이 페이지에서는 쿼리 통계 대시보드를 사용하여 쿼리의 성능 문제를 감지하고 분석하는 방법을 설명합니다.
소개
쿼리 통계는 Cloud SQL 데이터베이스의 쿼리 성능 문제를 감지하고 진단하고 방지하는 데 도움이 됩니다. 직관적인 모니터링을 지원하고 성능 문제를 감지하는 것뿐만 아니라 근본 원인까지 파악하는 데 도움을 주는 진단 정보를 제공합니다.
쿼리 통계를 사용하면 애플리케이션 수준에서 성능을 모니터링하고 모델, 뷰, 컨트롤러, 경로, 사용자, 호스트별로 애플리케이션 스택에서 문제가 있는 쿼리의 소스를 trace할 수 있습니다. 쿼리 통계 도구는 개방형 표준 및 API를 사용하여 기존 애플리케이션 모니터링(APM) 도구 및 Google Cloud서비스와 통합할 수 있습니다. 그러면 원하는 도구를 사용하여 쿼리 문제를 모니터링하고 해결할 수 있습니다.
쿼리 통계는 다음 단계에 대한 안내를 통해 Cloud SQL 쿼리 성능을 향상시킬 수 있게 해줍니다.
- 상위 쿼리의 데이터베이스 부하를 확인합니다.
- 잠재적으로 문제가 발생할 수 있는 쿼리 또는 태그를 식별합니다.
- 쿼리 또는 태그를 조사하여 문제를 식별합니다.
- 샘플 쿼리에서 생성된 trace 검사
Cloud SQL Enterprise Plus 버전의 쿼리 통계
Cloud SQL Enterprise Plus 버전을 사용하는 경우 쿼리 통계의 추가 기능을 이용해서 고급 쿼리 성능 진단을 수행할 수 있습니다. 쿼리 통계 대시보드의 표준 기능 외에도 Cloud SQL Enterprise Plus 버전의 쿼리 통계를 이용해서 다음을 수행할 수 있습니다.
- 실행된 모든 쿼리의 대기 이벤트 캡처 및 분석
- 쿼리, 태그, 대기 이벤트 유형 등의 추가 측정기준에 따라 집계된 데이터베이스 부하 필터링
- 실행된 모든 쿼리의 쿼리 계획 캡처
- 쿼리 계획을 분당 최대 200개까지 샘플링
- 긴 쿼리 텍스트(최대 100KB) 캡처
- 측정항목에 대한 거의 실시간(초 단위) 업데이트
- 30일 이상 측정항목 보관
- 색인 도우미에서 색인 추천 받기
- 활성 쿼리에서 세션이나 장기 실행 트랜잭션 종료
- AI 지원 문제 해결(프리뷰)에 액세스
다음 테이블에서는 Cloud SQL Enterprise 버전의 쿼리 통계 기능과 기능적 요구사항을 Cloud SQL Enterprise Plus 버전의 쿼리 통계와 비교해서 보여줍니다.
| 비교 영역 | Cloud SQL Enterprise 버전의 쿼리 통계 | Cloud SQL Enterprise Plus 버전의 쿼리 통계 |
|---|---|---|
| 지원되는 데이터베이스 버전 | PostgreSQL 9.6 이상 | PostgreSQL 12 이상 |
| 지원되는 머신 유형 | 모든 머신 유형에서 지원됨 | 공유 코어 머신 유형을 사용하는 인스턴스나 읽기 복제본 인스턴스에서는 지원되지 않음 |
| 지원되는 리전 | Cloud SQL 리전 위치 | Cloud SQL Enterprise Plus 버전 리전 위치 |
| 측정항목 보관 기간 | 7일 | 30일 |
| 쿼리 길이 한도 최댓값 | 4500바이트 | 100KB |
| 쿼리 계획 샘플 최댓값 | 20 | 200 |
| 대기 이벤트 분석 | 사용 불가 | 사용 가능 |
| 색인 도우미 추천 | 사용 불가 | 사용 가능 |
| 활성 쿼리에서 세션이나 장기 실행 트랜잭션 종료 | 사용 불가 | 사용 가능 |
| AI 지원 문제 해결(프리뷰) | 사용 불가 | 사용 가능 |
Cloud SQL Enterprise Plus 버전의 쿼리 통계 사용 설정
Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용 설정하려면 Cloud SQL Enterprise Plus 버전 인스턴스에서 쿼리 통계를 사용 설정할 때 Enterprise Plus 기능 사용 설정을 선택합니다.
가격 책정
Cloud SQL Enterprise 버전 인스턴스나 Cloud SQL Enterprise Plus 버전 인스턴스의 쿼리 통계를 사용하는 데 추가 비용이 발생하지 않습니다.
스토리지 요구사항
Cloud SQL Enterprise 버전의 쿼리 통계는 Cloud SQL 인스턴스에서 어떠한 저장 공간도 차지하지 않습니다. 측정항목은 Cloud Monitoring에 저장됩니다. API 요청은 Cloud Monitoring 가격 책정을 참조하세요. Cloud Monitoring에는 추가 비용 없이 사용할 수 있는 등급이 있습니다.
Cloud SQL Enterprise Plus 버전의 쿼리 통계는 Cloud SQL 인스턴스에 연결된 같은 디스크에 측정항목 데이터를 저장하며 스토리지 자동 증가 설정은 사용 설정 상태로 유지되어야 합니다.
7일 간 데이터의 스토리지 요구사항은 약 36GB입니다. 30일 동안은 약 155GB가 필요합니다. Cloud SQL Enterprise Plus 버전의 쿼리 통계는 최대 10MB RAM(공유 메모리)을 사용합니다. 측정항목은 쿼리 완료 후 30초 내에 쿼리 통계에서 사용할 수 있습니다. 여기에는 해당하는 스토리지 요금이 적용됩니다.제한사항
Cloud SQL Enterprise Plus 버전 인스턴스의 쿼리 통계에는 다음 제한사항이 적용됩니다.
- 인스턴스에 과도한 시스템 부하가 있으면 쿼리 통계 대시보드에서 측정항목 데이터를 쿼리할 때 쿼리가 느리게 로드되거나 타임아웃될 수 있습니다.
- 오래된 백업으로 인스턴스를 복원하면 백업 시간과 Cloud SQL Enterprise Plus 버전의 쿼리 통계에 대한 인스턴스를 복원하는 시간 사이의 측정항목이 손실될 수 있습니다. 예를 들어 4월 25일에 생성된 백업으로 4월 30일에 인스턴스를 복원하면 4월 25일과 4월 30일 사이의 모든 측정항목이 손실될 수 있습니다.
- 인스턴스에서 PostgreSQL 18을 사용하고 SQL 문이 시작되기 전에 쿼리에 주석 태그가 있는 경우 쿼리 통계를 사용할 때 애플리케이션 태그가 저장되지 않을 수 있습니다. 이 제한사항은 Cloud SQL Enterprise Plus 버전 및 Cloud SQL Enterprise 버전 인스턴스에 적용됩니다.
시작하기 전에
쿼리 통계를 사용하기 전에 다음을 수행하세요.
- 필수 역할 및 권한을 추가합니다.
- Cloud Trace API를 사용 설정합니다.
- Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용 중이면 자동 스토리지 증가 사용 설정이 인스턴스에 대해 사용 설정되었는지 확인합니다.
필수 역할 및 권한
쿼리 통계 대시보드에서 과거 쿼리 실행 데이터에 액세스하는 데 필요한 권한을 얻으려면 관리자에게 Cloud SQL 인스턴스를 호스팅하는 프로젝트에 대해 다음 IAM 역할을 부여해 달라고 요청하세요.
-
데이터베이스 통계 모니터링 뷰어(
roles/databaseinsights.monitoringViewer) -
Cloud SQL 뷰어(
roles/cloudsql.viewer)
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
Cloud Trace API 사용 설정
쿼리 계획과 엔드 투 엔드 뷰를 보려면 Google Cloud 프로젝트에 Cloud Trace API가 사용 설정되어 있어야 합니다. 이 설정을 사용하면Google Cloud 프로젝트가 인증된 소스에서 trace 데이터를 추가 비용 없이 수신할 수 있습니다. 이 데이터를 사용하면 인스턴스의 성능 문제를 감지하고 진단할 수 있습니다.
Cloud Trace API가 사용 설정되었는지 확인하려면 다음 단계를 수행합니다.
- Google Cloud 콘솔에서 API 및 서비스로 이동합니다.
- API 및 서비스 사용 설정을 클릭합니다.
- 검색창에
Cloud Trace API를 입력합니다. - API 사용 설정됨이 표시된 경우는 이 API가 사용 설정되어 있으므로 아무 조치를 하지 않아도 됩니다. 그렇지 않은 경우에는 사용 설정을 클릭합니다.
저장용량 자동 증가 사용 설정
Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용하는 경우 자동 스토리지 증가 사용 설정 인스턴스 설정이 사용 설정된 상태로 유지되는지 확인합니다. 기본적으로 이 옵션은 Cloud SQL 인스턴스에 사용 설정되어 있습니다.
이전에 이 인스턴스 설정을 사용 중지했고 Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용 설정하려면 먼저 자동 스토리지 증가를 다시 사용 설정합니다. 자동 스토리지 증가를 사용 중지하고 Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용 설정할 수는 없습니다.
쿼리 통계 사용 설정
쿼리 통계를 사용 설정하면 다른 모든 작업이 일시 정지됩니다. 이러한 작업에는 상태 점검, 로깅, 모니터링 및 기타 인스턴스 작업이 포함됩니다.
콘솔
인스턴스에 쿼리 통계 사용 설정
-
Google Cloud 콘솔에서 Cloud SQL 인스턴스 페이지로 이동합니다.
- 인스턴스의 개요 페이지를 열려면 인스턴스 이름을 클릭합니다.
- 구성 타일에서 구성 수정을 클릭합니다.
- 인스턴스 맞춤설정 섹션에서 쿼리 통계를 확장합니다.
- 쿼리 통계 사용 설정 체크박스를 선택합니다.
- 선택사항: 인스턴스의 추가 기능을 선택합니다. 일부 기능은 Cloud SQL Enterprise Plus 버전에서만 사용 가능합니다.
