Este documento aborda técnicas para implementar e automatizar a integração contínua (CI), a entrega contínua (CD) e a preparação contínua (CT) para sistemas de aprendizagem automática (ML). Este documento aplica-se principalmente a sistemas de IA preditiva.
A ciência de dados e a aprendizagem automática estão a tornar-se capacidades essenciais para resolver problemas complexos do mundo real, transformar setores e oferecer valor em todos os domínios. Atualmente, os ingredientes para aplicar a aprendizagem automática eficaz estão disponíveis para si:
- Conjuntos de dados grandes
- Recursos de computação a pedido económicos
- Aceleradores especializados para ML em várias plataformas de nuvem
- Avanços rápidos em diferentes campos de investigação de ML (como visão computacional, compreensão de linguagem natural, IA generativa e sistemas de IA de recomendações).
Por conseguinte, muitas empresas estão a investir nas suas equipas de ciência de dados e capacidades de ML para desenvolver modelos preditivos que possam oferecer valor empresarial aos seus utilizadores.
Este documento destina-se a cientistas de dados e engenheiros de ML que queiram aplicar os princípios de DevOps a sistemas de ML (MLOps). O MLOps é uma cultura e uma prática de engenharia de ML que visa unificar o desenvolvimento do sistema de ML (Dev) e a operação do sistema de ML (Ops). A prática de MLOps significa que defende a automatização e a monitorização em todos os passos da construção do sistema de AA, incluindo a integração, os testes, o lançamento, a implementação e a gestão da infraestrutura.
Os cientistas de dados podem implementar e preparar um modelo de ML com desempenho preditivo num conjunto de dados de retenção offline, dados os dados de preparação relevantes para o respetivo exemplo de utilização. No entanto, o verdadeiro desafio não é criar um modelo de AA, mas sim criar um sistema de AA integrado e operá-lo continuamente em produção. Com a longa história dos serviços de aprendizagem automática de produção na Google, aprendemos que podem existir muitas armadilhas na operação de sistemas baseados em aprendizagem automática na produção. Algumas destas armadilhas são resumidas no artigo Machine Learning: The High Interest Credit Card of Technical Debt.
Conforme mostrado no diagrama seguinte, apenas uma pequena parte de um sistema de ML do mundo real é composta pelo código de ML. Os elementos circundantes necessários são vastos e complexos.
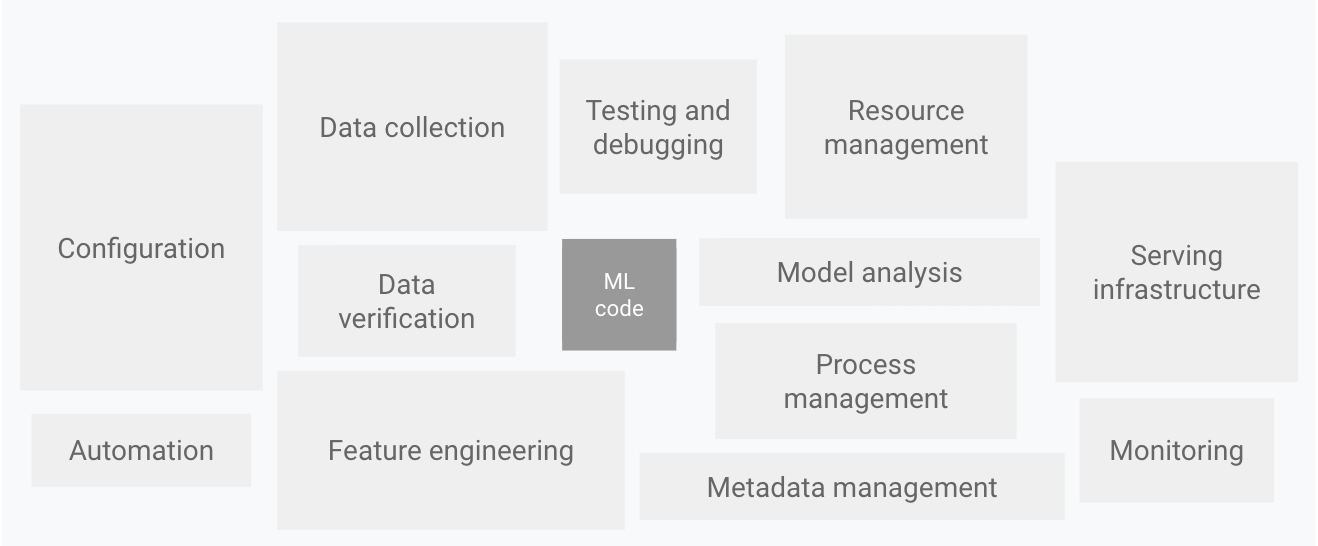
Figura 1. Elementos para sistemas de aprendizagem automática. Adaptado de Hidden Technical Debt in Machine Learning Systems.
