This page describes how to use the query insights dashboard to detect and analyze performance problems. For an overview of this feature, see Query insights overview.
You can use Gemini Cloud Assist to help you monitor and troubleshoot your AlloyDB resources. For more information, see Monitor and troubleshoot with Gemini assistance.
Before you begin
If you or other users need to view the query plan or perform end-to-end tracing, you need specific Identity and Access Management (IAM) permissions to do so. You can create a custom role and add the necessary IAM permissions to it. Then, you can add this role to each user account that uses query insights to troubleshoot an issue. See Create a custom role.
The custom role needs to have the following IAM permission: cloudtrace.traces.get.
Open the query insights dashboard
To open the query insights dashboard, do the following steps:
- From the list of clusters and instances, click an instance.
- Either click Go to Query insights for more in-depth info on queries and performance below the metrics graph on the cluster Overview page or select the Query insights tab in the left navigation panel.
On the subsequent page, you can use the following options to filter the results:
- Instance selector. Lets you select either the primary instance or read pool instances in the cluster. By default, the primary instance is selected. The details shown are aggregated for all connected read pool instances and their nodes.
- Database. Filters query load on a specific database or all databases.
- User. Filters query load from specific user accounts.
- Client address. Filters query load from a specific IP address.
- Time range. Filters query load by time ranges, such as hour, day, week, or a custom range.
Edit the query insights configuration
Query insights are enabled by default on AlloyDB instances. You can edit the default query insights configuration.
To edit the query insights configuration for an AlloyDB instance, follow these steps:
Console
In the Google Cloud console, go to the Clusters page.
Click a cluster in the Resource Name column.
Click Query insights in the left navigation panel.
Select Primary or Read pool from the Query insights list, and then click Edit.
Edit the Query insights fields:
To change the default limit of 1024 bytes on query lengths for AlloyDB to analyze, in the Query lengths field, enter a number from 256 to 4500.
The instance restarts after you edit this field.
Note: Higher query-length limits require more memory.
To customize your query insights feature sets, adjust the following options:
Query plan sampling: Select this checkbox to visualize the operations used to complete a sample of a query. The sampling rate determines the maximum number of queries that AlloyDB can sample per minute for the instance per node.
In the Maximum sampling rate field, enter a number from one to 20. By default, the sampling rate is set to 5. To disable sampling, clear the Query plan sampling checkbox.
Store client IP addresses: Select this checkbox to know from where your queries are originating, and to group that information to run metrics.
Store application tags: Select this checkbox to know which tagged applications are making requests, and to group that information to run metrics. For more information about application tags, see the specification.
Click Update instance.
gcloud
To enable query insights for an AlloyDB instance using Google Cloud CLI commands, do the following:
- Install the Google Cloud CLI.
- To initialize the gcloud CLI, run the following command:
gcloud init
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
For more information, see Set up authentication for a local development environment.
Here's an example:
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-addressReplace the following:
INSTANCE: the ID of the instance to updateCLUSTER: the ID of the instance's clusterPROJECT: the ID of the cluster's projectREGION: the cluster's region—for example,us-central1QUERY_LENGTH: the length of the query that ranges from 256 to 4500QUERY_PLANS: the number of query plans to configure per minute.
Also, use one or more of the following optional flags:
--insights-config-query-string-length: Sets the default query length limit to a specified value from 256 to 4500 bytes. The default query length is 1024 bytes. Higher query lengths are more useful for analytical queries, but they also require more memory. Changing the query length requires you to restart the instance. You can still add tags to queries that exceed the length limit.--insights-config-query-plans-per-minute: By default, a maximum of five executed query plan samples are captured per minute across all databases on the instance. Change this value to a number from 1 to 20. To disable sampling, enter 0. Increasing the sampling rate is likely to give you more data points but might add a performance overhead.--insights-config-record-client-address: Stores the client IP addresses where queries are coming from and helps you group that data to run metrics against it. Queries come from more than one host. Reviewing graphs for queries from client IP addresses can help identify the source of a problem. If you don't want to store client IP addresses, use--no-insights-config-record-client-address.--insights-config-record-application-tags: Stores application tags that help you determine the APIs and model-view-controller (MVC) routes that are making requests and group the data to run metrics against it. This option requires you to comment queries with a specific set of tags. If you don't want to store application tags, use--no-insights-config-record-application-tags.
Terraform
To use Terraform to configure query insights, use the google_alloydb_instance resource.
Here's an example:
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
Replace the following:
QUERY_STRING_LENGTH_VALUE: query string length. The default value is1024. Any integer between 256 and 4500 is valid.RECORD_APPLICATION_TAG_VALUE: record application tag for an instance. The default value istrue.RECORD_CLIENT_ADDRESS_VALUE: record client address for an instance. The default value istrue.QUERY_PLANS_PER_MINUTE_VALUE: the number of query execution plans captured by Insights per minute for all queries combined. The default value is5. Any integer between 0 and 20 is valid.To learn how to apply or remove a Terraform configuration, see Basic Terraform commands.
The sample instance configuration with the added query insights configuration should appear as follows:
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
This example configures observability settings on your AlloyDB instance. For a complete list of parameters for this call, see Method: projects.locations.clusters.instances.patch.
To configure query insights settings, modify optional fields as needed. For a complete list of fields for this call, see QueryInsightsInstanceConfig.
Before you use any of the request data, make the following replacements:
CLUSTER_ID: the ID of the cluster that you create. It must begin with a lowercase letter and can contain lowercase letters, numbers, and hyphens.PROJECT_ID: the ID of the project where you want the cluster placed.LOCATION_ID: the ID of the cluster's region.INSTANCE_ID: the name of the primary instance that you want to create.
