このページでは、クエリ分析情報ダッシュボードを使用してパフォーマンスの問題を検出して分析する方法について説明します。この機能の概要については、Query Insights の概要をご覧ください。
Gemini Cloud Assist を使用すると、AlloyDB リソースのモニタリングとトラブルシューティングを行うことができます。詳細については、Gemini の支援機能によるモニタリングとトラブルシューティングをご覧ください。
始める前に
自分または他のユーザーがクエリプランの表示やエンドツーエンドのトレースを行う必要がある場合は、特定の Identity and Access Management(IAM)権限が必要です。カスタムロールを作成し、必要な IAM 権限を追加できます。その後、クエリ分析情報を使用して問題のトラブルシューティングを行うユーザー アカウントに、このロールを追加できます。カスタムロールの作成に関するページをご覧ください。
カスタムロールには、IAM 権限 cloudtrace.traces.get が必要です。
クエリ分析情報ダッシュボードを開く
クエリ分析情報ダッシュボードを開くには、次の操作を行います。
- クラスタとインスタンスのリストで、インスタンスをクリックします。
- クラスタの [概要] ページの指標グラフの下にある [Query Insights に移動すると、クエリとパフォーマンスに関する詳細情報を確認できます] をクリックするか、左側のナビゲーション パネルで [Query Insights] タブを選択します。
後続のページで、次のオプションを使用して結果をフィルタできます。
- インスタンス セレクタ。クラスタ内のプライマリ インスタンスまたは読み取りプール インスタンスを選択できます。デフォルトでは、プライマリ インスタンスが選択されています。表示された詳細では、接続しているすべての読み取りプール インスタンスとそのノードについて集計されています。
- データベース。特定のデータベースまたはすべてのデータベースのクエリ負荷をフィルタリングします。
- ユーザー。特定のユーザー アカウントからのクエリ負荷をフィルタリングします。
- クライアント アドレス。特定の IP アドレスからのクエリ負荷をフィルタリングします。
- 期間。時間、日、週、カスタム範囲などの期間でクエリ負荷をフィルタリングします。
クエリ分析情報の構成を編集する
クエリ分析情報は、AlloyDB インスタンスでデフォルトで有効になっています。デフォルトのクエリ分析情報構成を編集できます。
AlloyDB インスタンスのクエリ分析情報構成を編集する手順は次のとおりです。
コンソール
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列でクラスタをクリックします。
左側のナビゲーション パネルで [Query Insights] をクリックします。
[Query Insights] リストから [プライマリ] または [読み取りプール] を選択し、[編集] をクリックします。
[Query Insights] フィールドを編集します。
AlloyDB が分析するクエリの長さのデフォルト上限(1,024 バイト)を変更するには、[クエリの長さ] フィールドに 256~4,500 の数値を入力します。
このフィールドを編集すると、インスタンスが再起動します。
注: クエリ長の上限を引き上げると、必要なメモリが増えます。
Query Insights の機能セットをカスタマイズするには、次のオプションを調整します。