- 저장을 클릭합니다.
| 기능 | 설명 | Cloud SQL Enterprise 버전 | Cloud SQL Enterprise Plus 버전 |
|---|---|---|---|
| Enterprise Plus 기능 사용 설정 | Cloud SQL에서 Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용 설정하려면 이 체크박스를 선택합니다. Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용하면 활성 쿼리에서 세션과 장기 실행 트랜잭션을 종료하고 측정항목 데이터 보관 기간을 30일까지 늘릴 수 있습니다. AI 지원 문제 해결(프리뷰)을 사용 설정하려면 이 체크박스를 선택해야 합니다. | 사용 불가 | 사용 가능
기본값: 사용 중지됨 |
| 활성 쿼리 분석 | 현재 실행 중인 쿼리에 대한 세부정보를 검토할 수 있습니다. Cloud SQL Enterprise Plus 버전에서 사용 설정된 경우 세션과 장기 실행 트랜잭션도 종료할 수 있습니다. PostgreSQL용 Cloud SQL 인스턴스에 활성 쿼리를 사용 설정하려면 이 체크박스를 선택합니다. 자세한 내용은 활성 쿼리 모니터링을 참조하세요. | 사용 가능
기본값: 사용 중지됨 |
사용 가능
기본값: 사용 중지됨 |
| 색인 도우미 추천 | 쿼리 처리 속도를 높이기 위한 색인 추천을 제공합니다. 자세한 내용은 색인 도우미 사용을 참조하세요. 색인 도우미를 사용 설정하려면 인스턴스를 다시 시작해야 합니다. 색인 도우미 사용 중지에는 다시 시작이 필요하지 않습니다. | 사용 불가 | 사용 가능 기본값: 사용 중지됨 |
| AI 지원 문제 해결 | 성능 이상 감지, 근본 원인 및 상황 분석을 사용 설정하고 쿼리 및 데이터베이스 문제를 해결하기 위한 추천을 받으려면 이 체크박스를 선택합니다. 이 기능은 프리뷰 버전이며 Google Cloud 콘솔을 통해서만 이 기능을 사용 설정하고 액세스할 수 있습니다. 자세한 내용은 AI 어시스턴스를 사용하여 관찰 및 문제 해결을 참조하세요. | 사용 불가 | 사용 가능
기본값: 사용 중지됨 |
| 클라이언트 IP 주소 저장 | 클라이언트 IP 주소 스토리지를 사용 설정하려면 이 체크박스를 선택합니다. Cloud SQL은 쿼리가 시작되는 위치의 IP 주소를 저장하고 이 데이터를 그룹화하여 이를 기준으로 측정항목을 실행할 수 있게 해줍니다. 쿼리는 두 개 이상의 호스트에서 가져옵니다. 클라이언트 IP 주소에서 쿼리 그래프를 검토하면 문제의 원인을 식별하는 데 도움이 될 수 있습니다. | 사용 가능
기본값: 사용 중지됨 |
사용 가능
기본값: 사용 중지됨 |
| 애플리케이션 태그 저장 | 애플리케이션 태그 스토리지를 사용 설정하려면 이 체크박스를 선택합니다. 애플리케이션 태그를 저장하면 요청을 실행하는 API 및 모델 뷰 컨트롤러(MVC) 경로를 확인하고 이에 대해 측정항목을 실행할 데이터를 그룹화할 수 있습니다. 이 옵션을 사용하려면 sqlcommenter 오픈소스 객체 관계형 매핑(ORM) 자동 계측 라이브러리를 사용하여 특정 태그 집합을 사용하여 쿼리에 주석을 추가해야 합니다. 이 정보는 쿼리 통계로 문제의 원인과 문제가 발생한 MVC를 식별하는 도움이 됩니다. 애플리케이션 경로를 사용하면 애플리케이션 모니터링을 수행할 수 있습니다. | 사용 가능
기본값: 사용 중지됨 |
사용 가능
기본값: 사용 중지됨 |
| 쿼리 길이 맞춤설정 |
쿼리 문자열 길이 한도를 맞춤설정하려면 이 체크박스를 선택합니다.
쿼리 길이가 길수록 분석 쿼리에 더 유용하지만 더 많은 메모리가 필요합니다.
지정된 한도를 초과하는 쿼리 문자열은 잘려서 표시됩니다. 쿼리 길이 한도를 변경하려면 인스턴스를 다시 시작해야 합니다. 길이 제한을 초과하는 쿼리에도 태그를 추가할 수 있습니다. |
한도를 256~4500바이트까지 바이트 단위로 설정할 수 있습니다.
기본값: 1024.
|
한도를 1024~100000까지 바이트 단위로 지정할 수 있습니다.
기본값: 10000바이트
|
| 최대 샘플링 레이트 설정 |
최대 샘플링 레이트를 설정하려면 이 체크박스를 선택합니다. 샘플링 레이트는 인스턴스의 모든 데이터베이스에 1분당 캡처되는 실행된 쿼리 계획 샘플 수입니다. 샘플링 레이트를 늘리면 더 많은 데이터 포인트를 얻을 가능성이 있지만 성능 오버헤드가 증가할 수 있습니다.
샘플링을 사용 중지하려면 이 값을 0으로 설정합니다.
|
이 값을 0~20까지의 숫자로 변경합니다.
기본값: 5.
|
최댓값을 200으로 늘려 더 많은 데이터 포인트를 제공할 수 있습니다.
기본값: 200
|
여러 인스턴스에 쿼리 통계 사용 설정
-
Google Cloud 콘솔에서 Cloud SQL 인스턴스 페이지로 이동합니다.
- 행에서 작업 더보기 메뉴를 클릭합니다.
- 쿼리 통계 사용 설정을 선택합니다.
- 대화상자에서 여러 인스턴스에 쿼리 통계 사용 설정 체크박스를 선택합니다.
- 사용 설정을 클릭합니다.
- 이후 대화상자에서 쿼리 통계를 사용 설정할 인스턴스를 선택합니다.
- 쿼리 통계 사용 설정을 클릭합니다.
gcloud
gcloud를 사용하여 Cloud SQL 인스턴스에 쿼리 통계를 사용 설정하려면 INSTANCE_ID를 인스턴스의 ID로 바꾼 후 다음과 같이 --insights-config-query-insights-enabled 플래그와 함께 gcloud sql instances patch를 실행합니다.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled
또한 다음 선택적인 플래그를 하나 이상 사용합니다.
--insights-config-record-client-address쿼리가 시작되는 클라이언트 IP 주소를 저장하고 데이터를 그룹화하여 측정항목을 실행할 수 있도록 해줍니다. 쿼리는 두 개 이상의 호스트에서 가져옵니다. 클라이언트 IP 주소에서 쿼리 그래프를 검토하면 문제의 원인을 식별하는 데 도움이 될 수 있습니다.
--insights-config-record-application-tags요청을 실행하는 API 및 MVC(Model-View-Controller) 경로를 확인하고 이에 대해 측정항목을 실행할 데이터를 그룹화하는 데 도움이 되는 애플리케이션 태그를 저장합니다. 이 옵션을 사용하려면 특정 태그 집합을 사용하여 쿼리에 주석을 추가해야 합니다. 이렇게 하려면 sqlcommenter 오픈소스 객체 관계형 매핑(ORM) 자동 계측 라이브러리를 사용합니다. 이 정보는 쿼리 통계로 문제의 원인과 문제가 발생한 MVC를 식별하는 도움이 됩니다. 애플리케이션 경로를 사용하면 애플리케이션 모니터링을 수행할 수 있습니다.
--insights-config-query-string-length기본 쿼리 길이 한도를 설정합니다. 쿼리 길이가 길수록 분석 쿼리에 더 유용하지만 더 많은 메모리가 필요합니다. 쿼리 길이를 변경하려면 인스턴스를 다시 시작해야 합니다. 길이 제한을 초과하는 쿼리에도 태그를 추가할 수 있습니다. Cloud SQL Enterprise 버전의 경우 값을
256~4500까지 바이트 단위로 지정할 수 있습니다. 기본 쿼리 길이는1024바이트입니다. Cloud SQL Enterprise Plus 버전의 경우 한도를1024~100000까지 바이트 단위로 지정할 수 있습니다. 기본값은10000바이트입니다.--insights-config-query-plans-per-minute기본적으로 인스턴스의 모든 데이터베이스에서 실행된 쿼리 계획 샘플이 분당 최대 5개까지 캡처됩니다. 샘플링 레이트를 늘리면 더 많은 데이터 포인트를 얻을 가능성이 있지만 성능 오버헤드가 추가될 수 있습니다. 샘플링을 사용 중지하려면 이 값을
0으로 설정합니다. Cloud SQL Enterprise 버전의 경우 값을 0~20까지 변경할 수 있습니다. Cloud SQL Enterprise Plus 버전의 경우 최대 200까지 늘려 더 많은 데이터 포인트를 제공할 수 있습니다. 기본적으로 최대 샘플링 레이트는 인스턴스의 모든 데이터베이스에서 분당 쿼리 계획 샘플200개입니다.
다음을 바꿉니다.
- INSIGHTS_CONFIG_QUERY_STRING_LENGTH: 저장할 쿼리 문자열 길이(바이트)입니다.
- API_TIER_STRING: 인스턴스에 사용할 커스텀 인스턴스 구성입니다.
- REGION: 인스턴스의 리전입니다.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled \ --insights-config-query-string-length=INSIGHTS_CONFIG_QUERY_STRING_LENGTH \ --insights-config-query-plans-per-minute=QUERY_PLANS_PER_MINUTE \ --insights-config-record-application-tags \ --insights-config-record-client-address \ --tier=API_TIER_STRING \ --region=REGION
REST v1
REST API를 사용해서 Cloud SQL 인스턴스에 대해 쿼리 통계를 사용 설정하려면 insightsConfig 설정을 사용해서 instances.patch 메서드를 호출합니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_ID: 프로젝트 ID
- INSTANCE_ID: 인스턴스 ID
HTTP 메서드 및 URL:
PATCH https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID
JSON 요청 본문:
{
"settings" : {
"insightsConfig" : {
"queryInsightsEnabled" : true,
"recordClientAddress" : true,
"recordApplicationTags" : true,
"queryStringLength" : 1024,
"queryPlansPerMinute" : 20,
}
}
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2025-03-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "OPERATION_ID",
"targetId": "INSTANCE_ID",
"selfLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/operations/OPERATION_ID",
"targetProject": "PROJECT_ID"
}
Terraform
Terraform을 사용하여 Cloud SQL 인스턴스에 대한 쿼리 통계를 사용 설정하려면 query_insights_enabled 플래그를 true로 설정합니다.