To modify your instance configuration, use the following PATCH request:
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
The request JSON body that configures all observability fields looks as follows:
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
Improve query performance
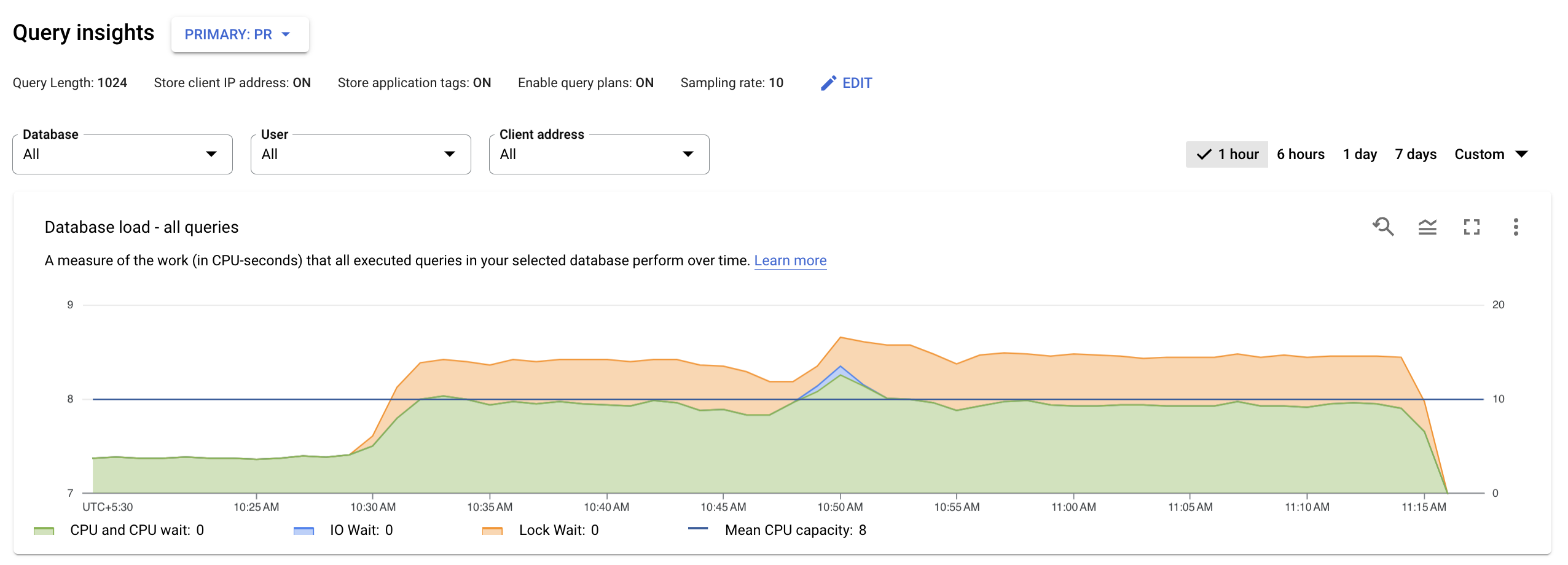
Query insights troubleshoot AlloyDB queries to look for performance issues. The query insights dashboard shows the query load based on factors that you select. Query load is a measurement of the total work for all the queries in the instance in the selected time range.
Query insights help you detect and analyze query performance problems. To troubleshoot queries with query insights, follow these steps:
- View the database load for all queries.
- Identify a problematic query or tag.
- Examine the query or tag to identify issues.
- Examine a trace generated by a sample query.
View the database load for all queries
The top-level query insights dashboard shows the Database load — all top queries graph using filtered data. Database query load is a measure of the work (in CPU seconds) that the executed queries in your selected database perform over time. Each running query is either using or waiting for CPU resources, IO resources, or lock resources. Database query load is the ratio of the amount of time taken by all the queries that are completed in a given time window to the wall clock time.
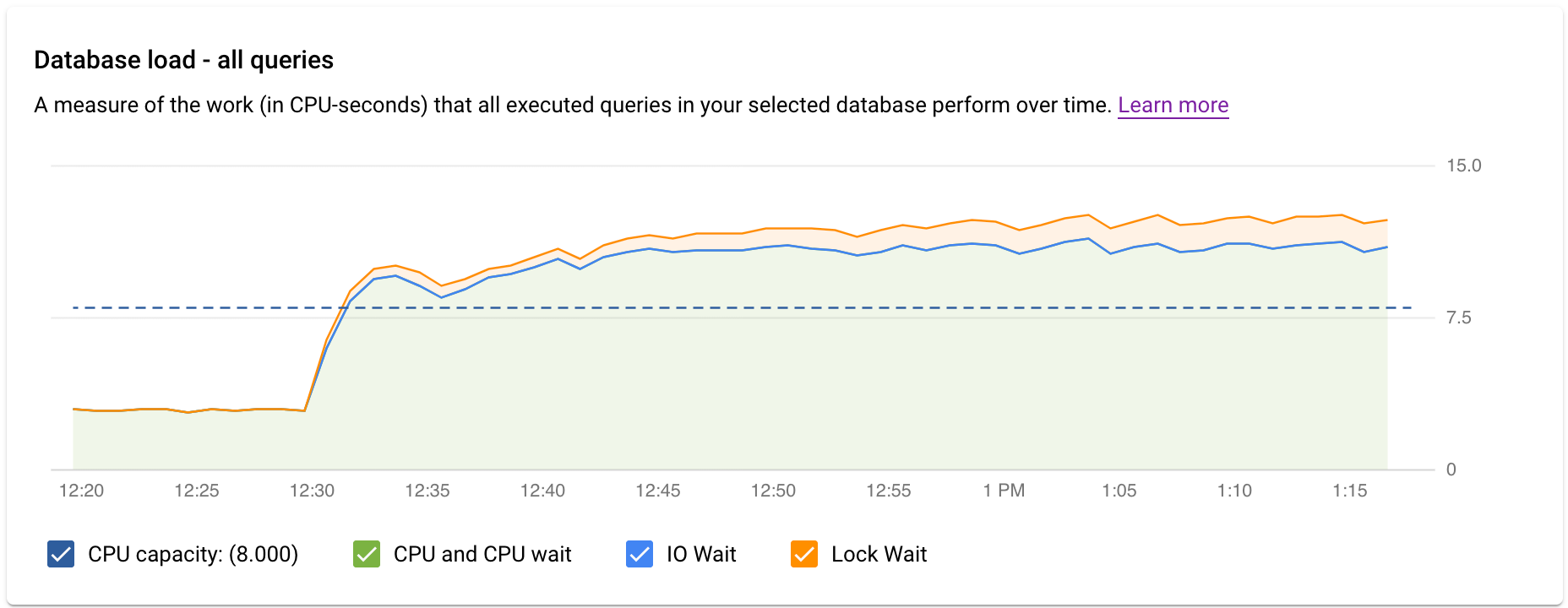
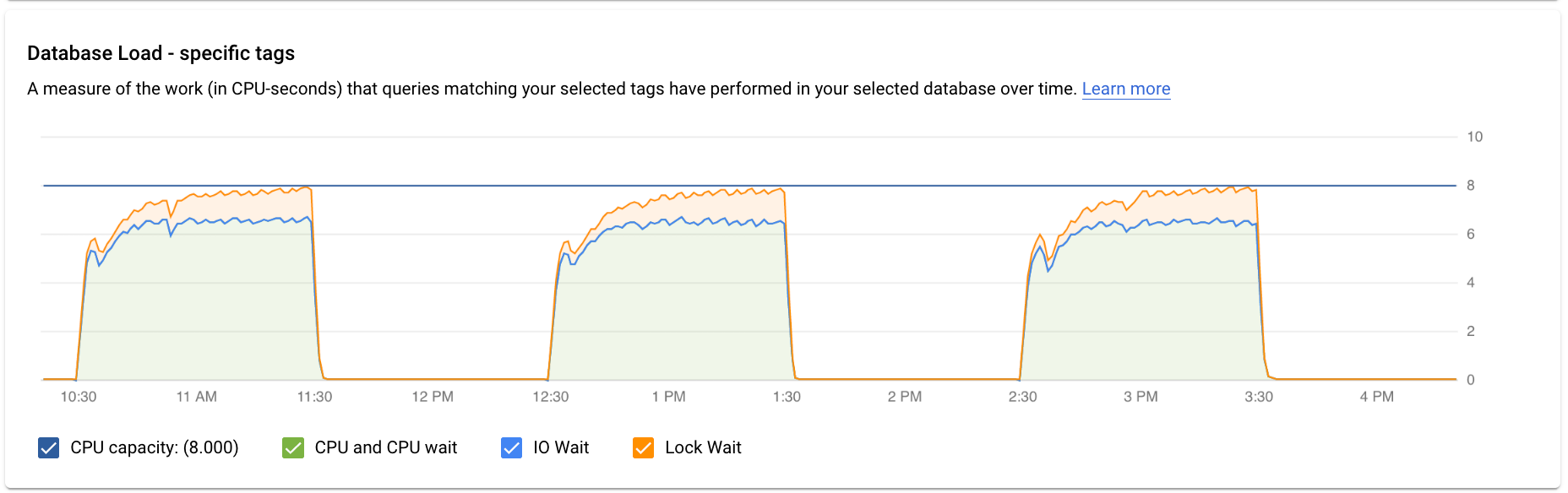
Colored lines in the graph show the query load, split into four categories:
- CPU capacity: The number of CPUs available on the instance.
CPU and CPU Wait: The ratio of the time taken by queries in an active state to wall clock time. IO and Lock waits do not block queries that are in an active state. This metric might mean that the query is either using the CPU or waiting for the Linux scheduler to schedule the server process running the query while other processes are using the CPU.
Note: CPU load accounts for both the runtime and the time waiting for the Linux scheduler to schedule the server process that is running. As a result, the CPU load can go beyond the maximum core line.