O diagrama anterior apresenta os seguintes componentes do sistema:
- Configuração
- Automatização
- Recolha de dados
- Validação de dados
- Testes e depuração
- Gestão de recursos
- Análise de modelos
- Processamento e gestão de metadados
- Infraestrutura de publicação
- Monitorização
Para desenvolver e operar sistemas complexos como estes, pode aplicar os princípios de DevOps aos sistemas de ML (MLOps). Este documento aborda os conceitos a ter em conta ao configurar um ambiente de MLOps para as suas práticas de ciência de dados, como CI, CD e CT em ML.
Os seguintes tópicos são abordados:
- DevOps versus MLOps
- Passos para desenvolver modelos de ML
- Níveis de maturidade de MLOps
- MLOps para IA generativa
DevOps versus MLOps
DevOps é uma prática popular no desenvolvimento e funcionamento de sistemas de software de grande escala. Esta prática oferece vantagens como o encurtamento dos ciclos de desenvolvimento, o aumento da velocidade de implementação e lançamentos fiáveis. Para alcançar estas vantagens, introduz dois conceitos no desenvolvimento do sistema de software:
Um sistema de aprendizagem automática é um sistema de software, pelo que se aplicam práticas semelhantes para ajudar a garantir que pode criar e operar sistemas de aprendizagem automática de forma fiável em grande escala.
No entanto, os sistemas de ML diferem de outros sistemas de software nos seguintes aspetos:
Competências da equipa: num projeto de ML, a equipa inclui normalmente cientistas de dados ou investigadores de ML, que se focam na análise exploratória de dados, no desenvolvimento de modelos e na experimentação. Estes membros podem não ser engenheiros de software experientes que possam criar serviços de classe de produção.
Desenvolvimento: a ML é de natureza experimental. Deve experimentar diferentes funcionalidades, algoritmos, técnicas de modelagem e configurações de parâmetros para encontrar o que funciona melhor para o problema o mais rapidamente possível. O desafio é acompanhar o que funcionou e o que não funcionou, e manter a reprodutibilidade enquanto maximiza a reutilização do código.
Testes: testar um sistema de ML é mais complexo do que testar outros sistemas de software. Além dos testes de integração e de unidades típicos, precisa de validação de dados, avaliação da qualidade do modelo preparado e validação do modelo.
Implementação: nos sistemas de ML, a implementação não é tão simples como implementar um modelo de ML preparado offline como um serviço de previsão. Os sistemas de ML podem exigir que implemente um pipeline de vários passos para voltar a preparar e implementar automaticamente modelos. Esta conduta adiciona complexidade e requer que automatize os passos que os cientistas de dados fazem manualmente antes da implementação para formar e validar novos modelos.
Produção: os modelos de ML podem ter um desempenho reduzido não só devido a uma programação abaixo do ideal, mas também devido a perfis de dados em constante evolução. Por outras palavras, os modelos podem deteriorar-se de mais formas do que os sistemas de software convencionais, e tem de considerar esta degradação. Por conseguinte, tem de acompanhar as estatísticas de resumo dos seus dados e monitorizar o desempenho online do seu modelo para enviar notificações ou reverter quando os valores se desviarem das suas expetativas.
A aprendizagem automática e outros sistemas de software são semelhantes na integração contínua do controlo de origem, nos testes unitários, nos testes de integração e na entrega contínua do módulo de software ou do pacote. No entanto, na aprendizagem automática, existem algumas diferenças notáveis:
- A CI já não se limita a testar e validar código e componentes, mas também a testar e validar dados, esquemas de dados e modelos.
