Este documento descreve duas arquiteturas de referência que ajudam a criar uma plataforma de aprendizagem federada Google Cloud no Google Kubernetes Engine (GKE). As arquiteturas de referência e os recursos associados descritos neste documento suportam o seguinte:
- Aprendizagem federada entre silos
- Aprendizagem federada multidispositivos, baseada na arquitetura entre silos
Os públicos-alvo deste documento são arquitetos da nuvem e engenheiros de IA e ML que querem implementar exemplos de utilização da aprendizagem federada noGoogle Cloud. Também se destina a decisores que estão a avaliar se devem implementar a aprendizagem federada no Google Cloud.
Arquitetura
Os diagramas nesta secção mostram uma arquitetura entre silos e uma arquitetura entre dispositivos para a aprendizagem federada. Para saber mais sobre as diferentes aplicações destas arquiteturas, consulte Exemplos de utilização.
Arquitetura entre silos
O diagrama seguinte mostra uma arquitetura que suporta a aprendizagem federada entre silos:

O diagrama anterior mostra um exemplo simplista de uma arquitetura entre silos. No diagrama, todos os recursos estão no mesmo projeto numa Google Cloud organização. Estes recursos incluem o modelo de cliente local, o modelo de cliente global e as respetivas cargas de trabalho de aprendizagem federada associadas.
Esta arquitetura de referência pode ser modificada para suportar várias configurações para silos de dados. Os membros do consórcio podem alojar os respetivos silos de dados das seguintes formas:
- No Google Cloud, na mesma Google Cloud organização e no mesmo Google Cloud projeto.
- Em Google Cloud, na mesma Google Cloud organização, em diferentes Google Cloud projetos.
- No Google Cloud, em diferentes Google Cloud organizações.
- Em ambientes privados, no local ou noutras nuvens públicas.
Para que os membros participantes possam colaborar, têm de estabelecer canais de comunicação seguros entre os respetivos ambientes. Para mais informações sobre o papel dos membros participantes no esforço de aprendizagem federada, como colaboram e o que partilham entre si, consulte os Exemplos de utilização.
A arquitetura inclui os seguintes componentes:
- Uma rede da nuvem virtual privada (VPC) e uma sub-rede.
- Um
cluster do GKE privado que ajuda a fazer o seguinte:
- Isolar os nós do cluster da Internet.
- Limite a exposição dos nós do cluster e do plano de controlo à Internet criando um cluster do GKE privado com redes autorizadas.
- Use nós de cluster protegidos que usam uma imagem do sistema operativo fortalecida.
- Ative o Dataplane V2 para uma rede Kubernetes otimizada.
- Node pools do GKE dedicados: cria um node pool dedicado para alojar exclusivamente apps e recursos de inquilinos. Os nós têm restrições para garantir que apenas as cargas de trabalho do inquilino são agendadas nos nós do inquilino. Os outros recursos de cluster estão alojados no pool de nós principal.
Encriptação de dados (ativada por predefinição):
- Dados em repouso.
- Dados em trânsito.
- Segredos do cluster na camada de aplicação.
Encriptação de dados em utilização, ativando opcionalmente os nós confidenciais do Google Kubernetes Engine.
Regras de firewall da VPC que aplicam o seguinte:
- Regras de base que se aplicam a todos os nós no cluster.
- Regras adicionais que se aplicam apenas aos nós no conjunto de nós do inquilino. Estas regras de firewall limitam a entrada e a saída de nós de inquilino.
Cloud NAT para permitir a saída para a Internet.
Registos do Cloud DNS para ativar o acesso privado à Google de modo que as apps no cluster possam aceder às APIs Google sem passar pela Internet.
Contas de serviço que são as seguintes:
- Uma conta de serviço dedicada para os nós no conjunto de nós do inquilino.
- Uma conta de serviço dedicada para as apps de inquilino usarem com a federação de identidades da carga de trabalho.
Suporte para a utilização de Grupos Google para o controlo de acesso baseado em funções (CABF) do Kubernetes.
Um repositório Git para armazenar descritores de configuração.
Um repositório do Artifact Registry para armazenar imagens de contentores.
Config Sync e Policy Controller para implementar a configuração e as políticas.
Gateways de malha de serviços na nuvem para permitir seletivamente o tráfego de entrada e saída do cluster.
Contentores do Cloud Storage para armazenar ponderações de modelos globais e locais.
Acesso a outras APIs Google e Google Cloud . Por exemplo, uma carga de trabalho de preparação pode ter de aceder a dados de preparação armazenados no Cloud Storage, no BigQuery ou no Cloud SQL.
Arquitetura multidispositivos
O diagrama seguinte mostra uma arquitetura que suporta a aprendizagem federada em vários dispositivos:
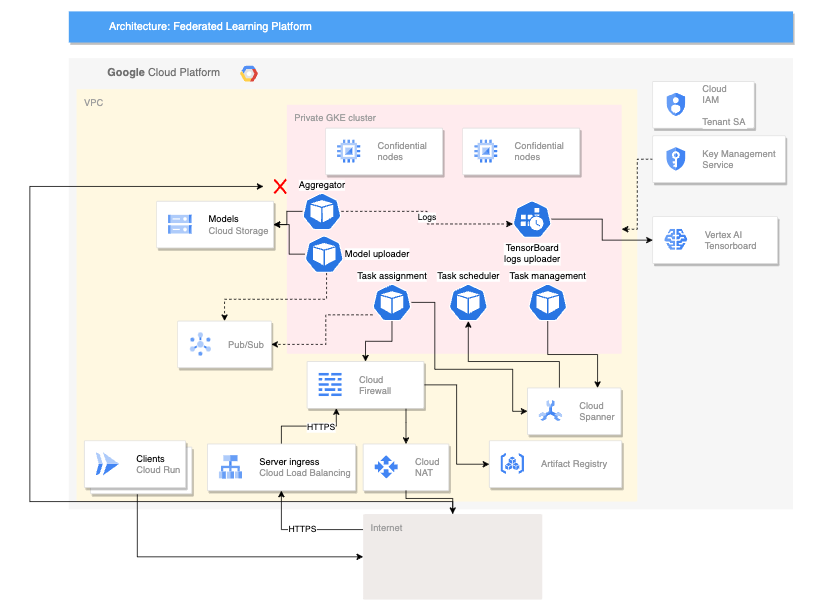
A arquitetura multidispositivos anterior baseia-se na arquitetura entre silos com a adição dos seguintes componentes:
- Um serviço do Cloud Run que simula dispositivos a estabelecer ligação ao servidor
- Um serviço de autoridade de certificação que cria certificados privados para o servidor e os clientes executar
- Um Vertex AI TensorBoard para visualizar o resultado da preparação
- Um contentor do Cloud Storage para armazenar o modelo consolidado
- O cluster privado do GKE que usa nós confidenciais como o respetivo conjunto principal para ajudar a proteger os dados em utilização
A arquitetura multidispositivo usa componentes do projeto da Federated Compute Platform (FCP) de código aberto. Este projeto inclui o seguinte:
- Código do cliente para comunicar com um servidor e executar tarefas nos dispositivos
- Um protocolo para comunicação cliente-servidor
- Pontos de ligação com o TensorFlow Federated para facilitar a definição dos seus cálculos federados
Os componentes da FCP apresentados no diagrama anterior podem ser implementados como um conjunto de microsserviços. Estes componentes fazem o seguinte:
- Agregador: esta tarefa lê os gradientes do dispositivo e calcula o resultado agregado com a privacidade diferencial.