IO Wait: The ratio of time taken by queries that are waiting for IO to wall clock time. IO wait includes Read IO Wait and Write IO Wait. See the PostgreSQL event table. If you want a breakdown of information for IO waits, you can see it in Cloud Monitoring. For more information, see metrics charts.
Lock Wait: The ratio of time taken by queries that are waiting for Locks to wall clock time. It includes Lock Waits, LwLock Waits, and Buffer pin Lock waits. If you want a breakdown of information for lock waits, you can see it in Cloud Monitoring. For more information, see metrics charts.
Next, review the graph and use the filtering options to answer these questions:
- Is the query load high? Is the graph spiking or elevated over time? If you don't see a high load, then the problem isn't with your queries.
- How long has the load been high? Is it only high now? Or has it been high for a long time? Use the range selection to select various time periods to find out how long the problem has occurred. Or you can zoom in to view a time window where query load spikes are observed. You can zoom out to view up to one week of the timeline.
- What is causing the high load? You can select options to look at the CPU capacity, CPU and CPU wait, lock wait, or IO wait. The graph for each of these options is a different color so that you can see which one has the highest load. The dark blue line on the graph shows the max CPU capacity of the system. It lets you compare the query load with the max CPU system capacity. This comparison helps you know whether an instance is running out of CPU resources.
- Which database is experiencing the load? Select different databases from the Databases drop-down menu to find the databases with the highest loads.
- Are specific users or IP addresses causing higher loads? Select different users and addresses from the drop-down menus to compare which ones are causing higher loads.
Filter the database load
The Queries and tags sections lets you filter or sort the query load for either a selected query or a SQL query tag.
Filter by queries
The QUERIES table provides an overview of the queries that cause the most query load. The table shows all the normalized queries for the time window and options selected on the query insights dashboard.
