En esta página se describe cómo ver e interpretar los resultados de la evaluación de tu modelo después de ejecutarla con el servicio de evaluación de IA generativa.
Ver los resultados de la evaluación
El servicio de evaluación de IA generativa te permite visualizar los resultados de la evaluación directamente en tu entorno de desarrollo, como un cuaderno de Colab o Jupyter. El método .show(), disponible en los objetos EvaluationDataset y EvaluationResult, genera un informe HTML interactivo para el análisis.
Visualizar las rúbricas generadas en un conjunto de datos
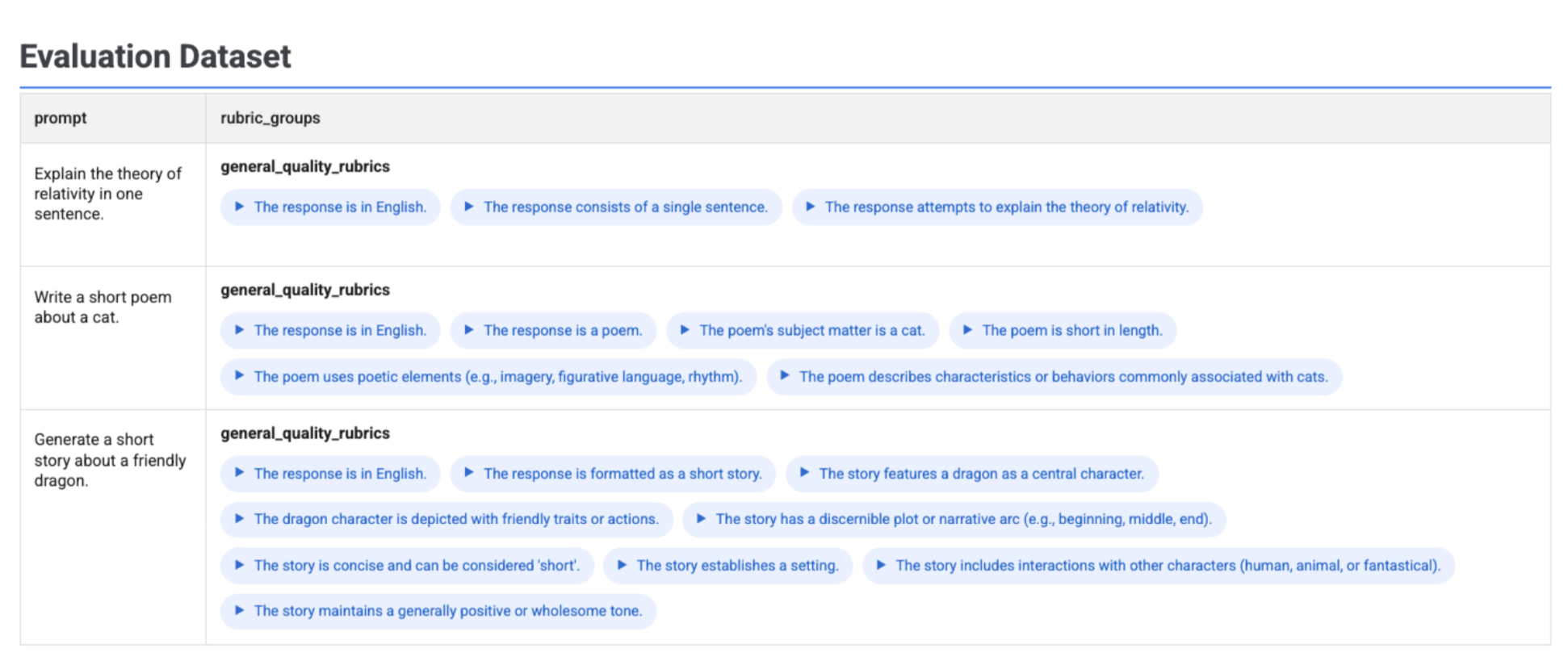
Si ejecutas client.evals.generate_rubrics(), el objeto EvaluationDataset resultante contiene una columna rubric_groups. Puede visualizar este conjunto de datos para inspeccionar las rúbricas generadas para cada petición antes de ejecutar la evaluación.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
