Auf dieser Seite wird beschrieben, wie Sie das Cloud SQL Systemstatistik-Dashboard verwenden können. Im Systemstatistik-Dashboard werden Messwerte für die Ressourcen angezeigt, die Ihre Instanz verwendet. Außerdem können Sie Probleme mit der Systemleistung erkennen und analysieren.
Sie können die Unterstützung von Gemini in Datenbanken verwenden, um Ihre Cloud SQL for PostgreSQL-Ressourcen zu beobachten und Fehler zu beheben. Weitere Informationen finden Sie unter Mit Gemini in Datenbanken beobachten und Fehler beheben.Systemstatistik-Dashboard aufrufen
So rufen Sie das Systemstatistik-Dashboard auf:
-
Wechseln Sie in der Google Cloud Console zur Seite Cloud SQL-Instanzen.
- Klicken Sie auf den Namen einer Instanz.
Wählen Sie im SQL-Navigationsbereich auf der linken Seite den Tab Systemstatistiken aus.
Das Systemstatistik-Dashboard wird geöffnet.
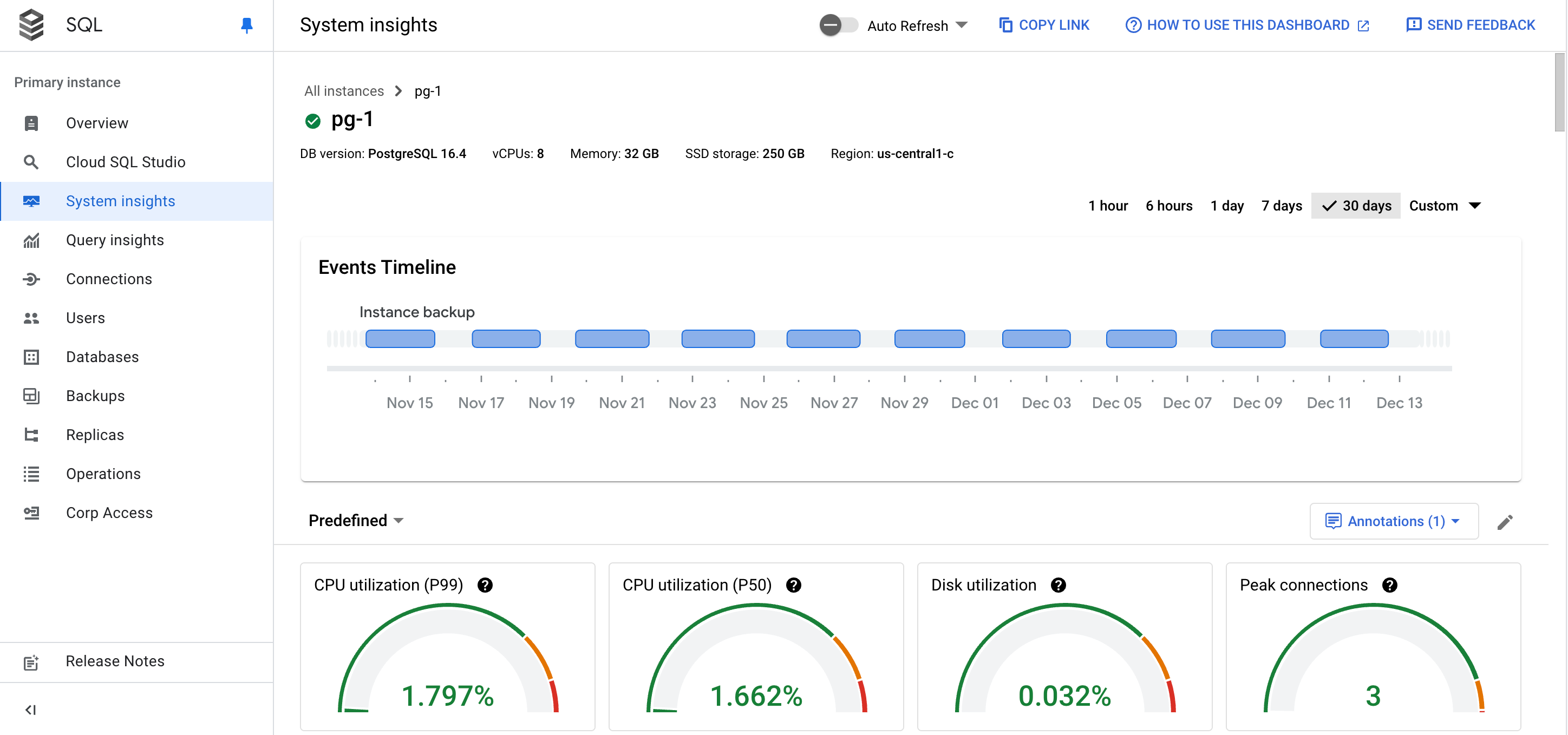
Das Systemstatistik-Dashboard enthält die folgenden Informationen:
Ihre Instanzdetails
Ereigniszeitachse: Hier werden die Systemereignisse in chronologischer Reihenfolge angezeigt. Anhand dieser Informationen können Sie die Auswirkungen von Systemereignissen auf den Status und die Leistung der Instanz bewerten.