クエリプランのサンプリング: このチェックボックスをオンにすると、クエリのサンプルを完了するために使用されるオペレーションを可視化できます。サンプリング レートは、AlloyDB がノードごとにインスタンスで 1 分間にサンプリングできるクエリの最大数を決定します。
[最大サンプリング レート] フィールドに 1~20 の数値を入力します。デフォルトでは、サンプリング レートは 5 に設定されています。サンプリングを無効にするには、[クエリプランのサンプリング] チェックボックスをオフにします。
クライアント IP アドレスを保存する: このチェックボックスをオンにすると、クエリの送信元を確認し、その情報をグループ化して指標を実行できます。
アプリケーション タグを保存: このチェックボックスをオンにすると、リクエストを行っているタグ付けされたアプリケーションを確認し、その情報をグループ化して指標を実行できます。アプリケーション タグの詳細については、仕様をご覧ください。
[インスタンスを更新] をクリックします。
gcloud
Google Cloud CLI コマンドを使用して AlloyDB インスタンスのクエリ分析情報を有効にするには、次の操作を行います。
- Google Cloud CLI をインストールします。
- gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init
ローカルシェルを使用している場合は、ユーザー アカウントのローカル認証情報を作成します。
gcloud auth application-default login
Cloud Shell を使用している場合は、この操作を行う必要はありません。
詳細については、ローカル開発環境の認証を設定するをご覧ください。
次に例を示します。
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-address次のように置き換えます。
INSTANCE: 更新するインスタンスの IDCLUSTER: インスタンスのクラスタの IDPROJECT: クラスタのプロジェクトの IDREGION: クラスタのリージョン(us-central1など)QUERY_LENGTH: クエリの長さ(256~4,500)QUERY_PLANS: 1 分あたりに構成するクエリプランの数
また、次のオプション フラグを 1 つ以上使用します。
--insights-config-query-string-length: デフォルトのクエリ長の上限を 256~4,500 バイトに設定します。デフォルトのクエリ長は 1,024 バイトです。分析クエリの場合はより長いほうが便利ですが、必要なメモリ量が増えます。クエリ長を変更するには、インスタンスを再起動する必要があります。長さの上限を超えるクエリにもタグを追加できます。--insights-config-query-plans-per-minute: インスタンス上のすべてのデータベースで、実行されるクエリプランのサンプルがデフォルトで 1 分間に最大 5 回キャプチャされます。この値を 1~20 の範囲で変更します。サンプリングを無効にするには、「0」と入力します。サンプルレートを上げると、通常よりもデータポイントの数が増えますが、パフォーマンスのオーバーヘッドが増加する可能性があります。--insights-config-record-client-address: クエリの送信元であるクライアント IP アドレスを保存します。