Vertex AI Agent Engine, que forma parte de la plataforma Vertex AI, es un conjunto de servicios que permite a los desarrolladores desplegar, gestionar y escalar agentes de IA en producción. Agent Engine se encarga de la infraestructura para escalar los agentes en producción, de forma que puedas centrarte en crear aplicaciones. Vertex AI Agent Engine ofrece los siguientes servicios, que puedes usar de forma individual o combinada:
Tiempo de ejecución:
- Despliega y escala agentes con un entorno de ejecución gestionado y funciones de gestión integrales.
- Personaliza la imagen del contenedor del agente con secuencias de comandos de instalación en tiempo de compilación para las dependencias del sistema.
- Usa funciones de seguridad, como el cumplimiento de VPC-SC y la configuración de la autenticación y la gestión de identidades y accesos.
- Acceder a modelos y herramientas como llamada de función.
- Despliega agentes creados con diferentes frameworks de Python y el protocolo abierto Agent2Agent.
- Comprende el comportamiento del agente con Google Cloud Trace (compatible con OpenTelemetry), Cloud Monitoring y Cloud Logging.
Calidad y evaluación (vista previa): evalúa la calidad de los agentes con el servicio de evaluación de IA generativa integrado y optimiza los agentes con las ejecuciones de entrenamiento del modelo de Gemini.
Tienda de ejemplos (vista previa): almacena y recupera de forma dinámica ejemplos de pocos disparos para mejorar el rendimiento del agente.
Sesiones (vista previa): Agent Engine Sessions te permite almacenar interacciones individuales entre usuarios y agentes, lo que proporciona fuentes definitivas para el contexto de la conversación.
Banco de memoria (vista previa): el banco de memoria de Agent Engine te permite almacenar y recuperar información de las sesiones para personalizar las interacciones de los agentes.
Ejecución de código (Vista previa): la ejecución de código de Agent Engine permite que tu agente ejecute código en un entorno de pruebas seguro, aislado y gestionado.
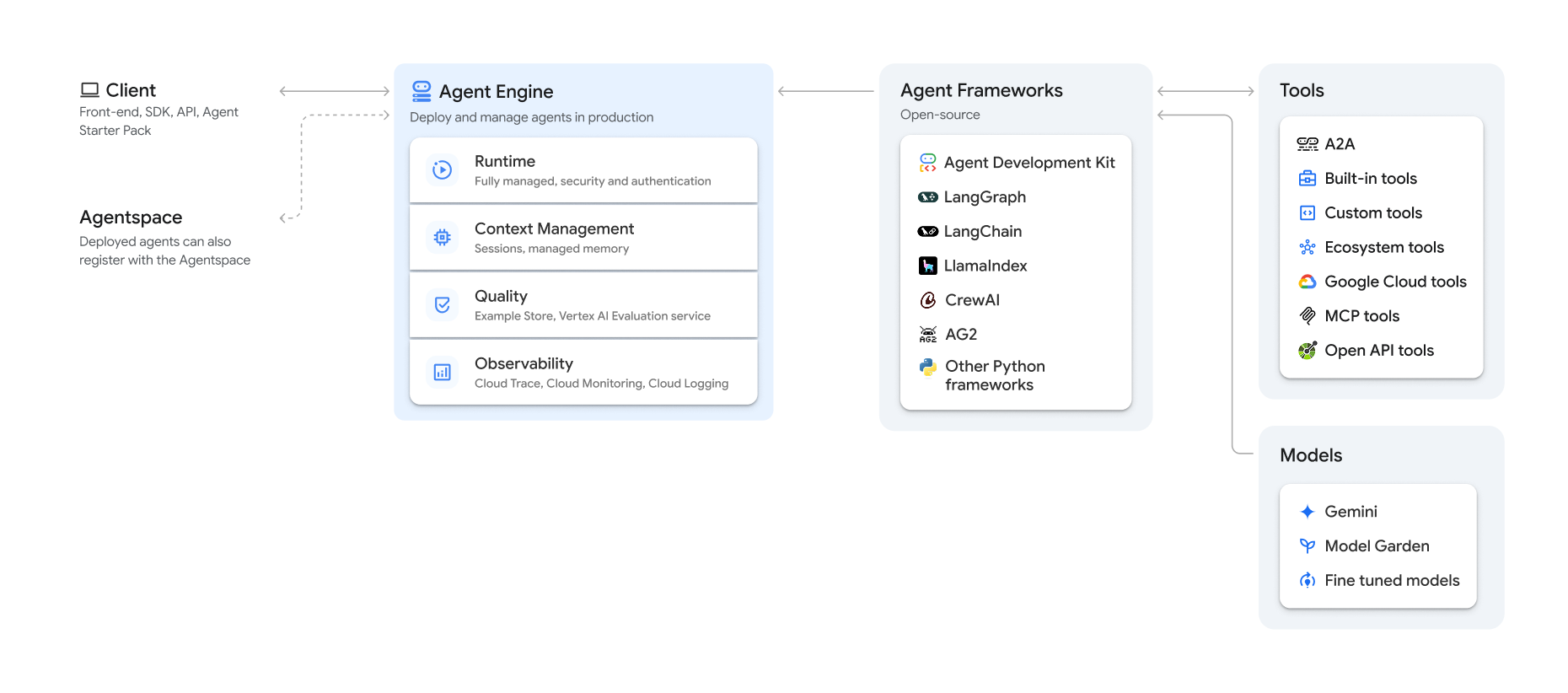
Vertex AI Agent Engine forma parte de Vertex AI Agent Builder, un conjunto de funciones para descubrir, crear y desplegar agentes de IA.