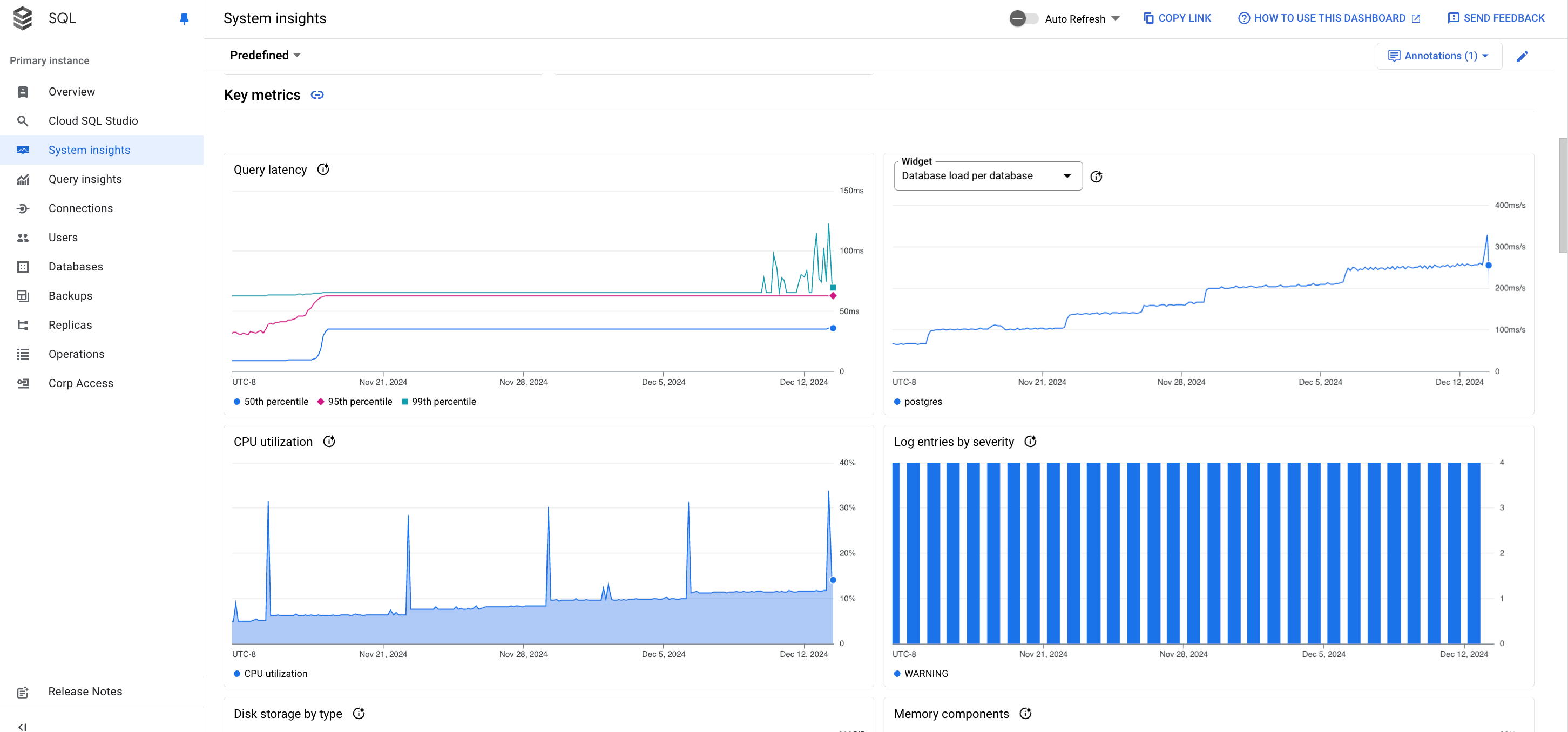
Zusammenfassungskarten: Bieten eine Übersicht über den Zustand und die Leistung der Instanz, indem die neuesten und aggregierten Werte für die Messwerte „CPU-Auslastung“, „Laufwerksauslastung“ und „Protokollfehler“ angezeigt werden.