- A CD já não se refere a um único pacote de software ou a um serviço, mas sim a um sistema (um pipeline de preparação de ML) que deve implementar automaticamente outro serviço (serviço de previsão de modelos).
- O CT é uma nova propriedade, exclusiva dos sistemas de ML, que se preocupa com o reajuste automático e a publicação dos modelos.
A secção seguinte aborda os passos típicos para preparar e avaliar um modelo de ML para publicação como um serviço de previsão.
Passos da ciência dos dados para a aprendizagem automática
Em qualquer projeto de ML, depois de definir o exemplo de utilização empresarial e estabelecer os critérios de êxito, o processo de disponibilização de um modelo de ML para produção envolve os seguintes passos. Estes passos podem ser concluídos manualmente ou através de um pipeline automático.
- Extração de dados: seleciona e integra os dados relevantes de várias origens de dados para a tarefa de ML.
- Análise de dados: realiza uma análise exploratória de dados (EDA) para compreender os dados disponíveis para criar o modelo de ML. Este
processo leva ao seguinte:
- Compreender o esquema de dados e as caraterísticas esperadas pelo modelo.
- Identificar a preparação de dados e a engenharia de funcionalidades necessárias para o modelo.
- Preparação de dados: os dados são preparados para a tarefa de ML. Esta preparação envolve a limpeza de dados, em que divide os dados em conjuntos de preparação, validação e teste. Também aplica transformações de dados e engenharia de funcionalidades ao modelo que resolve a tarefa alvo. O resultado deste passo são as divisões de dados no formato preparado.
- Preparação do modelo: o cientista de dados implementa diferentes algoritmos com os dados preparados para preparar vários modelos de ML. Além disso, submete os algoritmos implementados ao ajuste de hiperparâmetros para obter o modelo de AA com melhor desempenho. O resultado deste passo é um modelo preparado.
- Avaliação do modelo: o modelo é avaliado num conjunto de testes de retenção para avaliar a qualidade do modelo. O resultado deste passo é um conjunto de métricas para avaliar a qualidade do modelo.
- Validação do modelo: o modelo é confirmado como adequado para implementação, ou seja, o respetivo desempenho preditivo é melhor do que uma determinada base.
- Publicação do modelo: o modelo validado é implementado num ambiente de destino para publicar previsões. Esta implementação pode ser uma das
seguintes:
- Microsserviços com uma API REST para publicar previsões online.
- Um modelo incorporado num dispositivo móvel ou de extremidade.
- Parte de um sistema de previsão em lote.
- Monitorização do modelo: o desempenho preditivo do modelo é monitorizado para invocar potencialmente uma nova iteração no processo de ML.
O nível de automatização destes passos define a maturidade do processo de AA, o que reflete a velocidade de preparação de novos modelos com base em novos dados ou a preparação de novos modelos com base em novas implementações. As secções seguintes descrevem três níveis de MLOps, começando pelo nível mais comum, que não envolve automatização, até à automatização das pipelines de ML e CI/CD.
Nível 0 de MLOps: processo manual
Muitas equipas têm cientistas de dados e investigadores de ML que podem criar modelos avançados, mas o respetivo processo de criação e implementação de modelos de ML é totalmente manual. Este é considerado o nível de maturidade básico ou nível 0. O diagrama seguinte mostra o fluxo de trabalho deste processo.

Figura 2. Passos de ML manuais para publicar o modelo como um serviço de previsão.
Caraterísticas
A lista seguinte realça as caraterísticas do processo de MLOps de nível 0, conforme mostrado na Figura 2:
Manual, orientado por scripts e processo interativo: cada passo é manual, incluindo a análise de dados, a preparação de dados, a formação e a validação de modelos. Requer a execução manual de cada passo e a transição manual de um passo para outro. Normalmente, este processo é conduzido por código experimental escrito e executado interativamente em blocos de notas por cientistas de dados, até ser produzido um modelo funcional.
Desconexão entre a aprendizagem automática e as operações: o processo separa os cientistas de dados que criam o modelo e os engenheiros que fornecem o modelo como um serviço de previsão. Os cientistas de dados entregam um modelo preparado como um artefacto à equipa de engenharia para implementação na respetiva infraestrutura de API. Esta transferência pode incluir a colocação do modelo preparado numa localização de armazenamento, a validação do objeto do modelo num repositório de código ou o carregamento para um registo de modelos. Em seguida, os engenheiros que implementam o modelo têm de disponibilizar as funcionalidades necessárias na produção para a publicação com baixa latência, o que pode levar a uma divergência entre a preparação e a publicação.
