Questo documento spiega come monitorare il comportamento, l'integrità e le prestazioni dei modelli completamente gestiti in Vertex AI. Descrive come utilizzare la dashboard di osservabilità del modello predefinita per ottenere informazioni sull'utilizzo del modello, identificare problemi di latenza e risolvere gli errori.
Imparerai a:
- Accedere alla dashboard di osservabilità del modello e interpretarla.
- Visualizza le metriche di monitoraggio disponibili.
- Monitora il traffico dell'endpoint del modello utilizzando Metrics Explorer.
Accedere alla dashboard di osservabilità del modello e interpretarla
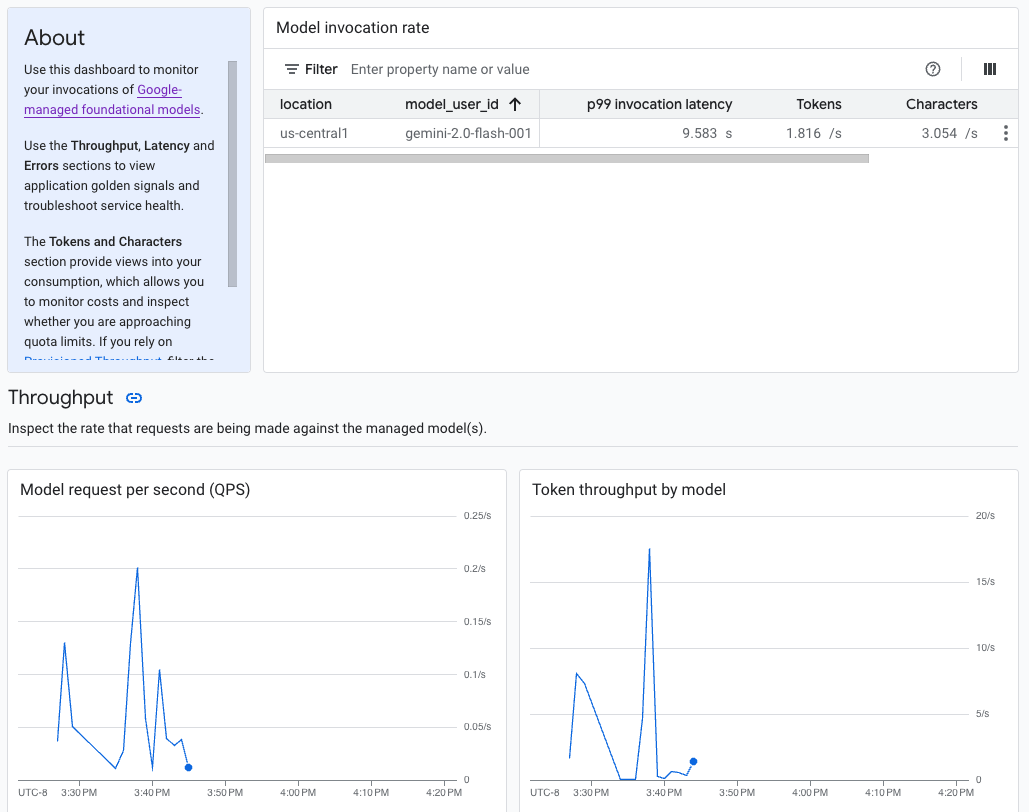
L'AI generativa su Vertex AI fornisce un dashboard di osservabilità del modello predefinito per visualizzare il comportamento, l'integrità e le prestazioni dei modelli completamente gestiti. I modelli completamente gestiti, noti anche come Model as a Service (MaaS), sono forniti da Google e includono i modelli Gemini di Google e i modelli dei partner con endpoint gestiti. Le metriche dei modelli self-hosted non sono incluse nella dashboard.
L'IA generativa su Vertex AI raccoglie e segnala automaticamente l'attività dei modelli MaaS per aiutarti a risolvere rapidamente i problemi di latenza e monitorare la capacità.
