Ce tutoriel présente une solution prête à l'emploi qui exploite Google Distributed Cloud et Config Sync pour déployer des clusters Kubernetes en périphérie à grande échelle. Ce tutoriel est destiné aux opérateurs de plate-forme et aux développeurs. Vous devez connaître les technologies et concepts suivants:
- Guides Ansible.
- Déploiements en périphérie et défis associés
- Utilisation d'un projet Google Cloud
- Déployer une application Web en conteneur.
- Interfaces de ligne de commande
gcloudetkubectl
Dans ce tutoriel, vous allez utiliser des machines virtuelles (VM) Compute Engine pour émuler des nœuds déployés en périphérie et un exemple d'application de point de vente en tant que charge de travail de périphérie. Google Distributed Cloud et Config Sync fournissent une gestion et un contrôle centralisés pour votre cluster périphérique. Config Sync extrait dynamiquement les nouvelles configurations à partir de GitHub, et applique ces règles et configurations à vos clusters.
Architecture de déploiement en périphérie
Un déploiement Retail Edge est un bon moyen d'illustrer l'architecture utilisée dans un déploiement Google Distributed Cloud classique.
Un magasin physique est le point d'interaction le plus proche entre une unité commerciale d'entreprise et le consommateur. Les systèmes logiciels dans les magasins doivent exécuter leurs charges de travail, recevoir des mises à jour en temps opportun et générer des rapports sur les métriques critiques indépendamment du système de gestion centrale de l'entreprise. De plus, ces systèmes logiciels doivent être conçus de manière à pouvoir être étendus à d'autres magasins à l'avenir. Bien que Google Distributed Cloud répond à toutes ces exigences pour les systèmes logiciels de magasin, le profil périphérique convient à un cas d'utilisation important: les déploiements dans des environnements avec des ressources matérielles limitées, comme une vitrine de magasin.
Le schéma suivant illustre un déploiement Google Distributed Cloud qui utilise le profil périphérique dans un magasin de détail:
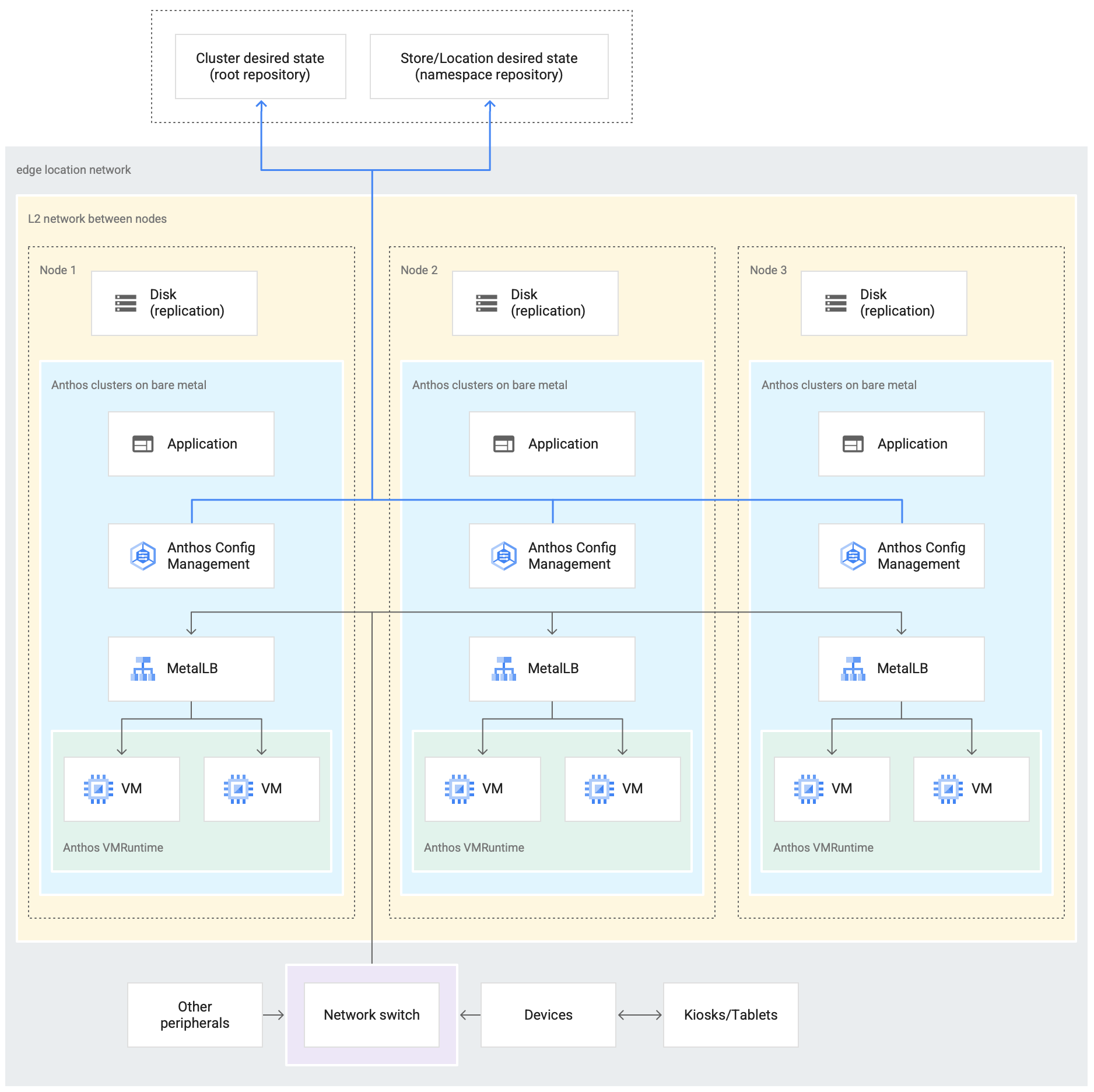
Le schéma précédent montre un magasin physique classique. Le magasin propose des appareils intelligents tels que des lecteurs de cartes, des points de vente, des appareils photo et des imprimantes.