これにより、そのデータをグループ化して、そのデータに対して指標を実行できます。クエリは複数のホストから送信されます。クライアント IP アドレスからのクエリのグラフを確認すると、問題の原因を特定しやすくなります。クライアント IP アドレスを保存しない場合は、--no-insights-config-record-client-addressを使用します。--insights-config-record-application-tags: アプリケーション タグを保存します。このタグは、リクエストを行っている API とモデル ビュー コントローラ(MVC)のルート決定や、指標を実行するためのデータのグループ化に役立ちます。このオプションでは、特定のタグセットを使用してクエリにコメントする必要があります。アプリケーション タグを保存しない場合は、--no-insights-config-record-application-tagsを使用します。
Terraform
Terraform を使用してクエリ分析情報を構成するには、google_alloydb_instance リソースを使用します。
次に例を示します。
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
次のように置き換えます。
QUERY_STRING_LENGTH_VALUE: クエリ文字列の長さ。デフォルト値は1024です。256~4,500 の整数を指定できます。RECORD_APPLICATION_TAG_VALUE: インスタンスのアプリケーション タグを記録します。デフォルト値はtrueです。RECORD_CLIENT_ADDRESS_VALUE: インスタンスのクライアント アドレスを記録します。デフォルト値はtrueです。QUERY_PLANS_PER_MINUTE_VALUE: すべてのクエリを合計した 1 分間に Insights によってキャプチャされたクエリ実行プランの数。デフォルト値は5です。0~20 の整数を指定できます。Terraform 構成を適用または削除する方法については、基本的な Terraform コマンドをご覧ください。
クエリ分析情報の構成が追加されたサンプル インスタンス構成は次のようになります。
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
この例では、AlloyDB インスタンスでオブザーバビリティ設定を構成します。この呼び出しのパラメータの完全なリストについては、メソッド: projects.locations.clusters.instances.patch をご覧ください。
クエリ分析情報の設定を構成するには、必要に応じてオプション フィールドを変更します。この呼び出しのフィールドの一覧については、QueryInsightsInstanceConfig をご覧ください。
リクエストのデータを使用する前に、次のように置き換えます。
CLUSTER_ID: 作成するクラスタの ID。先頭は英小文字にします。英小文字、数字、ハイフンを使用できます。PROJECT_ID: クラスタを配置するプロジェクトの ID。LOCATION_ID: クラスタのリージョンの ID。INSTANCE_ID: 作成するプライマリ インスタンスの名前。
インスタンス構成を変更するには、次の PATCH リクエストを使用します。
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
