfait d'architecture de microservices, car ils vous permettent de vous concentrer sur le développement des services sans avoir à vous soucier des dépendances. Les applications cloud natives modernes sont généralement construites sous forme de microservices à l'aide de conteneurs.
Découvrez comment Google Kubernetes Engine peut vous aider à créer des applications basées sur des microservices à l'aide de conteneurs.
Prêt à vous lancer ? Les nouveaux clients bénéficient de 300 $ de crédits à dépenser sur Google Cloud.
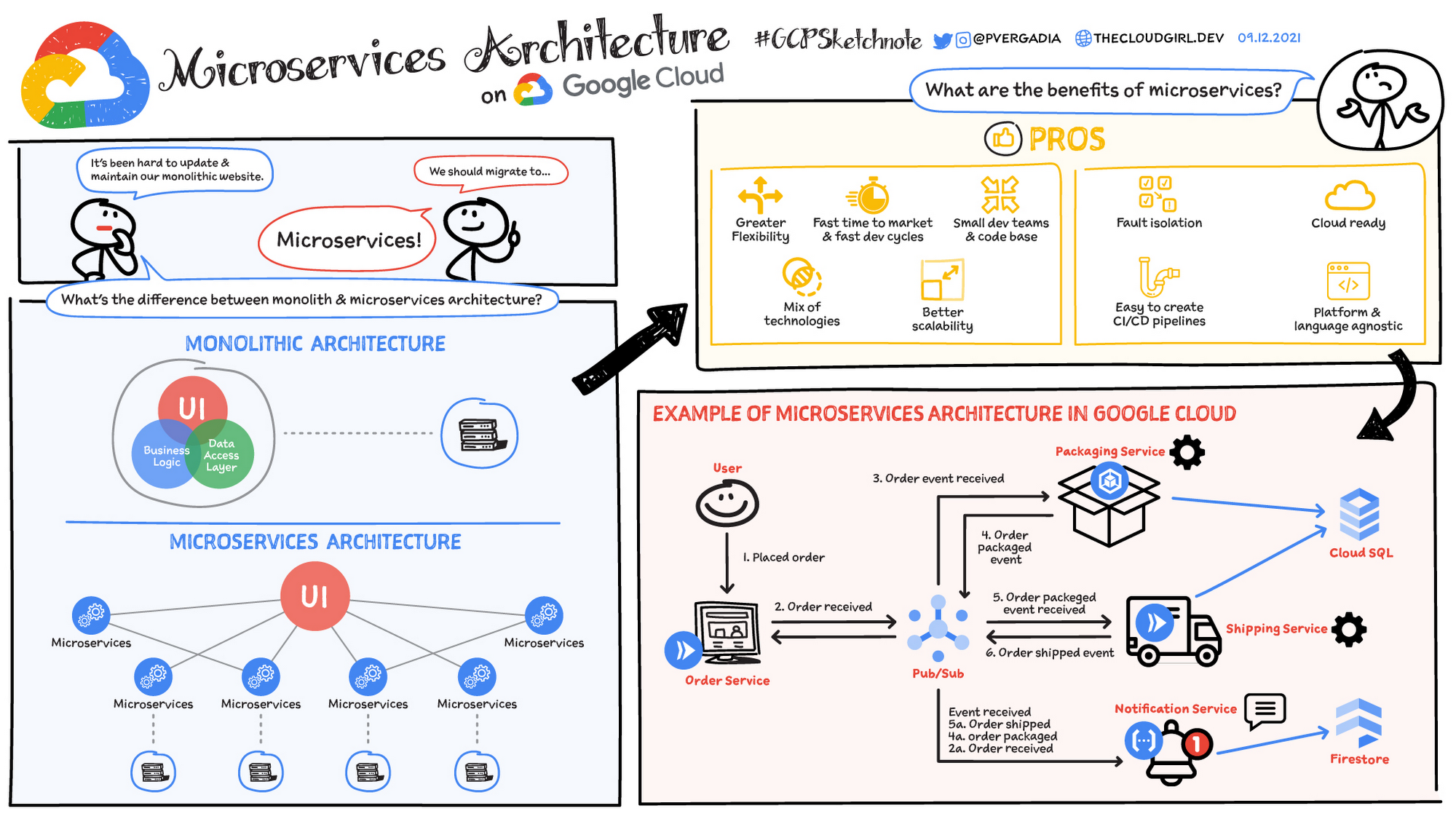
Définition de l'architecture de microservices
Une architecture de microservices est un type d'architecture d'application dans laquelle l'application est développée sous la forme d'un ensemble de services. Elle fournit le framework permettant de développer, déployer et gérer de manière indépendante des diagrammes et des services d'architecture de microservices.
Dans une architecture de microservices, chaque microservice est un service unique conçu pour accueillir une fonctionnalité d'application et gérer des tâches discrètes. Chaque microservice communique avec d'autres services via des interfaces simples afin de répondre à des problématiques métier.
Architecture monolithique ou de microservices
Les applications monolithiques traditionnelles sont conçues comme une seule unité unifiée. Tous les composants sont étroitement couplés et partagent des ressources et des données. Cela peut entraîner des difficultés au niveau de l'évolutivité, du déploiement et de la gestion de l'application, en particulier à mesure que sa complexité augmente. En revanche, l'architecture de microservices décompose une application en une suite de services indépendants de petite taille. Chaque microservice est autonome, avec son propre code, ses propres données et ses propres dépendances. Cette approche présente plusieurs avantages potentiels :
- Amélioration de l'évolutivité : les microservices individuels peuvent être évolutifs de manière indépendante en fonction de leurs besoins spécifiques
- Agilité accrue : les microservices peuvent être développés, déployés et mis à jour indépendamment, ce qui permet d'accélérer les cycles de publication.