Le magasin dispose également de trois appareils de calcul physique (identifiés Node 1, Node 2 et Node 3). Tous ces appareils sont connectés à un commutateur réseau central. Ainsi, les trois appareils informatiques sont connectés les uns aux autres via un réseau de couche 2. Les dispositifs informatiques mis en réseau constituent l'infrastructure Bare Metal.
Google Distributed Cloud s'exécute dans chacun des trois appareils informatiques. Ces appareils possèdent également leur propre espace de stockage sur disque et sont configurés pour la réplication des données entre eux afin d'assurer une haute disponibilité.
Le schéma montre également les composants clés suivants, qui font partie d'un déploiement Google Distributed Cloud:
- Le composant signalé comme MetalLB est l'équilibreur de charge groupé qui est déployé avec Google Distributed Cloud.
- Le composant Config Sync permet de synchroniser l'état du cluster avec les dépôts sources. Il s'agit d'un module complémentaire facultatif fortement recommandé qui nécessite une installation et une configuration distinctes. Pour en savoir plus sur la configuration de Config Sync et sur les différentes nomenclatures, consultez la documentation de Config Sync.
Le dépôt racine et le dépôt d'espaces de noms affichés en haut du schéma, en dehors de l'emplacement du magasin, représentent deux dépôts sources.
Les modifications apportées au cluster sont transférées vers ces dépôts sources centraux. Les déploiements Google Distributed Cloud dans différents emplacements périphériques extraient des mises à jour à partir des dépôts sources. Ce comportement est représenté par les flèches qui relient les deux dépôts du schéma aux composants Config Sync au sein du cluster GKE sur Bare Metal exécuté sur les appareils.
L'environnement d'exécution de VM sur GDC est un autre composant clé représenté dans le cadre du cluster. L'environnement d'exécution des VM sur GDC permet d'exécuter des charges de travail existantes basées sur des VM dans le cluster sans avoir besoin de conteneuriser. La documentation de l'environnement d'exécution des VM sur GDC explique comment l'activer et déployer vos charges de travail de VM dans le cluster.
Le composant marqué Application désigne le logiciel déployé dans le cluster par le magasin. L'application de point de vente utilisée sur les kiosques d'un magasin de détail en est un exemple.
Les cases au bas du schéma représentent les nombreux appareils (kiosques, tablettes ou caméras, par exemple) dans un magasin de détail, qui sont tous connectés à un commutateur réseau central. La mise en réseau locale au sein du magasin permet aux applications exécutées dans le déploiement Google Distributed Cloud d'atteindre ces appareils.
Dans la section suivante, vous verrez l'émulation du déploiement de ce magasin dans Google Cloud à l'aide de VM Compute Engine. C'est cette émulation que vous allez utiliser dans le tutoriel suivant pour tester Google Distributed Cloud.
Émulation du déploiement en périphérie dans Google Cloud
Le schéma suivant illustre tout ce que vous allez configurer dans Google Cloud dans ce tutoriel. Ce schéma correspond au schéma présenté dans la section précédente concernant le magasin de vente au détail. Ce déploiement représente un emplacement périphérique émulé dans lequel l'application de point de vente est déployée. L'architecture présente également un exemple de charge de travail d'application de point de vente simple que vous utilisez dans ce tutoriel. Vous accédez à l'application de point de vente dans le cluster en utilisant un navigateur Web en tant que kiosque.