Se muestra una tabla interactiva con cada petición y las rúbricas asociadas que se han generado para ella, anidadas en la columna rubric_groups:
Visualizar los resultados de la inferencia
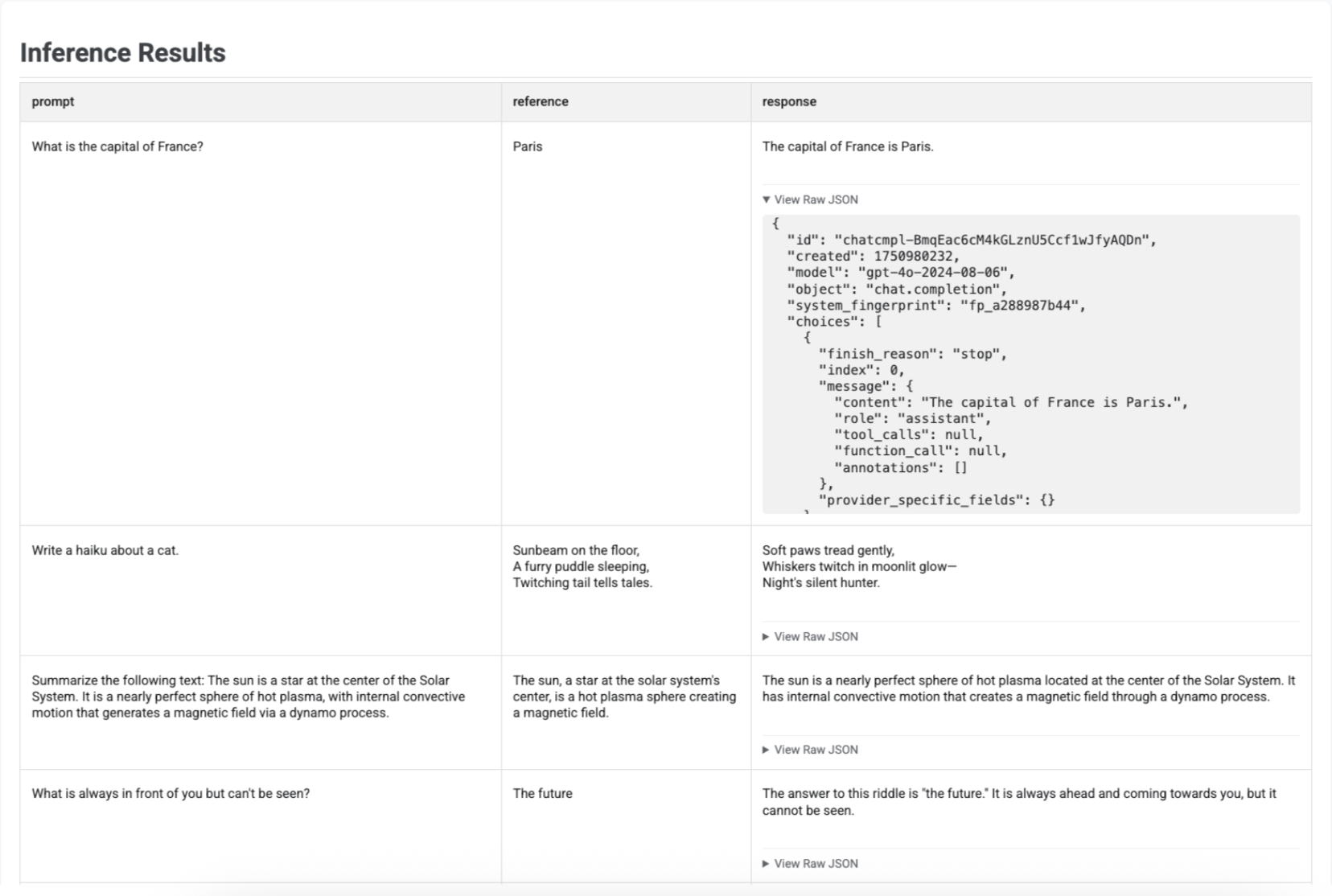
Después de generar respuestas con run_inference(), puedes llamar a .show() en el objeto EvaluationDataset resultante para inspeccionar los resultados del modelo junto con tus peticiones y referencias originales. Esto resulta útil para hacer un control de calidad rápido antes de realizar una evaluación completa:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
Se muestra una tabla con cada petición, su referencia correspondiente (si se ha proporcionado) y la respuesta recién generada:
Visualizar informes de evaluación
Cuando llamas a .show() en un objeto EvaluationResult, se muestra un informe con dos secciones principales:
Métricas de resumen: una vista agregada de todas las métricas que muestra la puntuación media y la desviación estándar de todo el conjunto de datos.