- Coletor: esta tarefa é executada periodicamente para consultar tarefas ativas e gradientes encriptados. Estas informações determinam quando a agregação começa.
- Carregador de modelos: esta tarefa recebe eventos e publica resultados para que os dispositivos possam transferir modelos atualizados.
- Atribuição de tarefas: este serviço de front-end distribui tarefas de preparação para dispositivos.
- Gestão de tarefas: este trabalho gere tarefas.
- Task-scheduler: esta tarefa é executada periodicamente ou é acionada por eventos específicos.
Produtos usados
As arquiteturas de referência para ambos os exemplos de utilização da aprendizagem federada usam os seguintes componentes: Google Cloud
- Google Cloud Kubernetes Engine (GKE): O GKE fornece a plataforma fundamental para a aprendizagem federada.
- TensorFlow Federated (TFF): O TFF oferece uma framework de código aberto para aprendizagem automática e outros cálculos em dados descentralizados.
O GKE também oferece as seguintes capacidades à sua plataforma de aprendizagem federada:
- Alojamento do coordenador da aprendizagem federada: o coordenador da aprendizagem federada é responsável pela gestão do processo de aprendizagem federada. Esta gestão inclui tarefas como distribuir o modelo global aos participantes, agregar atualizações dos participantes e atualizar o modelo global. O GKE pode ser usado para alojar o coordenador da aprendizagem federada de forma altamente disponível e escalável.
- Alojamento de participantes da aprendizagem federada: os participantes da aprendizagem federada são responsáveis pela preparação do modelo global nos respetivos dados locais. O GKE pode ser usado para alojar participantes da aprendizagem federada de forma segura e isolada. Esta abordagem pode ajudar a garantir que os dados dos participantes são mantidos localmente.
- Fornecer um canal de comunicação seguro e escalável: os participantes da aprendizagem federada têm de poder comunicar com o coordenador da aprendizagem federada de forma segura e escalável. O GKE pode ser usado para fornecer um canal de comunicação seguro e escalável entre os participantes e o coordenador.
- Gerir o ciclo de vida das implementações de aprendizagem federada: o GKE pode ser usado para gerir o ciclo de vida das implementações de aprendizagem federada. Esta gestão inclui tarefas como o aprovisionamento de recursos, a implementação da plataforma de aprendizagem federada e a monitorização do desempenho da plataforma de aprendizagem federada.
Além destas vantagens, o GKE também oferece várias funcionalidades que podem ser úteis para implementações de aprendizagem federada, como as seguintes:
- Clusters regionais: o GKE permite-lhe criar clusters regionais, o que ajuda a melhorar o desempenho das implementações de aprendizagem federada reduzindo a latência entre os participantes e o coordenador.
- Políticas de rede: o GKE permite-lhe criar políticas de rede, o que ajuda a melhorar a segurança das implementações de aprendizagem federada controlando o fluxo de tráfego entre os participantes e o coordenador.
- Equilíbrio de carga: o GKE oferece várias opções de equilíbrio de carga, o que ajuda a melhorar a escalabilidade das implementações de aprendizagem federada através da distribuição do tráfego entre os participantes e o coordenador.
O TFF oferece as seguintes funcionalidades para facilitar a implementação de exemplos de utilização da aprendizagem federada:
- A capacidade de expressar declarativamente cálculos federados, que são um conjunto de passos de processamento executados num servidor e num conjunto de clientes. Estes cálculos podem ser implementados em diversos ambientes de tempo de execução.
- Os agregadores personalizados podem ser criados através do código aberto do TFF.
- Suporte para uma variedade de algoritmos de aprendizagem federada, incluindo os seguintes algoritmos:
- Média federada:
um algoritmo que calcula a média dos parâmetros do modelo dos clientes participantes. É particularmente adequado para exemplos de utilização em que os dados são relativamente homogéneos e o modelo não é demasiado complexo. Seguem-se alguns exemplos de utilização típicos:
- Recomendações personalizadas: uma empresa pode usar a média federada para preparar um modelo que recomenda produtos aos utilizadores com base no respetivo histórico de compras.
- Deteção de fraudes: um consórcio de bancos pode usar a média federada para preparar um modelo que deteta transações fraudulentas.
- Diagnóstico médico: um grupo de hospitais pode usar a média federada para preparar um modelo que diagnostica o cancro.
- Descida do gradiente estocástico federado (FedSGD): um algoritmo que usa a descida do gradiente estocástico para atualizar os parâmetros do modelo. É adequado para exemplos de utilização em que os dados são heterogéneos e o modelo é complexo. Seguem-se alguns exemplos de utilização típicos:
- Processamento de linguagem natural: uma empresa pode usar o FedSGD para preparar um modelo que melhora a precisão do reconhecimento de voz.
- Reconhecimento de imagens: uma empresa pode usar o FedSGD para preparar um modelo que possa identificar objetos em imagens.
- Manutenção preditiva: uma empresa pode usar o FedSGD para preparar um modelo que preveja quando é provável que uma máquina avarie.
- Federated Adam:
Um algoritmo que usa o otimizador Adam para atualizar os parâmetros do modelo.
Seguem-se alguns exemplos de utilização típicos:
- Sistemas de recomendação: uma empresa pode usar o algoritmo Adam federado para preparar um modelo que recomenda produtos aos utilizadores com base no respetivo histórico de compras.
- Classificação: uma empresa pode usar o Adam federado para preparar um modelo que classifique os resultados da pesquisa.
- Previsão da taxa de cliques: uma empresa pode usar o Adam federado para formar um modelo que prevê a probabilidade de um utilizador clicar num anúncio.
- Média federada:
um algoritmo que calcula a média dos parâmetros do modelo dos clientes participantes. É particularmente adequado para exemplos de utilização em que os dados são relativamente homogéneos e o modelo não é demasiado complexo. Seguem-se alguns exemplos de utilização típicos:
Exemplos de utilização
Esta secção descreve exemplos de utilização para os quais as arquiteturas de vários silos e vários dispositivos são escolhas adequadas para a sua plataforma de aprendizagem federada.
A aprendizagem federada é uma definição de aprendizagem automática em que muitos clientes preparam colaborativamente um modelo. Este processo é liderado por um coordenador central e os dados de preparação permanecem descentralizados.