すべてのオブザーバビリティ フィールドを構成するリクエストの JSON 本文は次のようになります。
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
クエリのパフォーマンスを向上させる
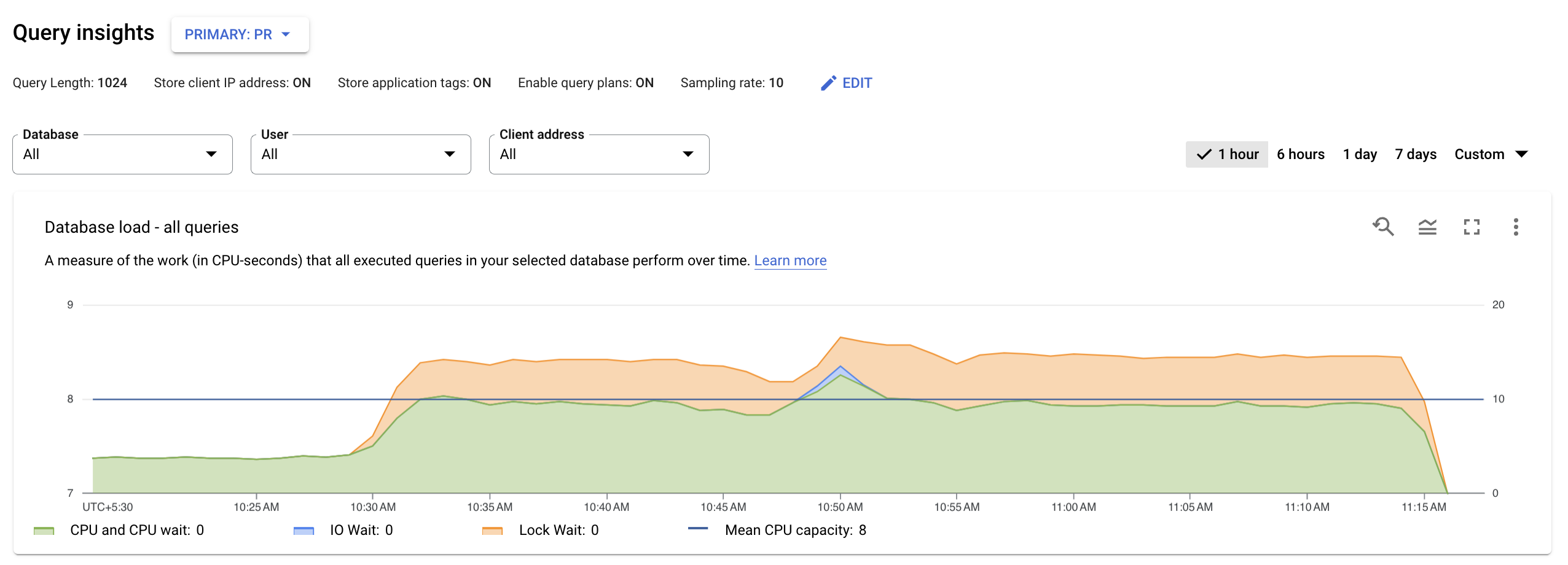
Query Insights では、AlloyDB クエリのトラブルシューティングを行い、パフォーマンスの問題を特定できます。クエリ分析情報ダッシュボードには、選択された要素に基づいて、クエリ負荷が表示されます。クエリ負荷は、選択された期間におけるインスタンス内のすべてのクエリの合計作業量の測定値です。
Query Insights では、クエリのパフォーマンスの問題を検出して分析できます。Query Insights を使用してクエリのトラブルシューティングを行う手順は次のとおりです。
すべてのクエリのデータベース負荷を表示する
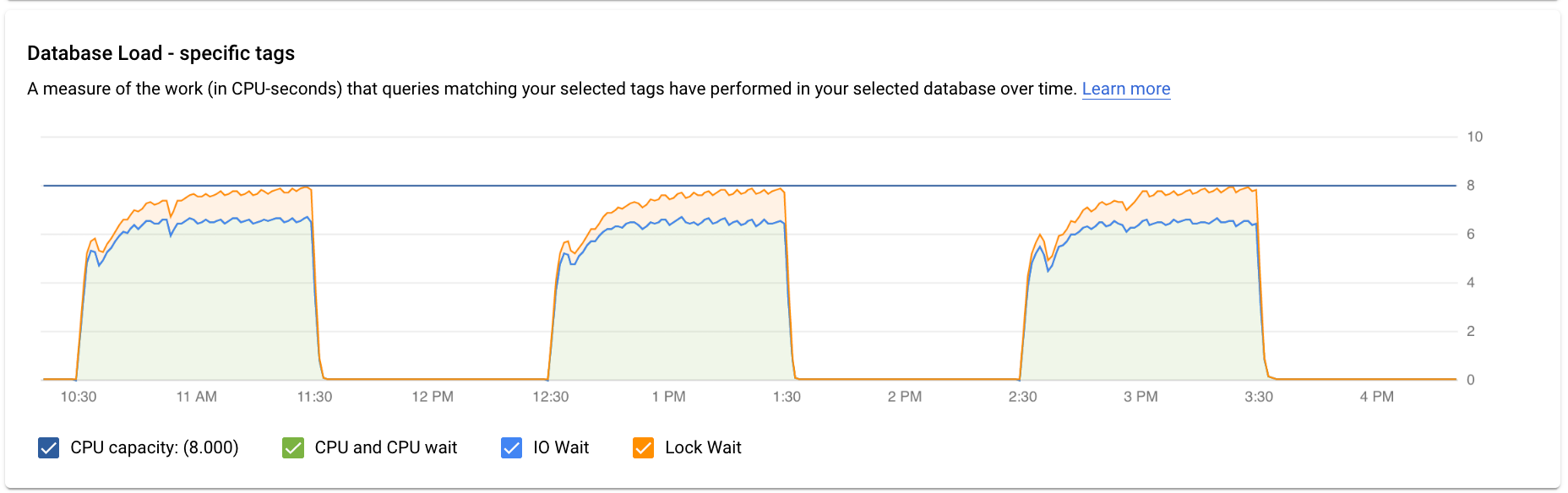
トップレベルのクエリ分析情報ダッシュボードには、フィルタされたデータを使用して [データベースの負荷 - すべての上位クエリ] グラフが表示されます。データベースのクエリ負荷は、選択したデータベースで実行されたクエリの作業量の経時的な測定結果(CPU 秒単位)です。実行中の各クエリは、CPU リソース、IO リソース、またはロックリソースを使用または待機しています。データベースのクエリ負荷は、実時間に対する、指定の時間枠内で完了したすべてのクエリで要した時間の比率です。
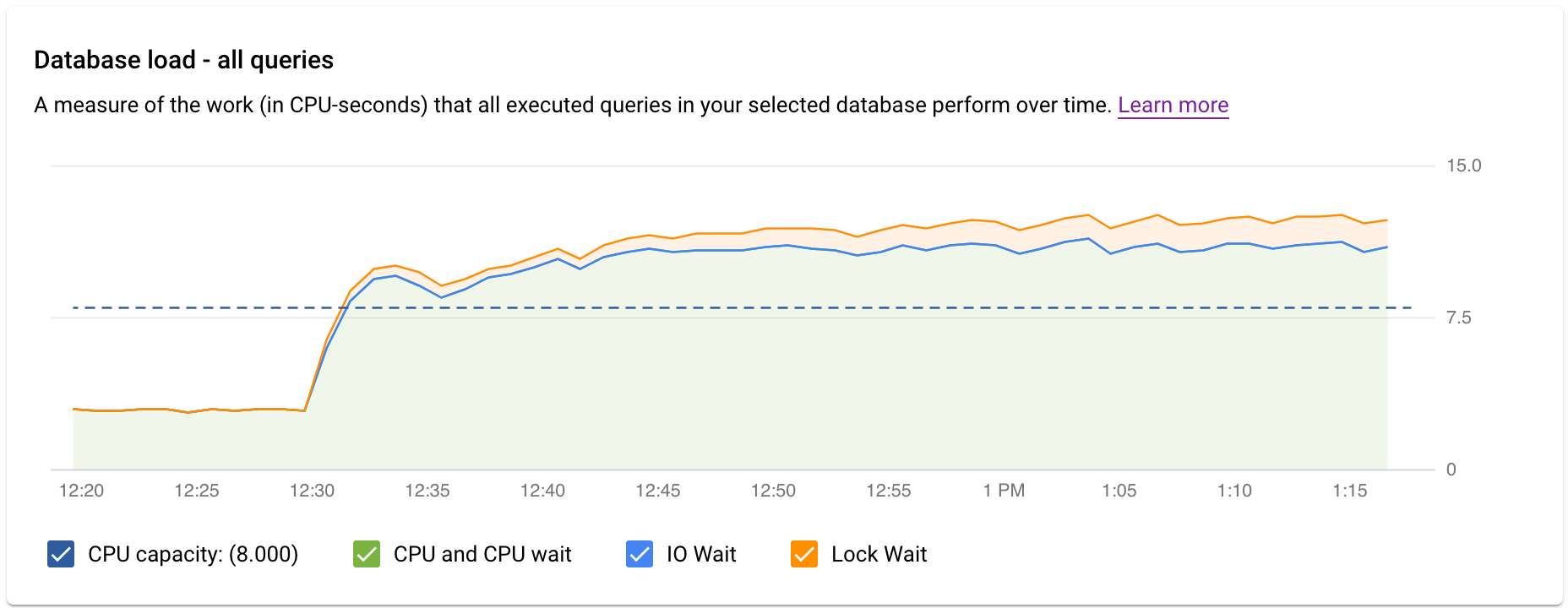
グラフの色付きの線で、クエリ負荷を 4 つのカテゴリに分けて表示します。
- CPU 容量: インスタンスで利用可能な CPU の数。
CPU と CPU 待機: 実時間に対する、アクティブな状態のクエリで要した時間の比率です。IO 待機とロック待機は、アクティブ状態のクエリをブロックしません。この指標は、クエリが CPU を使用している可能性があることを示します。また、他のプロセスが CPU を使用しているときに Linux スケジューラがクエリを実行しているサーバー プロセスをスケジューリングするのをクエリが待機している可能性もあります。
注: CPU 負荷では、ランタイムと、Linux スケジューラが実行中のサーバー プロセスをスケジューリングするのを待機する時間の両方が考慮されます。その結果、CPU 負荷が最大コアラインを超える可能性があります。
IO 待機: 実時間に対する、IO を待機していたクエリで要した時間の比率です。IO 待機には、読み取り IO 待機と書き込み IO 待機が含まれます。PostgreSQL のイベント テーブルをご覧ください。IO 待機に関する情報の内訳が必要な場合は、Cloud Monitoring で確認できます。詳細については、指標グラフをご覧ください。
ロック待機: 実時間に対する、ロックを待機していたクエリで要した時間の比率です。通常のロック待機の他に、LwLock 待機と BufferPin ロック待機が含まれます。ロック待機に関する情報の内訳が必要な場合は、Cloud Monitoring で確認できます。詳細については、指標グラフをご覧ください。
次に、グラフを確認し、フィルタのオプションを使って次の質問に答えます。