Messwertdiagramme: enthalten Informationen zu den Messwerten für Betriebssystem und Datenbank, mit denen Sie Einblicke in verschiedene Probleme etwa zu Durchsatz, Latenz und Kosten erhalten.
Das Dashboard bietet die folgenden allgemeinen Optionen:
- Sie können ein oder zwei Diagramme pro Zeile anzeigen lassen. Klicken Sie auf Ansicht anpassen, um festzulegen, wie diese Diagramme dargestellt werden. Sie können damit auch die Messwerte auswählen, die im Dashboard angezeigt werden sollen.
Aktivieren Sie die Option Automatische Aktualisierung
 , um das Dashboard auf dem neuesten Stand zu halten. Wenn Sie Automatisch aktualisieren aktivieren, werden die Dashboarddaten jede Minute aktualisiert. Diese Funktion ist nicht mit benutzerdefinierten Zeiträumen kompatibel.
, um das Dashboard auf dem neuesten Stand zu halten. Wenn Sie Automatisch aktualisieren aktivieren, werden die Dashboarddaten jede Minute aktualisiert. Diese Funktion ist nicht mit benutzerdefinierten Zeiträumen kompatibel.In der Zeitauswahl ist standardmäßig
1 dayausgewählt. Wenn Sie den Zeitraum ändern möchten, wählen Sie einen der anderen vordefinierten Zeiträume aus oder klicken Sie auf Benutzerdefiniert und definieren Sie eine Start- und Endzeit. Es stehen die Daten der letzten 30 Tage zur Verfügung.Zum Erstellen eines absoluten Links zum Dashboard klicken Sie auf Link kopieren. Sie können diesen Link für andere Cloud SQL-Nutzer freigeben, die die gleichen Berechtigungen haben.
Wenn Sie eine Benachrichtigung für ein bestimmtes Ereignis erstellen möchten, klicken Sie auf Benachrichtigung.
Wenn Sie bestimmte Benachrichtigungen anzeigen lassen möchten, klicken Sie auf Anmerkungen.
Zusammenfassungskarten
In der folgenden Tabelle werden die Zusammenfassungskarten beschrieben, die oben im Systemstatistik-Dashboard angezeigt werden. Diese Karten bieten einen kurzen Überblick über den Status und die Leistung der Instanz im ausgewählten Zeitraum.
| Zusammenfassungskarte | Beschreibung |
|---|---|
| CPU-Auslastung – P99 | P50 | Die CPU-Auslastungswerte P99 und P50 im ausgewählten Zeitraum. |
| Höchste Anzahl von Verbindungen | Das Verhältnis der höchsten Anzahl von Verbindungen zur maximalen Anzahl von Verbindungen im ausgewählten Zeitraum.
Die höchste Verbindungsanzahl kann höher sein als die maximale Anzahl, wenn die maximale Anzahl kürzlich geändert wurde, z. B. aufgrund einer Instanzskalierung oder einer manuellen Änderung der Einstellung max_connections. |
| Transaktions-ID-Nutzung | Der aktuelle Wert der Transaktions-ID-Nutzung im ausgewählten Zeitraum. |
| Laufwerksauslastung | Der aktuelle Wert der Laufwerksauslastung. |
| Logfehler | Die Anzahl der Fehler, die Nutzer protokollieren. |
Messwertdiagramme
Eine Diagrammkarte für einen Beispielmesswert wird so angezeigt.
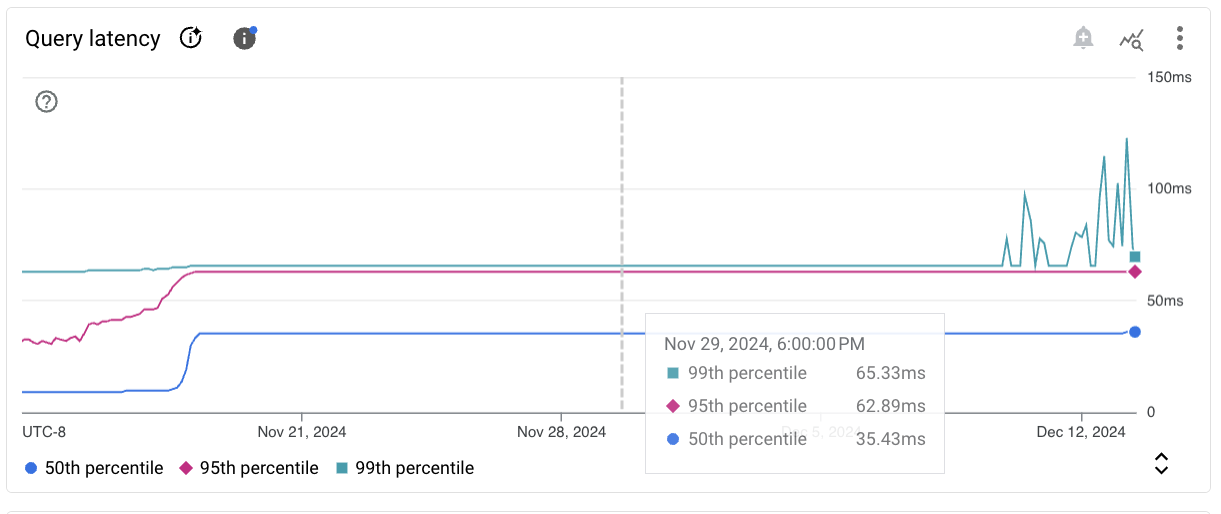
Die Symbolleiste jeder Diagrammkarte enthält folgende Standardoptionen:
Bewegen Sie den Mauszeiger über das Diagramm, um sich Messwerte für einen bestimmten Zeitpunkt im ausgewählten Zeitraum anzusehen.