No paradigma da aprendizagem federada, os clientes transferem um modelo global e melhoram-no através da preparação local nos respetivos dados. Em seguida, cada cliente envia as atualizações do modelo calculadas de volta para o servidor central, onde as atualizações do modelo são agregadas e é gerada uma nova iteração do modelo global. Nestas arquiteturas de referência, as cargas de trabalho de preparação de modelos são executadas no GKE.
A aprendizagem federada incorpora o princípio de privacidade da minimização de dados, restringindo os dados recolhidos em cada fase de cálculo, limitando o acesso aos dados e processando-os e, em seguida, eliminando-os o mais cedo possível. Além disso, a definição do problema da aprendizagem federada é compatível com técnicas de preservação da privacidade adicionais, como a utilização da privacidade diferencial (DP) para melhorar a anonimização do modelo e garantir que o modelo final não memoriza os dados de utilizadores individuais.
Consoante o exemplo de utilização, a preparação de modelos com aprendizagem federada pode ter vantagens adicionais:
- Conformidade: em alguns casos, os regulamentos podem restringir a forma como os dados podem ser usados ou partilhados. A aprendizagem federada pode ser usada para agir em conformidade com estes regulamentos.
- Eficiência da comunicação: em alguns casos, é mais eficiente formar um modelo com base em dados distribuídos do que centralizar os dados. Por exemplo, os conjuntos de dados nos quais o modelo tem de ser preparado são demasiado grandes para serem movidos centralmente.
- Tornar os dados acessíveis: a aprendizagem federada permite que as organizações mantenham os dados de preparação descentralizados em silos de dados por utilizador ou por organização.
- Maior precisão do modelo: a preparação com base em dados reais do utilizador (ao mesmo tempo que garante a privacidade) em vez de dados sintéticos (por vezes, denominados dados proxy) resulta frequentemente numa maior precisão do modelo.
Existem diferentes tipos de aprendizagem federada, que se caracterizam pela origem dos dados e pelo local onde ocorrem os cálculos locais. As arquiteturas neste documento focam-se em dois tipos de aprendizagem federada: entre silos e entre dispositivos. Outros tipos de aprendizagem federada estão fora do âmbito deste documento.
A aprendizagem federada é ainda categorizada pela forma como os conjuntos de dados são divididos, que pode ser da seguinte forma:
- Aprendizagem federada horizontal (HFL): conjuntos de dados com as mesmas caraterísticas (colunas), mas amostras diferentes (linhas). Por exemplo, vários hospitais podem ter registos de pacientes com os mesmos parâmetros médicos, mas populações de pacientes diferentes.
- Aprendizagem federada vertical (VFL): conjuntos de dados com as mesmas amostras (linhas), mas diferentes caraterísticas (colunas). Por exemplo, um banco e uma empresa de comércio eletrónico podem ter dados de clientes com indivíduos sobrepostos, mas informações financeiras e de compras diferentes.
- Aprendizagem por transferência federada (FTL): sobreposição parcial nas amostras e nas funcionalidades entre os conjuntos de dados. Por exemplo, dois hospitais podem ter registos de pacientes com alguns indivíduos sobrepostos e alguns parâmetros médicos partilhados, mas também funcionalidades únicas em cada conjunto de dados.
A computação federada entre silos é onde os membros participantes são organizações ou empresas. Na prática, o número de membros é geralmente pequeno (por exemplo, inferior a cem membros). Normalmente, a computação entre silos é usada em cenários em que as organizações participantes têm conjuntos de dados diferentes, mas querem treinar um modelo partilhado ou analisar resultados agregados sem partilhar os respetivos dados não processados entre si. Por exemplo, os membros participantes podem ter os respetivos ambientes em diferentes Google Cloud organizaçõesGoogle Cloud , como quando representam diferentes entidades legais, ou na mesmaGoogle Cloud organizaçãoGoogle Cloud , como quando representam diferentes departamentos da mesma entidade legal.
Os membros participantes podem não conseguir considerar as cargas de trabalho uns dos outros como entidades fidedignas. Por exemplo, um membro participante pode não ter acesso ao código-fonte de uma carga de trabalho de preparação que recebe de um terceiro, como o coordenador. Uma vez que não conseguem aceder a este código fonte, o membro participante não consegue garantir que a carga de trabalho é totalmente fidedigna.
Para ajudar a impedir que uma carga de trabalho não fidedigna aceda aos seus dados ou recursos sem autorização, recomendamos que faça o seguinte:
- Implemente cargas de trabalho não fidedignas num ambiente isolado.
- Conceda aos workloads não fidedignos apenas os direitos de acesso e as autorizações estritamente necessários para concluir as rondas de preparação atribuídas ao workload.
Para ajudar a isolar cargas de trabalho potencialmente não fidedignas, estas arquiteturas de referência implementam controlos de segurança, como a configuração de espaços de nomes Kubernetes isolados, em que cada espaço de nomes tem um conjunto de nós do GKE dedicado. A comunicação entre espaços de nomes e o tráfego de entrada e saída do cluster são proibidos por predefinição, a menos que substitua explicitamente esta definição.
Seguem-se exemplos de utilização da aprendizagem federada entre silos:
- Deteção de fraudes: a aprendizagem federada pode ser usada para preparar um modelo de deteção de fraudes em dados distribuídos por várias organizações. Por exemplo, um consórcio de bancos pode usar a aprendizagem federada para preparar um modelo que deteta transações fraudulentas.
- Diagnóstico médico: a aprendizagem federada pode ser usada para preparar um modelo de diagnóstico médico com base em dados distribuídos por vários hospitais. Por exemplo, um grupo de hospitais pode usar a aprendizagem federada para preparar um modelo que diagnostica o cancro.
A aprendizagem federada em vários dispositivos é um tipo de computação federada em que os membros participantes são dispositivos do utilizador final, como telemóveis, veículos ou dispositivos da IdC. O número de apoiantes pode atingir uma escala de milhões ou até dezenas de milhões.
O processo de aprendizagem federada em vários dispositivos é semelhante ao da aprendizagem federada em vários silos. No entanto, também requer que adapte a arquitetura de referência para ter em conta alguns dos fatores adicionais que tem de considerar quando lida com milhares a milhões de dispositivos. Tem de implementar cargas de trabalho administrativas para processar cenários encontrados em exemplos de utilização da aprendizagem federada em vários dispositivos. Por exemplo, a necessidade de coordenar um subconjunto de clientes que vai participar na ronda de formação. A arquitetura multidispositivos oferece esta capacidade ao permitir-lhe implementar os serviços FCP. Estes serviços têm cargas de trabalho com pontos de ligação ao TFF. O TFF é usado para escrever o código que gere esta coordenação.
Seguem-se exemplos de utilização da aprendizagem federada multidispositivos:
- Recomendações personalizadas: pode usar a aprendizagem federada entre dispositivos para preparar um modelo de recomendações personalizadas com base em dados distribuídos por vários dispositivos. Por exemplo, uma empresa pode usar a aprendizagem federada para preparar um modelo que recomenda produtos aos utilizadores com base no respetivo histórico de compras.