- クエリ負荷は高いですか?グラフは時間の経過にともなって増加または減少していますか?負荷が高くない場合は、クエリに問題はありません。
- 高い負荷がどのくらい続いていますか?高いのは今だけですか?それとも、長い間、高いですか?範囲の選択を使用して、さまざまな期間を選択して、問題が発生した期間を探します。あるいは、クエリ負荷の急増が観測される時間枠を拡大表示できます。縮小表示して最大 1 週間のタイムラインを表示することもできます。
- 高い負荷の原因は何ですか?CPU 容量、CPU と CPU 待機、ロック待機、IO 待機を確認するオプションを選択できます。これらの各オプションのグラフの色は異なるため、どこで最も負荷が高くなっているかを確認できます。グラフの濃い青色の線は、システムの最大 CPU 容量を示しています。これにより、クエリ負荷をシステムの最大 CPU 容量と比較できます。この比較を行うことで、インスタンスの CPU リソースが不足しているかどうかを把握できます。
- どのデータベースで負荷が発生していますか?[データベース] プルダウン メニューからデータベースを選択して、負荷が最も高いデータベースを特定します。
- 特定のユーザーまたは IP アドレスが高負荷の原因となっていますか?プルダウン メニューからユーザーとアドレスを選択して、どれが高負荷の原因となっているかを比較できます。
データベース負荷のフィルタリング
[クエリとタグ] セクションでは、選択したクエリまたは SQL クエリタグのクエリ負荷をフィルタまたは並べ替えることができます。
クエリでフィルタリングする
[クエリ] テーブルでは、クエリ負荷が最も大きいクエリの概要を確認できます。このテーブルには、クエリ分析情報ダッシュボードで選択された時間枠とオプションに対応する、正規化されたすべてのクエリが表示されます。
デフォルトでは、テーブルは選択した期間内の合計実行時間でクエリを並べ替えます。
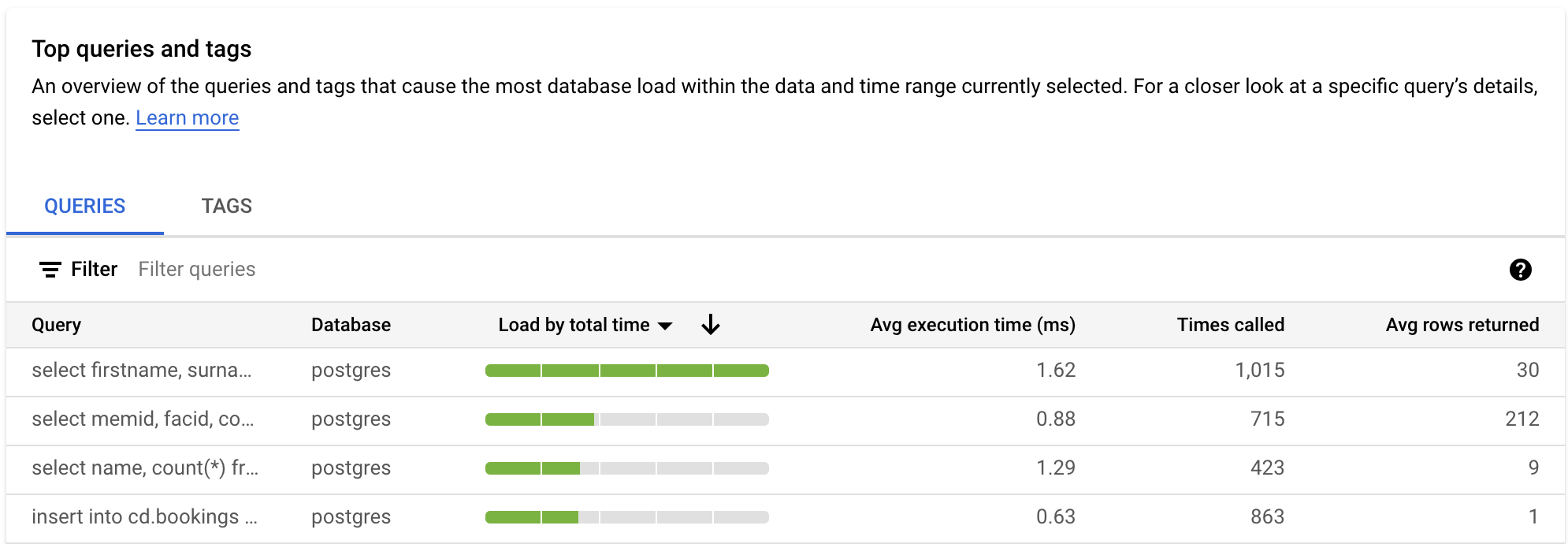
テーブルをフィルタするには、[クエリのフィルタリング] からプロパティを選択します。テーブルを並べ替えるには、列見出しを選択します。テーブルには以下のプロパティが表示されます。
クエリ文字列。正規化されたクエリ文字列。クエリ分析情報では、デフォルトでクエリ文字列のうち 1,024 文字のみが表示されます。
UTILITY COMMANDというラベルの付いたクエリには通常、BEGIN、COMMIT、EXPLAINコマンド、またはラッパー コマンドが含まれます。データベース。クエリが実行されたデータベース。
負荷(合計実行時間別) / 負荷(CPU 別) / 負荷(IO 待機別) / 負荷(ロック待機別)。これらのオプションにより、特定のクエリをフィルタリングして、各オプションの最大負荷を見つけることができます。
平均実行時間(ミリ秒)。すべてのサブタスクがすべての並列ワーカーでクエリを完了するためにかかる合計時間。詳細については、平均実行時間と継続時間をご覧ください。
呼び出された回数。アプリケーションによってクエリが呼び出された回数。
取得した平均行。クエリに対して取得された行数の平均。
クエリ分析情報は正規化されたクエリを表示します。つまり、文字定数は $1、$2 などに置換されます。例:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
この定数値は無視されるため、クエリ分析情報は類似したクエリを集計し、定数で表示される可能性のある PII 情報を削除できます。
クエリタグでフィルタリングする