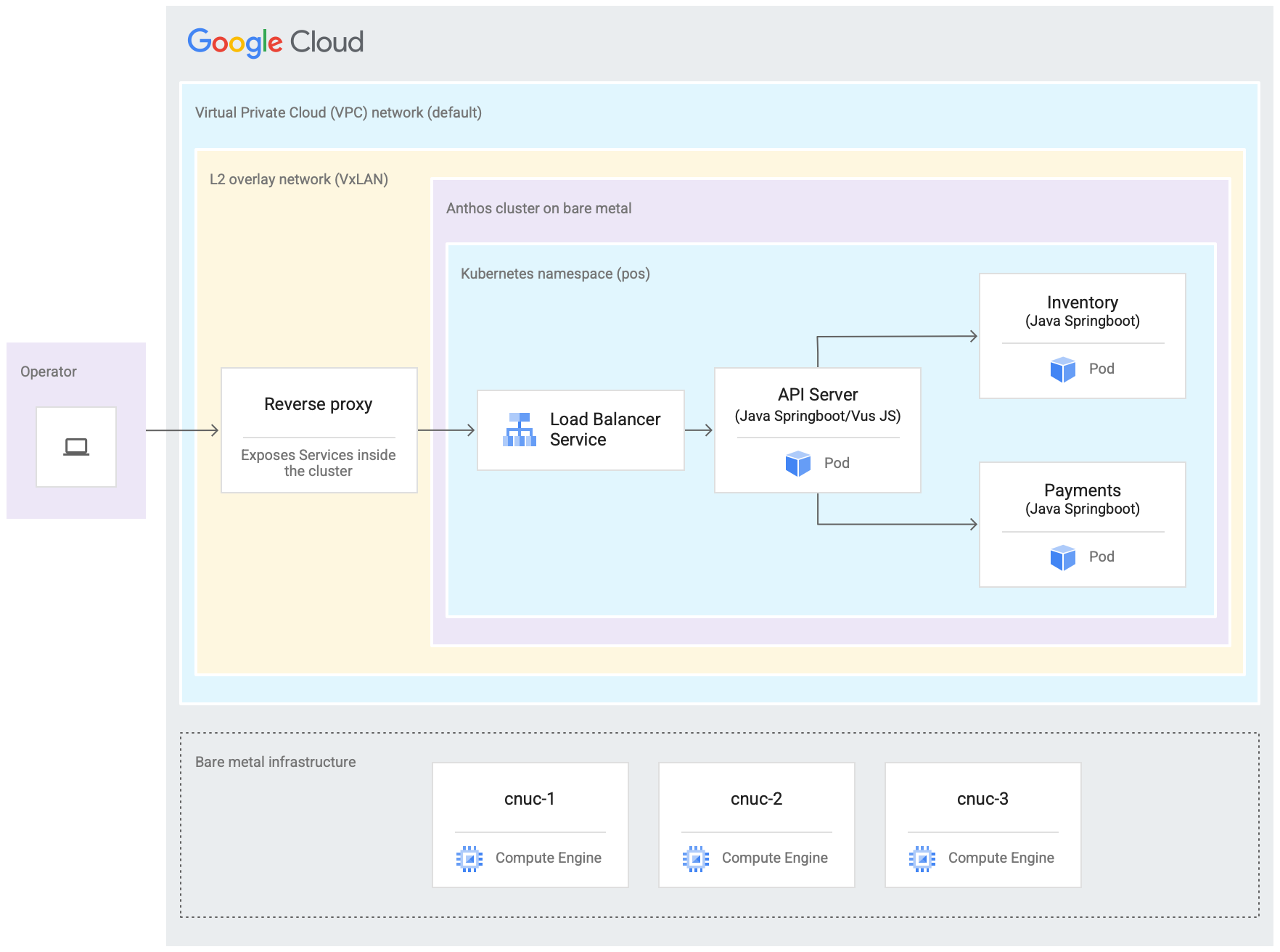
Les trois machines virtuelles (VM) Compute Engine présentées dans le schéma précédent représentent le matériel physique (ou les nœuds) dans un emplacement périphérique typique. Ce matériel serait connecté avec des commutateurs réseau pour constituer l'infrastructure Bare Metal. Dans notre environnement émulé dans Google Cloud, ces VM sont connectées les unes aux autres via le réseau cloud privé virtuel (VPC) par défaut du projet Google Cloud.
Dans une installation Google Distributed Cloud classique, vous pouvez configurer vos propres équilibreurs de charge. Toutefois, pour ce tutoriel, vous ne configurez pas d'équilibreur de charge externe. Utilisez plutôt l'équilibreur de charge MetalLB groupé qui est installé avec Google Distributed Cloud. L'équilibreur de charge MetalLB groupé nécessite une connectivité réseau de couche 2 entre les nœuds. Ainsi, la connectivité de couche 2 entre les VM Compute Engine est activée en créant un réseau VxLAN en superposition au-dessus du réseau cloud privé virtuel (VPC) par défaut.
Dans le rectangle intitulé "L2 superposition network (VxLAN)" sont affichés les composants logiciels exécutés dans les trois VM Compute Engine. Ce rectangle comprend le cluster GKE sur Bare Metal et un proxy inverse. Le cluster est représenté par le rectangle "Google Distributed Cloud". Ce rectangle représentant le cluster inclut un autre rectangle marqué "Espace de noms Kubernetes (pos)". Cela représente un espace de noms Kubernetes à l'intérieur du cluster. Tous les composants de cet espace de noms Kubernetes constituent l'application de point de vente déployée dans le cluster GKE sur Bare Metal. L'application de point de vente comporte trois microservices: serveur d'API, inventaire et paiements. Tous ces composants représentent une "application", illustrée dans le schéma de l'architecture de déploiement Edge précédent.
L'équilibreur de charge MetalLB groupé du cluster GKE sur Bare Metal n'est pas directement accessible depuis l'extérieur des VM. Le schéma montre un proxy inverse NGINX configuré pour s'exécuter à l'intérieur des VM afin d'acheminer le trafic entrant des VM Compute Engine vers l'équilibreur de charge. Il ne s'agit que d'une solution de contournement pour les besoins de ce tutoriel, dans lesquels les nœuds périphériques sont émulés à l'aide de VM Google Cloud Compute Engine. Dans un emplacement périphérique réel, cela peut être fait avec une configuration réseau appropriée.