Wenn Sie ein Diagramm vergrößern möchten, klicken Sie darauf und ziehen Sie es horizontal entlang der X-Achse oder vertikal entlang der Y-Achse. Klicken Sie auf Zoom zurücksetzen, um den Zoomvorgang rückgängig zu machen. Alternativ können Sie oben im Dashboard auf einen der vordefinierten Zeiträume klicken. Zoomvorgänge werden gleichzeitig auf alle Diagramme in einem Dashboard angewendet.
Klicken Sie auf more_vert Weitere Diagrammoptionen, um weitere Optionen aufzurufen. Die meisten Diagramme bieten diese Optionen:
Klicken Sie auf Im Vollbildmodus ansehen, um ein Diagramm im Vollbildmodus anzuzeigen. Wenn Sie den Vollbildmodus beenden möchten, klicken Sie auf Abbrechen.
Legende ausblenden oder minimieren
Ein PNG- oder CSV-Datei des Diagramms herunterladen.
In Metrics Explorer ansehen. Sehen Sie sich den Messwert im Metrics Explorer an. Sie können sich weitere Cloud SQL-Messwerte im Metrics Explorer ansehen, nachdem Sie den Ressourcentyp Cloud SQL-Datenbank ausgewählt haben.
Wenn Sie ein benutzerdefiniertes Dashboard erstellen möchten, klicken Sie auf edit Dashboard anpassen und geben Sie einen Namen ein. Sie können auch das Menü Vordefiniert maximieren und ein vorhandenes benutzerdefiniertes Dashboard auswählen.
Wenn Sie die Daten eines Messwertdiagramms im Detail ansehen möchten, klicken Sie auf query_stats Daten analysieren. Hier können Sie bestimmte Messwerte filtern und auswählen, wie das Diagramm dargestellt werden soll:
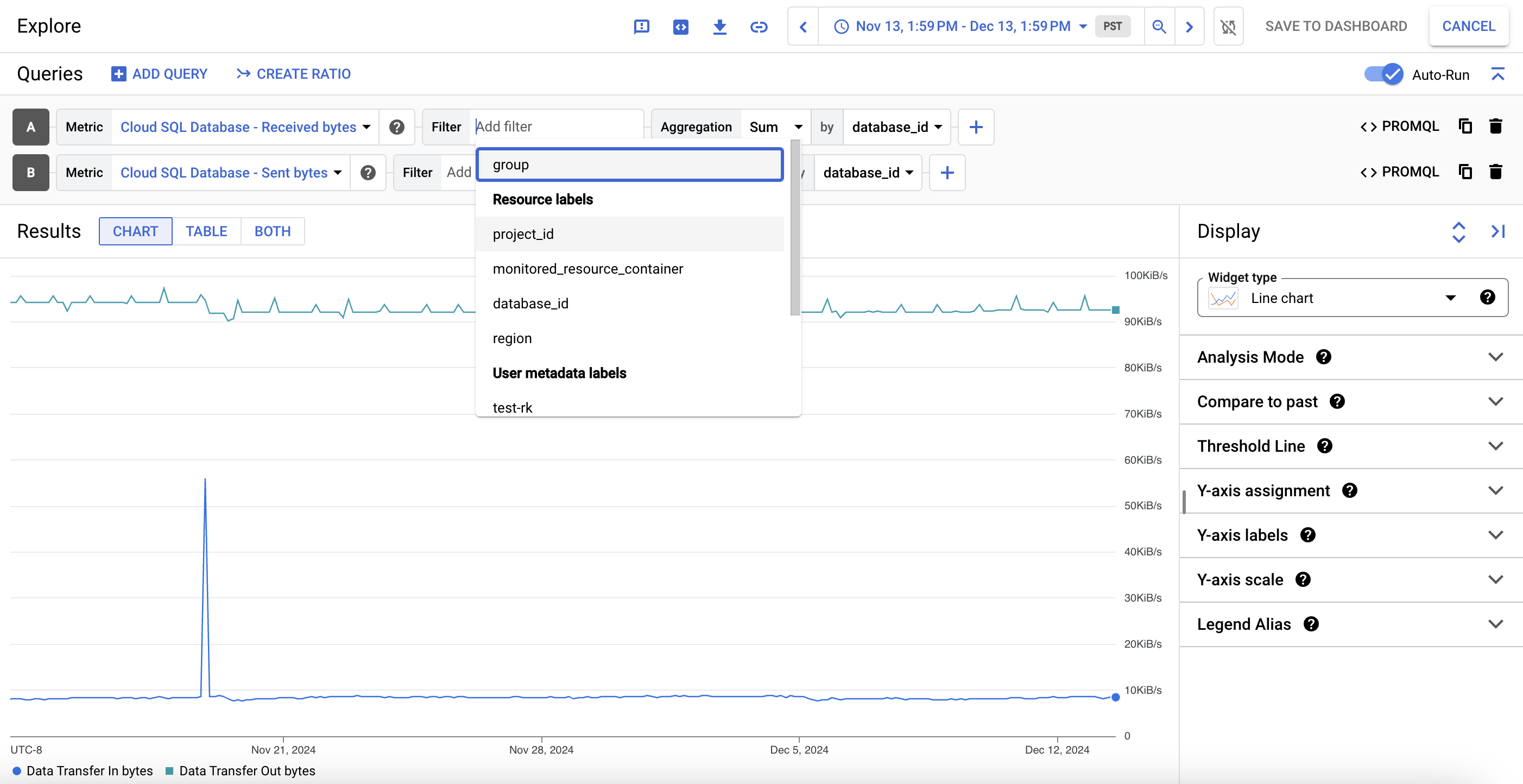
Wenn Sie diese benutzerdefinierte Ansicht als Messwertdiagramm speichern möchten, klicken Sie auf Im Dashboard speichern.
Standardmesswerte
In der folgenden Tabelle werden die Cloud SQL-Messwerte beschrieben, die standardmäßig im Systemstatistik-Dashboard von Cloud SQL angezeigt werden.
Die Messwerttyp-Strings folgen diesem Präfix: cloudsql.googleapis.com/database/.
Die aktuelle Verfügbarkeit der folgenden Messwerte in der Einführungsphase finden Sie unter Google Cloud -Messwerte.
| Name und Typ des Messwerts | Beschreibung |
|---|---|
Neue Verbindungen pro Sekundepostgresql/new_connection_count
|
Die Anzahl der neuen Verbindungen pro Sekunde, die Sie auf der Cloud SQL for PostgreSQL-Instanz erstellen. Cloud SQL berechnet und zeigt diesen Messwert pro Datenbank an. Dieser Messwert ist für PostgreSQL Version 14 und höher verfügbar. |
Warteereignistypen
postgresql/backends_in_wait
|
Die Anzahl der Verbindungen für jeden Warteereignistyp in einer Cloud SQL for PostgreSQL-Instanz. |
Warteereignissepostgresql/backends_in_wait
|
Anzahl der Warteereignisse in einer Cloud SQL for PostgreSQL-Instanz. Im Dashboard wird dieser Messwert als Warteereignisname angezeigt:warte ereignis type. |
Anzahl der Transaktionenpostgresql/transaction_count
|
Die Anzahl der Transaktionen im Status |
Arbeitsspeicherkomponentenmemory/components
|
Die für die Datenbank verfügbaren Arbeits-Speicherkomponenten Der Wert für jede Arbeits-Speicherkomponente wird als Prozentsatz des Gesamtarbeitsspeichers berechnet, der der Datenbank zur Verfügung steht. |
