Questo documento illustra come testare e monitorare le prestazioni di pubblicazione online dei modelli di machine learning (ML) di cui è stato eseguito il deployment in Previsione Piattaforma IA. Il documento utilizza Locust, uno strumento open source per i test di carico.
Il documento è rivolto a data scientist e MLOps engineer che vogliono monitorare il carico di lavoro del servizio, la latenza e l'utilizzo delle risorse dei loro modelli ML in produzione.
Il documento presuppone che tu abbia una certa esperienza con Google Cloud, TensorFlow, AI Platform Prediction, Cloud Monitoring e Jupyter Notebooks.
Il documento è accompagnato da un repository GitHub che include il codice e una guida all'implementazione per l'implementazione del sistema descritto in questo documento. Le attività vengono incorporate nei blocchi note Jupyter.
Costi
I notebook con cui lavori in questo documento utilizzano i seguenti componenti fatturabili di Google Cloud:
- Blocchi note gestiti dall'utente di Vertex AI Workbench
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine (GKE)
Per generare una stima dei costi in base all'utilizzo previsto, utilizza il Calcolatore prezzi.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Panoramica dell'architettura
Il seguente diagramma mostra l'architettura di sistema per il deployment del modello ML per la previsione online, l'esecuzione del test di carico e la raccolta e l'analisi delle metriche per le prestazioni di pubblicazione del modello ML.
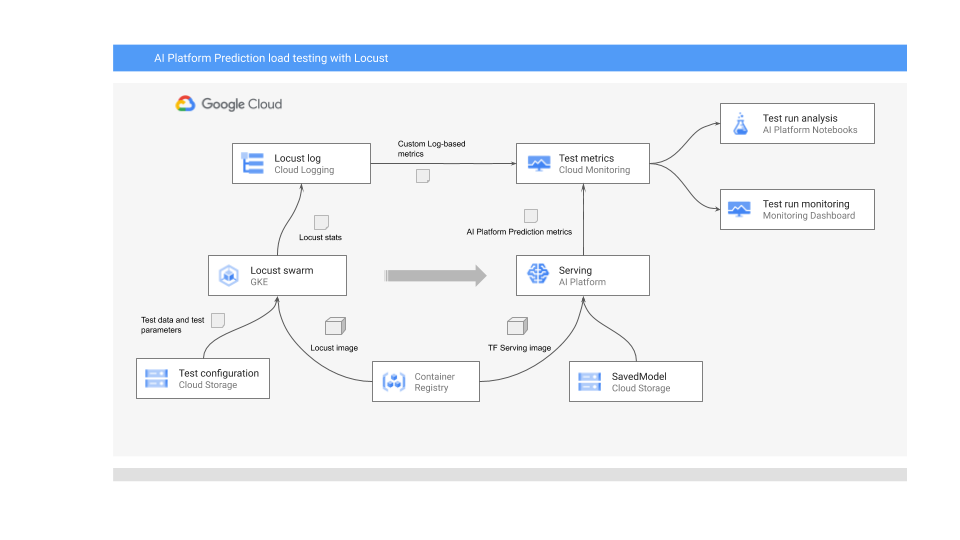
Il diagramma mostra il seguente flusso:
- Il modello addestrato potrebbe trovarsi in Cloud Storage, ad esempio un SavedModel di TensorFlow o un joblib di scikit-learn. In alternativa, potrebbe essere incorporato in un container di pubblicazione personalizzato in Container Registry, ad esempio TorchServe per la pubblicazione di modelli PyTorch.
- Il modello viene di cui è stato eseguito il deployment in AI Platform Prediction come API REST. AI Platform Prediction è un servizio completamente gestito per la pubblicazione di modelli che supporta diversi tipi di macchine, il ridimensionamento automatico in base all'utilizzo delle risorse e vari acceleratori GPU.
- Locust viene utilizzato per implementare un'attività di test (ovvero il comportamento dell'utente). Lo fa chiamando il modello ML di cui è stato eseguito il deployment in AI Platform Prediction ed eseguendolo su larga scala su Google Kubernetes Engine (GKE). In questo modo vengono simulate molte chiamate utente simultanee per il test di carico del servizio di previsione del modello. Puoi monitorare l'avanzamento dei test utilizzando l'interfaccia web di Locust.
- Locust registra le statistiche dei test in Cloud Logging. Le voci di log create dal test Locust vengono utilizzate per definire un insieme di metriche basate su log in Cloud Monitoring. Queste metriche completano le metriche di AI Platform Prediction standard.