Iterações de lançamento pouco frequentes: o processo pressupõe que a sua equipa de ciência de dados gere alguns modelos que não mudam com frequência, quer alterando a implementação do modelo, quer reciclado o modelo com novos dados. Uma nova versão do modelo é implementada apenas algumas vezes por ano.
Sem CI: uma vez que se pressupõem poucas alterações de implementação, o CI é ignorado. Normalmente, o teste do código faz parte da execução dos blocos de notas ou do script. Os scripts e os blocos de notas que implementam os passos da experiência são controlados pela origem e produzem artefactos, como modelos preparados, métricas de avaliação e visualizações.
Sem CD: uma vez que não existem implementações frequentes de versões de modelos, a CD não é considerada.
A implementação refere-se ao serviço de previsão: o processo diz respeito apenas à implementação do modelo preparado como um serviço de previsão (por exemplo, um microsserviço com uma API REST), em vez de implementar todo o sistema de ML.
Falta de monitorização ativa do desempenho: o processo não monitoriza nem regista as previsões e as ações do modelo, que são necessárias para detetar a degradação do desempenho do modelo e outras variações comportamentais do modelo.
A equipa de engenharia pode ter a sua própria configuração complexa para a configuração da API, testes e implementação, incluindo testes de segurança, regressão, carga e canários. Além disso, a implementação em produção de uma nova versão de um modelo de ML passa normalmente por testes A/B ou experiências online antes de o modelo ser promovido para atender a todo o tráfego de pedidos de previsão.
Desafios
O nível 0 de MLOps é comum em muitas empresas que estão a começar a aplicar a aprendizagem automática aos respetivos exemplos de utilização. Este processo manual, orientado por cientistas de dados, pode ser suficiente quando os modelos são raramente alterados ou preparados. Na prática, os modelos falham frequentemente quando são implementados no mundo real. Os modelos não se adaptam às alterações na dinâmica do ambiente nem às alterações nos dados que descrevem o ambiente. Para mais informações, consulte o artigo Por que motivo os modelos de aprendizagem automática falham em produção.
Para resolver estes desafios e manter a precisão do modelo em produção, tem de fazer o seguinte:
Monitorize ativamente a qualidade do seu modelo em produção: a monitorização permite-lhe detetar a degradação do desempenho e a obsolescência do modelo. Atua como um sinal para uma nova iteração de testes e uma reciclagem (manual) do modelo com novos dados.
Volte a preparar frequentemente os modelos de produção: para captar os padrões em evolução e emergentes, tem de voltar a preparar o modelo com os dados mais recentes. Por exemplo, se a sua app recomendar produtos de moda através da AA, as recomendações devem adaptar-se às tendências e aos produtos mais recentes.
Experimente continuamente novas implementações para produzir o modelo: Para tirar partido das ideias e dos avanços tecnológicos mais recentes, tem de experimentar novas implementações, como a engenharia de funcionalidades, a arquitetura do modelo e os hiperparâmetros. Por exemplo, se usar a visão computacional na deteção facial, os padrões faciais são fixos, mas as novas técnicas melhoradas podem melhorar a precisão da deteção.
Para resolver os desafios deste processo manual, as práticas de MLOps para CI/CD e CT são úteis. Ao implementar um pipeline de preparação de ML, pode ativar o CT e configurar um sistema de CI/CD para testar, criar e implementar rapidamente novas implementações do pipeline de ML. Estas funcionalidades são abordadas mais detalhadamente nas secções seguintes.
MLOps nível 1: automatização do pipeline de ML
O objetivo do nível 1 é realizar uma preparação contínua do modelo através da automatização do pipeline de ML. Isto permite-lhe alcançar uma entrega contínua do serviço de previsão do modelo. Para automatizar o processo de utilização de novos dados para voltar a preparar modelos em produção, tem de introduzir passos de validação de dados e modelos automatizados no pipeline, bem como acionadores de pipeline e gestão de metadados.
A figura seguinte é uma representação esquemática de um pipeline de ML automatizado para TC.