Objectifs
- Utiliser des VM Compute Engine pour émuler une infrastructure Bare Metal qui s'exécute dans un emplacement périphérique
- Créez un cluster GKE sur Bare Metal dans l'infrastructure de périphérie émulée.
- Connectez et enregistrez le cluster auprès de Google Cloud.
- Déployez un exemple de charge de travail d'application de point de vente sur le cluster GKE sur Bare Metal.
- Utilisez la console Google Cloud pour vérifier et surveiller l'application de point de vente qui fonctionne à l'emplacement périphérique.
- Utilisez Config Sync pour mettre à jour l'application de point de vente qui s'exécute sur le cluster GKE sur Bare Metal.
Avant de commencer
Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Installez et initialize la Google Cloud CLI.
Dupliquer et cloner le dépôt anthos-samples
Tous les scripts utilisés dans ce tutoriel sont stockés dans le dépôt anthos-samples. La structure de dossiers sous /anthos-bm-edge-deployment/acm-config-sink est organisée en fonction des attentes de Config Sync.
Clonez ce dépôt dans votre propre compte GitHub avant de passer aux étapes suivantes.
Si vous n'avez pas encore de compte, créez-en un sur GitHub.
Créez un jeton d'accès personnel à utiliser dans la configuration de Config Sync. Cela est nécessaire pour que les composants Config Sync du cluster s'authentifient avec votre compte GitHub lors de la tentative de synchronisation de nouvelles modifications.
- Sélectionnez uniquement le niveau d'accès
public_repo. - Enregistrez le jeton d'accès que vous avez créé en lieu sûr pour pouvoir l'utiliser ultérieurement.
- Sélectionnez uniquement le niveau d'accès
Dupliquez le dépôt
anthos-samplessur votre propre compte GitHub :- Accédez au dépôt anthos-samples.
- Cliquez sur l'icône Dupliquer en haut à droite de la page.
- Cliquez sur le compte utilisateur GitHub vers lequel vous souhaitez dupliquer le dépôt. Vous êtes automatiquement redirigé vers la page contenant votre version dupliquée du dépôt
anthos-samples.
Ouvrez un terminal dans votre environnement local.
Clonez le dépôt dupliqué en exécutant la commande suivante, où GITHUB_USERNAME est le nom d'utilisateur de votre compte GitHub:
git clone https://github.com/GITHUB_USERNAME/anthos-samples cd anthos-samples/anthos-bm-edge-deployment
Configurer l'environnement de la station de travail
Pour terminer le déploiement en périphérie décrit dans ce document, vous devez disposer d'un poste de travail ayant accès à Internet et des outils suivants installés:
- Docker
- Outil d'interface de ligne de commande envsubst (généralement préinstallé sous Linux et d'autres systèmes d'exploitation de type Unix)
Exécutez toutes les commandes du tutoriel sur la station de travail que vous configurez dans cette section.
Sur votre poste de travail, initialisez les variables d'environnement dans une nouvelle instance de shell:
export PROJECT_ID="PROJECT_ID" export REGION="us-central1" export ZONE="us-central1-a" # port on the admin Compute Engine instance you use to set up an nginx proxy # this allows to reach the workloads inside the cluster via the VM IP export PROXY_PORT="8082" # should be a multiple of 3 since N/3 clusters are created with each having 3 nodes export GCE_COUNT="3" # url to the fork of: https://github.com/GoogleCloudPlatform/anthos-samples export ROOT_REPO_URL="https://github.com/GITHUB_USERNAME/anthos-samples" # this is the username used to authenticate to your fork of this repository export SCM_TOKEN_USER="GITHUB_USERNAME" # access token created in the earlier step export SCM_TOKEN_TOKEN="ACCESS_TOKEN"Remplacez les valeurs suivantes :
- PROJECT_ID : ID de votre projet Google Cloud.
- GITHUB_USERNAME : votre nom d'utilisateur GitHub.
- ACCESS_TOKEN: jeton d'accès personnel que vous avez créé pour votre dépôt GitHub.
Conservez les valeurs par défaut des autres variables d'environnement. Elles sont expliquées dans les sections suivantes.
Sur votre poste de travail, initialisez la Google Cloud CLI:
gcloud config set project "${PROJECT_ID}" gcloud services enable compute.googleapis.com gcloud config set compute/region "${REGION}" gcloud config set compute/zone "${ZONE}"Sur votre poste de travail, créez le compte de service Google Cloud pour les instances Compute Engine. Ce script crée le fichier de clé JSON pour le nouveau compte de service à l'adresse
<REPO_ROOT>/anthos-bm-edge-deployment/build-artifacts/consumer-edge-gsa.json. Il configure également le trousseau de clés et la clé Cloud Key Management Service pour le chiffrement par clé privée SSH../scripts/create-primary-gsa.shL'exemple suivant n'est qu'une partie du script. Pour afficher l'intégralité du script, cliquez sur Afficher sur GitHub.
