¿Qué es la arquitectura de microservicios?
La arquitectura de microservicios (a menudo acortada como microservicios) se refiere a un estilo de arquitectura para desarrollar aplicaciones. Permiten dividir una aplicación grande en partes independientes más pequeñas y que cada una de ellas tenga su propio ámbito de responsabilidad. Una aplicación basada en microservicios puede llamar a muchos microservicios internos para redactar su respuesta con la finalidad de entregar una única solicitud de usuario.
Los contenedores son un ejemplo adecuado de arquitectura de microservicios, ya que te permiten enfocarte en desarrollar los servicios sin preocuparte por las dependencias. Por lo general, las aplicaciones nativas de la nube se compilan como microservicios mediante contenedores.
Obtén información sobre cómo Google Kubernetes Engine puede ayudarte a crear aplicaciones basadas en microservicios con contenedores.
¿Todo listo para comenzar? Los clientes nuevos obtienen $300 en créditos gratuitos que pueden usar en Google Cloud.
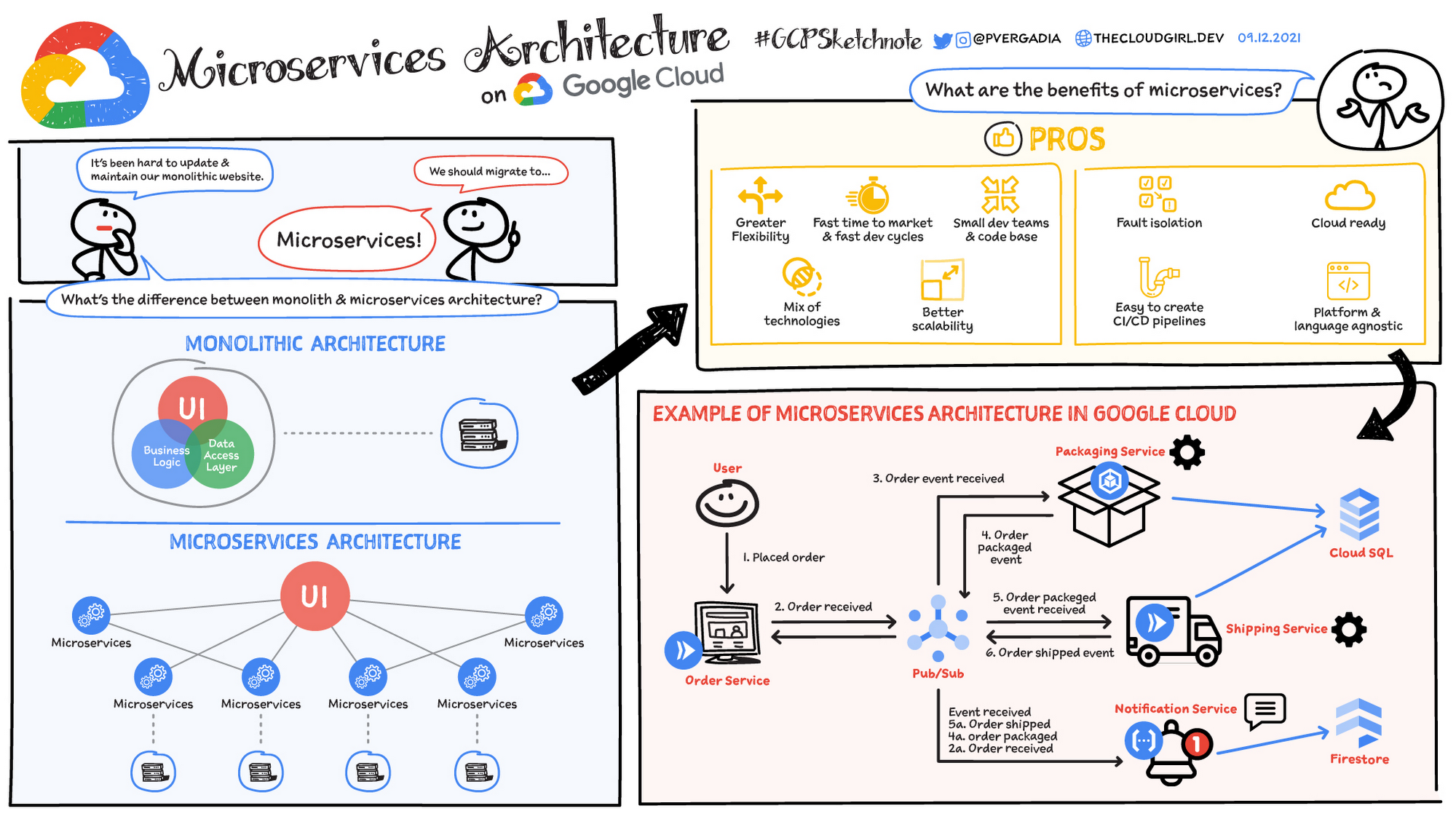
Arquitectura de microservicios definida
Una arquitectura de microservicios es un tipo de arquitectura de aplicación en el que la aplicación se desarrolla como una colección de servicios. Proporciona el framework para desarrollar, implementar y mantener los diagramas y servicios de arquitectura de microservicios de forma independiente.
Dentro de una arquitectura de microservicios, cada microservicio es un único servicio compilado para adaptarse a una característica de la aplicación y controlar tareas discretas. Cada microservicio se comunica con otros servicios a través de interfaces simples para resolver problemas empresariales.