Figura 3. Automatização do pipeline de ML para CT.
Caraterísticas
A lista seguinte realça as caraterísticas da configuração de MLOps de nível 1, conforme mostrado na Figura 3:
Experiência rápida: os passos da experiência de ML são organizados. A transição entre passos é automática, o que leva a uma iteração rápida de experiências e a uma melhor preparação para mover todo o pipeline para produção.
CT do modelo em produção: o modelo é automaticamente preparado em produção com dados atualizados com base em acionadores de pipeline em direto, que são abordados na secção seguinte.
Simetria operacional experimental: a implementação do pipeline usada no ambiente de desenvolvimento ou de experiência é usada no ambiente de pré-produção e de produção, o que é um aspeto fundamental da prática de MLOps para unificar o DevOps.
Código modularizado para componentes e pipelines: para construir pipelines de ML, os componentes têm de ser reutilizáveis, compostos e potencialmente partilháveis em pipelines de ML. Por conseguinte, embora o código de EDA possa continuar a existir nos blocos de notas, o código-fonte dos componentes tem de ser modularizado. Além disso, os componentes devem ser idealmente contentorizados para fazer o seguinte:
- Desacoplar o ambiente de execução do tempo de execução do código personalizado.
- Tornar o código reproduzível entre os ambientes de desenvolvimento e de produção.
- Isolar cada componente no pipeline. Os componentes podem ter a sua própria versão do ambiente de tempo de execução e ter diferentes linguagens e bibliotecas.
Entrega contínua de modelos: um pipeline de AA em produção fornece continuamente serviços de previsão a novos modelos que são preparados com novos dados. O passo de implementação do modelo, que publica o modelo preparado e validado como um serviço de previsão para previsões online, é automatizado.
Implementação de pipelines: no nível 0, implementa um modelo preparado como um serviço de previsão para produção. Para o nível 1, implementa um pipeline de preparação completo, que é executado automaticamente e de forma recorrente para publicar o modelo preparado como o serviço de previsão.
Componentes adicionais
Esta secção aborda os componentes que tem de adicionar à arquitetura para ativar a formação contínua de ML.
Validação de dados e modelos
Quando implementa o seu pipeline de ML na produção, um ou mais dos acionadores abordados na secção Acionadores do pipeline de ML executam automaticamente o pipeline. O pipeline espera novos dados em direto para produzir uma nova versão do modelo que é treinada com os novos dados (conforme mostrado na Figura 3). Por conseguinte, são necessários passos de validação de dados e validação de modelos automatizados no pipeline de produção para garantir o seguinte comportamento esperado:
Validação de dados: este passo é necessário antes da preparação do modelo para decidir se deve voltar a preparar o modelo ou parar a execução do pipeline. Esta decisão é tomada automaticamente se o pipeline tiver identificado o seguinte:
- Desvios do esquema de dados: estes desvios são considerados anomalias nos dados de entrada. Por conseguinte, os passos da pipeline a jusante, incluindo os passos de processamento de dados e preparação de modelos, recebem dados de entrada que não estão em conformidade com o esquema esperado. Neste caso, deve parar o pipeline para que a equipa de ciência de dados possa investigar. A equipa pode lançar uma correção ou uma atualização da conduta para processar estas alterações no esquema. As distorções do esquema incluem a receção de funcionalidades inesperadas, a não receção de todas as funcionalidades esperadas ou a receção de funcionalidades com valores inesperados.
- Desvios dos valores de dados: estes desvios são alterações significativas nas propriedades estatísticas dos dados, o que significa que os padrões de dados estão a mudar e tem de acionar uma nova formação do modelo para captar estas alterações.
Validação do modelo: este passo ocorre depois de preparar com êxito o modelo com os novos dados. Avalia e valida o modelo antes de o promover para produção. Este passo de validação do modelo offline consiste no seguinte.
- Produzir valores de métricas de avaliação usando o modelo preparado num conjunto de dados de teste para avaliar a qualidade preditiva do modelo.
- Comparar os valores das métricas de avaliação produzidos pelo modelo recém-formado com o modelo atual, por exemplo, o modelo de produção, o modelo de base ou outros modelos de requisitos empresariais. Certifica-se de que o novo modelo produz um desempenho melhor do que o modelo atual antes de o promover para produção.