- Sia le metriche della piattaforma AI sia le metriche personalizzate di Locust sono disponibili per la visualizzazione in una dashboard di Cloud Monitoring in tempo reale. Al termine del test, le metriche vengono anche raccolte tramite programmazione in modo da poterle analizzare e visualizzare nei notebook gestiti dall'utente di Vertex AI Workbench.
I notebook Jupyter per questo scenario
Tutte le attività per la preparazione e l'implementazione del modello, l'esecuzione del test Locust e la raccolta e l'analisi dei risultati del test sono codificate nei seguenti blocchi note Jupyter. Per eseguire le attività, esegui la sequenza di celle in ogni notebook.
01-prepare-and-deploy.ipynb. Esegui questo notebook per preparare un SavedModel di TensorFlow per il servizio e per eseguire il deployment del modello in AI Platform Prediction.02-perf-testing.ipynb. Esegui questo notebook per creare metriche basate su log in Cloud Monitoring per il test Locust, per eseguire il deployment del test Locust su GKE ed eseguirlo.03-analyze-results.ipynb. Esegui questo notebook per raccogliere e analizzare i risultati del test di carico Locust dalle metriche standard di AI Platform create da Cloud Monitoring e dalle metriche Locust personalizzate.
Inizializzazione dell'ambiente
Come descritto nel
README.md
file del repository GitHub associato, devi eseguire i seguenti
passaggi per preparare l'ambiente per l'esecuzione dei notebook:
- Nel tuo progetto Google Cloud, crea un bucket Cloud Storage, obbligatorio per archiviare il modello addestrato e la configurazione del test Locust. Prendi nota del nome utilizzato per il bucket, perché ti servirà in seguito.
- Crea uno spazio di lavoro Cloud Monitoring nel tuo progetto.
- Crea un cluster Google Kubernetes Engine con le CPU richieste. Il pool di nodi deve avere accesso alle API Cloud.
- Crea un'istanza di notebook gestita dall'utente di Vertex AI Workbench che utilizza TensorFlow 2. Per questo tutorial non sono necessarie GPU perché non addestri il modello. Le GPU possono essere utili in altri scenari, in particolare per velocizzare l'addestramento dei modelli.
Apertura di JupyterLab
Per svolgere le attività per lo scenario, devi aprire l'ambiente JupyterLab e recuperare i notebook.
Nella console Google Cloud, vai alla pagina Notebook.
Nella scheda Blocchi note gestiti dall'utente, fai clic su Apri JupyterLab accanto all'ambiente di notebook che hai creato.
Viene aperto l'ambiente JupyterLab nel browser.
Per avviare una scheda del terminale, fai clic sull'icona Terminale nella scheda Avvio app.
Nel terminale, clona il
mlops-on-gcprepository GitHub:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitAl termine del comando, vedrai la cartella
mlops-on-gcpnel browser di file. In questa cartella vedrai i notebook con cui lavori in questo documento.
Configurazione delle impostazioni del notebook
In questa sezione, imposti le variabili nei notebook con valori specifici per il tuo contesto e prepari l'ambiente per eseguire il codice per lo scenario.
- Vai alla directory
model_serving/caip-load-testing. - Per ciascuno dei tre notebook, svolgi le seguenti operazioni:
- Apri il notebook.
- Esegui le celle in Configura le impostazioni dell'ambiente Google Cloud.
Le sezioni seguenti mettono in evidenza le parti chiave del processo e spiegano aspetti del design e del codice.
Pubblicazione del modello per la previsione online
Il modello ML utilizzato in questo documento utilizza il preaddestrato modello di classificazione delle immagini ResNet V2 101 di TensorFlow Hub. Tuttavia, puoi adattare i pattern e le tecniche di progettazione di sistema descritti in questo documento ad altri domini e ad altri tipi di modelli.
Il codice per la preparazione e l'erogazione del modello ResNet 101 si trova nel
notebook 01-prepare-and-deploy.ipynb. Esegui le celle nel notebook per svolgere le seguenti attività:
- Scarica ed esegui il modello ResNet da TensorFlow Hub.
- Crea le firme di pubblicazione per il modello.
- Esporta il modello come SavedModel.
- Esegui il deployment del SavedModel in AI Platform Prediction.
- Convalida il modello di cui è stato eseguito il deployment.
Le sezioni successive di questo documento forniscono dettagli sulla preparazione del modello ResNet e sul suo dispiegamento.