Provisionner les instances Compute Engine
Dans cette section, vous allez créer les VM Compute Engine sur lesquelles Google Distributed Cloud sera installé. Vous vérifierez également la connectivité à ces VM avant de passer à la section d'installation.
Sur votre poste de travail, créez des clés SSH utilisées pour la communication entre les instances Compute Engine.
ssh-keygen -f ./build-artifacts/consumer-edge-machineChiffrer la clé privée SSH à l'aide de Cloud Key Management Service
gcloud kms encrypt \ --key gdc-ssh-key \ --keyring gdc-ce-keyring \ --location global \ --plaintext-file build-artifacts/consumer-edge-machine \ --ciphertext-file build-artifacts/consumer-edge-machine.encryptedGénérez le fichier de configuration de l'environnement
.envrcet récupérez-le. Une fois le fichier.envrccréé, inspectez le fichier pour vous assurer que les variables d'environnement ont été remplacées par les bonnes valeurs.envsubst < templates/envrc-template.sh > .envrc source .envrcVoici un exemple de fichier
.envrcgénéré en remplaçant les variables d'environnement dans le fichiertemplates/envrc-template.sh. Notez que les lignes mises à jour sont en surbrillance:Créer des instances Compute Engine sur lesquelles Google Distributed Cloud est installé
./scripts/cloud/create-cloud-gce-baseline.sh -c "$GCE_COUNT" | \ tee ./build-artifacts/gce-info
Installer Google Distributed Cloud avec Ansible
Le script utilisé dans ce guide crée des clusters GKE sur Bare Metal dans des groupes de trois instances Compute Engine. Le nombre de clusters créés est contrôlé par la variable d'environnement GCE_COUNT. Par exemple, vous définissez la variable d'environnement GCE_COUNT sur 6 pour créer deux clusters GKE sur Bare Metal comportant chacun 3 instances de VM. Par défaut, la variable d'environnement GCE_COUNT est définie sur 3. Ainsi, dans ce guide, un cluster avec 3 instances Compute Engine sera créé. Les instances de VM sont nommées avec le préfixe cnuc- suivi d'un nombre. La première instance de VM de chaque cluster fait office de poste de travail administrateur à partir duquel l'installation est déclenchée. Le cluster porte également le même nom que la VM du poste de travail administrateur (par exemple, cnuc-1, cnuc-4, cnuc-7).
Le playbook Ansible effectue les opérations suivantes :
- Il configure les instances Compute Engine avec les outils nécessaires, tels que
docker,bmctl,gcloudetnomos. - Il installe Google Distributed Cloud dans les instances Compute Engine configurées.
- crée un cluster GKE sur Bare Metal autonome nommé
cnuc-1; - Il enregistre le cluster
cnuc-1à l'aide de Google Cloud. - Il installe Config Sync dans le cluster
cnuc-1. - Configure Config Sync pour qu'il se synchronise avec les configurations de cluster situées dans
anthos-bm-edge-deployment/acm-config-sinkdans votre dépôt dupliqué. - Il génère le
Login tokenpour le cluster.
Pour configurer et lancer le processus d'installation, procédez comme suit:
Sur votre poste de travail, créez l'image Docker utilisée pour l'installation. Cette image dispose de tous les outils nécessaires au processus d'installation, comme Ansible, Python et la Google Cloud CLI.
gcloud builds submit --config docker-build/cloudbuild.yaml docker-build/Lorsque la compilation s'exécute correctement, elle produit un résultat semblable à celui-ci:
... latest: digest: sha256:99ded20d221a0b2bcd8edf3372c8b1f85d6c1737988b240dd28ea1291f8b151a size: 4498 DONE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ID CREATE_TIME DURATION SOURCE IMAGES STATUS 2238baa2-1f41-440e-a157-c65900b7666b 2022-08-17T19:28:57+00:00 6M53S gs://my_project_cloudbuild/source/1660764535.808019-69238d8c870044f0b4b2bde77a16111d.tgz gcr.io/my_project/consumer-edge-install (+1 more) SUCCESSGénérez le fichier d'inventaire Ansible à partir du modèle.
envsubst < templates/inventory-cloud-example.yaml > inventory/gcp.yamlExécutez le script d'installation qui lance un conteneur Docker à partir de l'image créée précédemment. Le script utilise Docker en interne pour générer le conteneur avec un montage de volume dans le répertoire de travail actuel. Une fois ce script exécuté avec succès, vous devez vous trouver dans le conteneur Docker qui a été créé. Vous déclenchez l'installation d'Ansible à partir de ce conteneur.
./install.shLorsque le script s'exécute correctement, il produit un résultat semblable à celui-ci:
... Check the values above and if correct, do you want to proceed? (y/N): y Starting the installation Pulling docker install image... ============================== Starting the docker container. You will need to run the following 2 commands (cut-copy-paste) ============================== 1: ./scripts/health-check.sh 2: ansible-playbook all-full-install.yaml -i inventory 3: Type 'exit' to exit the Docker shell after installation ============================== Thank you for using the quick helper script! (you are now inside the Docker shell)Depuis le conteneur Docker, vérifiez l'accès aux instances Compute Engine.
