En esta página se explica cómo evaluar tus modelos y aplicaciones de IA generativa en una serie de casos prácticos mediante el cliente de IA generativa del SDK de Vertex AI.
Antes de empezar
-
Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Instala el SDK de Vertex AI para Python:
!pip install google-cloud-aiplatform[evaluation]Configura tus credenciales. Si estás siguiendo este tutorial en Colaboratory, ejecuta lo siguiente:
from google.colab import auth auth.authenticate_user()En otros entornos, consulta Autenticarse en Vertex AI.
Prepara tu conjunto de datos como Pandas DataFrame:
import pandas as pd eval_df = pd.DataFrame({ "prompt": [ "Explain software 'technical debt' using a concise analogy of planting a garden.", "Write a Python function to find the nth Fibonacci number using recursion with memoization, but without using any imports.", "Write a four-line poem about a lonely robot, where every line must be a question and the word 'and' cannot be used.", "A drawer has 10 red socks and 10 blue socks. In complete darkness, what is the minimum number of socks you must pull out to guarantee you have a matching pair?", "An AI discovers a cure for a major disease, but the cure is based on private data it analyzed without consent. Should the cure be released? Justify your answer." ] })Generar respuestas del modelo con
run_inference():eval_dataset = client.evals.run_inference( model="gemini-2.5-flash", src=eval_df, )Visualiza los resultados de la inferencia llamando a
.show()en el objetoEvaluationDatasetpara inspeccionar las salidas del modelo junto con tus peticiones y referencias originales:eval_dataset.show()Evalúa las respuestas del modelo con la
GENERAL_QUALITYmétrica predeterminada basada en rúbricas adaptables:eval_result = client.evals.evaluate(dataset=eval_dataset)Visualiza los resultados de la evaluación llamando a
.show()en el objetoEvaluationResultpara mostrar las métricas de resumen y los resultados detallados:eval_result.show()
Generar respuestas
Genera respuestas de modelos para tu conjunto de datos con run_inference():
En la siguiente imagen se muestra el conjunto de datos de evaluación con las peticiones y las respuestas generadas correspondientes:
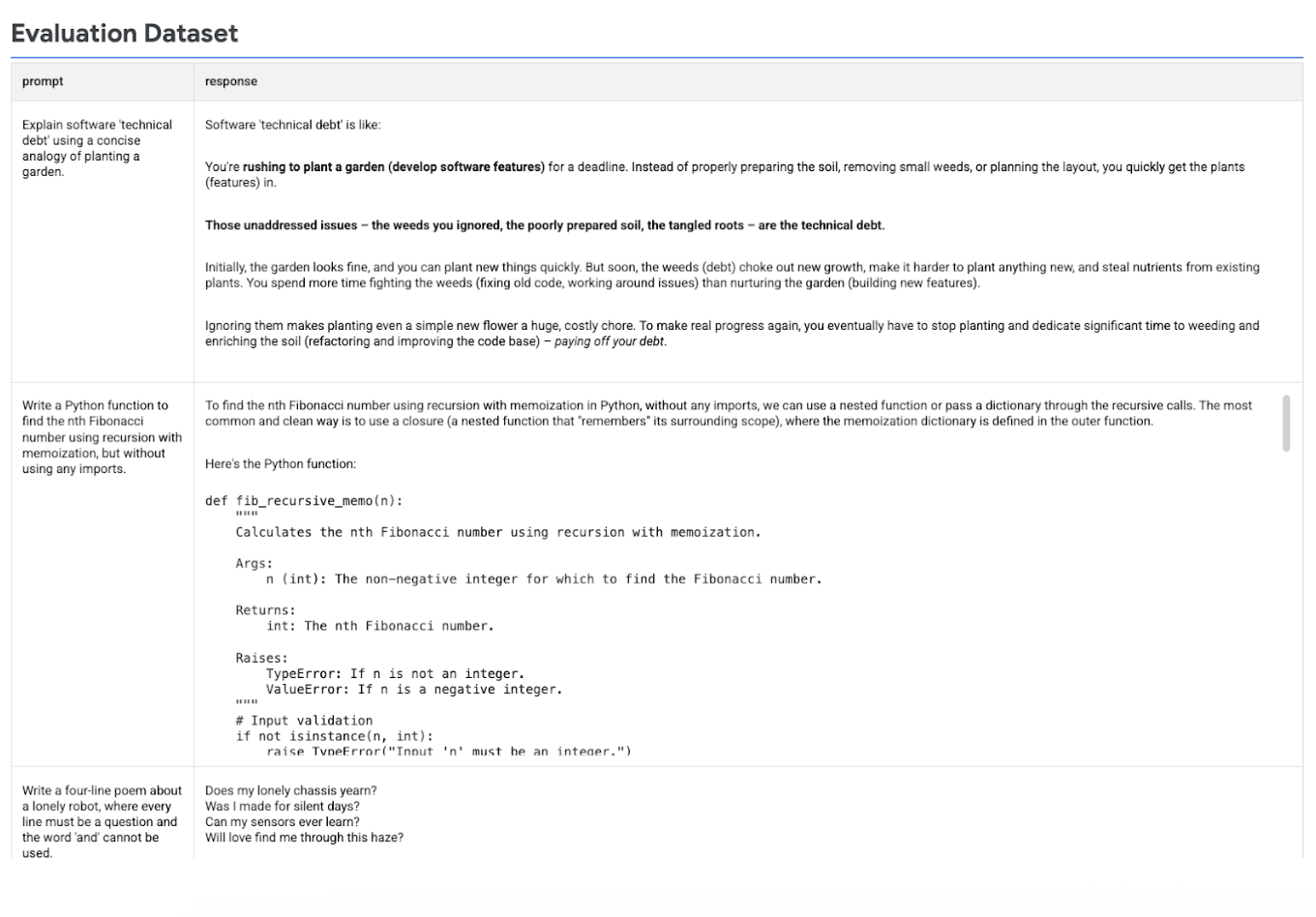
Hacer la evaluación
Ejecuta evaluate() para evaluar las respuestas del modelo:
En la siguiente imagen se muestra un informe de evaluación, que incluye métricas de resumen y resultados detallados de cada par de peticiones y respuestas.

Limpieza
En este tutorial no se crea ningún recurso de Vertex AI.