- Garantir que o desempenho do modelo é consistente em vários segmentos dos dados. Por exemplo, o modelo de abandono de clientes recém-formado pode produzir uma precisão preditiva global melhor em comparação com o modelo anterior, mas os valores de precisão por região do cliente podem ter uma grande variação.
- Certificar-se de que testa o modelo para implementação, incluindo a compatibilidade da infraestrutura e a consistência com a API do serviço de previsão.
Além da validação do modelo offline, um modelo implementado recentemente é submetido a uma validação do modelo online, numa implementação canary ou numa configuração de testes A/B, antes de apresentar previsões para o tráfego online.
Feature Store
Um componente adicional opcional para a automatização do pipeline de ML de nível 1 é um repositório de funcionalidades. Uma loja de funcionalidades é um repositório centralizado onde padroniza a definição, o armazenamento e o acesso a funcionalidades para preparação e serviço. Um repositório de funcionalidades tem de fornecer uma API para a publicação em lote de alto débito e a publicação em tempo real de baixa latência para os valores das funcionalidades, e suportar cargas de trabalho de preparação e publicação.
O repositório de funcionalidades ajuda os cientistas de dados a fazer o seguinte:
- Descobrir e reutilizar conjuntos de funcionalidades disponíveis para as respetivas entidades, em vez de recriar conjuntos iguais ou semelhantes.
- Evite ter funcionalidades semelhantes com definições diferentes mantendo as funcionalidades e os respetivos metadados.
- Publicar valores de funcionalidades atualizados a partir da loja de funcionalidades.
Evite a discrepância entre a preparação e a publicação usando a loja de funcionalidades como a origem de dados para a experimentação, a preparação contínua e a publicação online. Esta abordagem garante que as funcionalidades usadas para a preparação são as mesmas que as usadas durante a publicação:
- Para a experimentação, os cientistas de dados podem obter uma extração offline da loja de funcionalidades para executar as respetivas experiências.
- Para a preparação contínua, o pipeline de preparação de ML automatizado pode obter um lote dos valores das funcionalidades atualizados do conjunto de dados que são usados para a tarefa de preparação.
- Para a previsão online, o serviço de previsão pode obter um lote dos valores das caraterísticas relacionados com a entidade pedida, como caraterísticas demográficas dos clientes, caraterísticas dos produtos e caraterísticas de agregação da sessão atual.
- Para a previsão online e a obtenção de caraterísticas, o serviço de previsão identifica as caraterísticas relevantes para uma entidade. Por exemplo, se a entidade for um cliente, as caraterísticas relevantes podem incluir a idade, o histórico de compras e o comportamento de navegação. O serviço agrupa estes valores de atributos e obtém todos os atributos necessários para a entidade de uma só vez, em vez de individualmente. Este método de obtenção ajuda na eficiência, especialmente quando precisa de gerir várias entidades.
Gestão de metadados
As informações sobre cada execução do pipeline de ML são registadas para ajudar com a linhagem de dados e artefactos, a reprodutibilidade e as comparações. Também ajuda a depurar erros e anomalias. Sempre que executa o pipeline, o armazenamento de metadados de ML regista os seguintes metadados:
- As versões do pipeline e dos componentes que foram executadas.
- A data e a hora de início e de conclusão, bem como o tempo que o pipeline demorou a concluir cada um dos passos.
- O executor da pipeline.
- Os argumentos dos parâmetros que foram transmitidos para o pipeline.
- Os ponteiros para os artefactos produzidos por cada passo do pipeline, como a localização dos dados preparados, as anomalias de validação, as estatísticas calculadas e o vocabulário extraído das caraterísticas categóricas. O acompanhamento destes resultados intermédios ajuda a retomar o pipeline a partir do passo mais recente se o pipeline tiver sido interrompido devido a um passo com falha, sem ter de executar novamente os passos já concluídos.
- Um ponteiro para o modelo treinado anterior se precisar de reverter para uma versão do modelo anterior ou se precisar de produzir métricas de avaliação para uma versão do modelo anterior quando o pipeline recebe novos dados de teste durante o passo de validação do modelo.