./scripts/health-check.shLorsque le script s'exécute correctement, il produit un résultat semblable à celui-ci:
... cnuc-2 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-3 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-1 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"}Depuis le conteneur Docker, exécutez le playbook Ansible pour installer Google Distributed Cloud sur des instances Compute Engine. Une fois l'opération terminée, le
Login Tokendu cluster s'affiche à l'écran.ansible-playbook all-full-install.yaml -i inventory | tee ./build-artifacts/ansible-run.logLorsque l'installation s'exécute correctement, elle produit un résultat semblable à celui-ci:
... TASK [abm-login-token : Display login token] ************************************************************************** ok: [cnuc-1] => { "msg": "eyJhbGciOiJSUzI1NiIsImtpZCI6Imk2X3duZ3BzckQyWmszb09sZHFMN0FoWU9mV1kzOWNGZzMyb0x2WlMyalkifQ.eymljZS1hY2NvdW iZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImVkZ2Etc2EtdG9rZW4tc2R4MmQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2Nvd 4CwanGlof6s-fbu8" } skipping: [cnuc-2] skipping: [cnuc-3] PLAY RECAP *********************************************************************************************************** cnuc-1 : ok=205 changed=156 unreachable=0 failed=0 skipped=48 rescued=0 ignored=12 cnuc-2 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2 cnuc-3 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2
Se connecter au cluster GKE sur Bare Metal dans la console Google Cloud
Une fois le playbook Ansible exécuté jusqu'à la fin, un cluster GKE sur Bare Metal autonome est installé dans les VM Compute Engine. Ce cluster est également enregistré dans Google Cloud à l'aide de l'agent Connect. Toutefois, pour afficher les détails de ce cluster, vous devez vous y connecter à partir de la console Google Cloud. Pour vous connecter au cluster GKE, procédez comme suit.
Copiez le jeton figurant dans la sortie du playbook Ansible de la section précédente.
Dans la console Google Cloud, accédez à la page Clusters Kubernetes et utilisez le jeton copié pour vous connecter au cluster
cnuc-1.Accéder à la page des clusters Kubernetes
- Dans la liste des clusters, cliquez sur Actions à côté du cluster
cnuc-1, puis sur Se connecter. - Sélectionnez Jeton et collez le jeton copié.
- Cliquez sur Login (Connexion).
- Dans la liste des clusters, cliquez sur Actions à côté du cluster
- Dans la console Google Cloud, accédez à la page Configuration sous la section Fonctionnalités.
Dans l'onglet Packages, consultez la colonne État de synchronisation dans la table du cluster.
Vérifiez que l'état est Synchronisé. L'état Synced (Synchronisé) indique que Config Sync a correctement synchronisé vos configurations GitHub avec votre cluster déployé, cnuc-1.
Configurer un proxy pour le trafic externe
Le cluster GKE sur Bare Metal installé aux étapes précédentes utilise un équilibreur de charge groupé appelé MetalLB.
Ce service d'équilibrage de charge est accessible uniquement via une adresse IP de cloud privé virtuel (VPC). Pour acheminer le trafic entrant via son adresse IP externe vers l'équilibreur de charge groupé, configurez un service de proxy inverse dans l'hôte administrateur (cnuc-1). Ce service de proxy inverse vous permet d'accéder au serveur d'API de l'application de point de vente via l'adresse IP externe de l'hôte administrateur (cnuc-1).
Les scripts d'installation des étapes précédentes ont installé NGINX sur les hôtes d'administration, ainsi qu'un exemple de fichier de configuration. Mettez à jour ce fichier pour utiliser l'adresse IP du service d'équilibrage de charge et redémarrez NGINX.
Sur votre poste de travail, utilisez SSH pour vous connecter au poste de travail administrateur:
ssh -F ./build-artifacts/ssh-config abm-admin@cnuc-1Depuis le poste de travail administrateur, configurez le proxy inverse NGINX pour acheminer le trafic vers le service d'équilibrage de charge du serveur d'API. Obtenez l'adresse IP du service Kubernetes de type d'équilibreur de charge:
ABM_INTERNAL_IP=$(kubectl get services api-server-lb -n pos | awk '{print $4}' | tail -n 1)Mettez à jour le fichier de configuration du modèle avec l'adresse IP récupérée:
sudo sh -c "sed 's/<K8_LB_IP>/${ABM_INTERNAL_IP}/g' \ /etc/nginx/nginx.conf.template > /etc/nginx/nginx.conf"Redémarrez NGINX pour vous assurer que la nouvelle configuration est appliquée:
sudo systemctl restart nginxVérifiez et vérifiez l'état du serveur NGINX pour indiquer l'état "active (running)":
sudo systemctl status nginxLorsque NGINX s'exécute correctement, il produit un résultat semblable à l'exemple suivant:
● nginx.service - A high performance web server and a reverse proxy server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2021-09-17 02:41:01 UTC; 2s ago Docs: man:nginx(8) Process: 92571 ExecStartPre=/usr/sbin/nginx -t -q -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Process: 92572 ExecStart=/usr/sbin/nginx -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Main PID: 92573 (nginx) Tasks: 17 (limit: 72331) Memory: 13.2M CGroup: /system.slice/nginx.service ├─92573 nginx: master process /usr/sbin/nginx -g daemon on; master_process on; ├─92574 nginx: worker process ├─92575 nginx: worker process ├─92577 nginx: .... ... ...Quittez la session SSH sur le poste de travail administrateur:
exitQuittez la session de shell dans le conteneur Docker. Lorsque vous quittez l'instance admin, vous vous trouvez toujours dans le conteneur Docker utilisé pour l'installation:
exit
Accéder à l'application de point de vente
La configuration du proxy externe vous permet d'accéder à l'application exécutée dans le cluster GKE. Pour accéder à l'exemple d'application de point de vente, procédez comme suit.