Maximale Replikatverzögerung in Bytepostgresql/external_sync/max_replica_byte_lag
|
Dies ist die maximale Replikationsverzögerung in Byte unter allen Datenbanken auf dem Replikat des externen Servers (ES). |
Abfragelatenzpostgresql/insights/aggregate/latencies |
Die zusammengefasste Abfragelatenzverteilung pro Nutzer und Datenbank nach 99., 95. und 50. Perzentil. Nur für Instanzen verfügbar, bei denen Query Insights aktiviert ist. |
Datenbanklast pro Datenbank/Nutzer/Clientadressepostgresql/insights/aggregate/execution_time |
Die akkumulierte Abfrageausführungszeit pro Datenbank, Nutzer oder Clientadresse. Dies ist die Summe aus CPU-Zeit, E/A-Wartezeit, Wartezeit für Sperrungen, Prozesskontextwechsel und Planung für alle Prozesse, die an der Abfrageausführung beteiligt sind. Nur für Instanzen verfügbar, bei denen Query Insights aktiviert ist. |
CPU-Auslastungcpu/utilization |
Die aktuelle CPU-Auslastung, dargestellt als Prozentsatz der reservierten CPU, die derzeit verwendet wird. |
Laufwerksspeicher nach Typdisk/bytes_used_by_data_type
|
Die Aufschlüsselung der Instanzlaufwerksnutzung nach Datentypen, einschließlich Dieser Messwert hilft Ihnen, Ihre Speicherkosten nachzuvollziehen. Weitere Informationen zu Gebühren für die Speichernutzung finden Sie unter Speicher- und Netzwerkpreise. Die Wiederherstellung zu einem bestimmten Zeitpunkt (Point-In-Time Recovery, PITR) verwendet die WAL-Archivierung (Write-Ahead Log). Diese Logs werden regelmäßig aktualisiert und belegen Speicherplatz. Write-Ahead-Logs werden automatisch mit der zugehörigen automatischen Sicherung gelöscht, was in der Regel nach etwa sieben Tagen erfolgt. Wenn die Größe der Write-Ahead-Logs für die Instanz ein Problem darstellt, können Sie die Speichergröße erhöhen. Die Größe des Write-Ahead-Logs wird jedoch möglicherweise nur vorübergehend erhöht. Damit unerwartete Speicherprobleme vermieden werden, empfiehlt Google, die automatische Speichererweiterung bei Verwendung von PITR zu aktivieren. Wenn Sie die Logs löschen und Speicherplatz zurückgewinnen möchten, können Sie die Wiederherstellung zu einem bestimmten Zeitpunkt deaktivieren. Die Größe des für die Instanz bereitgestellten Speichers reduziert sich durch die Verringerung des verwendeten Speicherplatzes jedoch nicht. Der Messwert zur Speicherauslastung berücksichtigt auch temporäre Daten. Temporäre Daten werden im Rahmen der Wartung entfernt und können sich ohne Zusatzkosten für den Nutzer über benutzerdefinierte Kapazitätsgrenzen hinaus erhöhen. Damit lässt sich das Ereignis eines vollen Laufwerks vermeiden. Eine neu erstellte Datenbank belegt etwa 100 MB für Systemtabellen und -dateien. |
Laufwerksspeicher nach Typdisk/bytes_used_by_data_type
|
