Ce tutoriel explique comment configurer et effectuer une recherche vectorielle dans AlloyDB pour PostgreSQL à l'aide de la console Google Cloud . Des exemples sont inclus pour illustrer les fonctionnalités de recherche vectorielle. Ils sont fournis à des fins de démonstration uniquement.
Pour savoir comment utiliser la recherche vectorielle filtrée afin d'affiner vos recherches de similarité, consultez Recherche vectorielle filtrée dans AlloyDB pour PostgreSQL.
Pour savoir comment effectuer une recherche vectorielle avec les embeddings Vertex AI, consultez Premiers pas avec les embeddings vectoriels AlloyDB/AI.
Objectifs
- Créez un cluster AlloyDB et une instance principale.
- Connectez-vous à votre base de données et installez les extensions requises.
- Créez un tableau
productetproduct inventory. - Insérez des données dans les tables
productetproduct inventory, puis effectuez une recherche vectorielle de base. - Créez un index ScaNN sur la table "products".
- Effectuez une recherche vectorielle simple.
- Effectuez une recherche vectorielle complexe avec un filtre et une jointure.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, supprimez les ressources que vous avez créées pour éviter que des frais vous soient facturés. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
Activer la facturation et les API requises
Dans la console Google Cloud , accédez à la page Clusters.
Assurez-vous que la facturation est activée pour votre projet Google Cloud .
Activez les APIs Cloud nécessaires pour créer et vous connecter à AlloyDB pour PostgreSQL.
- À l'étape Confirmer le projet, cliquez sur Suivant pour confirmer le nom du projet que vous allez modifier.
À l'étape Activer les API, cliquez sur Activer pour activer les éléments suivants :
- API AlloyDB
- API Compute Engine
- API Service Networking
- API Vertex AI
Créer un cluster et une instance principale AlloyDB
Dans la console Google Cloud , accédez à la page Clusters.
Cliquez sur Créer un cluster.
Dans le champ ID du cluster, saisissez
my-cluster.Saisissez un mot de passe. Notez ce mot de passe, car vous l'utiliserez dans ce tutoriel.
Sélectionnez une région, par exemple
us-central1 (Iowa).Sélectionnez le réseau par défaut.
Si vous disposez d'une connexion d'accès privé, passez à l'étape suivante. Sinon, cliquez sur Configurer la connexion et procédez comme suit :
- Dans Allouer une plage d'adresses IP, cliquez sur Utiliser une plage d'adresses IP automatiquement allouée.
- Cliquez sur Continuer, puis sur Créer une connexion.
Dans Disponibilité zonale, sélectionnez Zone unique.
Sélectionnez le type de machine
2 vCPU,16 GB.Dans Connectivité, sélectionnez Activer l'adresse IP publique.
Cliquez sur Créer un cluster. La création du cluster par AlloyDB et son affichage sur la page Présentation du cluster principal peuvent prendre plusieurs minutes.
Dans Instances dans votre cluster, développez le volet Connectivité. Notez l'URI de connexion, car vous l'utiliserez dans ce tutoriel.
L'URI de connexion est au format
projects/<var>PROJECT_ID</var>/locations/<var>REGION_ID</var>/clusters/my-cluster/instances/my-cluster-primary.
Accorder l'autorisation Utilisateur Vertex AI à l'agent de service AlloyDB
Pour permettre à AlloyDB d'utiliser les modèles d'embedding de texte Vertex AI, vous devez ajouter des autorisations utilisateur Vertex AI à l'agent de service AlloyDB pour le projet où se trouvent votre cluster et votre instance.
Pour savoir comment ajouter les autorisations, consultez Accorder l'autorisation d'utilisateur Vertex AI à l'agent de service AlloyDB.
Se connecter à votre base de données à l'aide d'un navigateur Web
Dans la console Google Cloud , accédez à la page Clusters.
Dans la colonne Nom de la ressource, cliquez sur le nom de votre cluster,
my-cluster.Dans le volet de navigation, cliquez sur AlloyDB Studio.
Sur la page Se connecter à AlloyDB Studio, procédez comme suit :
- Sélectionnez la base de données
postgres. - Sélectionnez l'utilisateur
postgres. - Saisissez le mot de passe que vous avez créé dans Créer un cluster et son instance principale.
- Cliquez sur Authentifier. Le volet Explorateur affiche la liste des objets de la base de données
postgres.
- Sélectionnez la base de données
Ouvrez un nouvel onglet en cliquant sur + Nouvel onglet de l'éditeur SQL ou sur + Nouvel onglet.
Installer les extensions requises
Exécutez la requête suivante pour installer les extensions vector et alloydb_scann :
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Insérer des données produit et d'inventaire de produits, et effectuer une recherche vectorielle de base
Exécutez l'instruction suivante pour créer une table
productqui effectue les opérations suivantes :- Stocke les informations de base sur les produits.
- Inclut une colonne de vecteur
embeddingqui calcule et stocke un vecteur d'embedding pour la description de chaque produit.
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );Si nécessaire, vous pouvez utiliser l'explorateur de journaux pour afficher les journaux et résoudre les problèmes.
Exécutez la requête suivante pour créer une table
product_inventoryqui stocke des informations sur l'inventaire disponible et les prix correspondants. Les tablesproduct_inventoryetproductsont utilisées dans ce tutoriel pour exécuter des requêtes de recherche vectorielle complexes.CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );Exécutez la requête suivante pour insérer des données produit dans la table
product:INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');Facultatif : Exécutez la requête suivante pour vérifier que les données sont insérées dans la table
product:SELECT * FROM product;Exécutez la requête suivante pour insérer des données d'inventaire dans la table
product_inventory:INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);Exécutez la requête de recherche vectorielle suivante qui tente de trouver des produits similaires au mot
music. Cela signifie que même si le motmusicn'est pas mentionné explicitement dans la description du produit, le résultat affiche les produits qui correspondent à la requête :SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;Le résultat de la requête se présente comme suit :
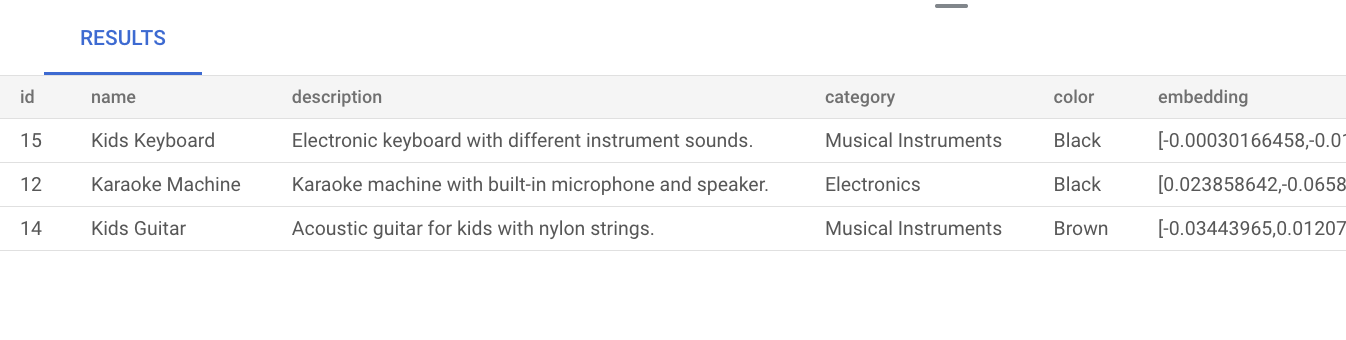
Une recherche vectorielle de base sans création d'index utilise la recherche exacte du voisin le plus proche (KNN), qui offre un rappel efficace. À grande échelle, l'utilisation de KNN peut avoir un impact sur les performances. Pour améliorer les performances des requêtes, nous vous recommandons d'utiliser l'index ScaNN pour la recherche approximative des voisins les plus proches (ANN), qui offre un rappel élevé avec de faibles latences.
Sans créer d'index, AlloyDB utilise par défaut la recherche exacte des k plus proches voisins (KNN).
Pour en savoir plus sur l'utilisation de ScaNN à grande échelle, consultez Premiers pas avec les embeddings vectoriels AlloyDB AI.
Créer un index ScaNN sur la table des produits
Exécutez la requête suivante pour créer un index ScaNN product_index sur la table product :
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (num_leaves=5);
Le paramètre num_leaves indique le nombre de nœuds feuilles avec lesquels l'index basé sur l'arborescence crée l'index. Pour savoir comment ajuster ce paramètre, consultez Ajuster les performances des requêtes vectorielles.