Crear y desplegar en Vertex AI Agent Engine
Nota: Para disfrutar de una experiencia de desarrollo y despliegue basada en IDE optimizada con Vertex AI Agent Engine, consulta el paquete de inicio de agente. Proporciona plantillas listas para usar, una interfaz de usuario integrada para experimentar y simplifica la implementación, las operaciones, la evaluación, la personalización y la observabilidad.
El flujo de trabajo para crear un agente en Vertex AI Agent Engine es el siguiente:
| Pasos | Descripción |
|---|---|
| 1. Configurar el entorno | Configura tu proyecto de Google e instala la versión más reciente del SDK de Vertex AI para Python. |
| 2. Desarrollar un agente | Desarrollar un agente que se pueda desplegar en Vertex AI Agent Engine. |
| 3. Desplegar el agente | Despliega el agente en el entorno de ejecución gestionado de Vertex AI Agent Engine. |
| 4. Usar el agente | Consulta el agente enviando una solicitud a la API. |
| 5. Gestionar el agente desplegado | Gestiona y elimina los agentes que hayas desplegado en Vertex AI Agent Engine. |
Los pasos se ilustran en el siguiente diagrama:

Frameworks admitidos
En la siguiente tabla se describe el nivel de asistencia que ofrece Vertex AI Agent Engine para varios frameworks de agentes:
| Nivel de asistencia | Frameworks de agentes |
|---|---|
| Plantilla personalizada: puedes adaptar una plantilla personalizada para que admita el despliegue en Vertex AI Agent Engine desde tu framework. | CrewAI y frameworks personalizados |
| Integración del SDK de Vertex AI: Vertex AI Agent Engine proporciona plantillas gestionadas por framework en el SDK de Vertex AI y en la documentación. | AG2, LlamaIndex |
| Integración completa: las funciones se integran para que funcionen en todo el framework, Vertex AI Agent Engine y el ecosistema Google Cloud en general. | Agent Development Kit (ADK), LangChain y LangGraph |
Desplegar en producción con el paquete inicial de agentes
El paquete inicial de agentes es una colección de plantillas de agentes de IA generativa listas para la producción creadas para Vertex AI Agent Engine. El paquete de inicio para agentes incluye lo siguiente:
- Plantillas de agentes predefinidas: ReAct, RAG, multiagente y otras plantillas.
- Zona de pruebas interactiva: prueba tu agente e interactúa con él.
- Infraestructura automatizada: usa Terraform para simplificar la gestión de recursos.
- Flujos de procesamiento de CI/CD: flujos de trabajo de despliegue automatizados que aprovechan Cloud Build.
- Observabilidad: compatibilidad integrada con Cloud Trace y Cloud Logging.
Para empezar, consulta la guía de inicio rápido.