Die Aufschlüsselung der Instanzlaufwerksnutzung nach Datentypen, einschließlich Dieser Messwert hilft Ihnen, Ihre Speicherkosten nachzuvollziehen. Weitere Informationen zu Gebühren für die Speichernutzung finden Sie unter Speicher- und Netzwerkpreise. Bei der Wiederherstellung zu einem bestimmten Zeitpunkt wird die WA-Archivierung (Write-Ahead Logging) verwendet. Für neue Cloud SQL-Instanzen, für die die Wiederherstellung zu einem bestimmten Zeitpunkt aktiviert ist, oder für vorhandene Instanzen, die die Wiederherstellung zu einem bestimmten Zeitpunkt aktivieren, nachdem dieses Feature zum Speichern von WAL-Logs in Cloud Storage verfügbar ist, werden Logs nicht mehr auf dem Laufwerk gespeichert; Stattdessen werden sie in Cloud Storage in derselben Region wie die Instanzen gespeichert. Sie können sehen, ob die Logs einer Instanz in Cloud Storage gespeichert werden. Dazu prüfen Sie den Messwert bytes_used_by_data_type. Wenn der Wert für den Datentyp Bei allen anderen Instanzen, für die die Wiederherstellung zu einem bestimmten Zeitpunkt aktiviert ist, werden die zugehörigen Logs weiterhin auf dem Laufwerk gespeichert. Die Änderung zum Speichern von Logs in Cloud Storage wird zu einem späteren Zeitpunkt zur Verfügung gestellt. Die Write-Ahead-Logs, die mit der Wiederherstellung zu einem bestimmten Zeitpunkt verwendet werden, werden automatisch mit der zugehörigen automatischen Sicherung gelöscht. Dies geschieht in der Regel, wenn der für transactionLogRetentionDays festgelegte Wert erreicht ist. Dies ist die Anzahl der Tage, die Transaktionslogs in Cloud SQL für die Wiederherstellung zu einem bestimmten Zeitpunkt aufbewahrt werden (von 1 bis 7). Bei Instanzen mit Write-Ahead-Logs in Cloud Storage werden die Logs in derselben Region wie die primäre Instanz gespeichert. Für diesen Logspeicher (bis zu sieben Tage, die maximale Länge für die Wiederherstellung zu einem bestimmten Zeitpunkt) fallen keine zusätzlichen Kosten pro Instanz an. Wenn die Wiederherstellung zu einem bestimmten Zeitpunkt aktiviert ist und die Größe der Write-Ahead-Logs auf dem Laufwerk ein Problem für die Instanz verursacht, deaktivieren Sie die Wiederherstellung zu einem bestimmten Zeitpunkt und aktivieren Sie sie noch einmal, damit neue Logs in Cloud Storage in derselben Region wie die Instanz gespeichert werden. Dadurch werden vorhandene Write-Ahead-Logs gelöscht, sodass Sie eine Wiederherstellung zu einem bestimmten Zeitpunkt erst wieder ab dem Zeitpunkt ausführen können, zu dem Sie die Wiederherstellung zu einem bestimmten Zeitpunkt wieder aktiviert haben. Obwohl die vorhandenen Logs gelöscht werden, bleibt die Laufwerksgröße gleich. Damit unerwartete Speicherprobleme vermieden werden, empfehlen wir die Aktivierung von automatischen Speichererweiterungen für alle Instanzen, wenn die Wiederherstellung zu einem bestimmten Zeitpunkt verwendet wird. Diese Empfehlung gilt nur, wenn auf Ihrer Instanz die Wiederherstellung zu einem bestimmten Zeitpunkt aktiviert ist und Ihre Logs auf dem Laufwerk gespeichert sind. Wenn Sie die Logs löschen und Speicherplatz zurückgewinnen möchten, können Sie die