- Processamento de linguagem natural: a aprendizagem federada pode ser usada para preparar um modelo de processamento de linguagem natural em dados distribuídos por vários dispositivos. Por exemplo, uma empresa pode usar a aprendizagem federada para formar um modelo que melhore a precisão do reconhecimento de voz.
- Previsão das necessidades de manutenção do veículo: a aprendizagem federada pode ser usada para preparar um modelo que preveja quando um veículo provavelmente vai precisar de manutenção. Este modelo pode ser preparado com base em dados recolhidos de vários veículos. Esta abordagem permite que o modelo aprenda com as experiências de todos os veículos sem comprometer a privacidade de nenhum veículo individual.
A tabela seguinte resume as funcionalidades das arquiteturas entre silos e entre dispositivos, e mostra como categorizar o tipo de cenário de aprendizagem federada aplicável ao seu exemplo de utilização.
| Funcionalidade | Computações federadas entre silos | Computações federadas entre dispositivos |
|---|---|---|
| Tamanho da população | Normalmente, é pequeno (por exemplo, inferior a cem dispositivos) | Escalável para milhares, milhões ou centenas de milhões de dispositivos |
| Membros participantes | Organizações ou empresas | Dispositivos móveis, dispositivos periféricos e veículos |
| Criação de partições de dados mais comum | HFL, VFL e FTL | HFL |
| Confidencialidade dos dados | Dados confidenciais que os participantes não querem partilhar entre si em formato não processado | Dados demasiado confidenciais para serem partilhados com um servidor central |
| Disponibilidade dos dados | Os participantes estão quase sempre disponíveis | Apenas uma fração dos participantes está disponível em qualquer altura |
| Exemplos de utilização | Deteção de fraudes, diagnóstico médico, previsão financeira | Tracking de fitness, reconhecimento de voz e classificação de imagens |
Considerações de design
Esta secção fornece orientações para ajudar a usar esta arquitetura de referência para desenvolver uma ou mais arquiteturas que cumpram os seus requisitos específicos de segurança, fiabilidade, eficiência operacional, custo e desempenho.
Considerações de design de arquitetura entre silos
Para implementar uma arquitetura de aprendizagem federada entre silos no Google Cloud, tem de implementar os seguintes pré-requisitos mínimos, que são explicados mais detalhadamente nas secções seguintes:
- Estabeleça um consórcio de aprendizagem federada.
- Determine o modelo de colaboração para o consórcio de aprendizagem federada a implementar.
- Determine as responsabilidades das organizações participantes.
Além destes pré-requisitos, existem outras ações que o proprietário da federação tem de realizar e que estão fora do âmbito deste documento, como as seguintes:
- Faça a gestão do consórcio de aprendizagem federada.
- Crie e implemente um modelo de colaboração.
- Preparar, gerir e operar os dados de preparação do modelo e o modelo que o proprietário da federação pretende preparar.
- Crie, coloque em contentores e organize fluxos de trabalho de aprendizagem federada.
- Implemente e faça a gestão de cargas de trabalho de aprendizagem federada.
- Configure os canais de comunicação para que as organizações participantes transfiram dados em segurança.
Estabeleça um consórcio de aprendizagem federada
Um consórcio de aprendizagem federada é o grupo de organizações que participa num esforço de aprendizagem federada entre silos. As organizações no consórcio apenas partilham os parâmetros dos modelos de ML, e pode encriptar estes parâmetros para aumentar a privacidade. Se o consórcio de aprendizagem federada permitir a prática, as organizações também podem agregar dados que não contenham informações de identificação pessoal (PII).
Determine um modelo de colaboração para o consórcio de aprendizagem federada
O consórcio de aprendizagem federada pode implementar diferentes modelos de colaboração, como os seguintes:
- Um modelo centralizado que consiste numa única organização de coordenação, denominada proprietário da federação ou orquestrador, e num conjunto de organizações participantes ou proprietários de dados.
- Um modelo descentralizado que consiste em organizações que se coordenam como um grupo.
- Um modelo heterogéneo que consiste num consórcio de diversas organizações participantes, todas elas com diferentes recursos para o consórcio.
Este documento pressupõe que o modelo de colaboração é um modelo centralizado.
Determinar as responsabilidades das organizações participantes
Depois de escolher um modelo de colaboração para o consórcio de aprendizagem federada, o proprietário da federação tem de determinar as responsabilidades das organizações participantes.
O proprietário da federação também tem de fazer o seguinte quando começa a criar um consórcio de aprendizagem federada:
- Coordenar o esforço de aprendizagem federada.
- Conceber e implementar o modelo de ML global e os modelos de ML para partilhar com as organizações participantes.
- Defina as rondas de aprendizagem federada: a abordagem para a iteração do processo de treino de ML.
- Selecione as organizações participantes que contribuem para qualquer ronda de aprendizagem federada. Esta seleção denomina-se coorte.
- Conceber e implementar um procedimento de validação de membros do consórcio para as organizações participantes.
- Atualizar o modelo de AA global e os modelos de AA para partilhar com as organizações participantes.
- Fornecer às organizações participantes as ferramentas para validar se o consórcio de aprendizagem federada cumpre os respetivos requisitos de privacidade, segurança e regulamentares.
- Fornecer às organizações participantes canais de comunicação seguros e encriptados.
- Fornecer às organizações participantes todos os dados agregados não confidenciais necessários para concluir cada ronda de aprendizagem federada.
As organizações participantes têm as seguintes responsabilidades:
- Fornecer e manter um ambiente seguro e isolado (um silo). O silo é onde as organizações participantes armazenam os seus próprios dados e onde é implementada a preparação de modelos de ML. As organizações participantes não partilham os seus próprios dados com outras organizações.
- Preparar os modelos fornecidos pelo proprietário da federação através da respetiva infraestrutura de computação e dos respetivos dados locais.
- Partilhar os resultados da preparação do modelo com o proprietário da federação sob a forma de dados agregados, após a remoção de quaisquer PII.
O proprietário da federação e as organizações participantes podem usar o Cloud Storage para partilhar modelos atualizados e resultados da preparação.
O proprietário da federação e as organizações participantes refinam a preparação do modelo de ML até que o modelo cumpra os respetivos requisitos.
Implemente a aprendizagem federada no dispositivo Google Cloud
Depois de estabelecer o consórcio de aprendizagem federada e determinar como o consórcio de aprendizagem federada vai colaborar, recomendamos que as organizações participantes façam o seguinte:
- Aprovisione e configure a infraestrutura necessária para o consórcio de aprendizagem federada.
- Implemente o modelo de colaboração.
- Inicie o esforço de aprendizagem federada.