또한 다음과 같은 선택적인 플래그를 하나 이상 사용할 수 있습니다.
query_string_length: Cloud SQL Enterprise 버전의 경우 값을256~4500까지 바이트 단위로 지정할 수 있습니다. 기본 쿼리 길이는1024바이트입니다. Cloud SQL Enterprise Plus 버전의 경우 한도를1024~100000까지 바이트 단위로 지정할 수 있습니다. 기본값은10000바이트입니다.record_application_tags: 쿼리에서 애플리케이션 태그를 기록하려면 값을true로 설정합니다.record_client_address: 클라이언트 IP 주소를 기록하려면 값을true로 설정합니다. 기본값은false입니다.-
query_plans_per_minute: Cloud SQL Enterprise 버전의 경우 값을0~20까지 설정할 수 있습니다. 기본값은5입니다. Cloud SQL Enterprise Plus 버전의 경우 최대200까지 늘려 더 많은 데이터 포인트를 제공할 수 있습니다. 기본 최대 샘플링 레이트는 인스턴스의 모든 데이터베이스에서 분당 쿼리 계획 샘플200개입니다.
예를 들면 다음과 같습니다.
resource "google_sql_database_instance" "INSTANCE_NAME" { name = "INSTANCE_NAME" database_version = "POSTGRESQL_VERSION" region = "REGION" root_password = "PASSWORD" deletion_protection = false # set to true to prevent destruction of the resource settings { tier = "DB_TIER" insights_config { query_insights_enabled = true query_string_length = 2048 # Optional record_application_tags = true # Optional record_client_address = true # Optional query_plans_per_minute = 10 # Optional } } }
프로젝트에 Terraform 구성을 적용하려면 Google Cloud 다음 섹션의 단계를 완료하세요.
Cloud Shell 준비
- Cloud Shell을 실행합니다.
-
Terraform 구성을 적용할 기본 Google Cloud 프로젝트를 설정합니다.
이 명령어는 프로젝트당 한 번만 실행하면 되며 어떤 디렉터리에서도 실행할 수 있습니다.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 구성 파일에서 명시적 값을 설정하면 환경 변수가 재정의됩니다.
디렉터리 준비
각 Terraform 구성 파일에는 자체 디렉터리(루트 모듈이라고도 함)가 있어야 합니다.
-
Cloud Shell에서 디렉터리를 만들고 해당 디렉터리 내에 새 파일을 만드세요. 파일 이름에는
.tf확장자가 있어야 합니다(예:main.tf). 이 튜토리얼에서는 파일을main.tf라고 합니다.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
튜토리얼을 따라 하는 경우 각 섹션이나 단계에서 샘플 코드를 복사할 수 있습니다.
샘플 코드를 새로 만든
main.tf에 복사합니다.필요한 경우 GitHub에서 코드를 복사합니다. 이는 Terraform 스니펫이 엔드 투 엔드 솔루션의 일부인 경우에 권장됩니다.
- 환경에 적용할 샘플 파라미터를 검토하고 수정합니다.
- 변경사항을 저장합니다.
-
Terraform을 초기화합니다. 이 작업은 디렉터리당 한 번만 수행하면 됩니다.
terraform init
원하는 경우 최신 Google 공급업체 버전을 사용하려면
-upgrade옵션을 포함합니다.terraform init -upgrade
변경사항 적용
-
구성을 검토하고 Terraform에서 만들거나 업데이트할 리소스가 예상과 일치하는지 확인합니다.
terraform plan
필요에 따라 구성을 수정합니다.
-
다음 명령어를 실행하고 프롬프트에
yes를 입력하여 Terraform 구성을 적용합니다.terraform apply
Terraform에 '적용 완료' 메시지가 표시될 때까지 기다립니다.
- 결과를 보려면 Google Cloud 프로젝트를 엽니다. Google Cloud 콘솔에서 UI의 리소스로 이동하여 Terraform이 리소스를 만들었거나 업데이트했는지 확인합니다.
쿼리 완료 후 수분 내에 쿼리 통계에서 측정항목을 사용할 수 있습니다. Cloud Monitoring 데이터 보관 정책을 검토합니다.
쿼리 통계 Trace는 Cloud Trace에 저장됩니다. Cloud Trace 데이터 보관 정책을 검토합니다.
쿼리 통계 대시보드 보기
쿼리 통계 대시보드에는 선택한 요소를 기반으로 쿼리 부하가 표시됩니다. 쿼리 부하는 선택한 기간 내의 인스턴스에 있는 모든 쿼리의 전체 작업을 측정한 것입니다. 대시보드는 쿼리 부하를 볼 수 있는 일련의 필터를 제공합니다.
쿼리 통계 대시보드를 열려면 다음 단계를 수행합니다.
- 인스턴스의 개요 페이지를 열려면 인스턴스 이름을 클릭합니다.
- Cloud SQL 탐색 메뉴에서 쿼리 통계를 클릭하거나 인스턴스 개요 페이지에서 쿼리 통계로 이동하여 쿼리 및 성능에 대한 자세한 정보 보기를 클릭합니다.
쿼리 통계 대시보드가 열립니다. Cloud SQL Enterprise 버전의 쿼리 통계 또는 Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용하는지 여부에 따라 쿼리 통계 대시보드에 인스턴스에 대한 다음 정보가 표시됩니다.
Cloud SQL Enterprise Plus 버전
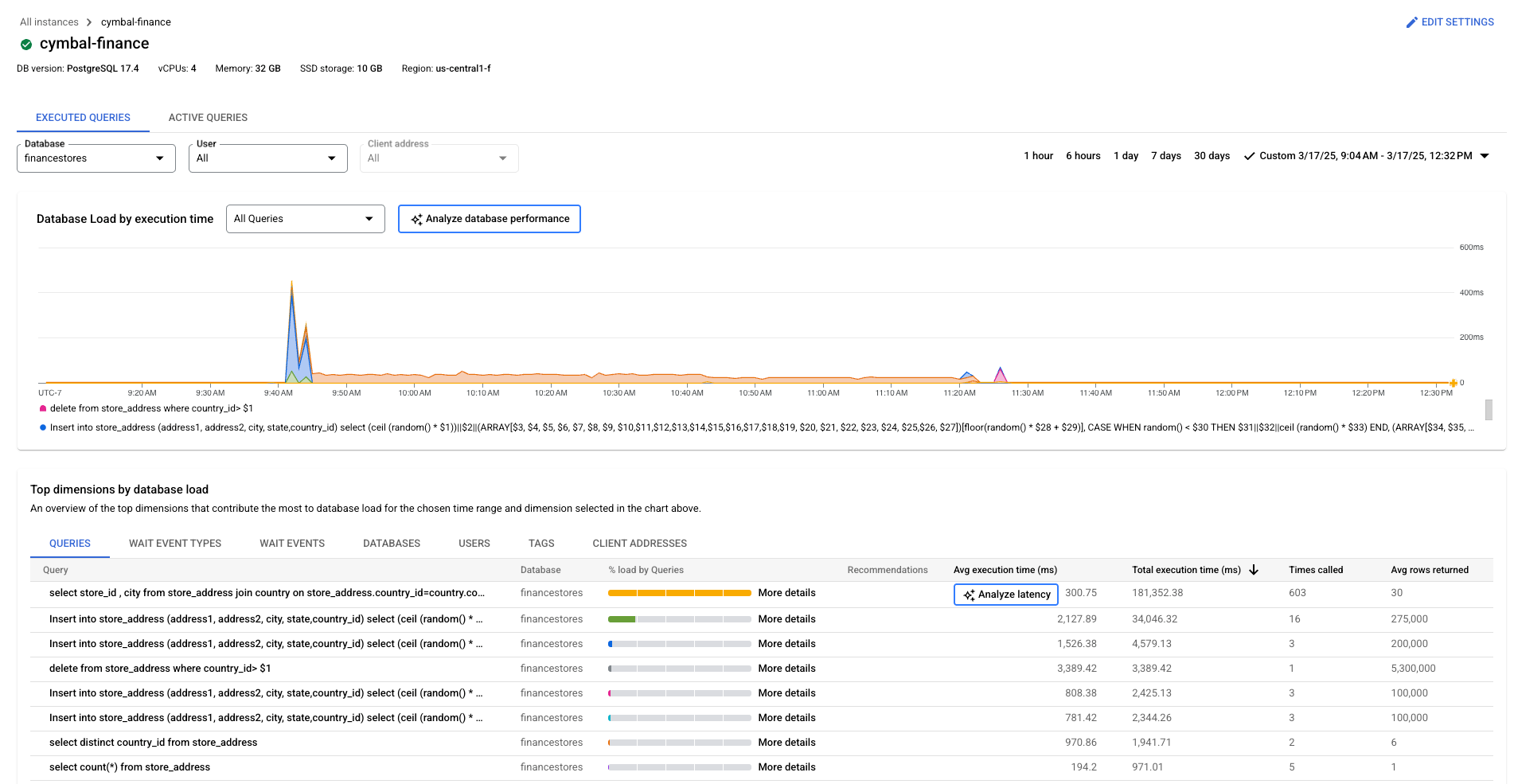
- 모든 쿼리: 선택한 기간의 모든 쿼리에 대한 데이터베이스 부하를 표시합니다. 각 쿼리는 개별적으로 색상으로 구분됩니다. 특정 쿼리의 특정 시점을 보려면 포인터를 쿼리의 차트 위로 가져갑니다.
- 데이터베이스: 특정 데이터베이스 또는 모든 데이터베이스에서 쿼리 부하를 필터링합니다.
- 사용자: 특정 사용자 계정의 쿼리 부하를 필터링합니다.
- 클라이언트 주소: 특정 IP 주소의 쿼리 부하를 필터링합니다.
- 기간: 1시간, 6시간, 1일, 7일, 30일 또는 커스텀 범위와 같은 기간별로 쿼리 부하를 필터링합니다.
- 대기 이벤트 유형: CPU 및 잠금 대기 이벤트 유형별로 쿼리 부하를 필터링합니다.
- 쿼리, 대기 이벤트 유형, 데이터베이스, 사용자, 태그, 클라이언트 주소: 차트에서 데이터베이스 부하에 가장 많이 기여하는 상위 측정기준별로 정렬합니다. 데이터베이스 부하 필터링을 참조하세요.