Effectuer une recherche vectorielle
Exécutez la requête de recherche vectorielle suivante qui tente de trouver des produits similaires à la requête en langage naturel music. Même si le mot music n'est pas inclus dans la description du produit, le résultat affiche des produits pertinents pour la requête :
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Les résultats de la requête sont les suivants :

Le paramètre de requête scann.num_leaves_to_search contrôle le nombre de nœuds feuilles recherchés lors d'une recherche de similarité. Les valeurs des paramètres num_leaves et scann.num_leaves_to_search permettent d'équilibrer les performances et le rappel.
Effectuer une recherche vectorielle qui utilise un filtre et une jointure
Vous pouvez exécuter efficacement des requêtes de recherche vectorielle filtrées, même lorsque vous utilisez l'index ScaNN. Exécutez la requête de recherche vectorielle complexe suivante, qui renvoie des résultats pertinents répondant aux conditions de la requête, même avec des filtres :
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
Accélérer votre recherche vectorielle filtrée
Vous pouvez utiliser le moteur columnar pour améliorer les performances des recherches de similarité vectorielle, en particulier les recherches K-Nearest Neighbor (KNN), lorsqu'il est combiné à un filtrage de prédicats très sélectif (par exemple, à l'aide de LIKE) dans les bases de données. Dans cette section, vous allez utiliser l'extension vector et l'extension AlloyDB google_columnar_engine.
Les améliorations des performances proviennent de l'efficacité intégrée du moteur en colonnes pour analyser de grands ensembles de données et appliquer des filtres (tels que les prédicats LIKE), ainsi que de sa capacité à préfiltrer les lignes à l'aide de la prise en charge des vecteurs.
Cette fonctionnalité réduit le nombre de sous-ensembles de données requis pour les calculs de distance vectorielle KNN ultérieurs et permet d'optimiser les requêtes analytiques complexes impliquant un filtrage standard et une recherche vectorielle.
Pour comparer le temps d'exécution d'une recherche vectorielle KNN filtrée par un prédicat LIKE avant et après l'activation du moteur columnar, procédez comme suit :
Activez l'extension
vectorpour prendre en charge les types de données et les opérations vectorielles. Exécutez les instructions suivantes pour créer une table d'exemple (éléments) avec un ID, une description textuelle et une colonne d'intégration vectorielle de 512 dimensions.CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );Remplissez les données en exécutant les instructions suivantes pour insérer un million de lignes dans l'exemple de table
items.-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, random_vector(512) -- Assumes random_vector function exists FROM generate_series(1, 999999) g;Mesurez les performances de référence de la recherche de similarité vectorielle sans le moteur en colonnes.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Activez le moteur columnar et la compatibilité avec les vecteurs en exécutant la commande suivante dans la Google Cloud CLI. Pour utiliser la gcloud CLI, vous pouvez installer et initialiser la gcloud CLI.
gcloud beta alloydb instances update INSTANCE_ID \ --cluster=CLUSTER_ID \ --region=REGION_ID \ --project=PROJECT_ID \ --database-flags=google_columnar_engine.enabled=on,google_columnar_engine.enable_vector_support=onAjoutez le tableau
itemsau moteur en colonnes :SELECT google_columnar_engine_add('items');Mesurez les performances de la recherche de similarité vectorielle à l'aide du moteur colonnaire. Vous réexécutez la requête que vous avez exécutée précédemment pour mesurer les performances de référence.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Pour vérifier si la requête a été exécutée avec le moteur columnar, exécutez la commande suivante :
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
Effectuer un nettoyage
Dans la console Google Cloud , accédez à la page Clusters.
Dans la colonne Nom de ressource, cliquez sur le nom de votre cluster,
my-cluster.Cliquez sur delete Supprimer le cluster.
Dans Delete cluster my-cluster, saisissez
my-clusterpour confirmer que vous souhaitez supprimer votre cluster.Cliquez sur Supprimer.
Si vous avez créé une connexion privée lorsque vous avez créé un cluster, accédez à la page Réseau de la console Google Cloud , puis cliquez sur Supprimer le réseau VPC.
Étapes suivantes
- Découvrez des cas d'utilisation concrets de la recherche vectorielle.
- Faites vos premiers pas avec les embeddings vectoriels à l'aide d'AlloyDB AI.
- Découvrez comment créer des applications d'IA générative à l'aide d'AlloyDB AI.
- Créez un index ScaNN.
- Ajustez vos index ScaNN.
- Découvrez comment créer un assistant d'achat intelligent avec AlloyDB, pgvector et la gestion des points de terminaison de modèles.
- Résolvez les erreurs à l'aide de l'explorateur de journaux.