Aprovisione e configure a infraestrutura para o consórcio de aprendizagem federada
Quando aprovisiona e configura a infraestrutura para o consórcio de aprendizagem federada, é da responsabilidade do proprietário da federação criar e distribuir as cargas de trabalho que preparam os modelos de ML federados para as organizações participantes. Uma vez que um terceiro (o proprietário da federação) criou e forneceu os fluxos de trabalho, as organizações participantes têm de tomar precauções ao implementar esses fluxos de trabalho nos respetivos ambientes de tempo de execução.
As organizações participantes têm de configurar os respetivos ambientes de acordo com as práticas recomendadas de segurança individuais e aplicar controlos que limitam o âmbito e as autorizações concedidas a cada carga de trabalho. Além de seguir as respetivas práticas recomendadas de segurança individuais, recomendamos que o proprietário da federação e as organizações participantes considerem vetores de ameaças específicos da aprendizagem federada.
Implemente o modelo de colaboração
Depois de a infraestrutura do consórcio de aprendizagem federada estar preparada, o proprietário da federação cria e implementa os mecanismos que permitem que as organizações participantes interajam entre si. A abordagem segue o modelo de colaboração que o proprietário da federação escolheu para o consórcio de aprendizagem federada.
Inicie o esforço de aprendizagem federada
Após a implementação do modelo de colaboração, o proprietário da federação implementa o modelo de ML global para preparar e os modelos de ML para partilhar com a organização participante. Depois de os modelos de ML estarem prontos, o proprietário da federação inicia a primeira ronda do esforço de aprendizagem federada.
Durante cada ronda do esforço de aprendizagem federada, o proprietário da federação faz o seguinte:
- Distribui os modelos de ML para partilhar com as organizações participantes.
- Aguarda que as organizações participantes forneçam os resultados da preparação dos modelos de ML que o proprietário da federação partilhou.
- Recolhe e processa os resultados da preparação produzidos pelas organizações participantes.
- Atualiza o modelo de AA global quando recebe resultados de preparação adequados das organizações participantes.
- Atualiza os modelos de AA para partilhar com os outros membros do consórcio, quando aplicável.
- Prepara os dados de preparação para a próxima ronda de aprendizagem federada.
- Inicia a ronda seguinte de aprendizagem federada.
Segurança, privacidade e conformidade
Esta secção descreve os fatores que deve considerar quando usa esta arquitetura de referência para criar uma plataforma de aprendizagem federada noGoogle Cloud. Estas orientações aplicam-se a ambas as arquiteturas descritas neste documento.
As cargas de trabalho de aprendizagem federada que implementa nos seus ambientes podem expô-lo a si, aos seus dados, aos seus modelos de aprendizagem federada e à sua infraestrutura a ameaças que podem afetar a sua empresa.
Para ajudar a aumentar a segurança dos seus ambientes de aprendizagem federada, estas arquiteturas de referência configuram controlos de segurança do GKE que se focam na infraestrutura dos seus ambientes. Estes controlos podem não ser suficientes para se proteger contra ameaças específicas das suas cargas de trabalho e exemplos de utilização de aprendizagem federada. Dada a especificidade de cada carga de trabalho de aprendizagem federada e exemplo de utilização, os controlos de segurança destinados a proteger a implementação da aprendizagem federada estão fora do âmbito deste documento. Para mais informações e exemplos sobre estas ameaças, consulte as Considerações de segurança da aprendizagem federada.
Controlos de segurança do GKE
Esta secção aborda os controlos que aplica com estas arquiteturas para ajudar a proteger o seu cluster do GKE.
Segurança melhorada dos clusters do GKE
Estas arquiteturas de referência ajudam a criar um cluster do GKE que implementa as seguintes definições de segurança:
- Limite a exposição dos nós do cluster e do plano de controlo à Internet criando um cluster privado do GKE com redes autorizadas.
- Use nós protegidos que usam uma imagem de nó fortalecida com o tempo de execução
containerd. - Isolamento aumentado das cargas de trabalho dos inquilinos através do GKE Sandbox.
- Encriptar dados em repouso por predefinição.
- Encriptar dados em trânsito por predefinição.
- Encripte os segredos do cluster na camada de aplicação.
- Opcionalmente, encriptar os dados em utilização ativando os nós confidenciais do Google Kubernetes Engine.
Para mais informações sobre as definições de segurança do GKE, consulte os artigos Reforce a segurança do seu cluster e Acerca do painel de controlo da postura de segurança.
Regras de firewall da VPC
As regras de firewall da nuvem virtual privada (VPC) determinam que tráfego é permitido de ou para VMs do Compute Engine. As regras permitem-lhe filtrar o tráfego ao nível da granularidade da VM, consoante os atributos da camada 4.
Cria um cluster do GKE com as regras de firewall do cluster do GKE predefinidas. Estas regras de firewall permitem a comunicação entre os nós do cluster e o plano de controlo do GKE, bem como entre os nós e os pods no cluster.
Aplica regras de firewall adicionais aos nós no conjunto de nós do inquilino. Estas regras de firewall restringem o tráfego de saída dos nós do inquilino. Esta abordagem pode aumentar o isolamento dos nós de inquilino. Por predefinição, todo o tráfego de saída dos nós de inquilino é recusado. Qualquer saída necessária tem de ser configurada explicitamente. Por exemplo, cria regras de firewall para permitir a saída dos nós do inquilino para o plano de controlo do GKE e para as APIs Google através do acesso privado à Google. As regras de firewall são direcionadas para os nós do inquilino através da conta de serviço para o conjunto de nós do inquilino.
Espaços de nomes
Os espaços de nomes permitem-lhe fornecer um âmbito para recursos relacionados num cluster, por exemplo, pods, serviços e controladores de replicação. Ao usar espaços de nomes, pode delegar a responsabilidade de administração dos recursos relacionados como uma unidade. Por conseguinte, os espaços de nomes são parte integrante da maioria dos padrões de segurança.
Os espaços de nomes são uma funcionalidade importante para o isolamento do plano de controlo. No entanto, não oferecem isolamento de nós, isolamento do plano de dados nem isolamento da rede.
Uma abordagem comum é criar espaços de nomes para aplicações individuais. Por exemplo, pode criar o espaço de nomes myapp-frontend para o componente de IU de uma aplicação.
Estas arquiteturas de referência ajudam a criar um espaço de nomes dedicado para alojar as apps de terceiros. O espaço de nomes e os respetivos recursos são tratados como um inquilino no seu cluster. Aplica políticas e controlos ao espaço de nomes para limitar o âmbito dos recursos no espaço de nomes.
Políticas de Rede
As políticas de rede aplicam fluxos de tráfego de rede da camada 4 através de regras de firewall ao nível do pod. As políticas de rede têm âmbito de um espaço de nomes.
Nas arquiteturas de referência descritas neste documento, aplica políticas de rede ao espaço de nomes do inquilino que aloja as apps de terceiros. Por predefinição, a política de rede recusa todo o tráfego de e para pods no espaço de nomes. Todo o tráfego necessário tem de ser adicionado explicitamente a uma lista de autorizações. Por exemplo, as políticas de rede nestas arquiteturas de referência permitem explicitamente o tráfego para os serviços de cluster necessários, como o DNS interno do cluster e o plano de controlo da Cloud Service Mesh.