Casos prácticos
Para obtener información sobre Vertex AI Agent Engine con ejemplos de extremo a extremo, consulta los siguientes recursos:
| Caso práctico | Descripción | Enlaces |
|---|---|---|
| Crear agentes conectándose a APIs públicas | Convertir entre monedas. Crea una función que se conecte a una aplicación de cambio de divisas para que el modelo pueda proporcionar respuestas precisas a consultas como "¿Cuál es el tipo de cambio de euros a dólares hoy?". |
Notebook del SDK de Vertex AI para Python: introducción a la creación y la implementación de un agente con Vertex AI Agent Engine |
| Diseñar un proyecto de energía solar comunitaria. Identifica posibles ubicaciones, busca las oficinas gubernamentales y los proveedores pertinentes, y consulta imágenes de satélite y el potencial solar de las regiones y los edificios para encontrar la ubicación óptima donde instalar tus paneles solares. |
Notebook del SDK de Vertex AI para Python: creación e implementación de un agente de la API de Google Maps con Vertex AI Agent Engine | |
| Crear agentes conectándose a bases de datos | Integración con AlloyDB y Cloud SQL para PostgreSQL. | Entrada de blog: presentamos LangChain en Vertex AI para AlloyDB y Cloud SQL para PostgreSQL Notebook del SDK de Vertex AI para Python: implementar una aplicación RAG con Cloud SQL para PostgreSQL en Vertex AI Agent Engine Notebook del SDK de Vertex AI para Python: implementar una aplicación RAG con AlloyDB para PostgreSQL en Vertex AI Agent Engine |
| Crea agentes con herramientas que accedan a los datos de tu base de datos. | Notebook del SDK de Vertex AI para Python: desplegar un agente con Vertex AI Agent Engine y MCP Toolbox for Databases | |
| Consulta y comprende almacenes de datos estructurados usando lenguaje natural. | Notebook del SDK de Vertex AI para Python: crear un agente de búsqueda conversacional con Vertex AI Agent Engine y RAG en Vertex AI Search | |
| Consultar y comprender bases de datos de grafos con lenguaje natural | Entrada de blog: GenAI GraphRAG y agentes de IA con Vertex AI Agent Engine, LangChain y Neo4j | |
| Consultar y comprender almacenes de vectores con lenguaje natural | Entrada de blog: Simplifica la función de RAG de la IA generativa con MongoDB Atlas y Vertex AI Agent Engine | |
| Crear agentes con Agent Development Kit | Crea y despliega agentes con Agent Development Kit. | Agent Development Kit: desplegar en Vertex AI Agent Engine |
| Gestiona el contexto con las sesiones de Vertex AI Agent Engine y Memory Bank en el modo Exprés de Vertex AI sin facturación. | Agent Development Kit: sesiones de Vertex AI Agent Engine y Memory Bank en el modo exprés de Vertex AI. | |
| Crear agentes con frameworks de código abierto | Crea y despliega agentes con el framework de código abierto OneTwo. | Entrada de blog: OneTwo y Vertex AI Agent Engine: explorando el desarrollo avanzado de agentes de IA en Google Cloud |
| Crea y despliega agentes con el framework de código abierto LangGraph. | Notebook del SDK de Vertex AI para Python: crear e implementar una aplicación LangGraph con Vertex AI Agent Engine | |
| Depurar y optimizar agentes | Crea y monitoriza agentes con OpenTelemetry y Cloud Trace. | Notebook del SDK de Vertex AI para Python: depuración y optimización de agentes. Guía para el seguimiento en Vertex AI Agent Engine |
| Crear sistemas multiagente con el protocolo A2A (vista previa) | Crea agentes interoperables que se comuniquen y colaboren con otros agentes independientemente de su framework. | Para obtener más información, consulta la documentación del protocolo A2A. |
Seguridad empresarial
Vertex AI Agent Engine admite varias funciones para ayudarte a cumplir los requisitos de seguridad de las empresas, seguir las políticas de seguridad de tu organización y aplicar las prácticas recomendadas de seguridad. Se admiten las siguientes funciones:
Controles de Servicio de VPC: Vertex AI Agent Engine admite Controles de Servicio de VPC para reforzar la seguridad de los datos y mitigar los riesgos de filtración externa de datos. Cuando se configura Controles de Servicio de VPC, el agente implementado mantiene el acceso seguro a las APIs y los servicios de Google, como la API de BigQuery, la API de administrador de Cloud SQL y la API de Vertex AI, lo que garantiza un funcionamiento fluido dentro del perímetro definido. Lo más importante es que los controles de servicio de VPC bloquean de forma eficaz todo el acceso a Internet público, lo que limita el movimiento de datos a los límites de tu red autorizada y mejora significativamente la postura de seguridad de tu empresa.
Interfaz de Private Service Connect: en el caso de Vertex AI Agent Engine Runtime, PSC-I permite que tus agentes interactúen con servicios alojados de forma privada en la VPC de un usuario. Para obtener más información, consulta Usar la interfaz de Private Service Connect con Vertex AI Agent Engine.
Claves de cifrado gestionadas por el cliente (CMEK): Vertex AI Agent Engine admite CMEK para proteger tus datos con tus propias claves de cifrado, lo que te da la propiedad y el control total de las claves que protegen tus datos en reposo en Google Cloud. Para obtener más información, consulta CMEK de Agent Engine.
Residencia de datos (DRZ): Vertex AI Agent Engine admite la residencia de datos (DRZ) para asegurarse de que todos los datos en reposo y en uso se almacenan en la región especificada.