By default, the table sorts queries by the total execution time within the time window you selected.
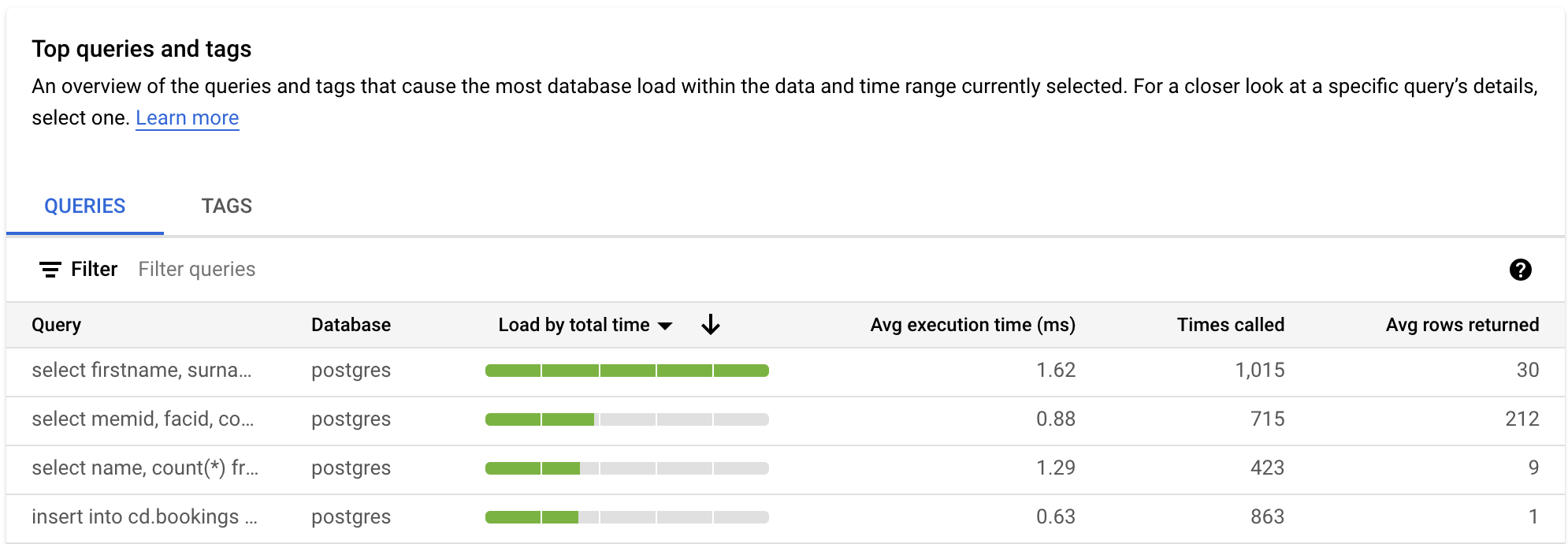
To filter the table, select a property from Filter queries. To sort the table, select a column heading. The table shows the following properties:
Query string. The normalized query string. query insights only shows 1024 characters in the query string by default.
Queries labeled
UTILITY COMMANDusually includeBEGIN,COMMIT, andEXPLAINcommands or wrapper commands.Database. The database that the query was run against.
Load by total time/Load by CPU/Load by IO wait/Load by lock wait. These options let you filter specific queries to find the largest load for each option.
Avg execution time (ms). The total time that all sub-tasks take across all parallel workers to complete the query. For more information, see Average execution time and duration.
Times called. The number of times the query was called by the application.
Avg rows fetched. The average number of rows fetched for the query.
Query insights display normalized queries, that is, $1, $2, and so on replace the literal constant values. For example:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
The constant's value is ignored so that query insights can aggregate similar queries and remove any PII information that the constant might show.
Filter by query tags
To troubleshoot an application, you must first add tags to your SQL queries.
Query insights provide application-centric monitoring to diagnose performance problems for applications built using ORMs.
If you're responsible for the entire application stack, Query insights provide query monitoring from an application view. Query tagging helps you find issues at higher-level constructs, such as using the business logic, a microservice, or some other construct. You might tag queries by the business logic, for example, using the payment, inventory, business analytics, or shipping tags. You can then find the query load that the various types of business logic are created. For example, you might find unexpected events, such as spikes for a business analytics tag at 1 PM. Or you might see unexpected growth for a payment service trending over the previous week.
Query load tags provide a breakdown of the query load of the selected tag over time.
To calculate the Database Load for Tag, query insights use the amount of time taken by every query that uses the tag you select. Query insights calculate the completion time at the minute boundary using wall clock time.
On the query insights dashboard, select TAGS to view the tags table. The TAGS table sorts tags by their total load by total time.

You can sort the table by selecting a property from Filter queries, or by clicking a column heading. The table shows the following properties:
- Action, Controller, Framework, Route, Application, DB Driver. Each property that you added to your queries is shown as a column. At least one of these properties must be added if you want to filter by tags.
- Load by total time/Load by CPU/Load by IO wait/Load by lock wait. These options let you filter specific queries to find the largest load for each option.
- Avg execution time (ms). The total time that all sub-tasks take across all parallel workers to complete the query. For more information, see Average execution time and duration.
- Times called. The number of times the query was called by the application.
- Avg rows fetched. The average number of rows fetched for the query.
- Database. The database that the query was run against.
Examine a specific query or tag
To determine if a query or a tag is the root cause of the problem, do the following from the Queries tab or Tags tab, respectively:
- Click the Load by total time header to sort the list in descending order.
- Click the query or tag that looks like it has the highest load and is taking a longer time than the others.
A dashboard opens showing the details of the selected query or tag.
If you selected a query, an overview of the selected query is shown:

If you selected a tag, an overview of the selected tag is shown.
Examine the load for a specific query or tag
The Database load — specific query graph shows a measure of the work (in CPU seconds) that your selected normalized query has performed in your selected query over time. To calculate load, it uses the amount of time taken by the normalized queries that are completed at the minute boundary to the wall clock time. At the top of the table, the first 1024 characters of the normalized query (where literals are removed for aggregation and PII reasons) are displayed. As with the total queries graph, you can filter the load for a specific query by Database, User, and Client Address. Query load is split into CPU capacity, CPU and CPU Wait, IO Wait, and Lock Wait.
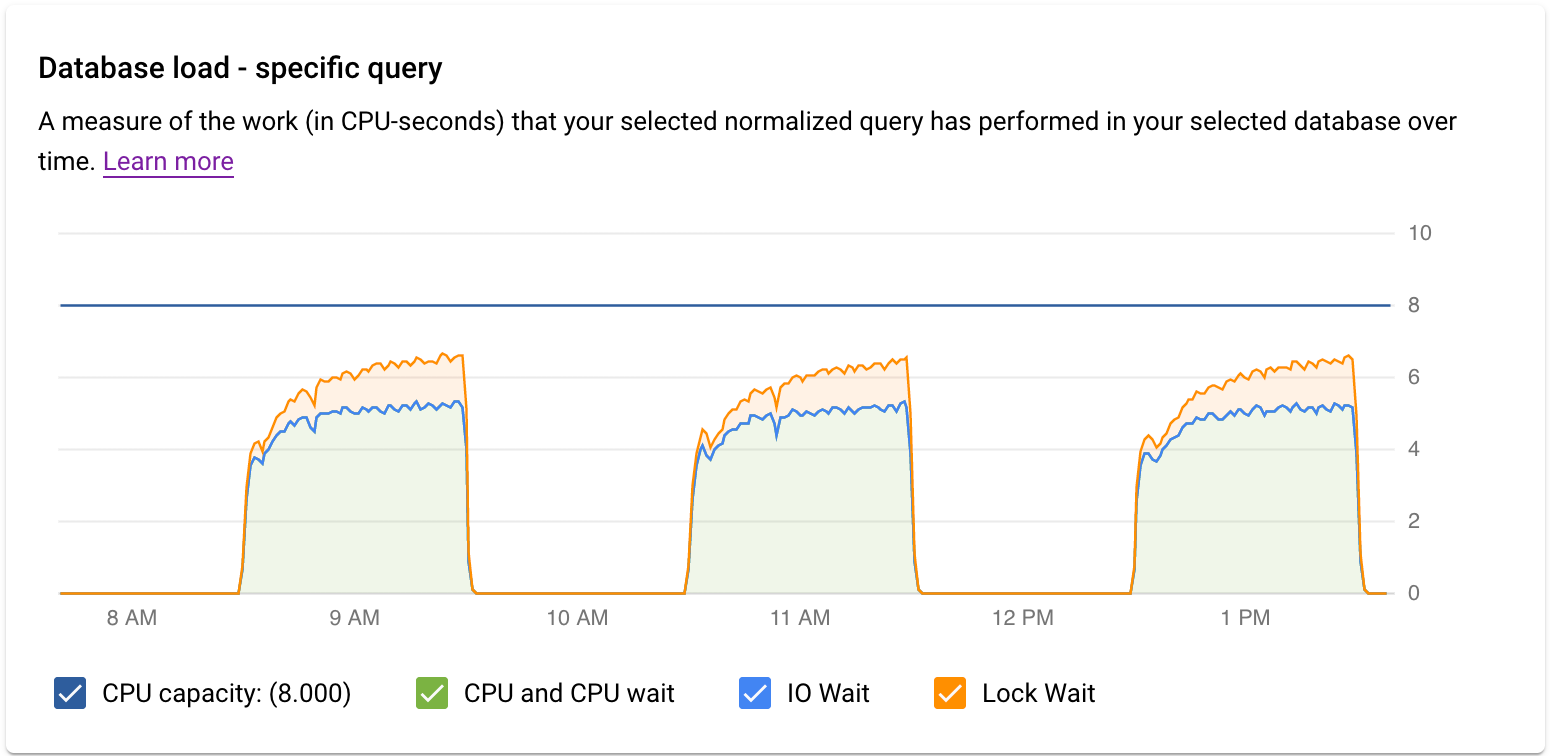
The Database load — specific tags graph shows a measure of the work (in CPU seconds) that queries matching your selected tags have performed in your selected database over time. As with the total queries graph, you can filter the load for a specific tag by Database, User, and Client Address.
Examine the latency
You use the Latency graph to examine latency on the query or tag. Latency is the time taken for the normalized query to complete, in wall clock time. The latency dashboard shows 50th, 95th, and 99th percentile latency to find outlier behaviors.