Wiederherstellung zu einem bestimmten Zeitpunkt deaktivieren. Die Größe des für die Instanz bereitgestellten Laufwerks wird jedoch durch das Verringern der verwendeten Write-Ahead-Logs nicht reduziert. Der Messwert zur Speicherauslastung berücksichtigt auch temporäre Daten. Temporäre Daten werden im Rahmen der Wartung entfernt und können sich ohne Zusatzkosten für den Nutzer über benutzerdefinierte Kapazitätsgrenzen hinaus erhöhen. Damit lässt sich das Ereignis eines vollen Laufwerks vermeiden. Eine neu erstellte Datenbank belegt etwa 100 MB für Systemtabellen und -dateien. |
Lese-/Schreibvorgänge des Laufwerksdisk/read_ops_count, disk/write_ops_count |
Der Messwert für die Anzahl der Lesevorgänge gibt an, wie viele Lesevorgänge vom Laufwerk und nicht aus dem Cache erfolgen. Mit diesem Messwert können Sie einschätzen, ob Ihre Instanz die richtige Größe für Ihre Umgebung hat. Bei Bedarf können Sie zu einem größeren Maschinentyp wechseln, um mehr Anfragen aus dem Cache zu bedienen und so die Latenz zu verringern. Der Messwert für die Anzahl der Schreibvorgänge gibt die Anzahl der Schreibvorgänge auf der Festplatte an. Auch wenn Ihre Anwendung nicht aktiv ist, werden Schreibaktivitäten generiert, da Cloud SQL-Instanzen und Replikate etwa jede Sekunde in eine Systemtabelle schreiben. |
Verbindungen nach Statuspostgresql/num_backends_by_state |
Die Anzahl der Verbindungen, die nach diesen Status gruppiert sind: Informationen zu diesen Status finden Sie in der Zeile |
Verbindungen pro Datenbankpostgresql/num_backends |
Die Anzahl der Verbindungen, die von der Datenbankinstanz gehalten werden. |
Eingehende/Ausgehende Bytenetwork/received_bytes_count, network/sent_bytes_count |
Der Netzwerk-Traffic in Bezug auf die Anzahl der eingehenden (empfangenen) Byte und ausgehenden (gesendeten) Byte zur bzw. von der Instanz. |
Aufschlüsselung der E/A-Wartezeit nach Typpostgresql/insights/aggregate/io_time |
Die Aufschlüsselung der E/A-Wartezeit für SQL-Anweisungen nach Lese- bzw. Schreibtyp. Nur für Instanzen verfügbar, bei denen Query Insights aktiviert ist. |
Deadlock-Anzahl nach Datenbankpostgresql/deadlock_count |
Die Anzahl der Deadlocks pro Datenbank. |
Anzahl der Blocking-Lesezugriffepostgresql/blocks_read_count |
Die Anzahl der pro Sekunde aus dem Laufwerk und dem Zwischenspeicher gelesenen Blöcke. |
Verarbeitete Zeilen pro Vorgangpostgresql/tuples_processed_count |
Die Anzahl der pro Vorgang und Sekunde verarbeiteten Zeilen. |
Zeilen in Datenbank nach Statuspostgresql/tuple_size |
Die Anzahl der Zeilen für jeden Datenbankstatus. Cloud SQL meldet diesen Messwert, wenn die Anzahl der Datenbanken in der Instanz weniger als 50 beträgt. |
Älteste Transaktion nach Alterpostgresql/vacuum/oldest_transaction_age |
Das Alter der ältesten Transaktion, die den Bereinigungsvorgang blockiert. |
WAL-Archivierungreplication/log_archive_success_count, replication/log_archive_failure_count |