Arquitectura monolítica vs. arquitectura de microservicios
Las aplicaciones monolíticas tradicionales se crean como una unidad única y unificada. Todos los componentes están estrechamente acoplados y comparten recursos y datos. Esto puede generar desafíos en la escalabilidad, la implementación y el mantenimiento de la aplicación, especialmente a medida que aumenta su complejidad. En cambio, la arquitectura de microservicios descompone una aplicación en un paquete de servicios pequeños y autónomos. Cada microservicio es independiente, con su propio código, datos y dependencias. Este enfoque ofrece varias ventajas potenciales:
- Escalabilidad mejorada: Los microservicios individuales se pueden escalar de forma independiente según sus necesidades específicas
- Agilidad mejorada: Los microservicios se pueden desarrollar, implementar y actualizar de forma independiente, lo que permite ciclos de lanzamiento más rápidos
- Resiliencia mejorada: Si falla un microservicio, no necesariamente afecta a toda la aplicación
- Diversidad tecnológica: La flexibilidad de los microservicios permite que los equipos usen la tecnología más adecuada para cada servicio
Ejemplos de la industria
Muchas organizaciones de diversos sectores adoptaron la arquitectura de microservicios para abordar desafíos empresariales específicos y fomentar la innovación. Estos son algunos ejemplos:
- Comercio electrónico: Muchas plataformas de comercio electrónico usan microservicios para administrar diferentes aspectos de sus operaciones, como el catálogo de productos, el carrito de compras, el procesamiento de pedidos y las cuentas de clientes. Esto les ayuda a escalar servicios individuales según la demanda, personalizar las experiencias de los clientes y, además, implementar nuevas funciones con rapidez.
- Servicios de transmisión: Los servicios de transmisión suelen depender de microservicios para realizar tareas como la codificación de videos, la entrega de contenido, la autenticación de usuarios y los motores de recomendaciones. Esto les permite ofrecer experiencias de transmisión de alta calidad a millones de usuarios de forma simultánea.
- Servicios financieros: Las instituciones financieras usan microservicios para administrar varios aspectos de sus operaciones, como la detección de fraudes, el procesamiento de pagos y la administración de riesgos. Esto les permite responder rápidamente a los cambios en las condiciones del mercado, mejorar la seguridad y cumplir con los requisitos normativos.
¿Para qué se usa la arquitectura de microservicios?
Por lo general, los microservicios se usan para acelerar el desarrollo de las aplicaciones. Las arquitecturas de microservicios compiladas con Java son comunes, especialmente las de Spring Boot. También es común comparar los microservicios con la arquitectura orientada al servicio. Ambos tienen el mismo objetivo, que es dividir las aplicaciones monolíticas en componentes más pequeños, pero tienen enfoques diferentes. Estos son algunos ejemplos de arquitectura de microservicios:
Migración del sitio web
Migración del sitio web
Un sitio web complejo alojado en una plataforma monolítica se puede migrar a una plataforma de microservicios basada en la nube y en contenedores.
Contenido multimedia
Contenido multimedia
El uso de la arquitectura de microservicios, las imágenes y los elementos de video se pueden almacenar en un sistema de almacenamiento de objetos escalable y se puede entregar de forma directa a la Web o a dispositivos móviles.
Transacciones y facturas
Transacciones y facturas
El procesamiento y el orden de pagos se puede separar como unidades de servicio independientes, para que los pagos se acepten si la facturación no funciona.
Procesamiento de datos
Procesamiento de datos
Una plataforma de microservicios puede extender la compatibilidad con la nube para servicios de procesamiento de datos modular existentes.
Productos y servicios relacionados
Cuando usas Google Cloud, puedes implementar microservicios con facilidad mediante el servicio de contenedores administrado, Google Kubernetes Engine o la oferta sin servidores completamente administrada, Cloud Run.
Según el caso de uso, Cloud SQL y otros productos y servicios de Google Cloud se pueden integrar con facilidad para admitir arquitecturas de microservicios.
 Google Kubernetes EngineServicio de Kubernetes seguro y administrado con ajuste de escala automático en cuatro direcciones y compatibilidad con varios clústeres.
Google Kubernetes EngineServicio de Kubernetes seguro y administrado con ajuste de escala automático en cuatro direcciones y compatibilidad con varios clústeres. Cloud RunPlataforma de procesamiento completamente administrada para implementar y escalar aplicaciones en contenedores de forma rápida y segura.
Cloud RunPlataforma de procesamiento completamente administrada para implementar y escalar aplicaciones en contenedores de forma rápida y segura. Cloud SQLServicio de bases de datos relacionales completamente administrado para MySQL, PostgreSQL y SQL Server.
Cloud SQLServicio de bases de datos relacionales completamente administrado para MySQL, PostgreSQL y SQL Server. AnthosModerniza las aplicaciones existentes y compila apps nativas de la nube en cualquier lugar a fin de promover la agilidad y la reducción de costos.
AnthosModerniza las aplicaciones existentes y compila apps nativas de la nube en cualquier lugar a fin de promover la agilidad y la reducción de costos.Solución
Desarrollo de aplicaciones nativas de la nubeCompila, ejecuta y opera aplicaciones nativas de la nube con Google Cloud. Adopta enfoques modernos, como el modelo sin servidores, los microservicios y los contenedores. Escribe código, compila, implementa y administra con rapidez y sin sacrificar la seguridad ni la calidad.Solución
Desbloquea aplicaciones heredadas mediante las APIExtiende la vida de las aplicaciones heredadas, compila servicios modernos y ofrece experiencias nuevas rápidamente con la plataforma administrativa de la API de Google como una capa de abstracción adicional a los servicios existentes.
Da el siguiente paso
Comienza a desarrollar en Google Cloud con el crédito gratis de $300 y los más de 20 productos del nivel Siempre gratuito.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos