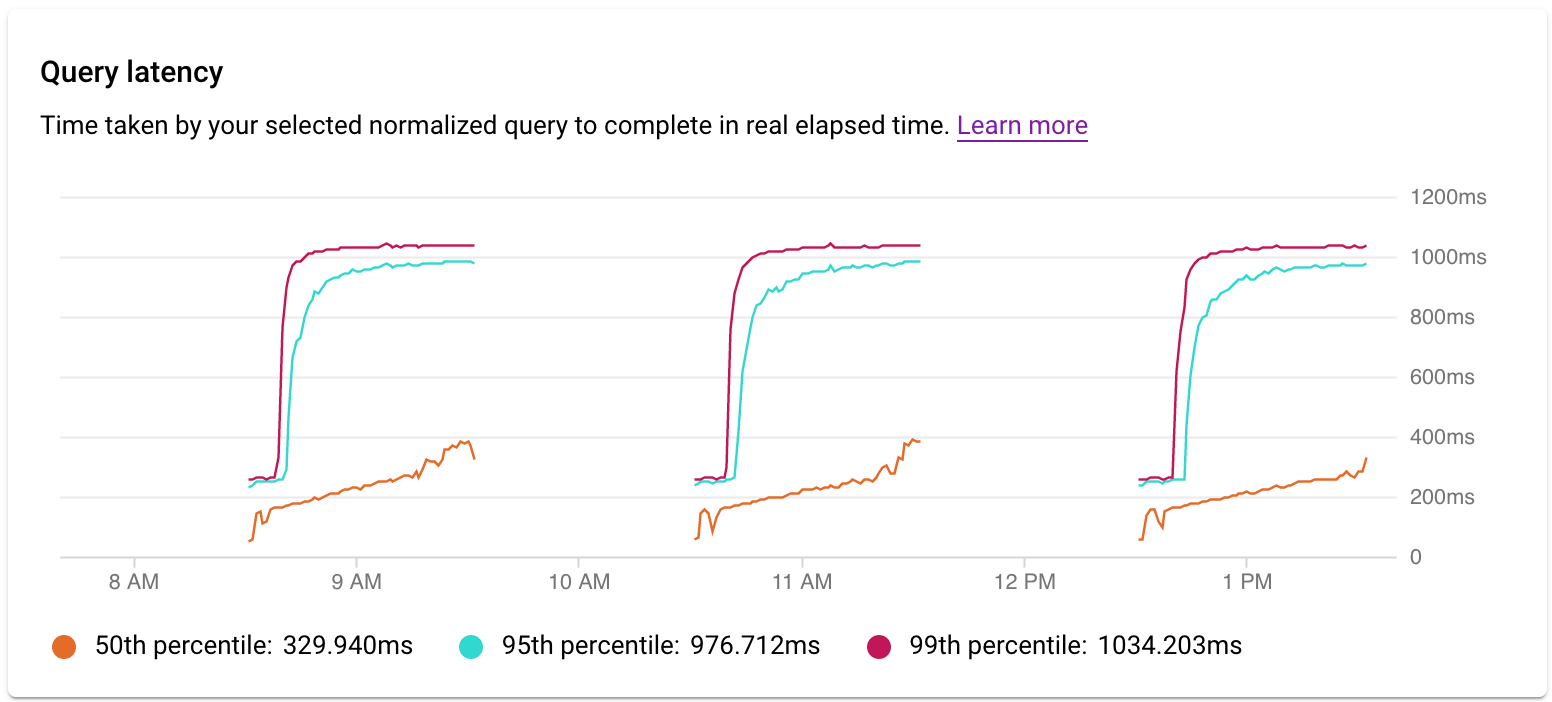
The latency of Parallel Queries is measured in wall clock time even though query load can be higher for the query due to multiple cores being used to run part of the query.
Try to narrow down the problem by looking at the following:
- What is causing the high load? Select options to look at the CPU capacity, CPU and CPU wait, lock wait, or IO wait.
- How long has the load been high? Is it only high now? Or has it been high for a long time? Change the time ranges to find the date and time that the load started performing poorly.
- Were there spikes in latency? You can change the time window to study the historical latency for the normalized query.
When you find the areas and times for the highest load, you can drill down further.
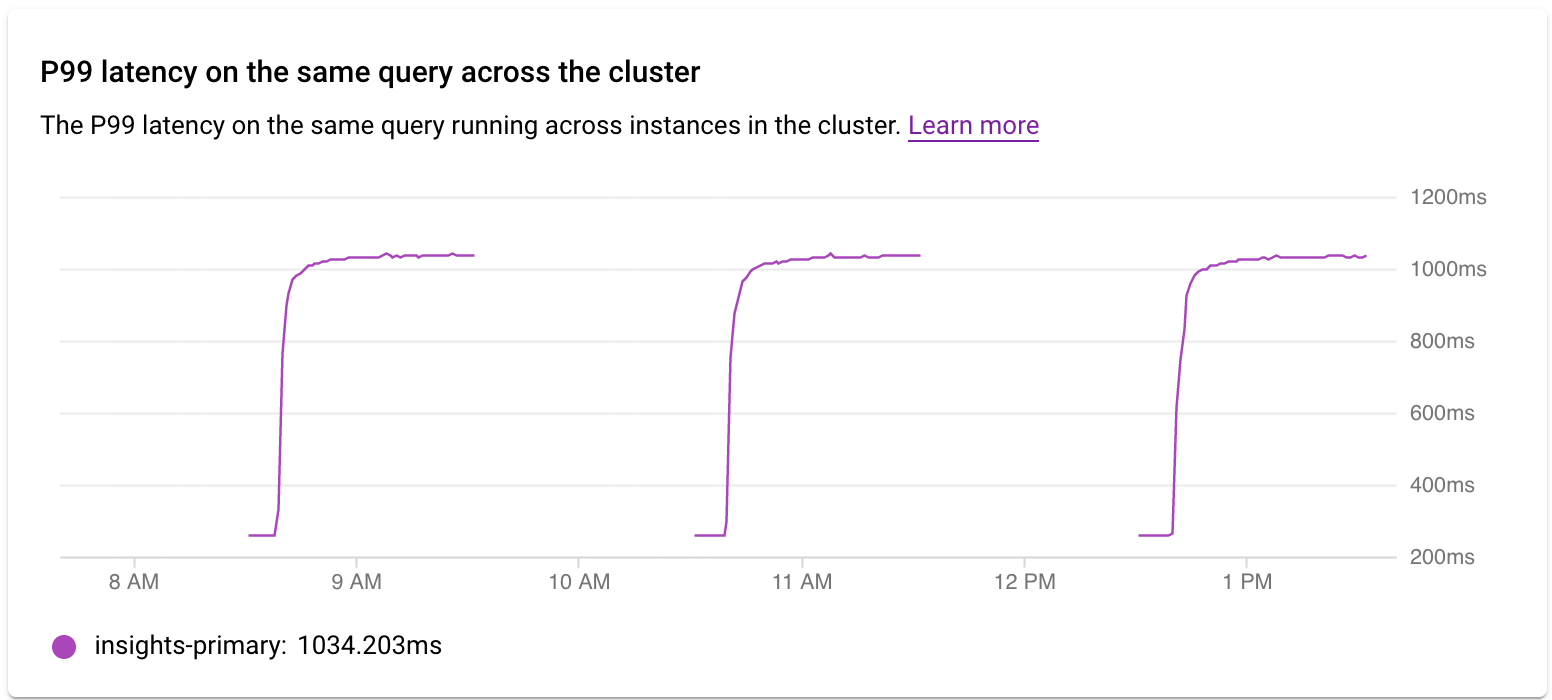
Examine the latency across a cluster
You use the P99 latency on the same query across the cluster graph to examine P99 latency on the query or tag across instances in the cluster.
Examine operations in a sampled query plan
A query plan takes a sample of your query and breaks it down into individual operations. It explains and analyzes each operation in the query. The Query plan samples graph shows all the query plans running at particular times and the amount of time each plan took to run.
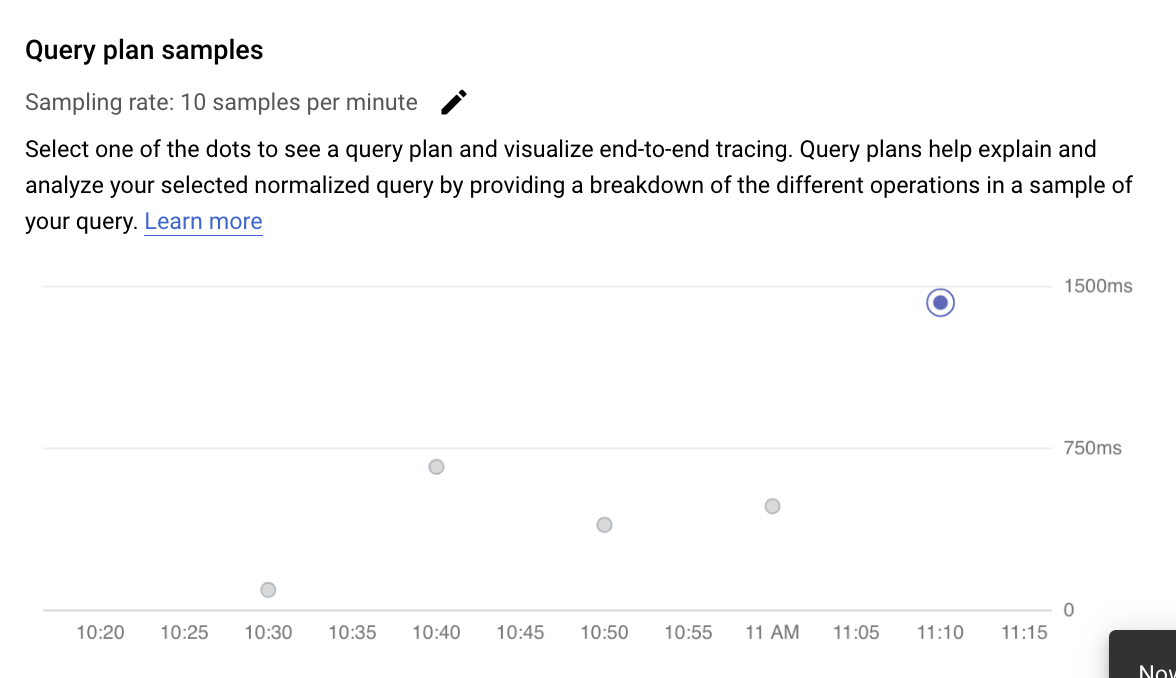
To see details for the sample query plan, click the dots on the Sample query plans graph. There is a view of executed sample query plans for most, but not all, queries. Expanded details show a model of all the operations in the query plan. Each operation shows the latency, rows returned, and the cost for that operation. When you select an operation, you can see more details, such as shared hit blocks, the type of schema, the actual loops, plan rows, and more.