Config Sync
O Config Sync mantém os seus clusters do GKE sincronizados com as configurações armazenadas num repositório do Git. O repositório Git funciona como a única fonte de informações fidedignas para a configuração e as políticas do cluster. O Config Sync é declarativo. Verifica continuamente o estado do cluster e aplica o estado declarado no ficheiro de configuração para aplicar políticas, o que ajuda a evitar a deriva de configuração.
Instala o Config Sync no seu cluster do GKE. Configura o Config Sync para sincronizar as configurações e as políticas do cluster a partir de um repositório de origem na nuvem. Os recursos sincronizados incluem o seguinte:
- Configuração do Cloud Service Mesh ao nível do cluster
- Políticas de segurança ao nível do cluster
- Configuração e política ao nível do espaço de nomes do inquilino, incluindo políticas de rede, contas de serviço, regras de RBAC e configuração da malha de serviços na nuvem
Controlador de políticas
O Policy Controller é um controlador de admissão dinâmico para o Kubernetes que aplica políticas baseadas em CustomResourceDefinition (baseadas em CRD) que são executadas pelo Open Policy Agent (OPA).
Os controladores de admissão são plug-ins do Kubernetes que intercetam pedidos para o servidor da API Kubernetes antes de um objeto ser persistido, mas depois de o pedido ser autenticado e autorizado. Pode usar controladores de admissão para limitar a forma como um cluster é usado.
Instala o Policy Controller no seu cluster do GKE. Estas arquiteturas de referência incluem políticas de exemplo para ajudar a proteger o seu cluster. Aplica automaticamente as políticas ao cluster através do Config Sync. Aplicar as seguintes políticas:
- Políticas selecionadas para ajudar a aplicar a segurança dos pods. Por exemplo, aplica políticas que impedem que os pods executem contentores privilegiados e que requerem um sistema de ficheiros raiz só de leitura.
- Políticas da biblioteca de modelos do Policy Controller. Por exemplo, aplica uma política que não permite serviços com o tipo NodePort.
Cloud Service Mesh
O Cloud Service Mesh é uma malha de serviços que ajuda a simplificar a gestão de comunicações seguras entre serviços. Estas arquiteturas de referência configuram a malha de serviços na nuvem para que faça o seguinte:
- Injeta automaticamente proxies sidecar.
- Aplica a comunicação mTLS entre os serviços na malha.
- Limita o tráfego de malha de saída apenas a anfitriões conhecidos.
- Limita o tráfego de entrada apenas de determinados clientes.
- Permite-lhe configurar políticas de segurança de rede com base na identidade do serviço, em vez de com base no endereço IP de pares na rede.
- Limita a comunicação autorizada entre serviços na malha. Por exemplo, as apps no espaço de nomes do inquilino só podem comunicar com apps no mesmo espaço de nomes ou com um conjunto de anfitriões externos conhecidos.
- Encaminha todo o tráfego de entrada e saída através de gateways de malha onde pode aplicar controlos de tráfego adicionais.
- Suporta a comunicação segura entre clusters.
Taints e afinidades de nós
As restrições de nós e a afinidade de nós são mecanismos do Kubernetes que lhe permitem influenciar a forma como os pods são agendados nos nós do cluster.
Os nós contaminados repelem os agrupamentos. O Kubernetes não agenda um pod num nó contaminado, a menos que o pod tenha uma tolerância para a contaminação. Pode usar taints de nós para reservar nós para utilização apenas por determinadas cargas de trabalho ou inquilinos. As restrições e as tolerâncias são usadas frequentemente em clusters multi-inquilinos. Para mais informações, consulte a documentação sobre os nós dedicados com taints e tolerâncias.
A afinidade de nós permite-lhe restringir os pods a nós com etiquetas específicas. Se um pod tiver um requisito de afinidade de nós, o Kubernetes não agenda o pod num nó, a menos que o nó tenha uma etiqueta que corresponda ao requisito de afinidade. Pode usar a afinidade de nós para garantir que os pods são agendados em nós adequados.
Pode usar taints de nós e afinidade de nós em conjunto para garantir que os pods de carga de trabalho do inquilino são agendados exclusivamente em nós reservados para o inquilino.
Estas arquiteturas de referência ajudam a controlar o agendamento das apps de inquilino das seguintes formas:
- Criar um node pool do GKE dedicado ao inquilino. Cada nó no conjunto tem uma mancha relacionada com o nome do inquilino.
- Aplicar automaticamente a tolerância e a afinidade de nós adequadas a qualquer pod que segmente o espaço de nomes do inquilino. Aplica a tolerância e a afinidade através de mutações do PolicyController.
Menor privilégio
É uma prática recomendada de segurança adotar um princípio de privilégio mínimo para os seus Google Cloud projetos e recursos, como clusters do GKE. Ao usar esta abordagem, as apps que são executadas no cluster, e os programadores e os operadores que usam o cluster, têm apenas o conjunto mínimo de autorizações necessárias.
Estas arquiteturas de referência ajudam a usar contas de serviço com o menor número possível de privilégios das seguintes formas:
- Cada pool de nós do GKE recebe a sua própria conta de serviço. Por exemplo, os nós no conjunto de nós do inquilino usam uma conta de serviço dedicada a esses nós. As contas de serviço do nó estão configuradas com as autorizações mínimas necessárias.
- O cluster usa a Workload Identity Federation para o GKE para associar contas de serviço do Kubernetes a contas de serviço Google. Desta forma, as apps de inquilino podem receber acesso limitado a quaisquer APIs Google necessárias sem transferir nem armazenar uma chave de conta de serviço. Por exemplo, pode conceder autorizações à conta de serviço para ler dados de um contentor do Cloud Storage.
Estas arquiteturas de referência ajudam a restringir o acesso aos recursos do cluster das seguintes formas:
- Cria uma função RBAC do Kubernetes de exemplo com autorizações limitadas para gerir apps. Pode conceder esta função aos utilizadores e grupos que operam as apps no espaço de nomes do inquilino. Ao aplicar esta função limitada de utilizadores e grupos, esses utilizadores só têm autorizações para modificar recursos de apps no espaço de nomes do inquilino. Não têm autorizações para modificar recursos ao nível do cluster ou definições de segurança confidenciais, como políticas da Cloud Service Mesh.
Autorização binária
A autorização binária permite-lhe aplicar políticas que define sobre as imagens de contentores que estão a ser implementadas no seu ambiente do GKE. A autorização binária permite a implementação apenas de imagens de contentores em conformidade com as políticas definidas. Impede a implementação de quaisquer outras imagens de contentores.
Nesta arquitetura de referência, a autorização binária está ativada com a respetiva configuração predefinida. Para inspecionar a configuração predefinida da autorização binária, consulte o artigo Exporte o ficheiro YAML da política.