Sur votre poste de travail, obtenez l'adresse IP externe de l'instance Compute Engine d'administration et accédez à l'interface utilisateur de l'application de point de vente:
EXTERNAL_IP=$(gcloud compute instances list \ --project ${PROJECT_ID} \ --filter="name:cnuc-1" \ --format="get(networkInterfaces[0].accessConfigs[0].natIP)") echo "Point the browser to: ${EXTERNAL_IP}:${PROXY_PORT}"Lorsque les scripts s'exécutent correctement, ils génèrent un résultat semblable au suivant :
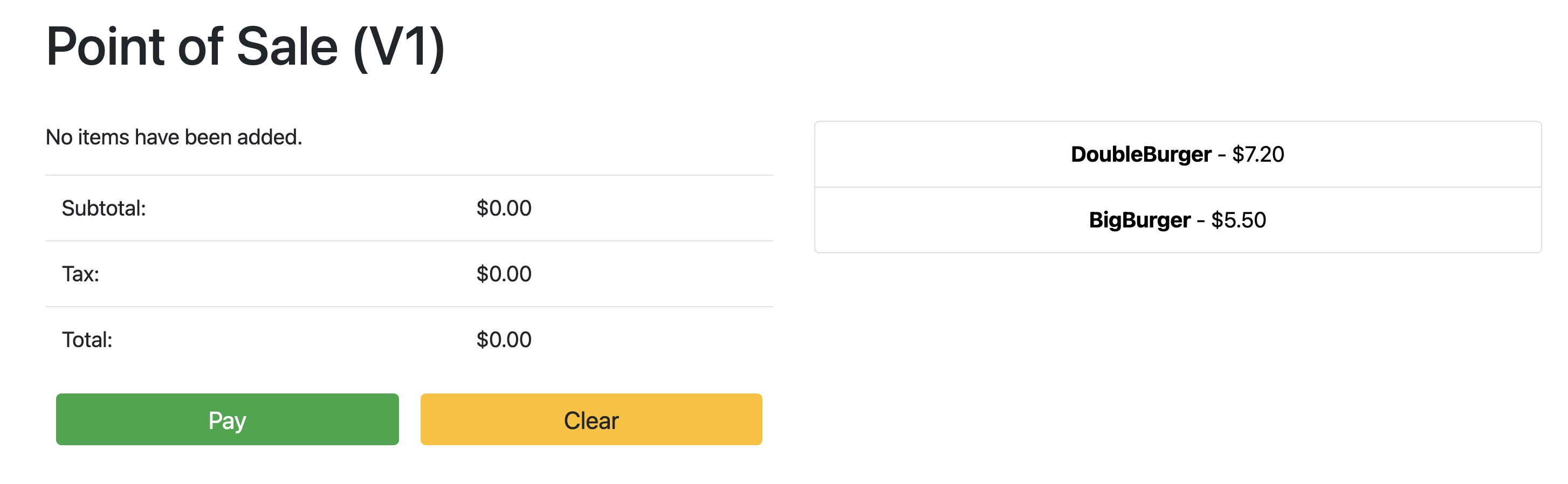
Point the browser to: 34.134.194.84:8082Ouvrez votre navigateur Web et accédez à l'adresse IP indiquée dans le résultat de la commande précédente. Vous pouvez accéder à l'exemple d'application de point de vente et le tester, comme illustré dans la capture d'écran suivante:
Mettre à jour le serveur d'API à l'aide de Config Sync
L'exemple d'application peut être mis à niveau vers une version plus récente en mettant à jour les fichiers de configuration dans le dépôt racine. Config Sync détecte les mises à jour et apporte automatiquement les modifications à votre cluster. Dans cet exemple, le dépôt racine est le dépôt anthos-samples que vous avez cloné au début de ce guide. Pour découvrir comment l'exemple d'application de point de vente peut effectuer un déploiement de mise à niveau vers une version plus récente, procédez comme suit.
Sur votre station de travail, mettez à jour le champ
imagepour remplacer la version du serveur d'APIv1parv2. La configuration YAML du déploiement se trouve dans le fichier à l'emplacementanthos-bm-edge-deployment/acm-config-sink/namespaces/pos/api-server.yaml.Ajoutez les modifications, validez-les et déployez-les dans votre dépôt dupliqué:
git add acm-config-sink/namespaces/pos/api-server.yaml git commit -m "chore: updated api-server version to v2" git pushDans la console Google Cloud, accédez à la page Config Sync pour vérifier l'état de la spécification de configuration. Vérifiez que l'état est Synchronisé.
Dans la console Google Cloud, accédez à la page Charges de travail Kubernetes Engine pour vérifier que le déploiement est bien mis à jour.