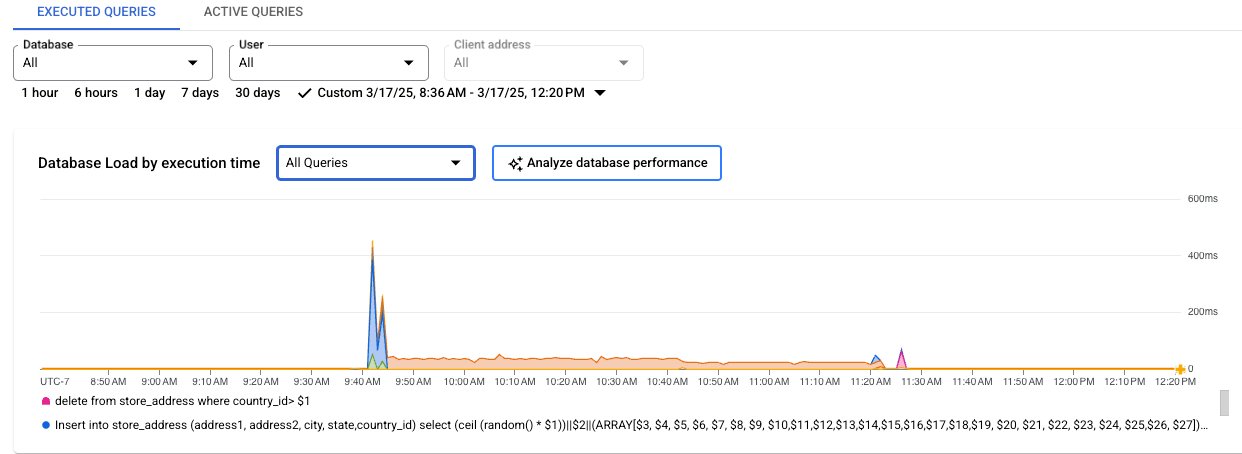
Cloud SQL Enterprise 버전
- 데이터베이스: 특정 데이터베이스 또는 모든 데이터베이스에서 쿼리 부하를 필터링합니다.
- 사용자: 특정 사용자 계정의 쿼리 부하를 필터링합니다.
- 클라이언트 주소: 특정 IP 주소의 쿼리 부하를 필터링합니다.
- 기간: 1시간, 6시간, 1일, 7일, 30일 또는 커스텀 범위와 같은 기간별로 쿼리 부하를 필터링합니다.
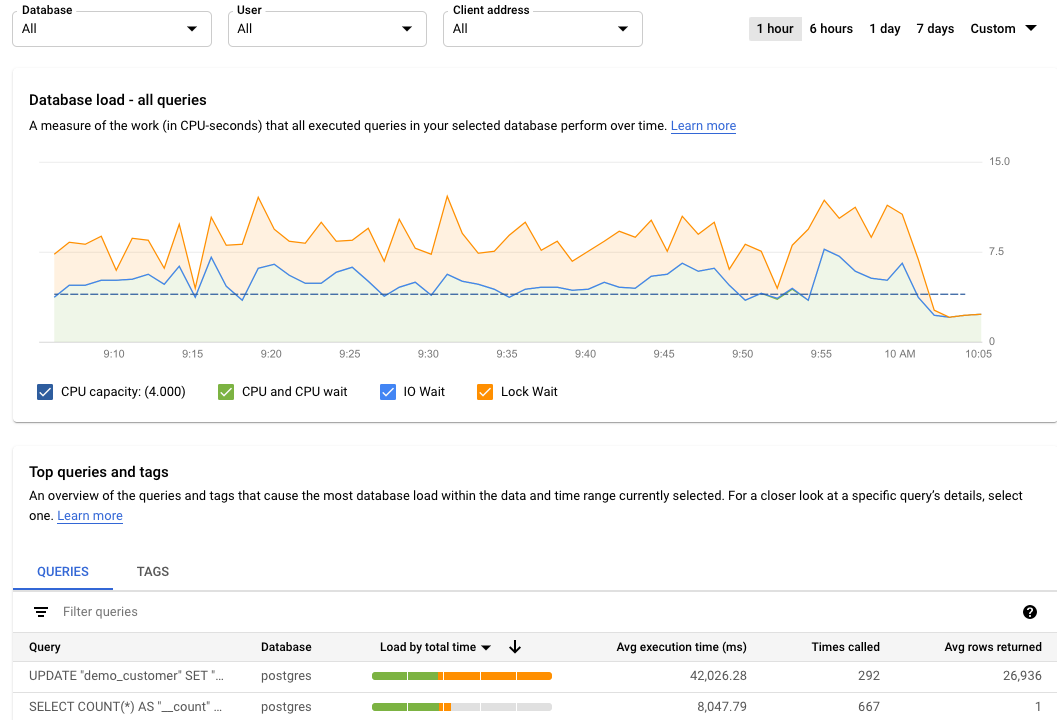
- 데이터베이스 부하 그래프: 필터링된 데이터를 기반으로 쿼리 부하 그래프를 표시합니다.
- CPU 용량, CPU 및 CPU 대기, IO 대기, 잠금 대기: 선택한 옵션에 따라 부하를 필터링합니다. 이러한 각 필터에 대한 자세한 내용은 상위 쿼리의 데이터베이스 부하 보기를 참조하세요.
- 쿼리 및 태그: 선택한 쿼리 또는 선택한 SQL 쿼리 태그에 따라 쿼리 부하를 필터링합니다. 데이터베이스 부하 필터링을 참조하세요.
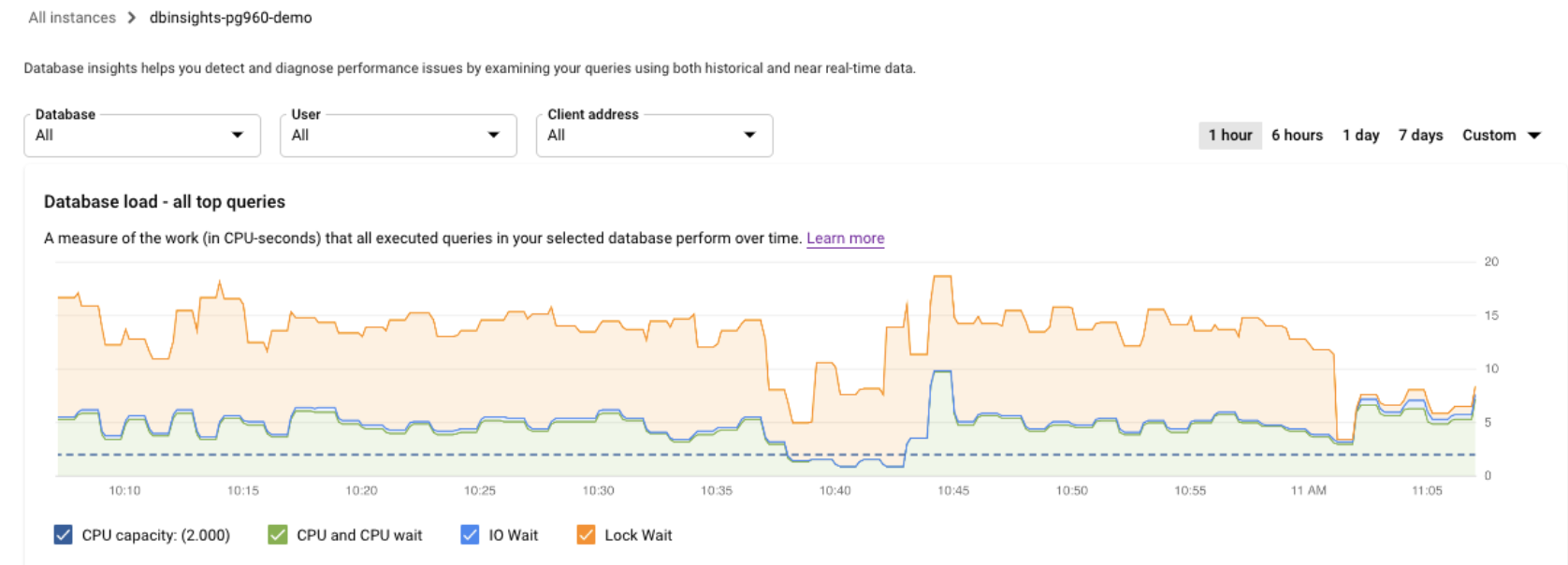
모든 쿼리의 데이터베이스 부하를 확인합니다.
데이터베이스 쿼리 부하는 선택한 데이터베이스에서 실행된 쿼리가 시간에 따라 수행하는 작업을 측정한 값(CPU-초)입니다. 실행 중인 각 쿼리는 CPU 리소스, IO 리소스 또는 잠금 리소스를 사용하거나 대기합니다. 데이터베이스 쿼리 부하는 지정된 기간에 완료된 모든 쿼리에 걸린 시간과 실제로 경과한 시간의 비율입니다.
최상위 수준 쿼리 통계 대시보드에 데이터베이스 부하 - 모든 상위 쿼리 그래프가 표시됩니다. 대시보드의 드롭다운 메뉴를 사용하면 특정 데이터베이스, 사용자 또는 클라이언트 주소에 대한 그래프를 필터링할 수 있습니다.
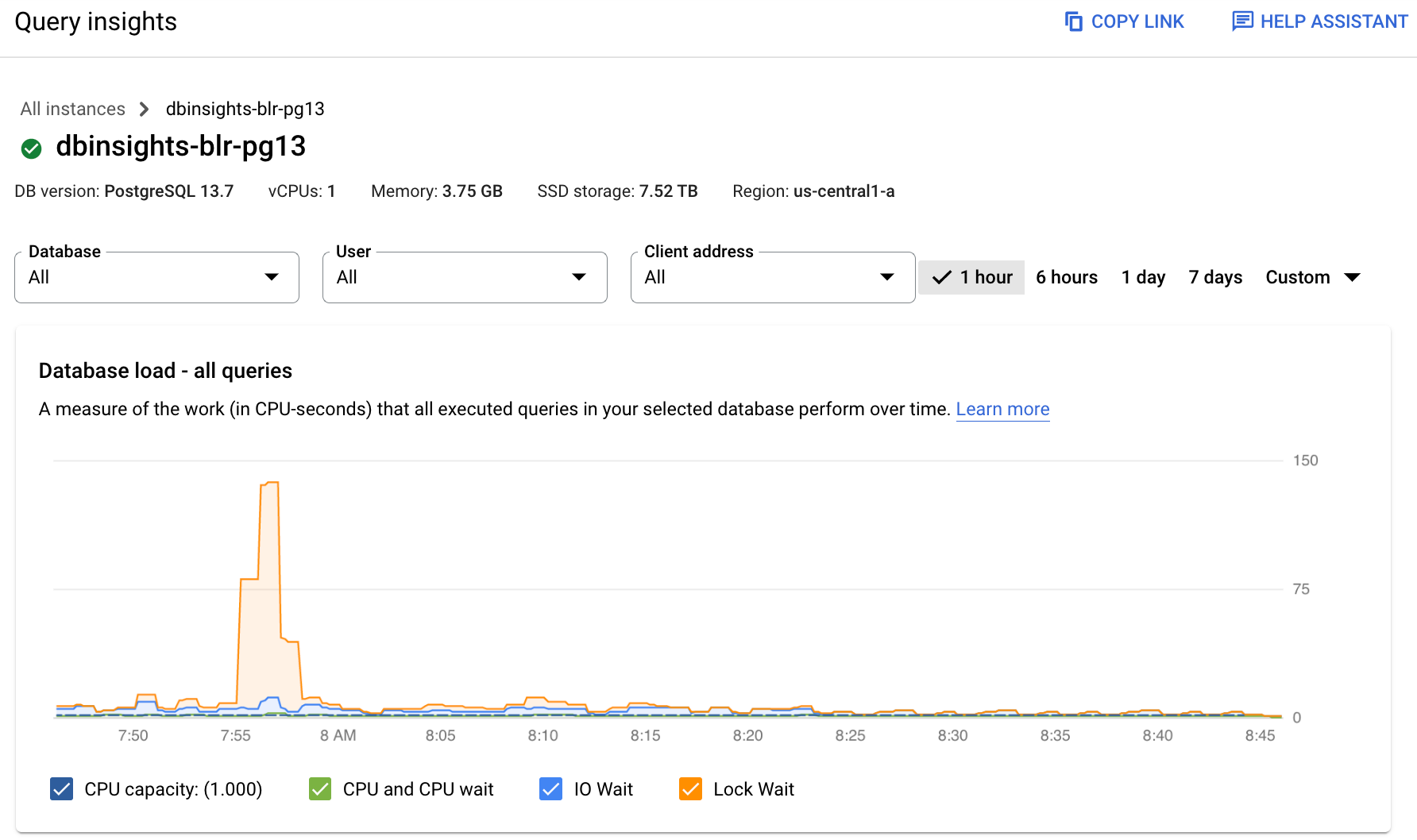
Cloud SQL Enterprise Plus 버전
Cloud SQL Enterprise 버전
그래프에서 색상이 지정된 선은 쿼리 부하를 다음 카테고리로 구분합니다.