Prepara il modello ResNet per il deployment
Il modello ResNet di TensorFlow Hub non ha firme di pubblicazione perché è ottimizzato per la ricostituzione e la messa a punto fine. Pertanto, devi creare firme di servizio per il modello in modo che possa essere pubblicato per le previsioni online.
Inoltre, per pubblicare il modello, ti consigliamo di incorporare la logica di creazione delle funzionalità nell'interfaccia di pubblicazione. In questo modo viene garantita l'affinità tra la preelaborazione e la pubblicazione del modello, anziché dipendere dall'applicazione client per preelaborare i dati nel formato richiesto. Devi anche includere il post-processing nell'interfaccia di pubblicazione, ad esempio la conversione di un ID classe in un'etichetta classe.
Per rendere il modello ResNet disponibile, devi implementare le firme di pubblicazione che descrivono i metodi di inferenza del modello. Pertanto, il codice del notebook aggiunge due firme:
- La firma predefinita. Questa firma espone il metodo
predictpredefinito del modello ResNet V2 101. Il metodo predefinito non ha logica di preelaborazione o post-elaborazione. - Firma di pre-elaborazione e post-elaborazione. Gli input previsti per questa interfaccia richiedono una preelaborazione relativamente complessa, inclusa la codifica, la scalatura e la normalizzazione dell'immagine. Pertanto, il modello esposto anche una firma alternativa che incorpora la logica di pre-elaborazione e post-elaborazione. Questa firma accetta immagini non elaborate e restituisce l'elenco delle etichette delle classi classificate e le probabilità associate.
Le firme vengono create in una classe del modulo personalizzato. La classe è derivata dalla
classe di base tf.Module
che incapsula il modello ResNet. La classe personalizzata estende la classe di base con un metodo che implementa la logica di pre-elaborazione delle immagini e di post-elaborazione dell'output. Il metodo predefinito del modulo personalizzato viene mappato al metodo predefinito del modello ResNet di base per mantenere l'interfaccia analoga. Il
modulo personalizzato viene esportato come SavedModel che include il modello originale, la
logica di preelaborazione e due firme di pubblicazione.
L'implementazione della classe del modulo personalizzato è mostrata nel seguente snippet di codice:
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
Il seguente snippet di codice mostra come il modello viene esportato come SavedModel con le firme di pubblicazione definite in precedenza:
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
Esegui il deployment del modello in AI Platform Prediction
Quando il modello viene esportato come SavedModel, vengono eseguite le seguenti attività:
- Il modello viene caricato su Cloud Storage.
- Viene creato un oggetto modello in AI Platform Prediction.
- Viene creata una versione del modello per il SavedModel.
Il seguente snippet di codice del notebook mostra i comandi che eseguono queste attività.
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
Il comando crea un tipo di macchina n1-standard-8 per il servizio di previsione del modello insieme a un acceleratore GPU nvidia-tesla-p4.
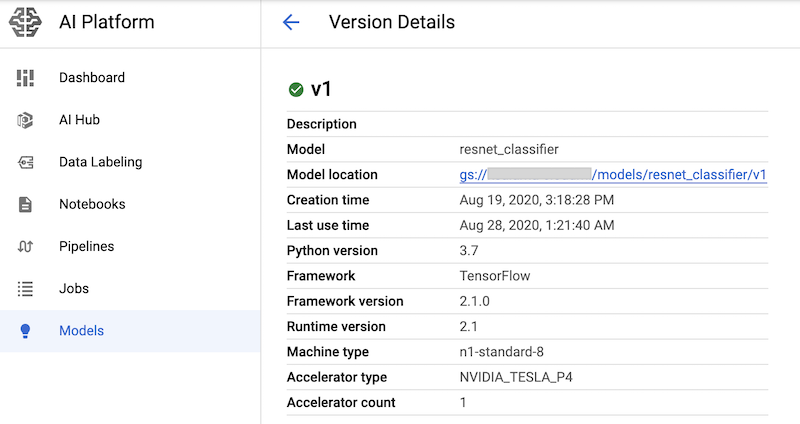
Dopo aver eseguito le celle del notebook contenenti questi comandi, puoi verificare che la versione del modello sia stata dispiata visualizzandola nella pagina Modelli della piattaforma AI della console Google Cloud. L'output è simile al seguente:
Creazione di metriche di Cloud Monitoring
Dopo aver configurato il modello per la pubblicazione, puoi configurare le metriche che ti consentono di monitorare il rendimento della pubblicazione. Il codice per la configurazione delle metriche si trova nel notebook 02-perf-testing.ipynb.
La prima parte del notebook
02-perf-testing.ipynb
crea metriche personalizzate basate su log in Cloud Monitoring utilizzando il
SDK Python Cloud Logging.