アプリケーションのトラブルシューティングを行うには、最初に SQL クエリにタグを追加する必要があります。
クエリ分析情報は、アプリケーション中心のモニタリングを提供して、ORM を使用して構築されたアプリケーションのパフォーマンスの問題を診断できるようにします。
アプリケーション スタック全体の担当者である場合、Query Insights で、アプリケーションの視点からクエリをモニタリングできます。クエリのタグ付けは、ビジネス ロジック、マイクロサービス、他のコンストラクトの使用など、より高レベルなコンストラクトで問題を見つけるために役立ちます。たとえば、支払いタグ、在庫タグ、ビジネス分析タグ、出荷タグなどを使用して、ビジネス ロジックでクエリにタグを付けることができます。このようにすると、さまざまなタイプのビジネス ロジックに作成されるクエリ負荷を特定できます。たとえば、午後 1 時のビジネス分析タグの急上昇など、予期しないイベントが発生するかもしれません。あるいは、前週に決済サービス トレンドの異常な増加が確認されるかもしれません。
クエリ負荷タグは、選択したタグのクエリ負荷の内訳の時間変化を示します。
タグのデータベース負荷を計算するために、クエリ分析情報は選択したタグを使用するすべてのクエリにかかる時間を使用します。クエリ分析情報は、実時間を使用して 1 分間隔で完了時間を計算します。
クエリ分析情報ダッシュボードで、[タグ] を選択して [タグ] テーブルを表示します。[タグ] テーブルは、合計負荷を合計時間で割った値でタグを並べ替えます。

テーブルを並べ替えるには、[クエリのフィルタリング] からプロパティを選択するか、列見出しをクリックします。テーブルには以下のプロパティが表示されます。
- アクション、コントローラ、フレームワーク、ルート、アプリケーション、DB ドライバ。クエリに追加したプロパティは、列として表示されます。タグでフィルタリングする場合は、これらのプロパティのうち少なくとも 1 つを追加する必要があります。
- 負荷(合計実行時間別) / 負荷(CPU 別) / 負荷(IO 待機別) / 負荷(ロック待機別)。これらのオプションにより、特定のクエリをフィルタリングして、各オプションの最大負荷を見つけることができます。
- 平均実行時間(ミリ秒)。すべてのサブタスクがすべての並列ワーカーでクエリを完了するためにかかる合計時間。詳細については、平均実行時間と継続時間をご覧ください。
- 呼び出された回数。アプリケーションによってクエリが呼び出された回数。
- 取得した平均行。クエリに対して取得された行数の平均。
- データベース。クエリが実行されたデータベース。
特定のクエリまたはタグの調査
クエリまたはタグが問題の根本原因であるかどうかを確認するには、[クエリ] タブまたは [タグ] タブで次の操作を行います。
- [負荷(合計実行時間別)] ヘッダーをクリックして、リストを降順で並べ替えます。
- 負荷が最も高く、他のクエリより時間がかかっているクエリまたはタグをクリックします。
選択したクエリまたはタグの詳細を示すダッシュボードが開きます。
クエリを選択すると、選択したクエリの概要が表示されます。

タグを選択した場合は、選択したタグの概要が表示されます。
特定のクエリまたはタグの負荷を調べる