- CPU 용량: 인스턴스에서 사용할 수 있는 CPU 수입니다.
- CPU 및 CPU 대기: 활성 상태의 쿼리에 걸린 시간과 실제로 경과한 시간의 비율입니다. IO 및 잠금 대기는 활성 상태의 쿼리를 차단하지 않습니다. 이 측정항목은 쿼리가 CPU를 사용하고 있거나 다른 프로세스가 CPU를 사용하는 동안 Linux 스케줄러가 쿼리 실행 서버 프로세스를 예약하도록 기다리고 있음을 의미할 수 있습니다.
- IO 대기: IO 대기 중인 쿼리에 걸린 시간과 실제로 경과한 시간의 비율입니다. IO 대기에는 읽기 IO 대기 및 쓰기 IO 대기가 포함됩니다. IO 대기에 대한 정보를 분석하려면 Cloud Monitoring에서 확인할 수 있습니다. 자세한 내용은 Cloud SQL 측정항목을 참조하세요. 자세한 내용은 PostgreSQL 이벤트 표를 참조하세요.
- 잠금 대기: 잠금 대기 중인 쿼리에 걸린 시간과 실제로 경과한 시간의 비율입니다. 여기에는 Lock 대기, LwLock 대기, Buffer pin Lock 대기가 포함됩니다. 잠금 대기에 대한 분석 정보를 보려면 Cloud Monitoring을 사용합니다. 자세한 내용은 Cloud SQL 측정항목을 참조하세요.
그래프에서 색상이 지정된 선은 실행 시간별 데이터베이스당 부하를 나타냅니다. 그래프를 검토하고 필터링 옵션을 사용하여 다음 질문에 답하세요.
- 쿼리 부하가 높은가요? 시간이 지남에 따라 그래프가 급증하거나 상승했나요? 높은 부하가 없으면 쿼리에 문제가 없는 것입니다.
- 부하는 얼마 동안 높은 상태였나요? 지금만 높은가요? 아니면 오랜 시간 동안 높았나요? 범위 선택기를 사용하여 여러 기간을 선택해서 문제가 지속된 기간을 확인합니다. 쿼리 부하 급증이 관측된 기간을 확인하려면 화면을 확대합니다. 타임라인을 최대 1주까지 표시하려면 화면을 축소합니다.
- 부하가 높은 원인은 무엇인가요? 옵션에 따라 CPU 용량, CPU 및 CPU 대기, 잠금 대기 또는 IO 대기를 검사하도록 선택할 수 있습니다. 이러한 각 옵션의 그래프는 부하가 가장 높은 지점을 식별할 수 있도록 색상별로 다르게 표시됩니다. 그래프의 어두운 파란색 선은 시스템의 최대 CPU 용량을 보여줍니다. 쿼리 부하를 최대 CPU 시스템 용량과 비교할 수 있습니다. 이 비교를 통해 인스턴스의 CPU 리소스가 부족한지 확인할 수 있습니다.
- 어떤 데이터베이스에서 부하가 발생하나요? 데이터베이스 드롭다운 메뉴에서 다른 데이터베이스를 선택하여 부하가 가장 높은 데이터베이스를 찾습니다.
- 특정 사용자 또는 IP 주소로 인해 더 높은 부하가 발생하나요? 드롭다운 메뉴에서 다른 사용자와 주소를 선택하여 더 높은 부하를 유발하는 사용자 및 주소를 식별합니다.
데이터베이스 부하 필터링
쿼리 또는 태그로 데이터베이스 부하를 필터링할 수 있습니다. Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용 중이면 다음 측정기준을 사용해서 표시된 데이터를 세분화하도록 데이터베이스 부하 차트를 맞춤설정할 수 있습니다.모든 쿼리
대기 이벤트 유형
대기 이벤트
데이터베이스
사용자
태그
클라이언트 주소
데이터베이스 부하 차트를 맞춤설정하려면 실행 시간별 데이터베이스 부하 드롭다운에서 측정기준을 선택합니다.
데이터베이스 부하별 상위 측정기준 보기
데이터베이스 부하에 가장 큰 영향을 미치는 요소를 보려면 데이터베이스 부하별 상위 측정기준 테이블을 사용하세요. 데이터베이스 부하별 상위 측정기준 테이블에는 실행 시간별 데이터베이스 부하 차트 드롭다운에서 선택한 기간 및 측정기준에 대해 가장 큰 기여도를 보인 항목이 표시됩니다. 기간 또는 측정기준을 수정하여 여러 다른 측정기준 또는 기간의 상위 요소를 볼 수 있습니다.
데이터 부하별 상위 측정기준 테이블에서 다음 탭을 선택할 수 있습니다.
| 탭 | 설명 |
|---|---|
| 쿼리 | 테이블에 총 실행 시간별로 상위 정규화된 쿼리가 표시됩니다.
각 쿼리에 대해 열에 표시되는 데이터는 다음과 같이 나열됩니다.
|
| 대기 이벤트 유형 | 이 테이블에서는 선택한 기간 중 발생한 상위 대기 이벤트 유형의 목록을 보여줍니다. 이 테이블은 Cloud SQL Enterprise Plus 버전의 쿼리 통계에 대해서만 제공됩니다.
|
| 대기 이벤트 | 이 테이블에서는 선택한 기간 중 발생한 상위 대기 이벤트의 목록을 보여줍니다. 이 테이블은 Cloud SQL Enterprise Plus 버전의 쿼리 통계에 대해서만 제공됩니다.
|
| 데이터베이스 | 이 테이블에서는 선택한 기간 동안 실행된 모든 쿼리에서 부하에 기여한 상위 데이터베이스의 목록을 보여줍니다.
|
| 사용자 | 이 테이블에서는 선택한 기간 동안 실행된 모든 쿼리에서 상위 사용자 목록을 보여줍니다.
|
| 태그 | 태그에 대한 자세한 내용은 쿼리 태그로 필터링을 참조하세요. |
| 클라이언트 주소 | 이 테이블에서는 선택한 기간 동안 실행된 모든 쿼리에서 상위 사용자 목록을 보여줍니다.
|
쿼리로 필터링
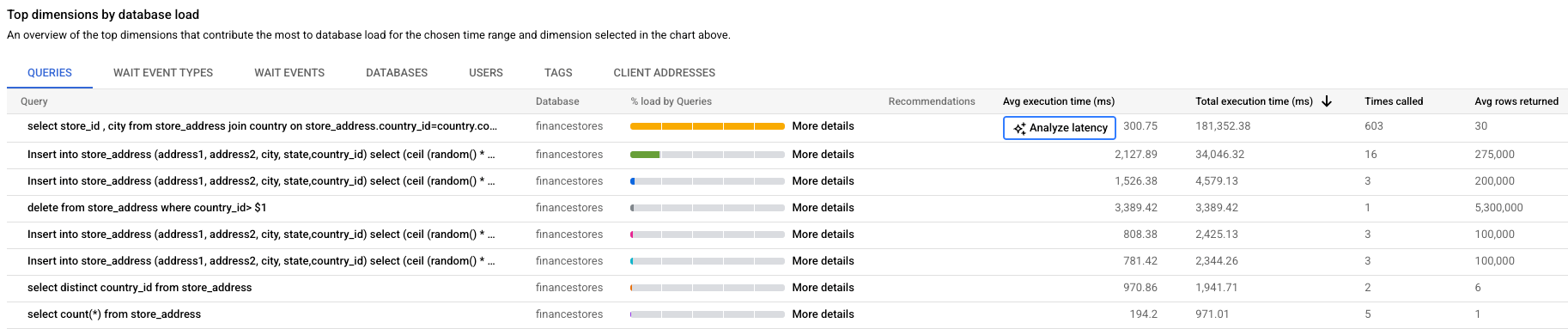
데이터베이스 부하별 상위 측정기준 테이블에는 쿼리 부하가 가장 많이 발생하는 쿼리의 개요가 제공됩니다. 표에는 쿼리 통계 대시보드에서 선택한 기간과 옵션에 대한 정규화된 모든 쿼리가 나와 있습니다. 선택한 기간 동안의 총 실행 시간을 기준으로 쿼리를 정렬합니다.
Cloud SQL Enterprise Plus 버전
테이블을 정렬하려면 열 제목을 선택합니다.
Cloud SQL Enterprise 버전
테이블을 정렬하려면 쿼리 필터링에서 열 제목 또는 속성을 선택합니다.
테이블에는 다음 속성이 표시됩니다.
- 쿼리: 정규화된 쿼리 문자열입니다. 기본적으로 쿼리 통계에는 쿼리 문자열이 1,024자까지만 표시됩니다.
UTILITY COMMAND라벨이 지정된 쿼리에는 일반적으로BEGIN,COMMIT,EXPLAIN명령어 또는 래퍼 명령어가 포함됩니다. - 데이터베이스: 쿼리가 실행된 데이터베이스입니다.
- 추천: 쿼리 성능을 향상시키기 위한 제안된 추천입니다(예: 색인 만들기).