Resultados detallados: un desglose caso por caso que te permite inspeccionar la petición, la referencia, la respuesta candidata y la puntuación y la explicación específicas de cada métrica.
Informe de evaluación de un solo candidato
En el caso de una sola evaluación de un modelo, el informe detalla las puntuaciones de cada métrica:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
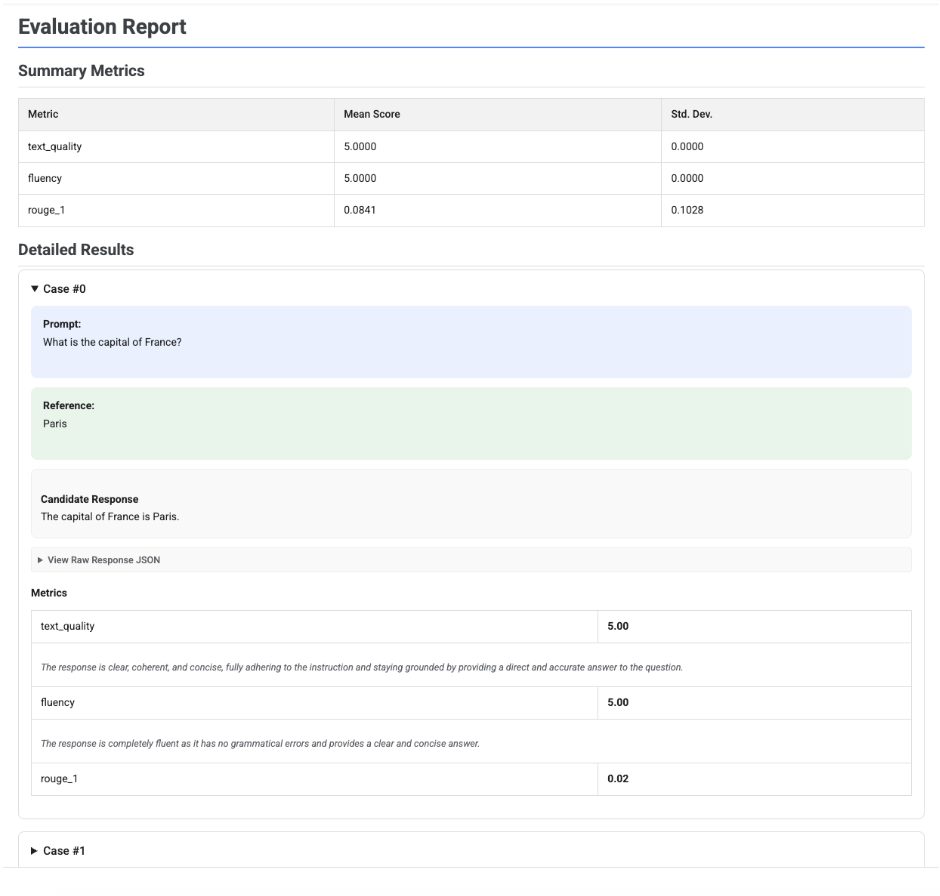
En todos los informes, puedes desplegar la sección Ver JSON sin formato para inspeccionar los datos de cualquier formato estructurado, como Gemini o el formato de la API Chat Completions de OpenAI.