Le metriche si basano sulle voci di log generate dall'attività Locust.
Il metodo
log_stats
scrive le voci di log in un log di Cloud Logging denominato locust.
Ogni voce del log include un insieme di coppie chiave-valore in formato JSON, come indicato nella tabella seguente. Le metriche si basano sul sottoinsieme di chiavi dell'elemento del log.
| Chiave | Descrizione del valore | Utilizzo |
|---|---|---|
test_id
|
L'ID di un test | Attributi di filtro |
model |
Il nome del modello AI Platform Prediction | |
model_version |
La versione del modello AI Platform Prediction | |
latency
|
Il tempo di risposta del 95° percentile, calcolato su un periodo di tempo scorrevole di 10 secondi | Valori metriche |
num_requests |
Il numero totale di richieste dall'inizio del test | |
num_failures |
Il numero totale di errori dall'avvio del test | |
user_count |
Il numero di utenti simulati | |
rps |
Le richieste al secondo |
Il seguente snippet di codice mostra la funzione create_locust_metric nel
notebook che crea una metrica personalizzata basata sui log.
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
Il seguente snippet di codice mostra come viene invocato il metodo create_locust_metric nel notebook per creare le quattro metriche Locust personalizzate mostrate nella tabella precedente.
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
Il notebook crea una dashboard di Cloud Monitoring personalizzata denominata AI Platform Prediction and Locust. La dashboard combina le metriche di previsione di AI Platform standard e le metriche personalizzate che vengono create in base ai log di Locust.
Per ulteriori informazioni, consulta la documentazione dell'API Cloud Logging.
Questa dashboard e i relativi grafici possono essere
creati manualmente.
Tuttavia, il notebook fornisce un modo programmatico per crearlo utilizzando il
modello JSON monitoring-template.json. Il codice utilizza la classe
DashboardsServiceClient
per caricare il modello JSON e creare la dashboard in Cloud Monitoring, come mostrato nello snippet di codice seguente:
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
Dopo aver creato la dashboard, puoi visualizzarla nell'elenco delle dashboard di Cloud Monitoring nella console Google Cloud:
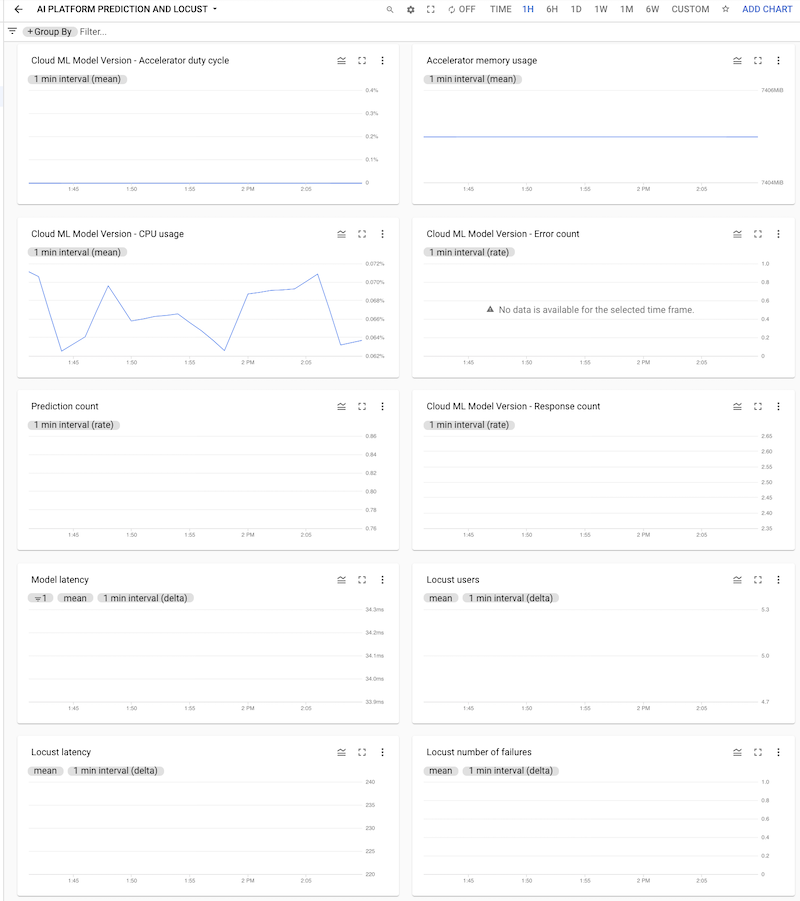
Puoi fare clic sulla dashboard per aprirla e visualizzare i grafici. Ogni grafico mostra una metrica di Previsione di AI Platform o dei log di Locust, come показано показано negli screenshot seguenti.
