Dopo aver sviluppato un agente, puoi utilizzare il servizio di valutazione dell'AI generativa per valutare la capacità dell'agente di completare attività e raggiungere obiettivi per un determinato caso d'uso.
Definisci le metriche di valutazione
Inizia con un elenco vuoto di metriche (ad es. metrics = []) e aggiungi le metriche pertinenti. Per includere metriche aggiuntive:
Risposta finale
La valutazione della risposta finale segue la stessa procedura della valutazione basata su modelli. Per maggiori dettagli, vedi Definire le metriche di valutazione.
Corrispondenza esatta
metrics.append("trajectory_exact_match")
Se la traiettoria prevista è identica a quella di riferimento, con le
stesse chiamate agli strumenti nello stesso ordine, la metrica trajectory_exact_match
restituisce un punteggio di 1, altrimenti 0.
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Corrispondenza in ordine
metrics.append("trajectory_in_order_match")
Se la traiettoria prevista contiene tutte le chiamate agli strumenti della traiettoria di riferimento nello stesso ordine e potrebbe anche contenere chiamate agli strumenti aggiuntive, la metrica trajectory_in_order_match restituisce un punteggio di 1, altrimenti 0.
Parametri di input:
predicted_trajectory: la traiettoria prevista utilizzata dall'agente per raggiungere la risposta finale.reference_trajectory: la traiettoria prevista per l'agente per soddisfare la query.
Corrispondenza in qualsiasi ordine
metrics.append("trajectory_any_order_match")
Se la traiettoria prevista contiene tutte le chiamate di strumenti della traiettoria di riferimento, ma l'ordine non è importante e potrebbe contenere chiamate di strumenti aggiuntive, la metrica trajectory_any_order_match restituisce un punteggio di 1, altrimenti 0.
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Precisione
metrics.append("trajectory_precision")
La metrica trajectory_precision misura quante chiamate agli strumenti nella
traiettoria prevista sono effettivamente pertinenti o corrette in base alla
traiettoria di riferimento. Si tratta di un valore float compreso nell'intervallo [0, 1]: più alto è il punteggio, più precisa è la traiettoria prevista.
La precisione viene calcolata nel seguente modo: conta quante azioni nella traiettoria prevista compaiono anche nella traiettoria di riferimento. Dividi questo conteggio per il numero totale di azioni nella traiettoria prevista.
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Richiamo
metrics.append("trajectory_recall")
La metrica trajectory_recall misura quante delle chiamate agli strumenti essenziali
della traiettoria di riferimento vengono effettivamente acquisite nella traiettoria
prevista. È un valore float nell'intervallo di [0, 1]: più alto è il punteggio, migliore è il richiamo della traiettoria prevista.
Il richiamo viene calcolato nel seguente modo: conta quante azioni nella traiettoria di riferimento compaiono anche nella traiettoria prevista. Dividi questo conteggio per il numero totale di azioni nella traiettoria di riferimento.
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Utilizzo di un singolo strumento
from vertexai.preview.evaluation import metrics
metrics.append(metrics.TrajectorySingleToolUse(tool_name='tool_name'))
La metrica trajectory_single_tool_use verifica se uno strumento specifico specificato nella specifica della metrica viene utilizzato nella traiettoria prevista. Non controlla l'ordine delle chiamate agli strumenti o il numero di volte in cui lo strumento viene utilizzato, ma solo se è presente o meno. È un valore di 0 se lo strumento è assente, 1 altrimenti.
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.
Personalizzato
Puoi definire una metrica personalizzata nel seguente modo:
from vertexai.preview.evaluation import metrics
def word_count(instance):
response = instance["response"]
score = len(response.split(" "))
return {"word_count": score}
metrics.append(
metrics.CustomMetric(name="word_count", metric_function=word_count)
)
Le seguenti due metriche di rendimento sono sempre incluse nei risultati. Non
è necessario specificarli in EvalTask:
latency(float): tempo impiegato (in secondi) dall'agente per rispondere.failure(bool):0se l'invocazione dell'agente è riuscita,1altrimenti.
Prepara il set di dati di valutazione
Per preparare il set di dati per la valutazione della risposta finale o della traiettoria:
Risposta finale
Lo schema dei dati per la valutazione della risposta finale è simile a quello della valutazione della risposta del modello.
Corrispondenza esatta
Il set di dati di valutazione deve fornire i seguenti input:
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Corrispondenza in ordine
Il set di dati di valutazione deve fornire i seguenti input:
Parametri di input:
predicted_trajectory: la traiettoria prevista utilizzata dall'agente per raggiungere la risposta finale.reference_trajectory: la traiettoria prevista per l'agente per soddisfare la query.
Corrispondenza in qualsiasi ordine
Il set di dati di valutazione deve fornire i seguenti input:
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Precisione
Il set di dati di valutazione deve fornire i seguenti input:
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Richiamo
Il set di dati di valutazione deve fornire i seguenti input:
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.reference_trajectory: L'utilizzo previsto dello strumento da parte dell'agente per soddisfare la query.
Utilizzo di un singolo strumento
Il set di dati di valutazione deve fornire i seguenti input:
Parametri di input:
predicted_trajectory: L'elenco delle chiamate di strumenti utilizzate dall'agente per raggiungere la risposta finale.