Caso d'uso
In qualità di sviluppatore di applicazioni, puoi visualizzare in che modo gli utenti interagiscono con i modelli che hai esposto. Ad esempio, puoi visualizzare l'andamento nel tempo dell'utilizzo del modello (richieste del modello al secondo) e dell'intensità di calcolo dei prompt degli utenti (latenze di invocazione del modello). Di conseguenza, poiché queste metriche sono correlate all'utilizzo del modello, puoi anche stimare i costi di esecuzione di ciascun modello.
Quando si verifica un problema, puoi risolverlo rapidamente dalla dashboard. Puoi verificare se i modelli rispondono in modo affidabile e tempestivo visualizzando i tassi di errore dell'API, le latenze del primo token e la velocità effettiva dei token.
Metriche di monitoraggio disponibili
La dashboard di osservabilità del modello mostra un sottoinsieme di metriche raccolte da Cloud Monitoring, come la richiesta di modello al secondo (QPS), il throughput dei token e le latenze del primo token. Visualizza la dashboard per vedere tutte le metriche disponibili.
Limitazioni
Vertex AI acquisisce le metriche della dashboard solo per le chiamate API a un endpoint del modello. Google Cloud L'utilizzo della console, ad esempio le metriche di Vertex AI Studio, non vengono aggiunte alla dashboard.
Visualizzare la dashboard
- Nella sezione Vertex AI della console Google Cloud , vai alla pagina Dashboard.
Vai a Vertex AI 1. Nella dashboard, in Osservabilità del modello, fai clic su Mostra tutte le metriche per visualizzare la dashboard di osservabilità del modello nella console Google Cloud Observability.
Per visualizzare le metriche per un modello specifico o in una località particolare, imposta uno o più filtri nella parte superiore della pagina della dashboard.
Per le descrizioni di ogni metrica, consulta la sezione "
aiplatform" nella pagina Google Cloud Metriche.
Monitorare il traffico dell'endpoint del modello
Segui queste istruzioni per monitorare il traffico verso l'endpoint in Metrics Explorere.
Nella console Google Cloud , vai alla pagina Esplora metriche.
Seleziona il progetto per cui vuoi visualizzare le metriche.
Nel menu a discesa Metrica, fai clic su Seleziona una metrica.
Nella barra di ricerca Filtra in base al nome della risorsa o della metrica, inserisci
Vertex AI Endpoint.Seleziona la categoria di metriche Endpoint Vertex AI > Previsione. In Metriche attive, seleziona una delle seguenti metriche:
prediction/online/error_countprediction/online/prediction_countprediction/online/prediction_latenciesprediction/online/response_count
Fai clic su Applica. Per aggiungere più di una metrica, fai clic su Aggiungi query.
Puoi filtrare o aggregare le metriche utilizzando i seguenti menu a discesa:
Per selezionare e visualizzare un sottoinsieme dei dati in base a criteri specifici, utilizza il menu a discesa Filtro. Ad esempio, per filtrare in base al modello
gemini-2.0-flash-001, utilizzaendpoint_id = gemini-2p0-flash-001(tieni presente che.nella versione del modello viene sostituito dap).Per combinare più punti dati in un unico valore e visualizzare una visualizzazione riepilogativa delle metriche, utilizza il menu a discesa Aggregazione. Ad esempio, puoi aggregare la Somma di
response_code.
(Facoltativo) Puoi configurare avvisi per l'endpoint. Per saperne di più, consulta Gestire i criteri di avviso.
Per visualizzare le metriche che aggiungi al progetto utilizzando una dashboard, consulta la panoramica delle dashboard.
Passaggi successivi
- Per scoprire come creare avvisi per la dashboard, consulta la panoramica degli avvisi.
- Per informazioni sulla conservazione dei dati delle metriche, consulta la sezione Quote e limiti di Monitoring.
- Per scoprire di più sui dati inattivi, consulta l'articolo Protezione dei dati inattivi.
- Per visualizzare un elenco di tutte le metriche raccolte da Cloud Monitoring, consulta la sezione "
aiplatform" nella pagina Google Cloud Metriche.