- 총 시간별 부하/CPU별 부하/IO 대기별 부하/잠금 대기별 부하: 특정 쿼리를 필터링하여 가장 큰 부하를 찾을 수 있는 옵션입니다.
- 쿼리별 부하 비율(%): 개별 쿼리의 부하 비율입니다.
- 지연 시간 분석: 이 인스턴스에 AI 지원 문제 해결(프리뷰)을 사용 설정한 경우 이 링크를 클릭하여 느린 쿼리 문제를 해결할 수 있습니다.
- 평균 실행 시간(밀리초): 쿼리가 실행되는 평균 시간입니다.
- 호출된 횟수: 애플리케이션이 쿼리를 호출한 횟수입니다.
- 반환된 행 평균: 쿼리로 반환된 평균 행 수입니다.
쿼리 통계는 정규화된 쿼리만 저장하고 표시합니다.
기본적으로 쿼리 통계는 IP 주소 또는 태그 정보를 수집하지 않습니다. 이 정보를 수집하도록 쿼리 통계를 사용 설정하고 필요한 경우 수집을 사용 중지할 수 있습니다.
쿼리 계획 trace는 상수 값을 수집하거나 저장하지 않으며 상수가 표시할 수 있는 개인 식별 정보를 삭제합니다.
PostgreSQL 9.6 및 10의 경우 쿼리 통계에 정규화된 쿼리가 표시됩니다. 즉 리터럴 상수 값이 ?로 바뀝니다. 다음 예시에서는 이름 상수가 삭제되고 ?로 바뀝니다.
UPDATE "demo_customer" SET "customer_id" = ?::uuid, "name" = ?, "address" = ?, "rating" = ?, "balance" = ?, "current_city" = ?, "current_location" = ? WHERE "demo_customer"."id" = ?
PostgreSQL 버전 11 이상에서는 $1, $2 및 유사 변수가 리터럴 상수 값으로 바뀝니다.
UPDATE "demo_customer" SET "customer_id" = $1::uuid, "name" = $2, "address" = $3, "rating" = $4, "balance" = $5, "current_city" = $6, "current_location" = $7 WHERE "demo_customer"."id" = $8
쿼리 태그로 필터링
애플리케이션 문제를 해결하려면 먼저 태그를 SQL 쿼리에 추가해야 합니다. 쿼리 부하 태그는 시간 경과에 따라 선택된 태그의 쿼리 부하를 분석합니다.
쿼리 통계는 ORM을 사용하여 빌드된 애플리케이션의 성능 문제를 진단하기 위한 애플리케이션 중심 모니터링을 제공합니다. 전체 애플리케이션 스택을 담당하는 경우 쿼리 통계는 애플리케이션 뷰에서 쿼리 모니터링을 제공합니다. 쿼리 태그 지정은 비즈니스 로직 또는 마이크로서비스 등의 상위 수준 구성에서 문제를 찾는 데 도움이 됩니다.
결제, 인벤토리, 비즈니스 분석, 배송 태그와 같은 비즈니스 로직으로 쿼리를 태그할 수 있습니다. 그런 다음 다양한 비즈니스 로직이 만드는 쿼리 부하를 찾을 수 있습니다. 예를 들어 오후 1시의 비즈니스 분석 태그 급증이나 이전 1주 동안의 비정상적인 결제 서비스 증가 추세와 같은 예기치 않은 이벤트가 관찰될 수 있습니다.
태그용 데이터베이스 부하를 계산하기 위해 쿼리 통계는 사용자가 선택한 태그를 사용하는 모든 쿼리에 걸린 시간을 사용합니다. 이 도구는 실제 경과 시간을 사용하여 분 경계에서 완료 시간을 계산합니다.
쿼리 통계 대시보드에서 태그 테이블을 보려면 태그를 선택합니다. 태그 테이블은 총 시간별 총 부하에 따라 태그를 정렬합니다.
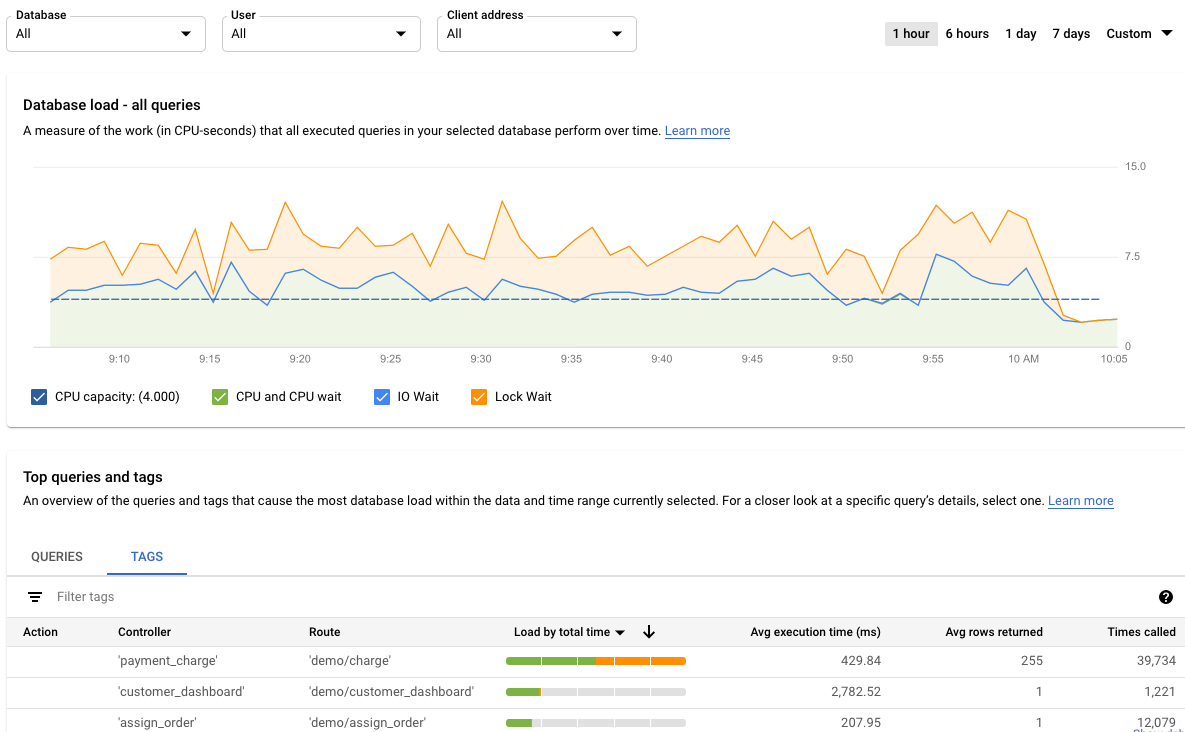
태그 필터링에서 속성을 선택하거나 열 제목을 클릭하여 테이블을 정렬할 수 있습니다. 테이블에는 다음 속성이 표시됩니다.
- 작업, 컨트롤러, 프레임워크, 경로, 애플리케이션, DB 드라이버: 쿼리에 추가한 각 속성이 열로 표시됩니다. 태그로 필터링하려면 이러한 속성을 하나 이상 추가해야 합니다.
- 총 시간별 부하/CPU별 부하/IO 대기별 부하/잠금 대기별 부하: 특정 쿼리를 필터링하여 각 옵션의 최대 부하를 찾는 옵션입니다.
- 평균 실행 시간(밀리초): 쿼리가 실행되는 평균 시간입니다.
- 반환된 행 평균: 쿼리로 반환된 평균 행 수입니다.
- 호출된 횟수: 애플리케이션이 쿼리를 호출한 횟수입니다.
- 데이터베이스: 쿼리가 실행된 데이터베이스입니다.
특정 쿼리 또는 태그의 쿼리 세부정보 보기
특정 쿼리나 태그가 문제의 근본 원인인지 확인하려면 쿼리 탭이나 태그 탭 각각에서 다음을 수행합니다.
- 목록을 내림차순으로 정렬하려면 총 시간별 부하 제목을 클릭합니다.
- 목록 상단에서 쿼리 또는 태그를 클릭합니다. 부하가 가장 높고 다른 것보다 시간이 오래 걸립니다.
쿼리 세부정보 페이지가 열리고 선택한 쿼리나 태그의 세부정보가 표시됩니다.
특정 쿼리 부하 검사
선택한 쿼리의 쿼리 세부정보 페이지가 다음과 같이 표시됩니다.
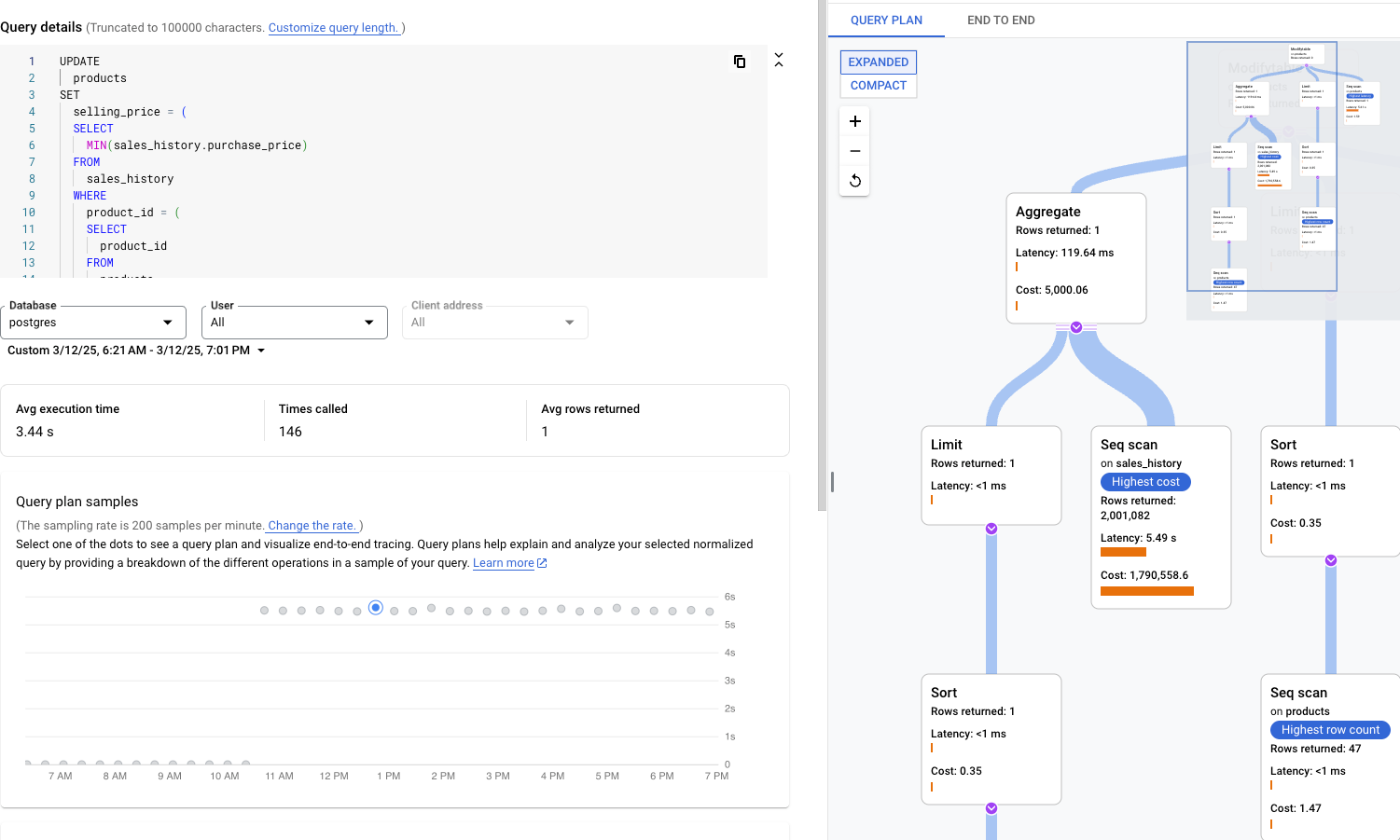
데이터베이스 부하 - 특정 쿼리 그래프는 정규화된 쿼리가 시간 경과에 따라 선택된 쿼리에서 수행한 작업의 측정값(CPU-초)을 보여줍니다. 부하를 계산하기 위해 실제 경과 시간에 대한 분 경계에서 완료된 정규화된 쿼리가 걸린 총 시간을 사용합니다. 테이블 상단에는 집계 및 PII 이유로 리터럴이 삭제된 상태로 정규화된 쿼리의 처음 1,024자가 표시됩니다.