Die Anzahl der Write-Ahead-Logdateien, die pro Minute erfolgreich oder nicht erfolgreich archiviert wurden. |
Transaktions-ID-Nutzungpostgresql/transaction_id_utilization |
Der Prozentsatz der in der Instanz verwendeten Transaktions-IDs. |
Anzahl der Verbindungen pro Anwendungsnamepostgresql/num_backends_by_application |
Die Anzahl der Verbindungen zur Cloud SQL-Instanz, gruppiert nach Anwendungen. |
Vergleich zwischen abgerufenen Zeilen, zurückgegebenen Zeilen und geschriebenen Zeilen
|
Wenn der Unterschied zwischen den zurückgegebenen Zeilen und den abgerufenen Zeilen so groß ist, dass ihre Werte nicht im gleichen Maßstab angezeigt werden, wird der Wert der abgerufenen Zeilen als 0 angezeigt, da er im Vergleich zum Wert der zurückgegebenen Zeilen vernachlässigbar ist. |
Temporäre Datengrößepostgresql/temp_bytes_written_count |
Die Gesamtmenge der Daten (in Byte), die zum Ausführen von Abfragen und Algorithmen wie Join und Sortieren verwendet werden. |
Temporäre Dateienpostgresql/temp_files_written_count |
Die Anzahl der temporären Dateien, die zum Ausführen von Abfragen und Algorithmen wie Join und Sortieren verwendet werden. |
Außerdem zeigt der Cloud Logging-Messwert Logeinträge nach Schweregrad (logging.googleapis.com/log_entry_count) die Gesamtzahlen der Fehler- und Warnungslogeinträge an.
Diese werden aus postgres.log (Datenbanklog) und aus pgaudit.log, das Datenzugriffsinformationen enthält, extrahiert.
Weitere Informationen finden Sie unter Cloud SQL-Messwerte.
Ereigniszeitachse
Das Dashboard enthält die Details der folgenden Ereignisse:
| Ereignisname | Beschreibung | Vorgangstyp |
|---|---|---|
Instance restart |
Startet die Cloud SQL-Instanz neu | RESTART |
Instance failover |
Initiiert einen manuellen Failover einer primären Hochverfügbarkeitsinstanz (HA) zu einer Standby-Instanz, die zur primären Instanz wird. | FAILOVER |
Instance maintenance |
Gibt an, dass die Instanz derzeit gewartet wird. Normalerweise führt dies dazu, dass die Instanz 1 bis 3 Minuten lang nicht verfügbar ist. | MAINTENANCE |
Instance backup |
Führt eine Instanzsicherung durch. | BACKUP_VOLUME |
Instance update |
Aktualisiert die Einstellungen einer Cloud SQL-Instanz. | UPDATE |
Promote replica |
Stuft eine Cloud SQL-Replikatinstanz hoch. | PROMOTE_REPLICA |
Start replica |
Startet die Replikation auf einer Cloud SQL-Lesereplikatinstanz. | START_REPLICA |
Stop replica |
Beendet die Replikation auf einer Cloud SQL-Lesereplikatinstanz. | STOP_REPLICA |
Recreate replica |
Erstellt Ressourcen für eine Cloud SQL-Replikatinstanz neu. | RECREATE_REPLICA |
Create replica |
Erstellt eine Cloud SQL-Replikatinstanz. | CREATE_REPLICA |
Data import |
Importiert Daten in eine Cloud SQL-Instanz. | IMPORT |
Instance export |
Exportiert Daten aus einer Cloud SQL-Instanz in einen Cloud Storage-Bucket. | EXPORT |
Restore backup |
Stellt eine Sicherung einer Cloud SQL-Instanz wieder her. Durch diesen Vorgang wird Ihre Instanz möglicherweise neu gestartet. | RESTORE_VOLUME |