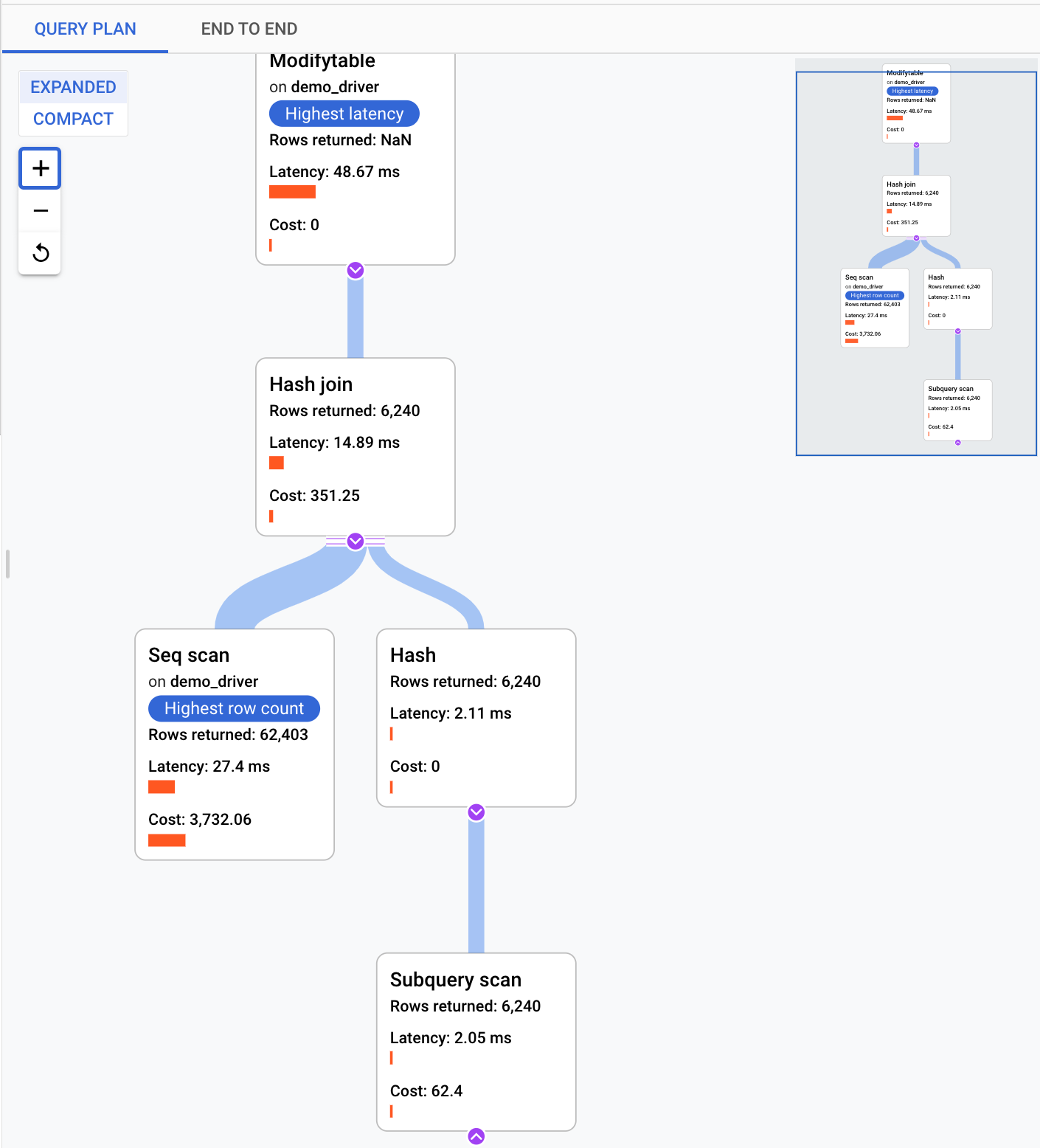
Try to narrow down the problem by looking at the following questions:
- What is the resource consumption?
- How does it relate to other queries?
- Does consumption change over time?
Examine a trace generated by a sample query
In addition to viewing the sample query plan, you can use query insights to view an in-context, end-to-end application trace for a sample query. This trace can help you identify the source of a problematic query by displaying database activity for a specific request. Also, log entries that the application sends to Cloud Logging during the request are linked to the trace, which helps you with your investigation.
To view the in-context trace, do the following:
In the Sample Query pane, click the End-to-end Trace tab. This tab displays a Gantt chart that details the spans, which are records of individual operations, for the trace generated by the query.
To view more details about each span, such as attributes and metadata, click the span.
You can also view the trace in the Trace Explorer page. To do so, click View in Cloud Trace. For details about how to use the Trace Explorer page to explore your trace data, see Find and explore traces.
Add tags to SQL queries
Tagging SQL queries simplifies application troubleshooting. You can use sqlcommenter to add tags to your SQL queries either automatically by using Object-relational mapping (ORM) or manually.
Use sqlcommenter with ORM
When ORM is used instead of directly writing SQL queries, you might not find application code that is causing performance challenges. You might also have trouble analyzing how your application code impacts query performance. To tackle that pain point, Query insights provide an open source library called sqlcommenter, an ORM instrumentation library. This library is useful for developers using ORMs and administrators to detect which application code is causing performance problems.
If you're using ORM and sqlcommenter together, the tags are auto created without requiring you to change or add custom code to your application.
You can install sqlcommenter on the application server. The instrumentation library allows application information related to your MVC framework to be propagated to the database along with the queries as a SQL comment. The database picks up these tags and starts recording and aggregating statistics by tags, which are orthogonal with statistics aggregated by normalized queries. Query insights show the tags so that you know which application is causing the query load. This information helps you find which application code is causing performance problems.
When you examine results in SQL database logs, they appear as follows:
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
Supported tags include the controller name, route, framework, and action.
The set of ORMs in sqlcommenter is supported for various programming languages:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
For more information about sqlcommenter and how to use it sqlcommenter in your ORM framework, see the sqlcommenter documentation in GitHub.
Use sqlcommenter to add tags manually
If you're not using ORM, you must manually add sqlcommenter tags to your SQL queries. In your query, you must augment each SQL statement with a comment containing a serialized key-value pair. Use at least one of the following keys:
action=''controller=''framework=''route=''application=''db driver=''
Query insights drop all other keys. See the sqlcommenter documentation for the correct SQL comment format.
Execution time and duration
Query insights provide an Avg execution time (ms) metric, which reports the total time that all sub-tasks take across all parallel workers to complete the query. This metric can help you optimize the aggregate resource utilization of databases by finding and optimizing queries that create the highest CPU overhead.
To view the elapsed time, you can measure the duration of a query by running the
\timing command on the psql client. It measures the time that elapses between
receiving the query and the PostgreSQL server sending a response. This metric can
help you analyze why a given query is taking too long, and decide whether to
optimize it to run faster.
If a query is completed single-threaded by a single task, the duration and average execution time remain the same.
Enable advanced query insights features for AlloyDB
The advanced query insights features for AlloyDB dashboard is integrated within the standard query insights dashboard. For more information about enabling advanced query insights features, see Improve query performance using advanced query insights features.
What's next
- Query insights overview
- Improve query performance using advanced query insights features for AlloyDB
- AlloyDB metrics
- SQL Commenter blog: Introducing Sqlcommenter: An open source ORM auto-instrumentation library
- How-to blog: Enable query tagging with Sqlcommenter