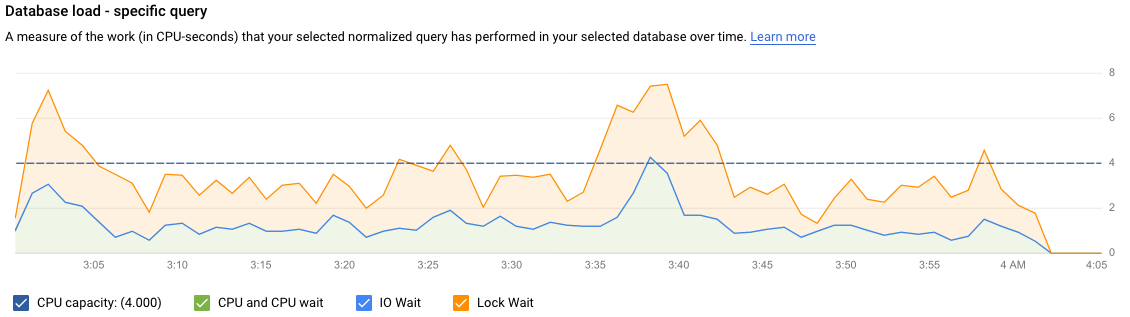
총 쿼리 그래프와 마찬가지로 데이터베이스, 사용자, 클라이언트 주소를 기준으로 특정 쿼리의 부하를 필터링할 수 있습니다. 쿼리 부하가 CPU 용량, CPU 및 CPU 대기, IO 대기 및 잠금 대기로 분할됩니다.
특정 태그 지정된 쿼리 부하 검사
선택한 태그에 대한 대시보드가 다음과 같이 표시됩니다. 예를 들어 마이크로서비스 결제의 모든 쿼리가 payment로 태그가 지정된 경우 payment 태그를 보고 쿼리 부하의 양 추세를 확인할 수 있습니다.
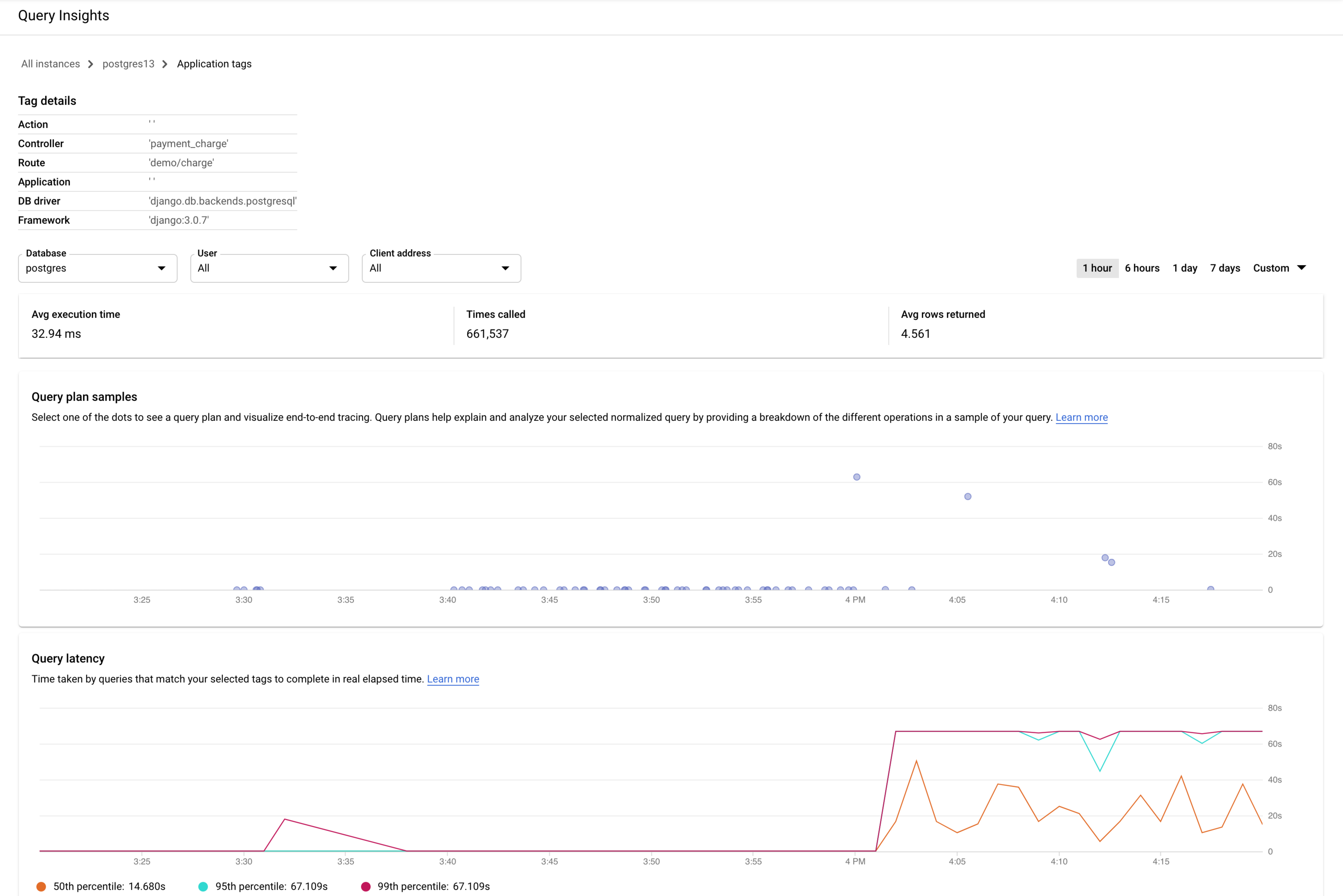
데이터베이스 부하 - 특정 태그 그래프에 선택한 태그와 일치하는 쿼리가 선택한 데이터베이스에서 일정 시간 동안 수행된 작업의 측정(CPU 초)이 표시됩니다. 총 쿼리 그래프와 마찬가지로 데이터베이스, 사용자, 클라이언트 주소를 기준으로 특정 태그의 부하를 필터링할 수 있습니다.
샘플링된 쿼리 계획의 작업 검사
쿼리 계획은 쿼리의 샘플을 가져와서 개별 작업으로 나눕니다. 쿼리의 각 작업을 설명하고 분석합니다.
쿼리 계획 샘플 그래프에는 특정 시간에 실행되는 모든 쿼리 계획과 각 계획을 실행하는 데 걸린 시간이 표시됩니다. 쿼리 계획 샘플이 분당 캡처되는 속도를 변경할 수 있습니다. 쿼리 통계 사용 설정을 참조하세요.
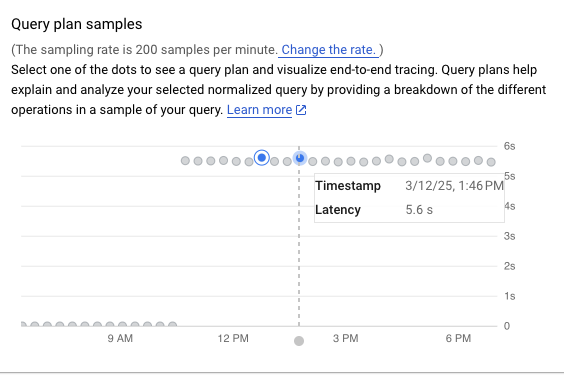
기본적으로 오른쪽 패널에는 쿼리 계획 샘플 그래프에 표시된 대로 가장 오래 걸리는 샘플 쿼리 계획의 세부정보가 표시됩니다. 다른 샘플 쿼리 계획의 세부정보를 보려면 그래프에서 관련 원을 클릭합니다. 세부정보를 펼치면 쿼리 계획의 모든 작업 모델이 표시됩니다.
각 작업에는 지연 시간, 반환된 행, 작업 비용이 표시됩니다. 작업을 선택하면 공유 적중 블록, 스키마 유형, 루프, 계획 행 등의 더 많은 세부정보를 볼 수 있습니다.

다음 질문을 확인하여 문제의 범위를 좁혀 보세요.
- 리소스 소비란 무엇인가요?
- 다른 쿼리와는 어떤 연관이 있나요?
- 시간이 지나면 소비가 달라지나요?
샘플 쿼리에서 생성된 trace 검사
샘플 쿼리 계획을 보는 것 외에도 쿼리 통계를 사용하여 샘플 쿼리의 컨텍스트 내 엔드 투 엔드 애플리케이션 trace를 볼 수 있습니다. 이 trace는 특정 요청의 데이터베이스 활동을 표시하여 문제가 있는 쿼리의 소스를 식별하는 데 도움이 됩니다. 또한 요청 중에 애플리케이션이 Cloud Logging에 전송하는 로그 항목이 trace에 연결되어 조사를 지원합니다.