- As métricas de avaliação do modelo produzidas durante o passo de avaliação do modelo para os conjuntos de preparação e de testes. Estas métricas ajudam a comparar o desempenho de um modelo recém-treinado com o desempenho registado do modelo anterior durante o passo de validação do modelo.
Acionadores de pipelines de ML
Pode automatizar os pipelines de produção de AA para voltar a preparar os modelos com novos dados, consoante o seu exemplo de utilização:
- A pedido: execução manual ad hoc do pipeline.
- De forma agendada: os dados novos e etiquetados estão sistematicamente disponíveis para o sistema de ML numa base diária, semanal ou mensal. A frequência de reciclagem também depende da frequência com que os padrões de dados mudam e do custo da reciclagem dos seus modelos.
- Na disponibilidade de novos dados de preparação: os novos dados não estão disponíveis sistematicamente para o sistema de ML e, em vez disso, estão disponíveis numa base ad hoc quando são recolhidos novos dados e disponibilizados nas bases de dados de origem.
- Sobre a degradação do desempenho do modelo: o modelo é novamente preparado quando existe uma degradação do desempenho percetível.
- Em alterações significativas nas distribuições de dados (desvio de conceito). É difícil avaliar o desempenho completo do modelo online, mas nota alterações significativas nas distribuições de dados das funcionalidades usadas para fazer a previsão. Estas alterações sugerem que o modelo ficou desatualizado e que tem de ser novamente preparado com dados atualizados.
Desafios
Partindo do princípio de que as novas implementações do pipeline não são implementadas com frequência e que está a gerir apenas alguns pipelines, normalmente, testa manualmente o pipeline e os respetivos componentes. Além disso, implementa manualmente novas implementações de pipelines. Também envia o código-fonte testado para a equipa de TI para implementação no ambiente de destino. Esta configuração é adequada quando implementa novos modelos com base em novos dados, em vez de novas ideias de ML.
No entanto, tem de experimentar novas ideias de AA e implementar rapidamente novas implementações dos componentes de AA. Se gerir muitas pipelines de ML em produção, precisa de uma configuração de CI/CD para automatizar a criação, o teste e a implementação de pipelines de ML.
MLOps nível 2: automatização do pipeline de CI/CD
Para uma atualização rápida e fiável dos pipelines em produção, precisa de um sistema de CI/CD automatizado robusto. Este sistema de CI/CD automatizado permite que os seus cientistas de dados explorem rapidamente novas ideias sobre engenharia de funcionalidades, arquitetura de modelos e hiperparâmetros. Podem implementar estas ideias e criar, testar e implementar automaticamente os novos componentes do pipeline no ambiente de destino.
O diagrama seguinte mostra a implementação do pipeline de ML através de CI/CD, que tem as características da configuração de pipelines de ML automatizados, além das rotinas de CI/CD automatizadas.

Figura 4. CI/CD e pipeline de ML automatizado.
Esta configuração de MLOps inclui os seguintes componentes:
- Controlo de fontes
- Serviços de teste e compilação
- Serviços de implementação
- Registo de modelos
- Feature Store
- Armazenamento de metadados de ML
- Orquestrador de pipelines de ML
Caraterísticas
O diagrama seguinte mostra as fases do pipeline de automatização de CI/CD de ML:

Figura 5. Fases do pipeline de ML automatizado de CI/CD.
O pipeline consiste nas seguintes fases:
Desenvolvimento e experiências: experimenta iterativamente novos algoritmos de ML e nova modelagem em que as etapas da experiência são organizadas. O resultado desta fase é o código-fonte dos passos do pipeline de AA que são, em seguida, enviados para um repositório de origem.
Integração contínua do pipeline: compila o código-fonte e executa vários testes. Os resultados desta fase são componentes do pipeline (pacotes, ficheiros executáveis e artefactos) a implementar numa fase posterior.
Entrega contínua do pipeline: implementa os artefactos produzidos pela fase de CI no ambiente de destino. O resultado desta fase é um pipeline implementado com a nova implementação do modelo.
Acionamento automático: o pipeline é executado automaticamente em produção com base num horário ou em resposta a um acionador. O resultado desta fase é um modelo preparado que é enviado para o registo de modelos.
Implementação contínua de modelos: implementa o modelo preparado como um serviço de previsão para as previsões. O resultado desta fase é um serviço de previsão de modelo implementado.