HIPAA como parte de Vertex AI Platform, Vertex AI Agent Engine admite cargas de trabajo de conformidad con la HIPAA.
Transparencia de acceso: esta función te proporciona registros donde constan las acciones que lleva a cabo el personal de Google cuando accede a tu contenido. Para obtener más información sobre cómo habilitar Transparencia de acceso en Vertex AI Agent Engine, consulta el artículo Transparencia de acceso en Vertex AI.
En la siguiente tabla se muestra qué funciones de seguridad empresarial se admiten en cada servicio de Agent Engine:
| Función de seguridad | Tiempo de ejecución | Sesiones | Memory Bank | Tienda de ejemplo | Ejecución de código |
|---|---|---|---|---|---|
| Controles de Servicio de VPC | Sí | Sí | Sí | No | No |
| Claves de encriptado gestionadas por el cliente | Sí | Sí | Sí | No | No |
| Residencia de datos en reposo | Sí | Sí | Sí | No | No |
| Residencia de datos (DRZ) en uso | No | Sí | Sí* | No | Sí |
| HIPAA | Sí | Sí | Sí | Sí | No |
| Transparencia de acceso | Sí | Sí | Sí | No | No |
* Solo cuando se usa un endpoint regional de Gemini.
Regiones disponibles
Vertex AI Agent Engine Runtime, Agent Engine Sessions y Vertex AI Agent Engine Memory Bank se admiten en las siguientes regiones:
| Región | Ubicación | Versiones compatibles |
|---|---|---|
us-central1 |
Iowa | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
us-east4 |
Norte de Virginia | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
us-west1 |
Oregón | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
europe-west1 |
Bélgica | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
europe-west2 |
Londres | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
europe-west3 |
Fráncfort | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
europe-west4 |
Países Bajos | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
europe-southwest1 |
Madrid | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
asia-east1 |
Taiwán | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
asia-northeast1 |
Tokio | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
asia-south1 |
Bombay | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
asia-southeast1 |
Singapur | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
australia-southeast2 |
Melbourne | v1 es compatible con las funciones de GA. v1beta1 se admite en las funciones de vista previa. |
En el caso de Ejecución de código de Agent Engine (vista previa), se admiten las siguientes regiones.
| Región | Ubicación | Versiones compatibles |
|---|---|---|
us-central1 |
Iowa | Se admite la versión v1beta1. |
Cuota
Se aplican los siguientes límites a Vertex AI Agent Engine en cada región de un proyecto determinado:| Descripción | Límite |
|---|---|
| Crear, eliminar o actualizar Vertex AI Agent Engine por minuto | 10 |
| Crear, eliminar o actualizar sesiones de Vertex AI Agent Engine por minuto | 100 |
Query o StreamQuery Vertex AI Agent Engine por minuto |
90 |
| Añadir eventos a las sesiones de Vertex AI Agent Engine por minuto | 300 |
| Número máximo de recursos de Vertex AI Agent Engine | 100 |
| Crear, eliminar o actualizar recursos de memoria de Vertex AI Agent Engine por minuto | 100 |
| Obtener, enumerar o recuperar datos de Memory Bank de Vertex AI Agent Engine por minuto | 300 |
| Solicitudes de ejecución por minuto del entorno de pruebas (ejecución de código) | 1000 |
| Entidades de entorno aislado (ejecución de código) por región | 1000 |
Solicitudes POST de agentes de A2A, como sendMessage y cancelTask por minuto |
60 |
Solicitudes get de agente de A2A, como getTask y getCard, por minuto |
600 |
Conexiones bidireccionales simultáneas en directo mediante la API BidiStreamQuery por minuto |
10 |
Precios
Para obtener información sobre los precios de Agent Engine Runtime, consulta los precios de Vertex AI.
Migración al SDK basado en el cliente
El módulo agent_engines del SDK de Vertex AI para Python se está refactorizando para que tenga un diseño basado en clientes por los siguientes motivos principales:
- Para que coincida con el ADK de Google y el SDK de IA generativa de Google en representaciones de tipos canónicos. De esta forma, se garantiza una forma coherente y estandarizada de representar los tipos de datos en diferentes SDKs, lo que simplifica la interoperabilidad y reduce la sobrecarga de conversión.
- Para definir el ámbito de los parámetros Google Cloud a nivel de cliente en aplicaciones de varios proyectos y varias ubicaciones. De esta forma, una aplicación puede gestionar las interacciones con recursos de diferentes Google Cloud proyectos y ubicaciones geográficas configurando cada instancia de cliente con sus ajustes de proyecto y ubicación específicos.
- Para mejorar la visibilidad y la cohesión de los servicios de Vertex AI Agent Engine