Eseguire il deployment del test Locust nel cluster GKE
Prima di eseguire il deployment del sistema Locust in GKE, devi compilare l'immagine del container Docker che contiene la logica di test integrata nel file task.py. L'immagine è ricavata dall'immagine baseline locust.io e viene utilizzata per i pod Locust master e worker.
La logica per la creazione e il deployment è nel notebook in 3. Esegui il deployment di Locust in un cluster GKE. L'immagine viene creata utilizzando il seguente codice:
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
Il processo di deployment descritto nel notebook è stato definito utilizzando Kustomize. I manifest di deployment di Locust Kustomize definiscono i seguenti file che definiscono i componenti:
locust-master. Questo file definisce un deployment che ospita un'interfaccia web in cui avviare il test e visualizzare le statistiche in tempo reale.locust-worker. Questo file definisce un deployment che esegue un'attività per il test di carico del servizio di previsione del modello di ML. In genere, vengono creati più worker per simulare l'effetto di più utenti simultanei che effettuano chiamate all'API del servizio di previsione.locust-worker-service. Questo file definisce un servizio che accede all'interfaccia web inlocust-mastertramite un bilanciatore del carico HTTP.
Devi aggiornare il manifest predefinito prima di eseguire il deployment del cluster. Il manifest predefinito è costituito dai file kustomization.yaml e patch.yaml. Devi apportare modifiche in entrambi i file.
Nel file kustomization.yaml:
- Imposta il nome dell'immagine Locust personalizzata. Imposta il campo
newNamenella sezioneimagessul nome dell'immagine personalizzata creata in precedenza. - (Facoltativo) Imposta il numero di pod worker. La configurazione predefinita consente di eseguire il deployment di 32 pod worker. Per modificare il numero, modifica il campo
countnella sezionereplicas. Assicurati che il tuo cluster GKE abbia un numero sufficiente di CPU per i worker Locust. - Imposta il bucket Cloud Storage per la configurazione del test e per i file del payload. Nella sezione
configMapGenerator, assicurati che sia impostato quanto segue:LOCUST_TEST_BUCKET. Imposta il nome del bucket Cloud Storage che hai creato in precedenza.LOCUST_TEST_CONFIG. Imposta il nome del file di configurazione del test. Nel file YAML, questo valore è impostato sutest-config.json, ma puoi modificarlo se vuoi utilizzare un nome diverso.LOCUST_TEST_PAYLOAD. Imposta il nome del file del payload di test. Nel file YAML, questo valore è impostato sutest-payload.json, ma puoi modificarlo se vuoi utilizzare un nome diverso.
Nel file patch.yaml:
- Se vuoi, modifica il pool di nodi che ospita il master e i worker di Locust. Se esegui il deployment del workload Locust in un pool di nodi diverso da
default-pool, individua la sezionematchExpressionse poi invaluesaggiorna il nome del pool di nodi in cui verrà eseguito il deployment del workload Locust.
Dopo aver apportato queste modifiche, puoi creare le tue personalizzazioni nei manifest di Kustomize e applicare il deployment di Locust (locust-master,
locust-worker e locust-master-service) al cluster GKE. Il seguente comando nel notebook esegue queste attività:
!kustomize build locust/manifests | kubectl apply -f -
Puoi controllare i workload di cui è stato eseguito il deployment nella console Google Cloud. L'output è simile al seguente:
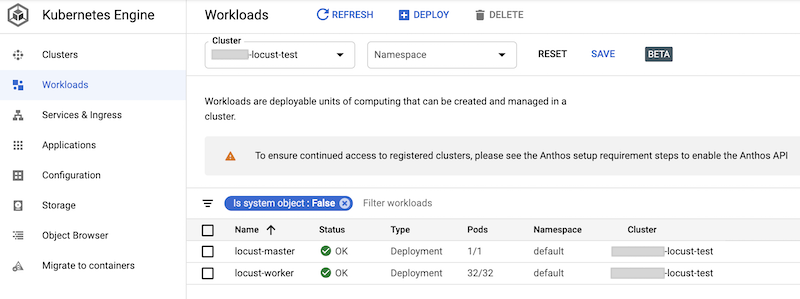
Implementazione del test di carico Locust
Il compito di test di Locust è chiamare il modello di cui è stato eseguito il deployment in AI Platform Prediction.