Monitorização: recolhe estatísticas sobre o desempenho do modelo com base em dados em direto. O resultado desta fase é um acionador para executar o pipeline ou para executar um novo ciclo de experiência.
O passo de análise de dados continua a ser um processo manual para os cientistas de dados antes de o pipeline iniciar uma nova iteração da experiência. O passo de análise do modelo também é um processo manual.
Integração contínua
Nesta configuração, o pipeline e os respetivos componentes são criados, testados e embalados quando é feito o commit ou o push de novo código para o repositório de código fonte. Além de criar pacotes, imagens de contentores e ficheiros executáveis, o processo de CI pode incluir os seguintes testes:
Testar a lógica de engenharia de funcionalidades.
Testar as diferentes funções implementadas no seu modelo. Por exemplo, tem uma função que aceita uma coluna de dados categóricos e codifica a função como uma caraterística one-hot.
Testar se a preparação do modelo converge (ou seja, a perda do modelo diminui por iterações e ajusta-se em demasia a alguns registos de amostra).
Testar se a preparação do modelo não produz valores NaN devido à divisão por zero ou à manipulação de valores pequenos ou grandes.
Testar se cada componente no pipeline produz os artefactos esperados.
Testar a integração entre componentes do pipeline.
Entrega contínua
Neste nível, o seu sistema fornece continuamente novas implementações de pipelines ao ambiente de destino, que, por sua vez, fornece serviços de previsão do modelo recentemente preparado. Para uma entrega contínua rápida e fiável de pipelines e modelos, deve considerar o seguinte:
Validar a compatibilidade do modelo com a infraestrutura de destino antes de implementar o modelo. Por exemplo, tem de verificar se os pacotes exigidos pelo modelo estão instalados no ambiente de publicação e se os recursos de memória, computação e acelerador necessários estão disponíveis.
Testar o serviço de previsão chamando a API de serviço com as entradas esperadas e certificar-se de que recebe a resposta esperada. Normalmente, este teste captura problemas que podem ocorrer quando atualiza a versão do modelo e espera uma entrada diferente.
Testar o desempenho do serviço de previsão, o que envolve testar a carga do serviço para captar métricas como consultas por segundo (QPS) e latência do modelo.
Validar os dados para reciclagem ou previsão em lote.
Verificar se os modelos cumprem os alvos de desempenho preditivo antes de serem implementados.
Implementação automatizada num ambiente de teste, por exemplo, uma implementação que é acionada pelo envio de código para o ramo de desenvolvimento.
Implementação semiautomática num ambiente de pré-produção, por exemplo, uma implementação acionada pela união de código ao ramo principal depois de os revisores aprovarem as alterações.
Implementação manual num ambiente de produção após várias execuções bem-sucedidas do pipeline no ambiente de pré-produção.
Em resumo, a implementação da aprendizagem automática num ambiente de produção não significa apenas implementar o seu modelo como uma API para previsão. Em vez disso, significa implementar um pipeline de ML que possa automatizar a reciclagem e a implementação de novos modelos. A configuração de um sistema de CI/CD permite-lhe testar e implementar automaticamente novas implementações de pipelines. Este sistema permite-lhe lidar com alterações rápidas nos seus dados e no ambiente empresarial. Não tem de mover imediatamente todos os seus processos de um nível para outro. Pode implementar gradualmente estas práticas para ajudar a melhorar a automatização do desenvolvimento e da produção do seu sistema de ML.
O que se segue?
- Saiba mais sobre a arquitetura para MLOps com o TensorFlow Extended, os Vertex AI Pipelines e o Cloud Build.
- Saiba mais sobre o guia do profissional para operações de aprendizagem automática (MLOps).
- Veja as práticas recomendadas de MLOps no Google Cloud (Cloud Next '19) no YouTube.
- Para uma vista geral dos princípios e recomendações de arquitetura específicos das cargas de trabalho de IA e ML no Google Cloud, consulte aperspetiva de IA e ML no Well-Architected Framework.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
Colaboradores
Autores:
- Jarek Kazmierczak | Solutions Architect
- Khalid Salama | Staff Software Engineer, Machine Learning
- Valentin Huerta | Engenheiro de IA
Outro colaborador: Sunil Kumar Jang Bahadur | Customer Engineer