- Résilience améliorée : si un microservice échoue, cela n'affecte pas nécessairement l'ensemble de l'application.
- Diversité technologique : la flexibilité des microservices permet aux équipes d'utiliser la technologie la plus adaptée à chaque service.
Exemples de secteurs
De nombreuses organisations de divers secteurs ont adopté une architecture de microservices pour relever des défis métier spécifiques et stimuler l'innovation. Voici quelques exemples :
- E-commerce : de nombreuses plates-formes d'e-commerce utilisent des microservices pour gérer différents aspects de leurs opérations, comme le catalogue de produits, le panier d'achat, le traitement des commandes et les comptes client. Cela leur permet d'adapter chaque service à la demande, de personnaliser l'expérience client et de déployer rapidement de nouvelles fonctionnalités.
- Services de streaming : les services de streaming s'appuient souvent sur des microservices pour gérer des tâches telles que l'encodage vidéo, la diffusion de contenu, l'authentification des utilisateurs et les moteurs de recommandations. Cela leur permet de proposer des expériences de streaming de haute qualité à des millions d'utilisateurs simultanément.
- Services financiers : les établissements financiers utilisent des microservices pour gérer différents aspects de leurs opérations, comme la détection des fraudes, le traitement des paiements et la gestion des risques. Cela leur permet de réagir rapidement à l'évolution des conditions du marché, d'améliorer la sécurité et de respecter les exigences réglementaires.
À quoi sert l'architecture de microservices ?
En général, les microservices sont utilisés pour accélérer le développement d'applications. Les architectures de microservices créées à l'aide de Java sont courantes, en particulier les architectures Spring Boot. Il est également courant de comparer les microservices à une architecture orientée services. Les deux architectures ont le même objectif, c'est-à-dire diviser des applications monolithiques en composants plus petits, mais elles ont des approches différentes. Voici quelques exemples d'architectures de microservices :
Migration de sites Web
Migration de sites Web
Un site Web complexe hébergé sur une plate-forme monolithique peut être migré vers une plate-forme de microservices dans le cloud, basée sur des conteneurs.
Contenu multimédia
Contenu multimédia
Grâce à l'architecture de microservices, les images et les éléments vidéo peuvent être stockés dans un système de stockage d'objets évolutif, et diffusés directement sur le Web ou sur mobile.
Transactions et factures
Transactions et factures
Le traitement et le règlement des paiements peuvent être séparés sous la forme d'unités de services indépendantes afin que les paiements restent acceptés si la facturation ne fonctionne pas.
Traitement des données
Traitement des données
Une plate-forme de microservices peut étendre la compatibilité cloud pour les services de traitement de données modulaires existants.
Produits et services associés
Lorsque vous utilisez Google Cloud, vous pouvez facilement déployer des microservices à l'aide du service de conteneurs géré, Google Kubernetes Engine, ou de la solution sans serveur entièrement gérée, Cloud Run.
Selon le cas d'utilisation, Cloud SQL et les autres produits et services Google Cloud peuvent être facilement intégrés pour être compatibles avec les architectures de microservices.
 Google Kubernetes EngineService Kubernetes sécurisé et géré avec autoscaling quadridirectionnel et compatibilité multicluster.
Google Kubernetes EngineService Kubernetes sécurisé et géré avec autoscaling quadridirectionnel et compatibilité multicluster. Cloud RunPlate-forme de calcul entièrement gérée destinée au déploiement et au scaling rapide et sécurisé des applications en conteneurs
Cloud RunPlate-forme de calcul entièrement gérée destinée au déploiement et au scaling rapide et sécurisé des applications en conteneurs Cloud SQLService de base de données relationnelle entièrement géré pour MySQL, PostgreSQL et SQL Server.
Cloud SQLService de base de données relationnelle entièrement géré pour MySQL, PostgreSQL et SQL Server. AnthosModernisez vos applications existantes et développez des applications cloud natives dans n'importe quel environnement, pour favoriser l'agilité et réaliser des économies.
AnthosModernisez vos applications existantes et développez des applications cloud natives dans n'importe quel environnement, pour favoriser l'agilité et réaliser des économies.Solution
Développement d'applications cloud nativesCréez, exécutez et exploitez des applications cloud natives avec Google Cloud. Adoptez des approches modernes telles que des solutions sans serveur, des microservices et des conteneurs. Codez, développez, déployez et gérez rapidement sans compromettre la sécurité ni la qualité.Solution
Accéder aux anciennes applications à l'aide des APIProlongez la durée de vie des anciennes applications, créez des services modernes et proposez rapidement de nouvelles expériences en utilisant la plate-forme de gestion des API de Google en tant que couche d'abstraction par-dessus les services existants.
Passez à l'étape suivante
Profitez de 300 $ de crédits gratuits et de plus de 20 produits Always Free pour commencer à créer des applications sur Google Cloud.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouvez un partenairePoursuivez vos recherches
Voir tous les produits