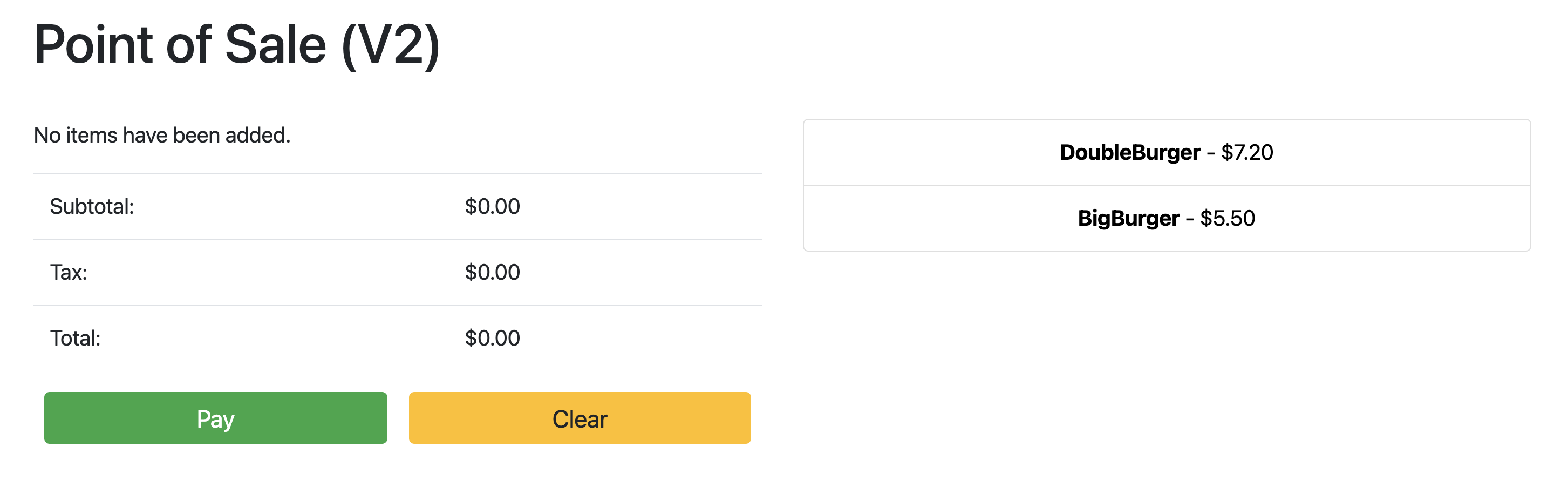
Lorsque l'état du déploiement est OK, faites pointer votre navigateur vers l'adresse IP de la section précédente pour afficher l'application de point de vente. Notez que la version dans le titre indique "V2", ce qui indique que la modification de votre application a été déployée, comme illustré dans la capture d'écran suivante:
Vous devrez peut-être actualiser l'onglet du navigateur pour voir les modifications.
Effectuer un nettoyage
Pour éviter d'encourir des frais inutiles liés à Google Cloud, supprimez les ressources utilisées dans ce guide lorsque vous n'en avez plus besoin. Vous pouvez supprimer ces ressources manuellement ou supprimer votre projet Google Cloud, ce qui supprime également toutes les ressources associées. En outre, vous pouvez supprimer les modifications apportées sur votre station de travail locale :
Station de travail locale
Vous devez mettre à jour les fichiers suivants pour supprimer les modifications apportées par les scripts d'installation.
- Supprimez les adresses IP des VM Compute Engine ajoutées au fichier
/etc/hosts. - Supprimez la configuration SSH de
cnuc-*dans le fichier~/.ssh/config. - Supprimez les empreintes des VM Compute Engine du fichier
~/.ssh/known_hosts.
Suppression du projet
Si vous avez créé un projet dédié pour cette procédure, supprimez le projet Google Cloud de la console Google Cloud.
Manuel
Si vous avez utilisé un projet existant pour cette procédure, procédez comme suit :
- Annulez l'enregistrement de tous les clusters Kubernetes dont le nom commence par le préfixe
cnuc-. - Supprimez toutes les VM Compute Engine dont le nom commence par le préfixe
cnuc-. - Supprimez le bucket Cloud Storage dont le nom commence par le préfixe
abm-edge-boot. - Supprimez les règles de pare-feu
allow-pod-ingressetallow-pod-egress. - Supprimez le secret Secret Manager
install-pub-key.
Étape suivante
Vous pouvez développer ce guide en ajoutant un autre emplacement périphérique. Définir la variable d'environnement GCE_COUNT sur 6 et exécuter à nouveau les étapes décrites dans les sections précédentes crée trois instances Compute Engine (cnuc-4, cnuc-5, cnuc-6) et un cluster GKE sur Bare Metal nommé cnuc-4.
Vous pouvez également essayer de mettre à jour les configurations de cluster dans votre dépôt dupliqué pour appliquer de manière sélective différentes versions de l'application de point de vente aux deux clusters, cnuc-1 et cnuc-4, à l'aide de ClusterSelectors.
Pour en savoir plus sur les étapes individuelles du présent guide ainsi que sur les scripts impliqués, consultez le dépôt anthos-samples.