컨텍스트 내 trace를 보려면 다음을 수행합니다.
- 샘플 쿼리 화면에서 엔드 투 엔드 Trace 탭을 클릭합니다. 이 탭에는 쿼리로 생성된 trace의 개별 작업 기록인 스팬을 자세히 보여주는 Gantt 차트가 표시됩니다.
- 속성 및 메타데이터와 같은 각 스팬에 대한 세부정보를 보려면 스팬을 선택합니다.
Trace 탐색기 페이지에서 trace를 볼 수도 있습니다. 이렇게 하려면 Cloud Trace에서 보기를 클릭합니다. Trace 탐색기 페이지를 사용하여 trace 데이터를 탐색하는 방법에 대한 자세한 내용은 Trace 찾기 및 탐색을 참조하세요.
지연 시간 검사
지연 시간은 정규화된 쿼리가 실제 경과 시간으로 완료되는 데 걸린 시간입니다. 지연 시간 그래프를 사용하여 쿼리나 태그의 지연 시간을 검사합니다. 지연 시간 대시보드에 이상점 동작을 찾기 위해 50번째, 95번째, 99번째 백분위수 지연 시간이 표시됩니다.
다음 이미지는 CPU 용량, CPU 및 CPU 대기, IO 대기, 잠금 대기에 대해 선택된 필터를 사용하여 특정 쿼리에 대한 50번째 백분위수의 데이터베이스 부하 그래프를 보여줍니다.
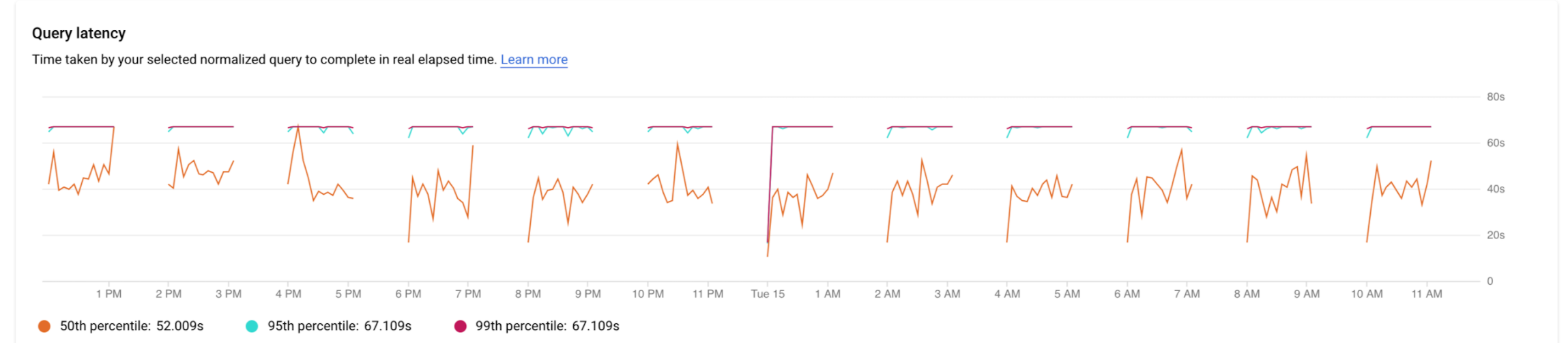
쿼리의 일부를 실행하는 데 사용되는 여러 코어로 인해 쿼리의 데이터베이스 부하가 높은 경우에도 병렬 쿼리의 지연 시간은 실제 경과 시간으로 측정됩니다.
다음 질문을 확인하여 문제의 범위를 좁혀 보세요.
- 부하가 높은 원인은 무엇인가요? 옵션을 선택하여 CPU 용량, CPU 및 CPU 대기, I/O 대기 또는 잠금 대기를 확인합니다.
- 부하는 얼마 동안 높은 상태였나요? 지금 현재만 높나요? 아니면 오랜 기간 동안 높은 상태였나요? 부하 성능이 저하된 날짜와 시간을 찾으려면 기간을 변경합니다.
- 지연 시간이 급증했나요? 기간을 변경하여 정규화된 쿼리의 이전 지연 시간을 조사합니다.
SQL 쿼리에 태그 추가
SQL 쿼리에 태그를 지정하면 애플리케이션 문제 해결이 간소화됩니다. sqlcommenter를 사용하여 SQL 쿼리에 자동 또는 수동으로 태그를 추가할 수 있습니다.
ORM과 함께 sqlcommenter 사용
SQL 쿼리를 직접 작성하는 대신 ORM을 사용하는 경우 성능 문제를 일으키는 애플리케이션 코드를 찾지 못할 수 있습니다. 또한 애플리케이션 코드가 쿼리 성능에 어떤 영향을 미치는지 분석하는 데 문제가 있을 수도 있습니다. 이 문제를 해결하기 위해 쿼리 통계는 sqlcommenter라는 오픈소스 라이브러리를 제공합니다. 이 라이브러리는 ORM 도구를 사용해서 성능 문제를 일으키는 애플리케이션 코드를 감지하는 개발자 및 관리자에게 유용합니다.
ORM 및 sqlcommenter를 함께 사용하면 태그가 자동으로 생성됩니다. 애플리케이션에서 코드를 추가하거나 변경할 필요가 없습니다.
애플리케이션 서버에 sqlcommenter를 설치할 수 있습니다. 계측 라이브러리를 사용하면 MVC 프레임워크와 관련된 애플리케이션 정보를 쿼리와 함께 SQL 주석으로 데이터베이스에 적용할 수 있습니다. 데이터베이스는 이러한 태그를 선택하고 태그별로 통계를 기록 및 집계하며, 이는 정규화된 쿼리를 통해 집계된 통계와 유사합니다. 쿼리 통계에는 쿼리 부하를 일으키는 애플리케이션을 파악하고 성능 문제를 일으키는 애플리케이션 코드를 찾을 수 있도록 태그가 표시됩니다.
SQL 데이터베이스 로그에서 결과를 검사하면 다음과 같이 표시됩니다.
SELECT * from USERS /action='run+this', controller='foo%3', traceparent='00-01', tracestate='rojo%2'/
지원되는 태그에는 컨트롤러 이름, 경로, 프레임워크, 작업이 포함됩니다.
sqlcommenter의 ORM 도구 집합은 다음 프로그래밍 언어에 대해 지원됩니다.
| Python |
|
| 자바 |
|
| Ruby |
|
| Node.js |
|
| PHP |
|
sqlcommenter 및 ORM 프레임워크에서 이를 사용하는 방법에 대한 자세한 내용은 sqlcommenter 문서를 참조하세요.
sqlcommenter를 사용하여 태그 추가
ORM을 사용하지 않는 경우에는 올바른 SQL 주석 형식으로 sqlcommenter 태그 또는 주석을 SQL 쿼리에 수동으로 추가해야 합니다. 또한 직렬화된 키-값 쌍이 포함된 주석으로 각 SQL 문을 보강해야 합니다. 다음 키 중 하나 이상을 사용하세요.
action=''controller=''framework=''route=''application=''db driver=''
쿼리 통계는 다른 모든 키를 삭제합니다.
차단된 활성 쿼리
특정 활성 쿼리가 차단되거나 예상보다 훨씬 오래 실행되면 다른 종속 쿼리가 차단될 수 있습니다.
Cloud SQL에서는 장기 실행되거나 차단된 특정 활성 쿼리를 종료할 수 있습니다.
자세한 내용은 차단된 활성 쿼리를 참고하세요.
쿼리 통계 사용 중지
콘솔
Google Cloud 콘솔을 사용하여 Cloud SQL 인스턴스의 쿼리 통계를 사용 중지하려면 다음 단계를 수행합니다.
-
Google Cloud 콘솔에서 Cloud SQL 인스턴스 페이지로 이동합니다.
- 인스턴스의 개요 페이지를 열려면 인스턴스 이름을 클릭합니다.
- 구성 타일에서 구성 수정을 클릭합니다.
- 구성 옵션 섹션에서 쿼리 통계를 펼칩니다.
- 쿼리 통계 사용 설정 체크박스를 선택 취소합니다.
- 저장을 클릭합니다.
gcloud
gcloud를 사용하여 Cloud SQL 인스턴스의 쿼리 통계를 사용 중지하려면 INSTANCE_ID를 인스턴스 ID로 바꾼 후 다음과 같이 --no-insights-config-query-insights-enabled 플래그와 함께 gcloud sql instances patch를 실행합니다.
gcloud sql instances patch INSTANCE_ID \ --no-insights-config-query-insights-enabled
REST
REST API를 사용해서 Cloud SQL 인스턴스에 대해 쿼리 통계를 사용 중지하려면 다음과 같이 queryInsightsEnabled를 false로 설정하여 instances.patch 메서드를 호출합니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- project-id: 프로젝트 ID
- instance-id: 인스턴스 ID입니다.
HTTP 메서드 및 URL:
PATCH https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id
JSON 요청 본문:
{
"settings" : { "insightsConfig" : { "queryInsightsEnabled" : false } }
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2021-01-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "operation-id",
"targetId": "instance-id",
"selfLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/operations/operation-id",
"targetProject": "project-id"
}
Cloud SQL Enterprise Plus 버전의 쿼리 통계 사용 중지
Cloud SQL Enterprise Plus 버전의 쿼리 통계를 사용 중지하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 Cloud SQL 인스턴스 페이지로 이동합니다.
- 인스턴스의 개요 페이지를 열려면 인스턴스 이름을 클릭합니다.
- 수정을 클릭합니다.
- 인스턴스 맞춤설정 섹션에서 쿼리 통계를 확장합니다.
- Enterprise Plus 기능 사용 설정 체크박스를 선택 해제합니다.
- 저장을 클릭합니다.
다음 단계
- 출시 블로그: Cloud SQL Enterprise Plus 버전의 최신 쿼리 통계로 데이터베이스 병목 현상을 더 빠르게 해결
- Cloud SQL 측정항목을 참조하세요.
쿼리 통계 측정항목 유형 문자열은
database/postgresql/insights로 시작합니다. - 블로그: Cloud SQL Insights로 쿼리 성능 문제 해결 기술 향상
- 동영상: Cloud SQL Insights 소개
- 팟캐스트: Cloud SQL Insights
- Insights Codelab
- 높은 CPU 사용률 최적화
- 높은 메모리 사용률 최적화
- 블로그: Sqlcommenter 소개: 오픈소스 ORM 자동 계측 라이브러리
- 블로그: Sqlcommenter로 쿼리 태그 지정 사용 설정