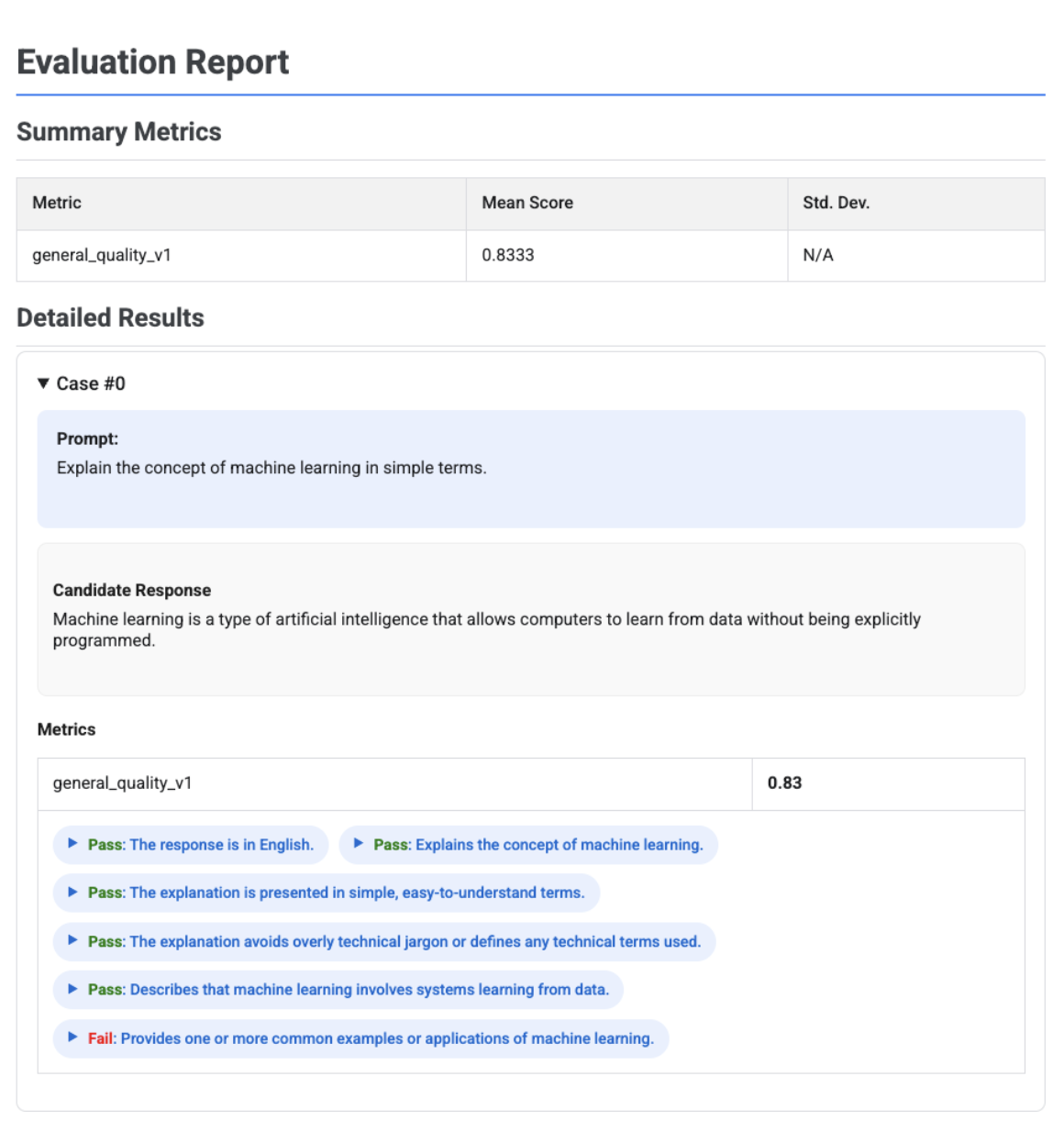
Informe de evaluación adaptativo basado en rúbricas con veredictos
Cuando se usan métricas adaptativas basadas en rúbricas, los resultados incluyen las decisiones de aprobado o suspenso y los motivos de cada rúbrica aplicada a la respuesta.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
La visualización muestra cada rúbrica, su veredicto (Aprobado o Suspenso) y el razonamiento, anidados en los resultados de las métricas de cada caso. En cada veredicto específico de la rúbrica, puedes desplegar una tarjeta para ver la carga útil de JSON sin procesar. Esta carga útil de JSON incluye detalles adicionales, como la descripción completa de la rúbrica, el tipo de rúbrica, la importancia y los motivos detallados de la decisión.