[データベースの負荷 - 特定のクエリ] グラフは、選択した正規化クエリが選択したクエリで時間の経過に伴って行った作業量(CPU 秒)の測定結果を示します。実時間の 1 分間隔で完了した正規化クエリで要した時間を使用して、負荷を計算します。テーブルの上部には、集計と PII の理由からリテラルが削除された状態で、正規化されたクエリの最初の 1,024 文字が表示されます。全クエリのグラフと同様に、データベース、ユーザー、クライアント アドレスで、特定のクエリの負荷をフィルタリングできます。クエリ負荷は、CPU 容量、CPU と CPU 待機、IO 待機、ロック待機に分割されます。
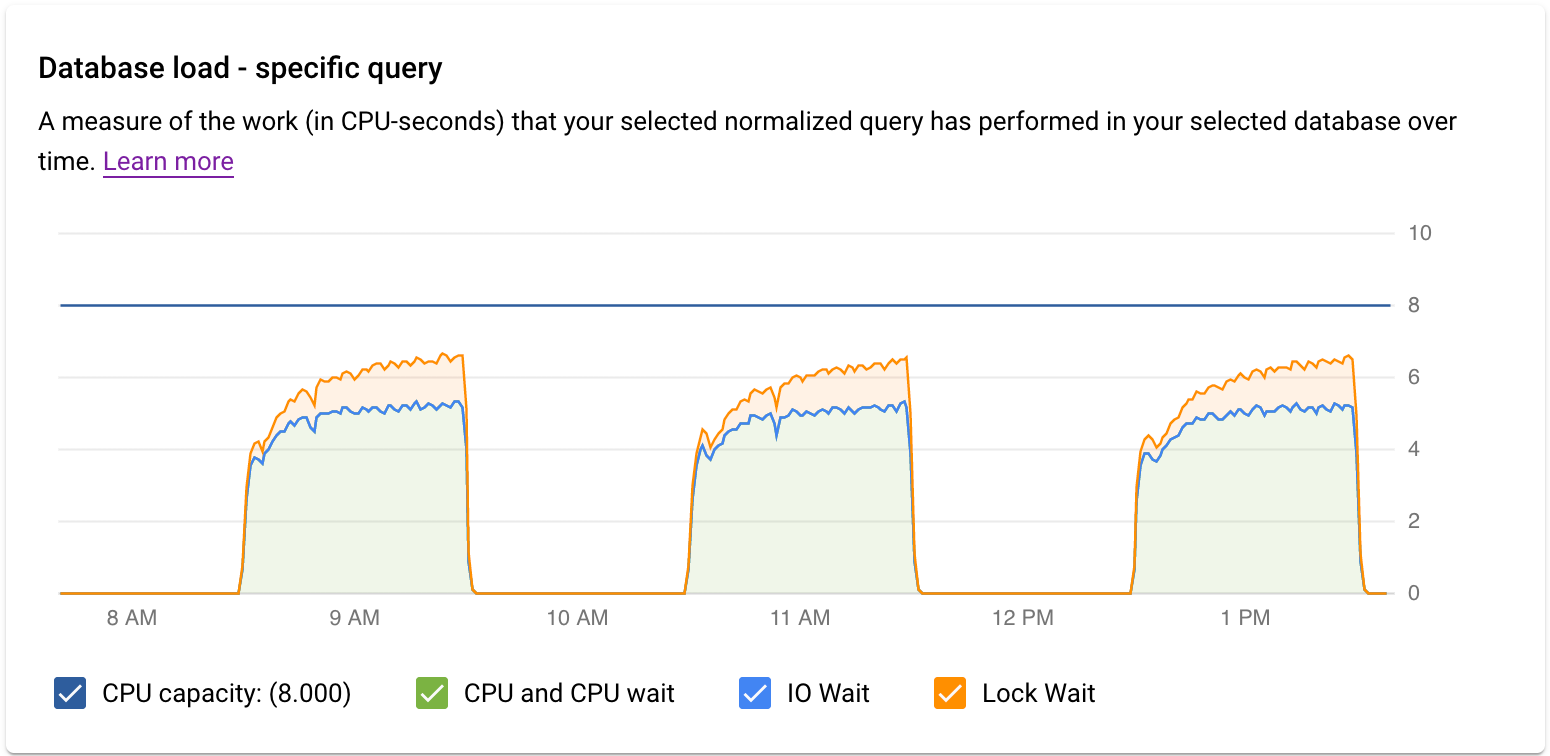
[データベースの負荷 - 特定のタグ] グラフは、選択したタグに一致するクエリが選択したデータベースで行った作業量(CPU 秒)の測定結果を時系列で示します。全クエリのグラフと同様に、データベース、ユーザー、クライアント アドレスで、特定のタグの負荷をフィルタリングできます。
レイテンシを調べる
クエリまたはタグのレイテンシを調べるには、レイテンシ グラフを使用します。レイテンシとは、正規化されたクエリの実行に要した実時間です。レイテンシ ダッシュボードには、50、95、99 パーセンタイルのレイテンシが表示されるため、外れ値の挙動を確認できます。
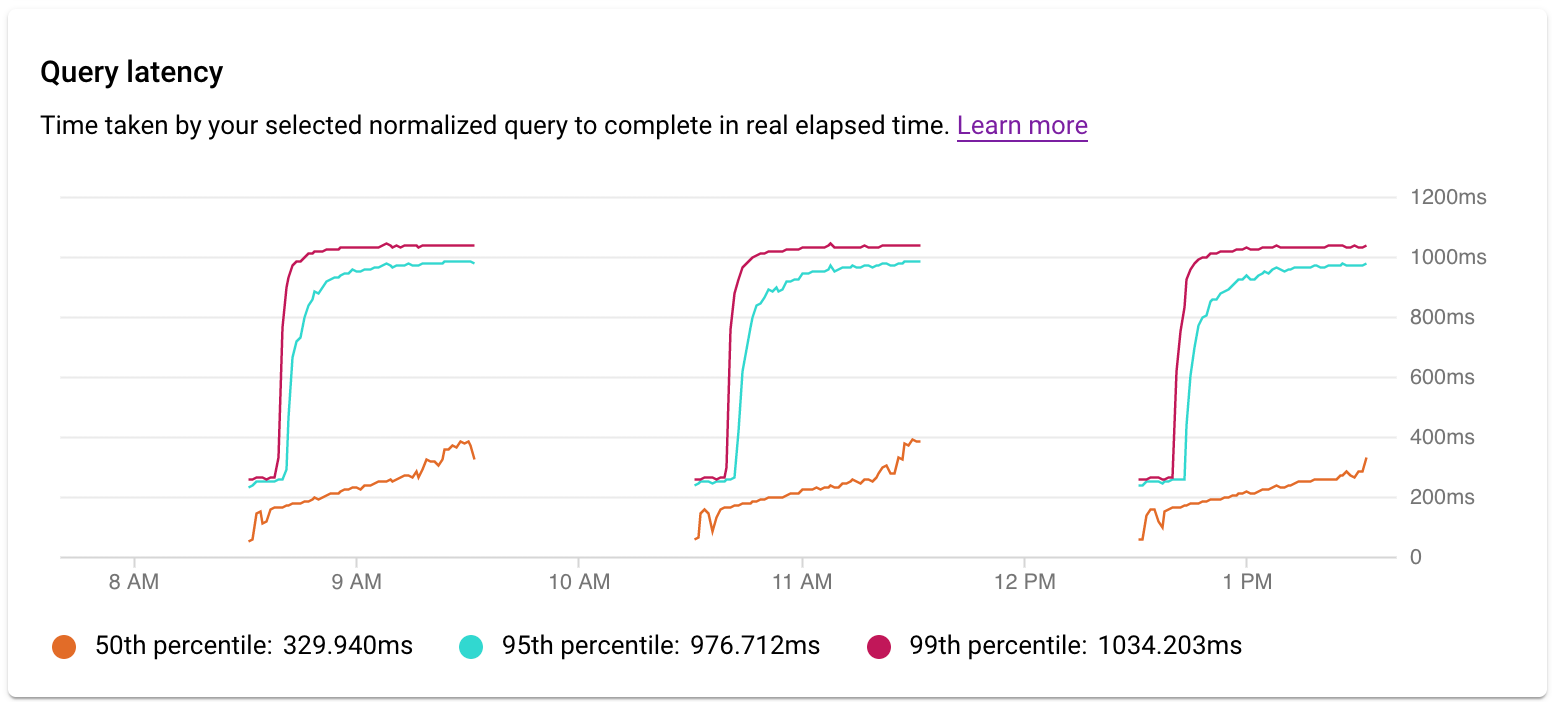
並列クエリでは、クエリの一部を実行するのに複数のコアが使用されるためクエリ負荷が高くなる可能性がありますが、レイテンシは実時間で測定されます。
以下のことを確認して、問題を絞り込んでみてください。
- 高い負荷の原因は何ですか?CPU 容量、CPU と CPU 待機、ロック待機、IO 待機を確認するオプションを選択します。
- 高い負荷がどのくらい続いていますか?高いのは今だけですか?それとも、長い間、高いですか?期間を変更して、負荷が悪化しはじめた日時を見つけます。
- レイテンシの急増はありますか?時間枠を変更して、正規化されたクエリの履歴レイテンシを調べることができます。
負荷が最も高い領域と時間が見つかったら、さらにドリルダウンできます。
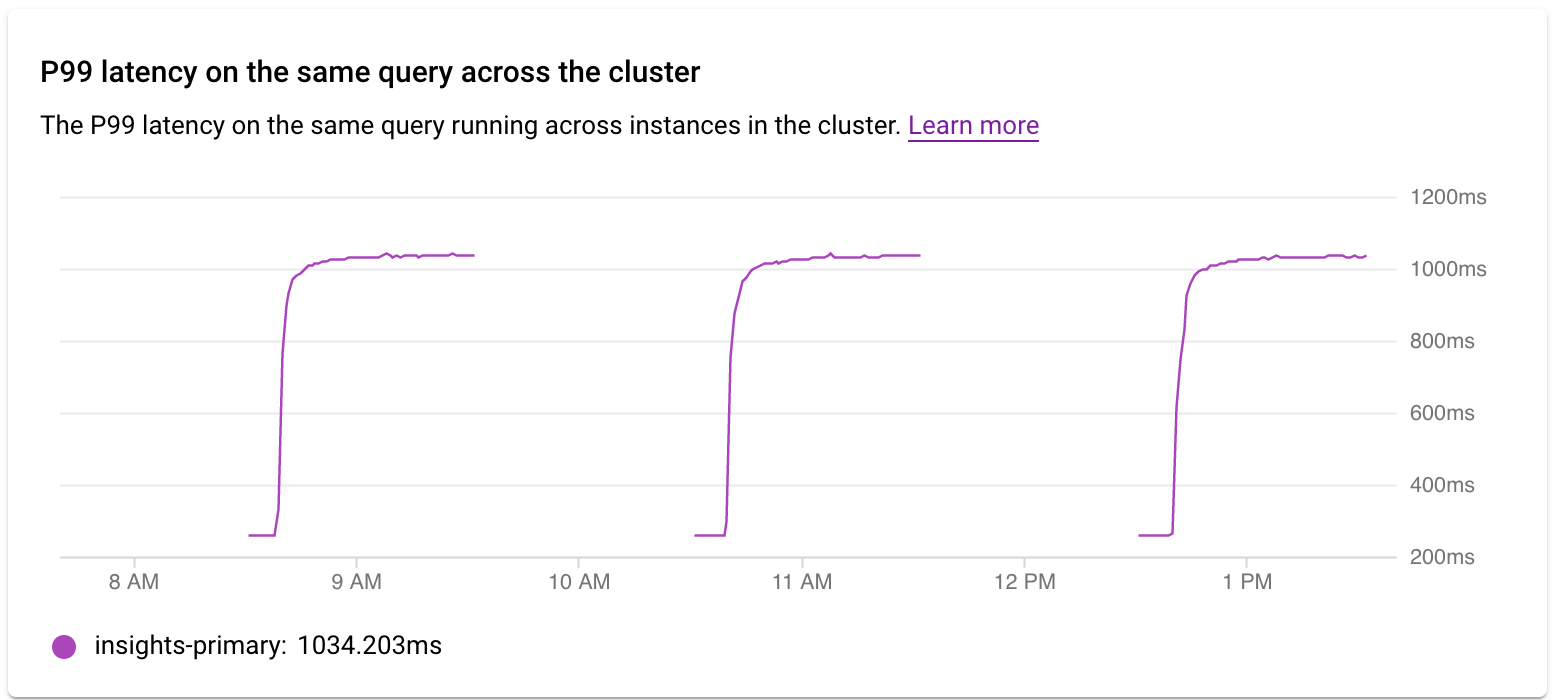
クラスタ全体のレイテンシを調べる
クラスタ内のインスタンスにわたるクエリまたはタグの P99 レイテンシを調べるには、「クラスタ全体での同じクエリに対する P99 レイテンシ」グラフを使用します。
サンプリングされたクエリプランでのオペレーションの調査
クエリプランは、クエリのサンプルを取得し、それを個々のオペレーションに分割します。クエリ内の各オペレーションが説明され、分析されます。[クエリプランのサンプル] グラフには、特定の時間に実行されているすべてのクエリプランと、各プランの実行にかかった時間が表示されます。
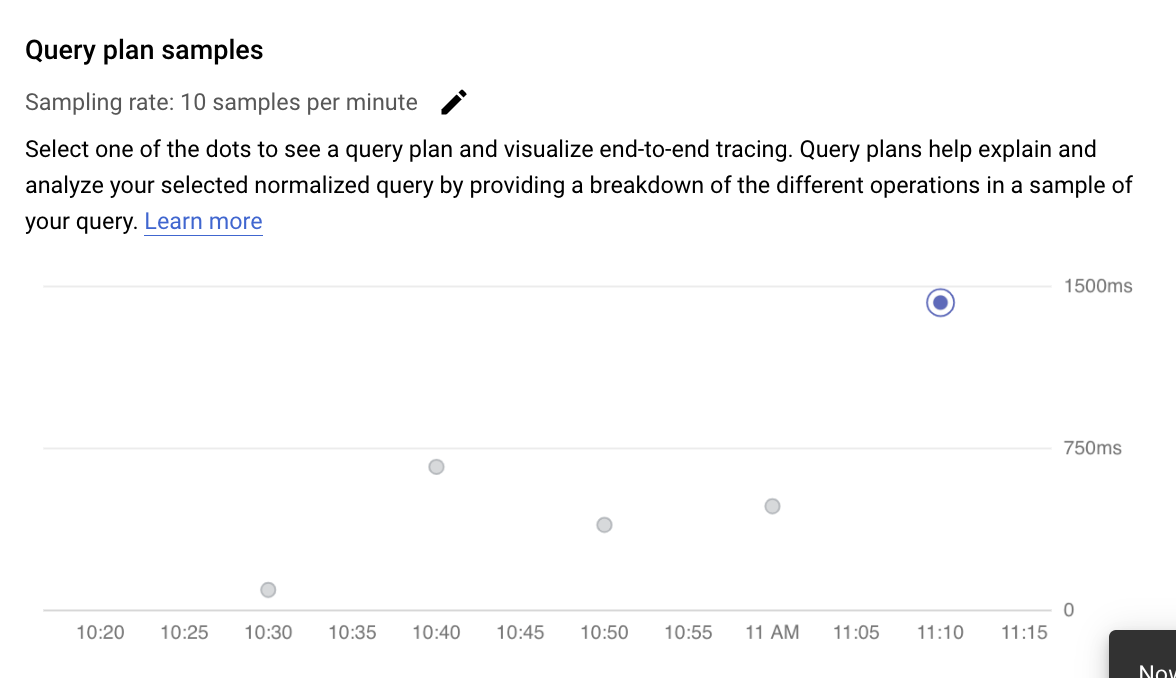
サンプル クエリプランの詳細を表示するには、[クエリプランのサンプル] グラフのドットをクリックします。すべてではありませんが、ほとんどのクエリで、実行されたサンプル クエリプランが表示されます。開かれた詳細は、クエリプランのすべてのオペレーションのモデルを示しています。オペレーションごとに、レイテンシ、返される行、そのオペレーションの費用が表示されます。オペレーションを選択すると、共有ヒットブロック、スキーマのタイプ、実際のループ、プラン行などの詳細を確認できます。
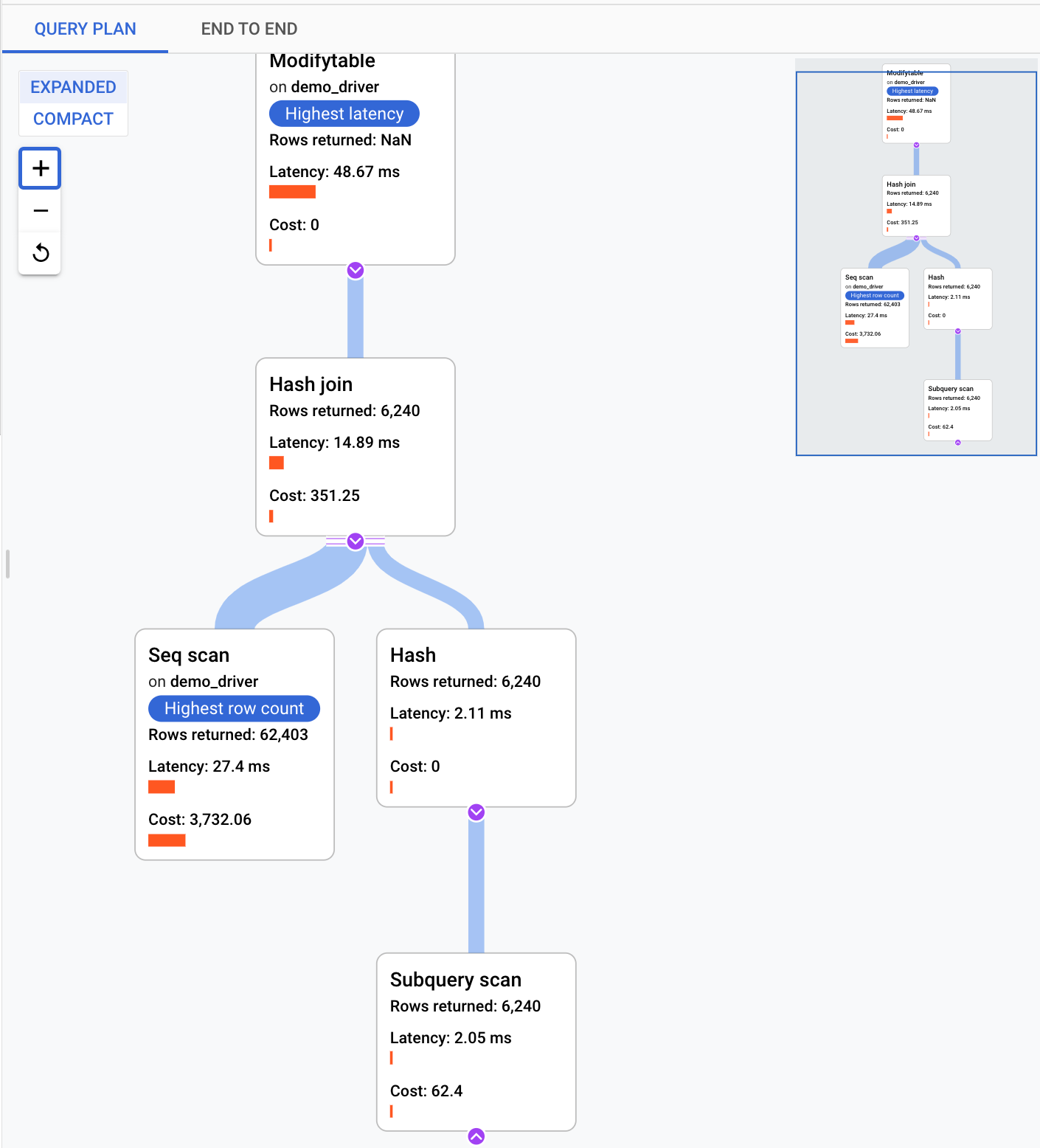
以下の質問を確認して、問題を絞り込んでみてください。
- リソースを消費しているのは何ですか?