Questa attività è implementata nella classe
AIPPClient
del modulo
task.py
che si trova nella cartella /locust/locust-image/. Il seguente snippet di codice mostra l'implementazione della classe.
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
La classe AIPPUser nel file task.py eredita dalla classe locust.User per simulare il comportamento dell'utente che chiama il modello di Previsione di AI Platform. Questo comportamento è implementato nel metodo predict_task. Il metodo on_start della classe AIPPUser scarica i seguenti file da un bucket Cloud Storage specificato nella variabile LOCUST_TEST_BUCKET nel file task.py:
test-config.json. Questo file JSON include le seguenti configurazioni per il test:test_id,project_id,modeleversion.test-payload.json. Questo file JSON include le istanze di dati nel formato previsto da AI Platform Prediction, insieme alla firma target.
Il codice per la preparazione dei dati di test e della configurazione del test è incluso nel notebook
02-perf-testing.ipynb
in 4. Configura un test Locust.
Le configurazioni di test e le istanze di dati vengono utilizzate come parametri per il metodo predict nella classe AIPPClient per testare il modello di destinazione utilizzando i dati di test richiesti. AIPPUser
Simula un tempo di attesa
di 1-2 secondi tra le chiamate di un singolo utente.
Eseguire il test Locust
Dopo aver eseguito le celle del notebook per eseguire il deployment del carico di lavoro Locust nel
cluster GKE e aver creato e caricato i file test-config.json e test-payload.json su Cloud Storage,
puoi avviare, arrestare e configurare un nuovo test di carico Locust utilizzando la sua
interfaccia web.
Il codice nel notebook recupera l'URL del bilanciatore del carico esterno che espone l'interfaccia web utilizzando il seguente comando:
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
Per eseguire il test:
- In un browser, inserisci l'URL recuperato.
Per simulare il carico di lavoro del test utilizzando configurazioni diverse, inserisci i valori nell'interfaccia di Locust, simile al seguente:
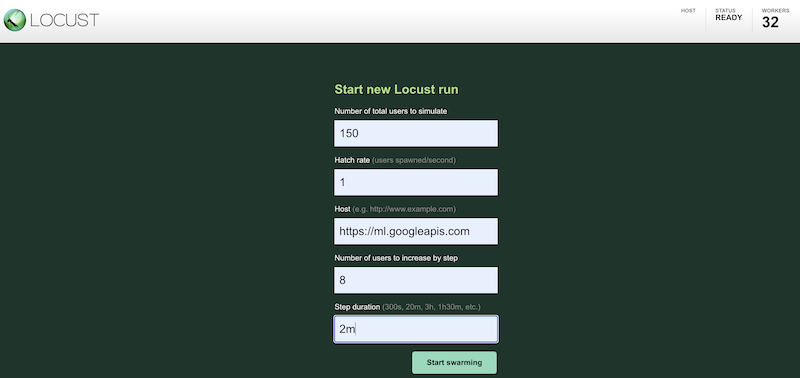
Lo screenshot precedente mostra i seguenti valori di configurazione:
- Numero totale di utenti da simulare:
150 - Tasso di schiusa:
1 - Host:
http://ml.googleapis.com - Numero di utenti da aumentare per passaggio:
10 - Durata del passaggio:
2m
- Numero totale di utenti da simulare:
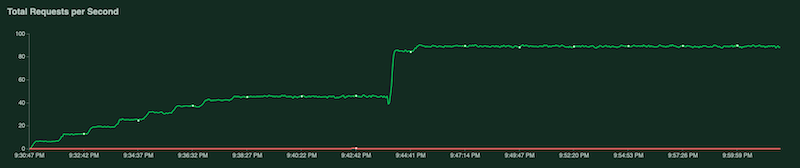
Durante l'esecuzione del test, puoi monitorarlo esaminando i grafici di Locust. Gli screenshot seguenti mostrano come vengono visualizzati i valori.
Un grafico mostra il numero totale di richieste al secondo:
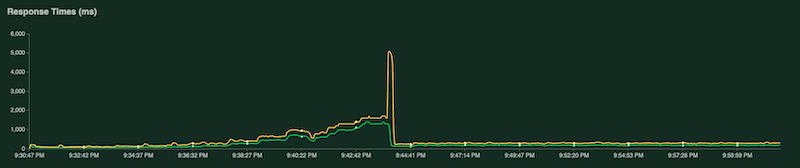
Un altro grafico mostra il tempo di risposta in millisecondi:
Come accennato in precedenza, queste statistiche vengono registrate anche in Cloud Logging, in modo da poter creare metriche personalizzate basate sui log di Cloud Monitoring.