Para mais informações sobre como configurar políticas, consulte as seguintes orientações específicas:
- CLI do Google Cloud
- Google Cloud consola
- A API REST
- O
google_binary_authorization_policyrecurso do Terraform
Validação da atestação entre organizações
Pode usar a autorização binária para validar atestações geradas por um signatário de terceiros. Por exemplo, num exemplo de utilização de aprendizagem federada entre silos, pode validar atestações criadas por outra organização participante.
Para validar as atestações criadas por terceiros, faça o seguinte:
- Receber as chaves públicas que o terceiro usou para criar as atestações que tem de validar.
- Crie os atestadores para validar as atestações.
- Adicione as chaves públicas que recebeu do terceiro à lista de atestadores que criou.
Para mais informações sobre como criar atestadores, consulte as seguintes orientações específicas:
- CLI do Google Cloud
- Google Cloud consola
- a API REST
- o recurso do Terraform
google_binary_authorization_attestor
Considerações de segurança da aprendizagem federada
Apesar do seu modelo de partilha de dados rigoroso, a aprendizagem federada não é inerentemente segura contra todos os ataques direcionados, e deve ter estes riscos em conta quando implementar qualquer uma das arquiteturas descritas neste documento. Também existe o risco de fugas de informações não intencionais sobre modelos de ML ou dados de preparação de modelos. Por exemplo, um atacante pode comprometer intencionalmente o modelo de AA global ou as rondas do esforço de aprendizagem federada, ou pode executar um ataque de tempo (um tipo de ataque de canal lateral) para recolher informações sobre a dimensão dos conjuntos de dados de preparação.
As ameaças mais comuns contra uma implementação da aprendizagem federada são as seguintes:
- Memorização intencional ou não intencional de dados de preparação. A sua implementação da aprendizagem federada ou um atacante podem armazenar dados intencionalmente ou não intencionalmente de formas que podem ser difíceis de usar. Um atacante pode conseguir recolher informações sobre o modelo de AM global ou as rondas anteriores do esforço de aprendizagem federada através da engenharia reversa dos dados armazenados.
- Extrair informações de atualizações para o modelo de ML global. Durante o esforço de aprendizagem federada, um atacante pode fazer a engenharia reversa das atualizações ao modelo de ML global que o proprietário da federação recolhe das organizações e dos dispositivos participantes.
- O proprietário da federação pode comprometer as rondas. Um proprietário da federação comprometido pode controlar um silo ou um dispositivo não autorizado e iniciar uma ronda do esforço de aprendizagem federada. No final da ronda, o proprietário da federação comprometido pode conseguir recolher informações sobre as atualizações que recolhe de organizações e dispositivos participantes legítimos comparando essas atualizações com a que o silo fraudulento produziu.
- As organizações e os dispositivos participantes podem comprometer o modelo de aprendizagem automática global. Durante o esforço de aprendizagem federada, um atacante pode tentar afetar maliciosamente o desempenho, a qualidade ou a integridade do modelo de AA global produzindo atualizações não autorizadas ou inconsequentes.
Para ajudar a mitigar o impacto das ameaças descritas nesta secção, recomendamos as seguintes práticas recomendadas:
- Ajuste o modelo para reduzir ao mínimo a memorização dos dados de preparação.
- Implemente mecanismos de preservação da privacidade.
- Audite regularmente o modelo de ML global, os modelos de ML que pretende partilhar, os dados de preparação e a infraestrutura que implementou para alcançar os seus objetivos de aprendizagem federada.
- Implementar um algoritmo de agregação segura para processar os resultados da preparação que as organizações participantes produzem.
- Gerar e distribuir chaves de encriptação de dados de forma segura através de uma infraestrutura de chave pública.
- Implementar infraestrutura numa plataforma de computação confidencial.
Os proprietários da federação também têm de seguir estes passos adicionais:
- Validar a identidade de cada organização participante e a integridade de cada silo no caso de arquiteturas de vários silos, bem como a identidade e a integridade de cada dispositivo no caso de arquiteturas de vários dispositivos.
- Limitar o âmbito das atualizações ao modelo de AA global que as organizações e os dispositivos participantes podem produzir.
Fiabilidade
Esta secção descreve os fatores de design que deve considerar quando usa qualquer uma das arquiteturas de referência neste documento para criar e desenvolver uma plataforma de aprendizagem federada no Google Cloud.
Ao conceber a sua arquitetura de aprendizagem federada no Google Cloud, recomendamos que siga as orientações nesta secção para melhorar a disponibilidade e a escalabilidade da carga de trabalho, e ajudar a tornar a sua arquitetura resiliente a interrupções e desastres.
GKE: o GKE suporta vários tipos de clusters diferentes que pode personalizar de acordo com os requisitos de disponibilidade das suas cargas de trabalho e o seu orçamento. Por exemplo, pode criar clusters regionais que distribuem o plano de controlo e os nós por várias zonas numa região ou clusters zonais que têm o plano de controlo e os nós numa única zona. As arquiteturas de referência entre silos e entre dispositivos baseiam-se em clusters do GKE regionais. Para mais informações sobre os aspetos a ter em consideração ao criar clusters do GKE, consulte as opções de configuração de clusters.
Consoante o tipo de cluster e a forma como o plano de controlo e os nós do cluster são distribuídos por regiões e zonas, o GKE oferece diferentes capacidades de recuperação de desastres para proteger as suas cargas de trabalho contra interrupções zonais e regionais. Para mais informações sobre as capacidades de recuperação de desastres do GKE, consulte o artigo Arquitetar a recuperação de desastres para interrupções da infraestrutura na nuvem: Google Kubernetes Engine.
Google Cloud Load Balancing: o GKE suporta várias formas de balancear a carga do tráfego para as suas cargas de trabalho. As implementações do GKE das APIs Kubernetes Gateway e Kubernetes Service permitem aprovisionar e configurar automaticamente o Cloud Load Balancing para expor de forma segura e fiável as cargas de trabalho em execução nos seus clusters do GKE.
Nestas arquiteturas de referência, todo o tráfego de entrada e saída passa pelos gateways do Cloud Service Mesh. Estas gateways significam que pode controlar rigorosamente a forma como o tráfego flui dentro e fora dos seus clusters do GKE.
Desafios de fiabilidade para a aprendizagem federada multidispositivos
A aprendizagem federada entre dispositivos tem vários desafios de fiabilidade que não são encontrados em cenários entre silos. Estas incluem o seguinte:
- Conetividade do dispositivo não fiável ou intermitente
- Armazenamento limitado no dispositivo
- Capacidade de computação e memória limitadas
A conetividade não fiável pode originar problemas como os seguintes:
- Atualizações desatualizadas e divergência de modelos: quando os dispositivos têm uma conetividade intermitente, as respetivas atualizações de modelos locais podem ficar desatualizadas, representando informações desatualizadas em comparação com o estado atual do modelo global. A agregação de atualizações desatualizadas pode levar a uma divergência do modelo, em que o modelo global se desvia da solução ideal devido a inconsistências no processo de preparação.