- 他のクエリとどのように関係していますか?
- 消費は時間とともに変化していますか?
サンプルクエリによって生成されたトレースを調べる
サンプル クエリプランを確認する方法だけでなく、Query Insights を使用して、サンプルクエリのコンテキスト内のエンドツーエンドのアプリケーション トレースを確認する方法もあります。このトレースでは、特定のリクエストのデータベース アクティビティを表示して、問題のあるクエリの送信元を特定できます。また、リクエスト中にアプリケーションが Cloud Logging に送信するログエントリがトレースにリンクされるため、調査に役立ちます。
コンテキスト内のトレースを確認するには、次の操作を行います。
[クエリの例] ペインで、[End-to-end Trace] タブをクリックします。このタブには、クエリによって生成されたトレースのスパン(個々のオペレーションのレコード)の詳細を示すガントチャートが表示されます。
属性やメタデータといった各スパンの詳細を確認するには、スパンをクリックします。
トレースは [Trace エクスプローラ] ページでも確認できます。表示するには、[Cloud Trace で表示] をクリックします。[Trace エクスプローラ] ページを使用してトレースデータを調査する方法の詳細については、トレースを検索して調査するをご覧ください。
SQL クエリにタグを追加する
SQL クエリにタグを追加すると、アプリケーションのトラブルシューティングが簡単になります。SQL クエリにタグを追加するには、sqlcommenter を使用します。このとき、オブジェクト リレーショナル マッピング(ORM)で自動的に追加することも、手動で追加することもできます。
ORM での sqlcommenter の使用
SQL クエリを直接記述する代わりに、ORM を使用すると、パフォーマンスの問題を引き起こすアプリケーション コードを見つけられないことがあります。また、アプリケーション コードによるクエリのパフォーマンスへの影響の分析に支障をきたすことがあります。この問題に対処するため、クエリ分析情報には ORM 計測ライブラリである sqlcommenter というオープンソース ライブラリが用意されています。このライブラリは、ORM を使用するデベロッパーと管理者がパフォーマンスの問題を引き起こしているアプリケーション コードを検出するのに役立ちます。
ORM と sqlcommenter を組み合わせて使用している場合、タグが自動的に作成されます。カスタムコードの変更やアプリケーションへの追加は必要もありません。
sqlcommenter はアプリケーション サーバーにインストールできます。インストルメンテーション ライブラリを使用すると、MVC フレームワークに関連するアプリケーション情報を、SQL コメントとしてクエリとともにデータベースに伝播できます。データベースはこれらのタグを取得し、正規化されたクエリによって集計される統計とは無関係に、タグによる統計の記録と集計を開始します。クエリ分析情報でタグが表示されるため、クエリ負荷の原因となったアプリケーションを把握できます。この情報により、パフォーマンスの問題を引き起こしているアプリケーション コードを検出できます。
SQL データベース ログの結果を調べると、次のように表示されます。
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
サポートされるタグには、コントローラ名、ルート、フレームワーク、アクションが含まれます。
一連の sqlcommenter の ORM は、さまざまなプログラミング言語でサポートされています。
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
sqlcommenter の詳細と、ORM フレームワークで sqlcommenter を使用する方法については、GitHub の sqlcommenter のドキュメントをご覧ください。
sqlcommenter を使用した手動でのタグの追加
ORM を使用していない場合は、SQL クエリに手動で sqlcommenter タグを追加する必要があります。クエリでは、シリアル化された Key-Value ペアを含むコメントで各 SQL ステートメントを拡張する必要があります。次のキーの少なくとも 1 つを使用します。
action=''controller=''framework=''route=''application=''db driver=''
クエリ分析情報は、他のすべてのキーを無視します。正しい SQL コメント形式については、sqlcommenter のドキュメントをご覧ください。
実行時間と期間
クエリ分析情報には、平均実行時間(ミリ秒)の指標があります。これは、すべての並列ワーカーのすべてのサブタスクがクエリを完了するまでに要した合計時間を報告します。この指標は、CPU オーバーヘッドが最も大きいクエリを見つけて最適化することで、データベースの総リソース使用率を最適化する際に役立ちます。
経過時間を表示するには、psql クライアントで \timing コマンドを実行してクエリの所要時間を測定します。クエリの受信から PostgreSQL サーバーがレスポンスを送信するまでの時間を測定します。この指標は、特定のクエリに時間がかかっている理由を分析し、実行時間を短縮するために最適化が必要かどうかを判断する際に役立ちます。
クエリが単一のタスクによってシングル スレッドで完了した場合、所要時間と平均実行時間は変わりません。
AlloyDB の高度なクエリ分析機能を有効にする
AlloyDB ダッシュボードの高度なクエリ分析機能は、標準のクエリ分析情報ダッシュボードに統合されています。高度な Query Insights 機能を有効にする方法については、高度な Query Insights を使用してクエリのパフォーマンスを向上させるをご覧ください。
次のステップ
- Query Insights について
- AlloyDB の高度なクエリ分析機能を使用してクエリのパフォーマンスを向上させる
- AlloyDB 指標
- SQL Commenter についてのブログ: Sqlcommenter のご紹介: オープンソース ORM の自動計測ライブラリ
- 手法を紹介したブログ投稿: Sqlcommenter を使用してクエリのタグ付けを有効にする