Raccogliere e analizzare i risultati dei test
Il passaggio successivo consiste nel raccogliere e analizzare le metriche di Cloud Monitoring che vengono calcolate dai log dei risultati come oggetto pandas DataFrame in modo da poter visualizzare e analizzare i risultati nel notebook. Il codice per eseguire questa operazione si trova nel notebook 03-analyze-results.ipynb.
Il codice utilizza il
SDK Python per query di monitoraggio di Cloud
per filtrare e recuperare i valori delle metriche, dati i valori trasmessi ai parametri
project_id, test_id, start_time, end_time, model, model_version e
log_name.
Il seguente snippet di codice mostra i metodi che recuperano le metriche di previsione di AI Platform e le metriche personalizzate basate sui log di Locust.
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
I dati delle metriche vengono recuperati come oggetto DataFrame di pandas per ogni metrica;
i singoli frame di dati vengono poi uniti in un unico oggetto DataFrame. L'oggetto DataFrame finale con i risultati uniti sarà simile al seguente nel tuo notebook:
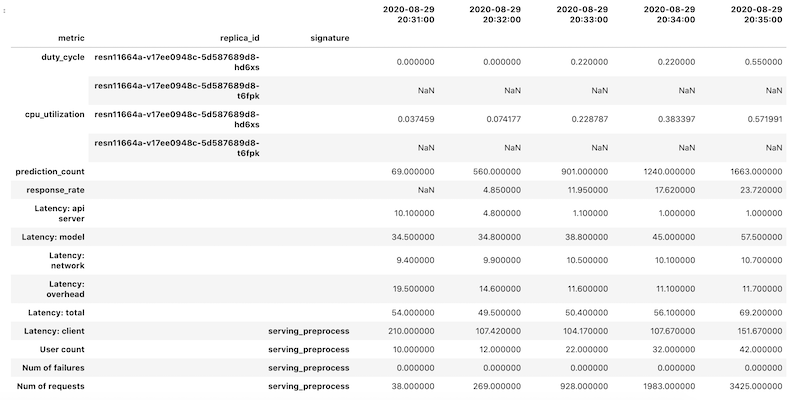
L'oggetto DataFrame recuperato utilizza
l'indicizzazione gerarchica
per i nomi delle colonne. Il motivo è che alcune metriche contengono più serie temporali.
Ad esempio, la metrica GPU duty_cycle include una serie temporale di misurazioni per ogni GPU utilizzata nel deployment, indicata come replica_id. Il primo livello
dell'indice di colonna mostra il nome di una singola metrica. Il secondo livello è un ID replica. Il terzo livello mostra la firma di un modello. Tutte le metriche sono aliniate sulla stessa sequenza temporale.
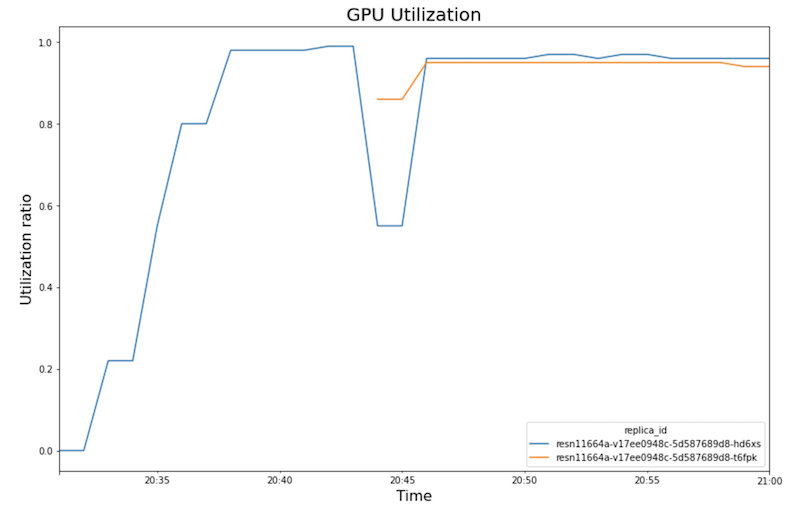
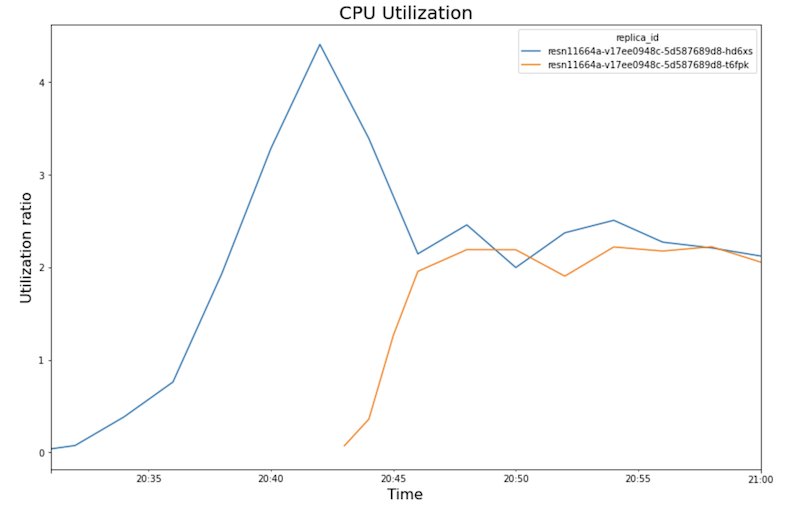
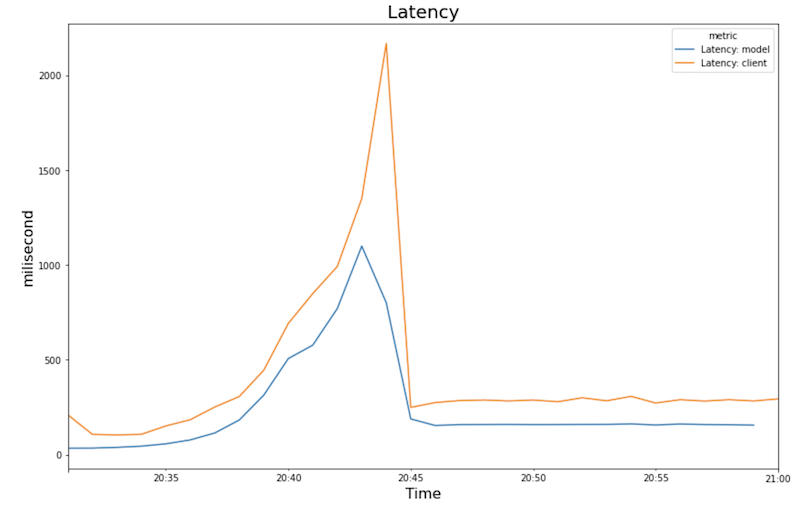
I seguenti grafici mostrano l'utilizzo della GPU, l'utilizzo della CPU e la latenza come appaiono nel notebook.