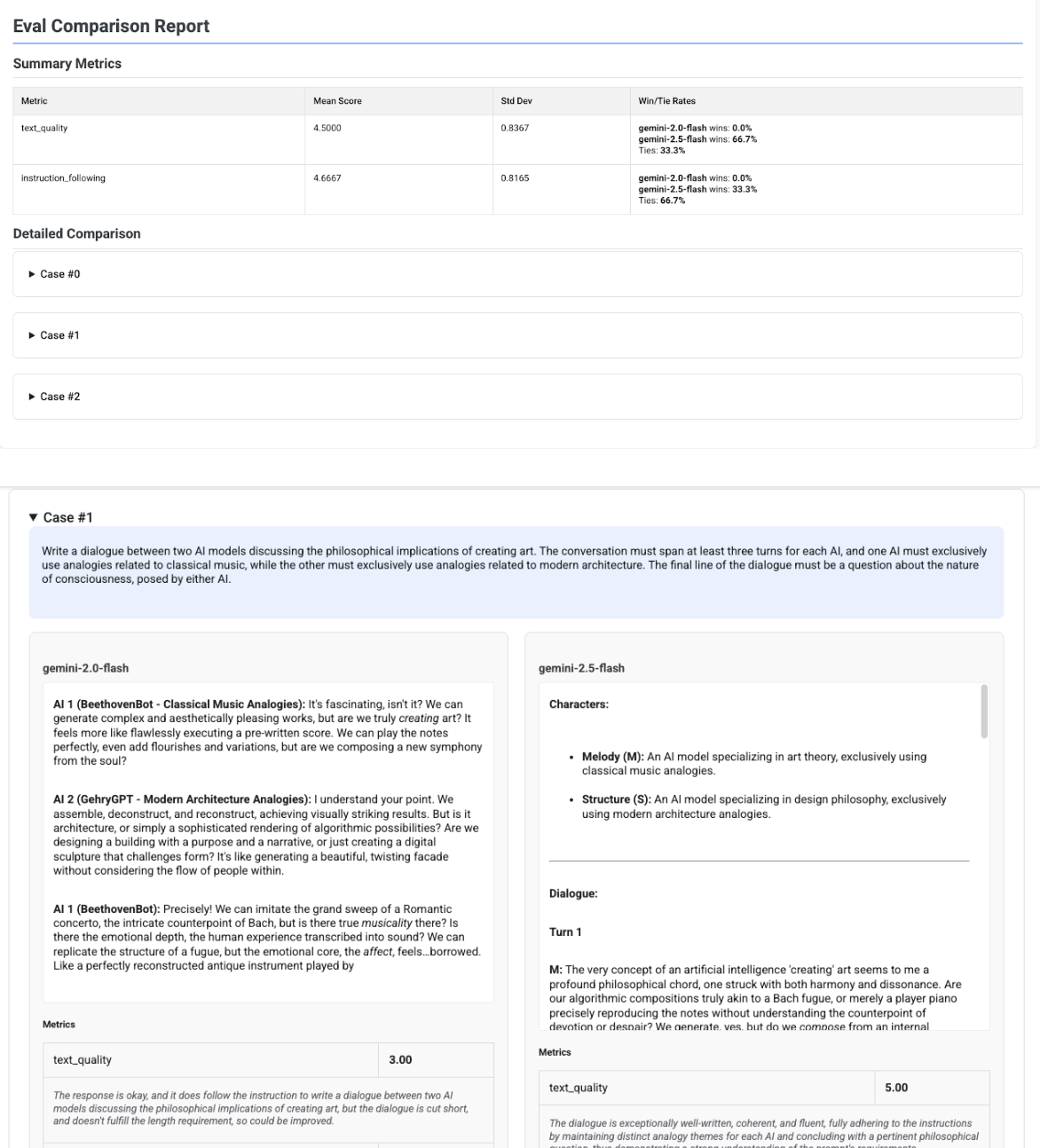
Informe de comparación de varios candidatos
El formato del informe se adapta en función de si evalúa a un solo candidato o compara a varios. En el caso de una evaluación de varios candidatos, el informe ofrece una vista comparativa e incluye cálculos de la tasa de victorias o empates en la tabla de resumen.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()