- Contribuições desequilibradas e modelos tendenciosos: a comunicação intermitente pode resultar numa distribuição desigual das contribuições dos dispositivos participantes. Os dispositivos com conetividade fraca podem contribuir com menos atualizações, o que leva a uma representação desequilibrada da distribuição dos dados subjacentes. Este desequilíbrio pode enviesar o modelo global para os dados de dispositivos com ligações mais fiáveis.
- Aumento da sobrecarga de comunicação e do consumo de energia: a comunicação intermitente pode levar a um aumento da sobrecarga de comunicação, uma vez que os dispositivos podem ter de reenviar atualizações perdidas ou danificadas. Este problema também pode aumentar o consumo de energia nos dispositivos, especialmente para aqueles com autonomia da bateria limitada, uma vez que podem ter de manter ligações ativas durante períodos mais longos para garantir a transmissão bem-sucedida das atualizações.
Para ajudar a mitigar alguns dos efeitos causados pela comunicação intermitente, as arquiteturas de referência neste documento podem ser usadas com o FCP.
Uma arquitetura do sistema que execute o protocolo FCP pode ser concebida para cumprir os seguintes requisitos:
- Processar rondas de longa duração.
- Ativar a execução especulativa (as rondas podem começar antes de o número necessário de clientes estar reunido, antecipando a chegada de mais clientes em breve).
- Permitir que os dispositivos escolham as tarefas nas quais querem participar. Esta abordagem pode ativar funcionalidades como a amostragem sem reposição, que é uma estratégia de amostragem em que cada unidade de amostra de uma população tem apenas uma oportunidade de ser selecionada. Esta abordagem ajuda a mitigar as contribuições desequilibradas e os modelos tendenciosos
- Extensível para técnicas de anonimização, como a privacidade diferencial (DP) e a agregação fidedigna (TAG).
Para ajudar a mitigar o armazenamento e as capacidades de computação limitados do dispositivo, as seguintes técnicas podem ajudar:
- Compreenda qual é a capacidade máxima disponível para executar a computação de aprendizagem federada
- Compreenda a quantidade de dados que podem ser armazenados em qualquer altura
- Crie o código de aprendizagem federada do lado do cliente para funcionar dentro do poder de computação e da RAM disponíveis nos clientes
- Compreenda as implicações de ficar sem armazenamento e implemente um processo para gerir esta situação
Otimização de custos
Esta secção fornece orientações para otimizar o custo de criação e execução da plataforma de aprendizagem federada no Google Cloud que estabelece através desta arquitetura de referência. Estas orientações aplicam-se a ambas as arquiteturas descritas neste documento.
A execução de cargas de trabalho no GKE pode ajudar a otimizar os custos do seu ambiente através do aprovisionamento e da configuração dos clusters de acordo com os requisitos de recursos das suas cargas de trabalho. Também ativa funcionalidades que reconfiguram dinamicamente os clusters e os nós de cluster, como a escalabilidade automática dos nós de cluster e dos pods, e o dimensionamento adequado dos clusters.
Para mais informações sobre a otimização do custo dos seus ambientes do GKE, consulte o artigo Práticas recomendadas para executar aplicações Kubernetes otimizadas em termos de custos no GKE.
Eficiência operacional
Esta secção descreve os fatores que deve considerar para otimizar a eficiência quando usa esta arquitetura de referência para criar e executar uma plataforma de aprendizagem federada no Google Cloud. Estas orientações aplicam-se a ambas as arquiteturas descritas neste documento.
Para aumentar a automatização e a monitorização da sua arquitetura de aprendizagem federada, recomendamos que adote os princípios de MLOps, que são princípios de DevOps no contexto dos sistemas de aprendizagem automática. A prática de MLOps significa que defende a automatização e a monitorização em todos os passos da construção do sistema de ML, incluindo a integração, os testes, o lançamento, a implementação e a gestão da infraestrutura. Para mais informações sobre MLOps, consulte o artigo MLOps: fornecimento contínuo e pipelines de automatização na aprendizagem automática.
Otimização do desempenho
Esta secção descreve os fatores que deve considerar para otimizar o desempenho das suas cargas de trabalho quando usa esta arquitetura de referência para criar e executar uma plataforma de aprendizagem federada no Google Cloud. Estas orientações aplicam-se a ambas as arquiteturas descritas neste documento.
O GKE suporta várias funcionalidades para ajustar e dimensionar automaticamente e manualmente o seu ambiente do GKE de forma adequada para satisfazer as exigências das suas cargas de trabalho e ajudar a evitar o aprovisionamento excessivo de recursos. Por exemplo, pode usar o Recommender para gerar estatísticas e recomendações para otimizar a utilização dos recursos do GKE.
Ao pensar em como dimensionar o seu ambiente do GKE, recomendamos que crie planos de curto, médio e longo prazo sobre como pretende dimensionar os seus ambientes e cargas de trabalho. Por exemplo, como pretende aumentar a sua presença no GKE dentro de algumas semanas, meses e anos? Ter um plano pronto ajuda a tirar o máximo partido das funcionalidades de escalabilidade que o GKE oferece, otimizar os seus ambientes do GKE e reduzir os custos. Para mais informações sobre o planeamento da escalabilidade de clusters e cargas de trabalho, consulte Acerca da escalabilidade do GKE.
Para aumentar o desempenho das suas cargas de trabalho de ML, pode adotar as unidades de processamento tensor da nuvem (TPUs da nuvem), aceleradores de IA concebidos pela Google que estão otimizados para a preparação e a inferência de grandes modelos de IA.
Implementação
Para implementar as arquiteturas de referência entre silos e entre dispositivos que este documento descreve, consulte o repositório do Federated Learning no Google Cloud GitHub.
O que se segue?
- Explore como pode implementar os seus algoritmos de aprendizagem federada na plataforma TensorFlow Federated.
- Saiba mais sobre os avanços e os problemas em aberto na aprendizagem federada.
- Leia sobre a aprendizagem federada no blogue de IA da Google.
- Veja como a Google mantém a privacidade intacta quando usa a aprendizagem federada com informações agregadas e anonimizadas para melhorar os modelos de AA.
- Leia o artigo Towards Federated learning at scale.
- Explore como pode implementar um pipeline de MLOps para gerir o ciclo de vida dos modelos de aprendizagem automática.
- Para uma vista geral dos princípios e recomendações de arquitetura específicos das cargas de trabalho de IA e ML no Google Cloud, consulte aperspetiva de IA e ML no Well-Architected Framework.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
Colaboradores
Autores:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Arquiteto de soluções na nuvem
Outros colaboradores:
- Chloé Kiddon | Staff Software Engineer and Manager
- Laurent Grangeau | Solutions Architect
- Lilian Felix | Engenheira da nuvem
- Christiane Peters | Arquiteta de segurança da nuvem