Utilizzo GPU:
Utilizzo CPU:
Latenza:
I grafici mostrano il seguente comportamento e sequenza:
- Con l'aumento del carico di lavoro (numero di utenti), aumenta anche l'utilizzo della CPU e della GPU. Di conseguenza, la latenza aumenta e la differenza tra la latenza del modello e la latenza totale aumenta fino a raggiungere il picco intorno alle 20:40.
- Alle 20:40, l'utilizzo della GPU raggiunge il 100%, mentre il grafico della CPU mostra che l'utilizzo raggiunge 4 CPU. In questo test, il sample utilizza una macchina
n1-standard-8con 8 CPU. Di conseguenza, l'utilizzo della CPU raggiunge il 50%. - A questo punto, la scalabilità automatica aggiunge capacità: viene aggiunto un nuovo nodo di servizio con un'altra replica della GPU. L'utilizzo della prima replica della GPU diminuisce e l'utilizzo della seconda replica della GPU aumenta.
- La latenza diminuisce quando la nuova replica inizia a fornire le previsioni, convergendo a circa 200 millisecondi.
- L'utilizzo della CPU converrebbe a circa il 250% per ogni replica, ovvero
utilizzando 2,5 CPU su 8. Questo valore indica che puoi utilizzare una macchina
n1-standard-4anziché unan1-standard-8.
Pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo documento, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Se vuoi mantenere il progetto Google Cloud, ma eliminare le risorse che hai creato, elimina il cluster Google Kubernetes Engine e il modello di AI Platform di cui è stato eseguito il deployment.
Passaggi successivi
- Scopri di più su MLOps e sulle pipeline di distribuzione continua e automazione nel machine learning.
- Scopri di più sull'architettura per MLOps utilizzando TFX, Kubeflow Pipelines e Cloud Build.
- Per altre architetture di riferimento, diagrammi e best practice, visita il Centro architetture di Google Cloud.