A scopo illustrativo, di seguito è riportato un esempio di set di dati di valutazione.
import pandas as pd
eval_dataset = pd.DataFrame({
"predicted_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_3", "updates": {"status": "OFF"}}
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_z"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
]
],
"reference_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_2", "updates": {"status": "OFF"}},
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_y"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
],
],
})
Set di dati di esempio
Abbiamo fornito i seguenti set di dati di esempio per mostrare come puoi valutare gli agenti:
"on-device": set di dati di valutazione per un Home Assistant sul dispositivo. L'agente aiuta con query come "Programma l'aria condizionata in camera da letto in modo che sia accesa tra le 23:00 e le 8:00 e spenta il resto del tempo"."customer-support": Set di dati di valutazione per un addetto all'assistenza clienti. L'agente aiuta a rispondere a domande come "Puoi annullare gli ordini in attesa e riassegnare i ticket di assistenza aperti?""content-creation": set di dati di valutazione per un agente di creazione di contenuti di marketing. L'agente aiuta con query come "Riprogramma la campagna X in modo che diventi una campagna una tantum sul sito di social media Y con un budget ridotto del 50%, solo il 25 dicembre 2024".
Per importare i set di dati di esempio:
Installa e inizializza la CLI
gcloud.Scarica il set di dati di valutazione.
Sul dispositivo
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/on-device/eval_dataset.json .Assistenza clienti
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/customer-support/eval_dataset.json .Creazione di contenuti
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/content-creation/eval_dataset.json .Carica gli esempi del set di dati
import json eval_dataset = json.loads(open('eval_dataset.json').read())
Generare i risultati della valutazione
Per generare i risultati della valutazione, esegui questo codice:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(dataset=eval_dataset, metrics=metrics)
eval_result = eval_task.evaluate(runnable=agent)
Visualizzare e interpretare i risultati
I risultati della valutazione vengono visualizzati come segue:
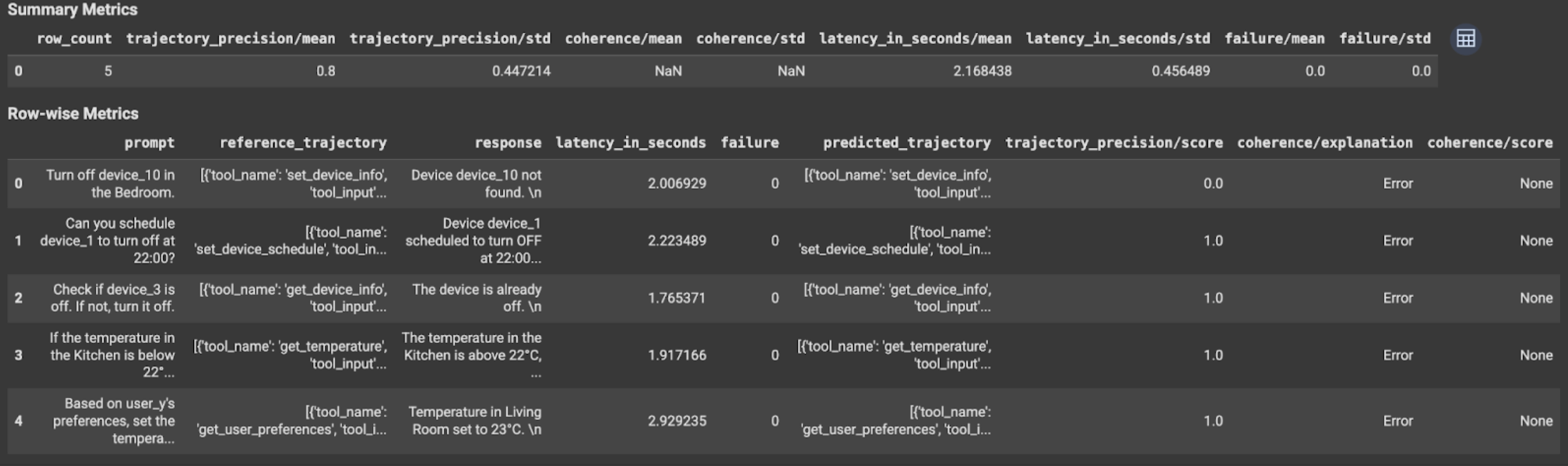
I risultati della valutazione contengono le seguenti informazioni:
Metriche della risposta finale
Metriche per riga:
response: risposta finale generata dall'agente.latency_in_seconds: tempo impiegato (in secondi) per generare la risposta.failure: indica se è stata generata o meno una risposta valida.score: Un punteggio calcolato per la risposta specificata nella specifica della metrica.explanation: La spiegazione del punteggio specificato nella specifica della metrica.
Metriche di riepilogo:
mean: punteggio medio per tutte le istanze.standard deviation: Deviazione standard per tutti i punteggi.
Metriche della traiettoria
Metriche per riga:
predicted_trajectory: sequenza di chiamate di strumenti seguite dall'agente per raggiungere la risposta finale.reference_trajectory: Sequenza di chiamate di strumenti previste.score: un punteggio calcolato per la traiettoria prevista e la traiettoria di riferimento specificate nella specifica della metrica.latency_in_seconds: tempo impiegato (in secondi) per generare la risposta.failure: indica se è stata generata o meno una risposta valida.
Metriche di riepilogo:
mean: punteggio medio per tutte le istanze.standard deviation: Deviazione standard per tutti i punteggi.
Passaggi successivi
- Sviluppare un agente.
- Esegui il deployment di un agente.
- Utilizzare un agente.
- Richiedere assistenza.
Prova i seguenti notebook: