이 페이지에서는 Cloud SQL 시스템 통계 대시보드를 사용하는 방법을 설명합니다. 시스템 통계 대시보드는 인스턴스가 사용하는 리소스에 대한 측정항목을 표시하고 시스템 성능 문제를 감지하고 분석하는 데 도움이 됩니다.
Databases의 Gemini 지원을 사용하여 PostgreSQL용 Cloud SQL 리소스를 관찰하고 문제를 해결할 수 있습니다. 자세한 내용은 Gemini 지원을 통한 관찰 및 문제 해결을 참조하세요.시스템 통계 대시보드 보기
시스템 통계 대시보드를 보려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 Cloud SQL 인스턴스 페이지로 이동합니다.
- 인스턴스 이름을 클릭합니다.
왼쪽의 SQL 탐색 패널에서 시스템 통계 탭을 선택합니다.
시스템 통계 대시보드가 열립니다.
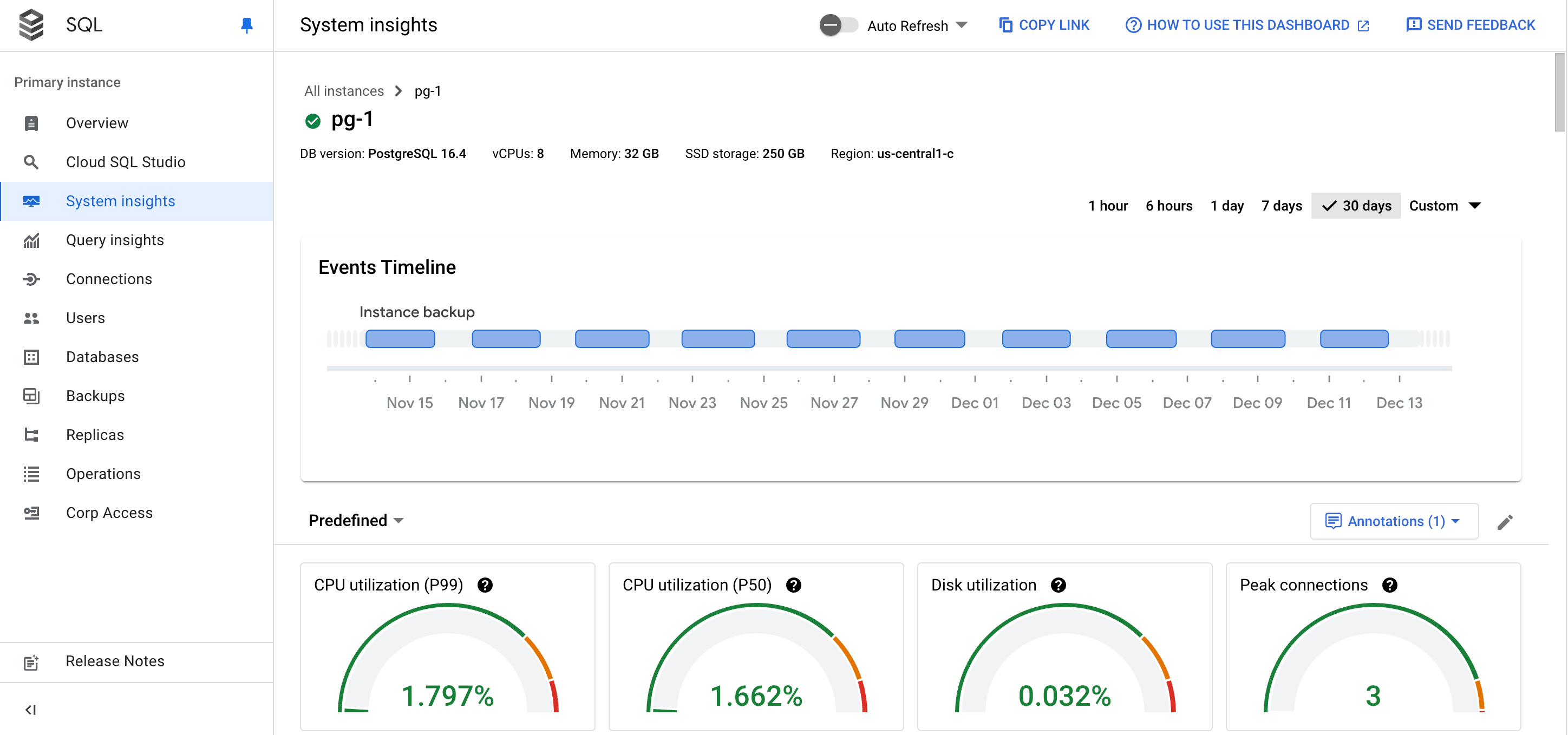
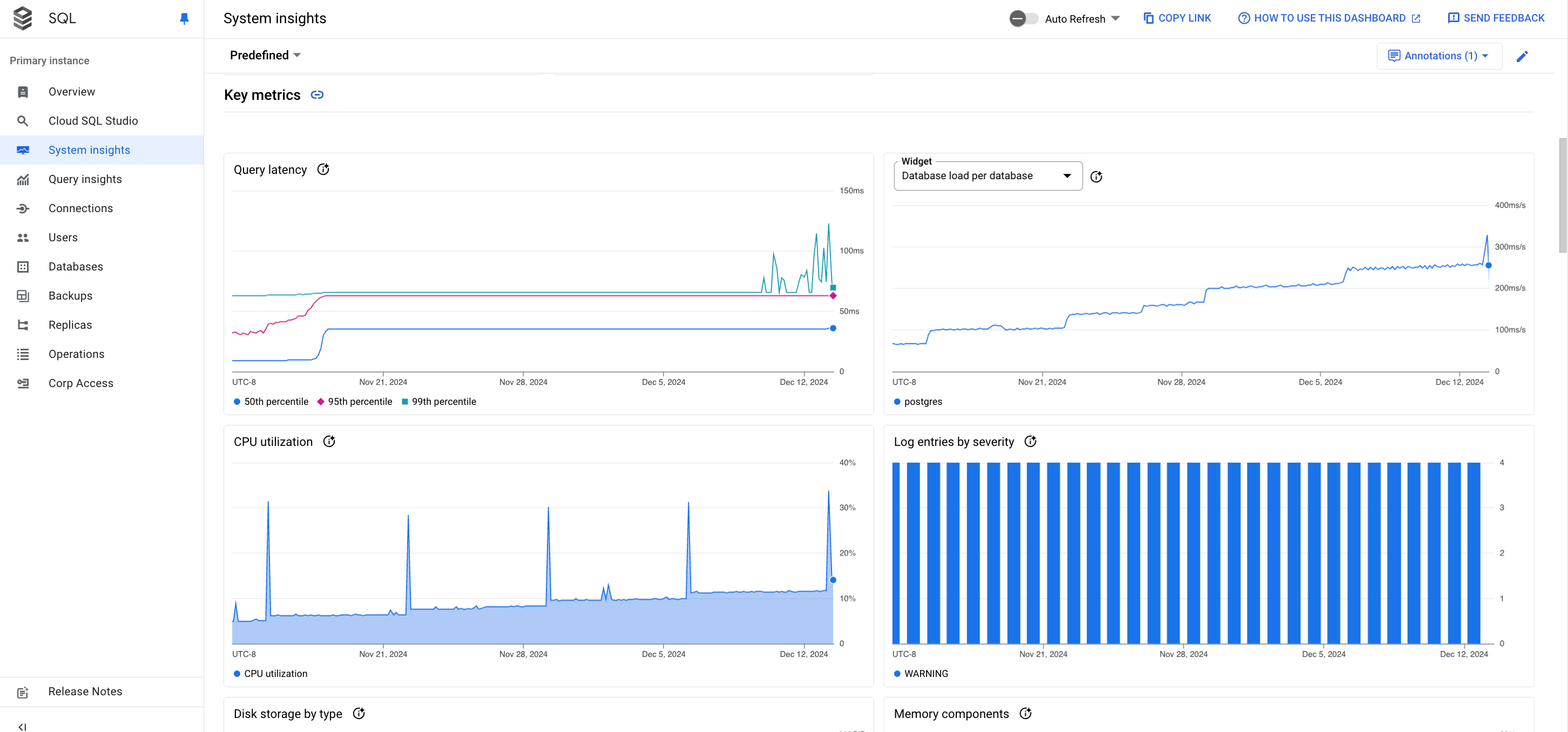
시스템 통계 대시보드에는 다음 정보가 표시됩니다.
인스턴스 세부정보
이벤트 타임라인: 시스템 이벤트를 시간순으로 표시합니다. 이 정보는 시스템 이벤트가 인스턴스의 상태와 성능에 미치는 영향을 평가하는 데 도움이 됩니다.
요약 카드: CPU 사용률, 디스크 사용률, 로그 오류 측정항목에 대한 최신 값과 집계된 값을 표시하여 인스턴스 상태 및 성능에 대한 개요를 제공합니다.
측정항목 차트: 처리량, 지연 시간, 비용과 같은 여러 문제에 대한 유용한 정보를 얻는 데 도움이 되는 운영체제 및 데이터베이스 측정항목에 대한 정보를 표시합니다.
대시보드는 다음과 같은 간략한 옵션을 제공합니다.
- 행당 차트 1개 또는 2개를 보려면 뷰 맞춤설정을 클릭하여 이러한 차트가 표시되는 방식을 선택합니다. 이 옵션을 사용하여 대시보드에 표시할 측정항목을 선택할 수도 있습니다.
대시보드를 최신 상태로 유지하려면
 자동 새로고침 옵션을 사용 설정합니다. 자동 새로고침을 사용 설정하면 대시보드 데이터가 1분마다 업데이트됩니다. 이 기능은 맞춤설정된 기간과 호환되지 않습니다.
자동 새로고침 옵션을 사용 설정합니다. 자동 새로고침을 사용 설정하면 대시보드 데이터가 1분마다 업데이트됩니다. 이 기능은 맞춤설정된 기간과 호환되지 않습니다.기본적으로 시간 선택기에는 선택된
1 day가 표시됩니다. 기간을 변경하려면 사전 정의된 다른 기간 중 하나를 선택하거나 커스텀을 클릭하고 시작 및 종료 시간을 정의합니다. 지난 30일 동안의 데이터가 제공됩니다.대시보드의 절대 링크를 만들려면 링크 복사 버튼을 클릭합니다. 같은 권한이 있는 다른 Cloud SQL 사용자와 이 링크를 공유할 수 있습니다.
특정 이벤트에 대한 알림을 만들려면 알림을 클릭합니다.
특정 알림을 표시하려면 주석을 클릭합니다.
요약 카드
다음 표에서는 시스템 통계 대시보드 상단에 표시되는 요약 카드를 설명합니다. 이러한 카드에서는 선택한 기간 동안의 인스턴스 상태 및 성능에 대한 간략한 개요를 제공합니다.
| 요약 카드 | 설명 |
|---|---|
| CPU 사용률 - P99 | P50 | 선택한 기간 동안 P99 및 P50 CPU 사용률 값입니다. |
| 최대 연결 수 | 선택한 기간 중 최고 연결 수 및 최대 연결 수의 비율입니다.
최대 연결 수는 인스턴스 확장 또는 max_connections 설정 수동 변경과 같이 최근에 최대 수가 변경된 경우 최대 수보다 클 수 있습니다. |
| 트랜잭션 ID 사용률 | 선택한 기간의 최신 트랜잭션 ID 사용률 값입니다. |
| 디스크 사용률 | 최신 디스크 사용률 값입니다. |
| 로그 오류 | 사용자가 로깅하는 오류 수입니다. |
측정항목 차트
샘플 측정항목의 차트 카드가 다음과 같이 표시됩니다.
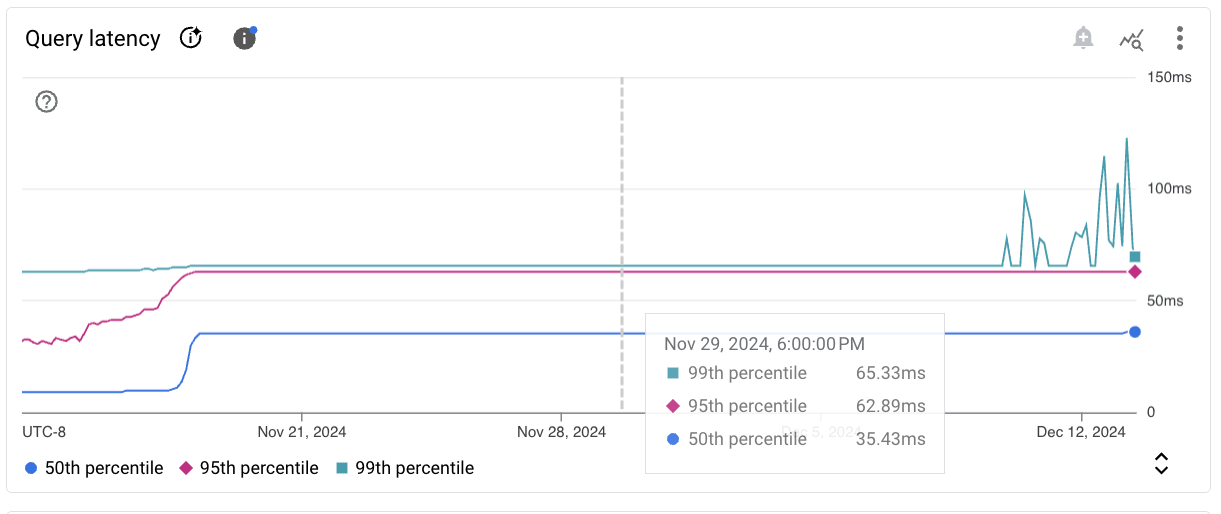
각 차트 카드의 툴바는 다음과 같은 표준 옵션 집합을 제공합니다.
선택한 기간의 특정 시점에 대한 측정항목 값을 보려면 커서를 차트 위로 이동합니다.
차트를 확대하려면 차트를 클릭하고 x축을 따라 가로로 또는 y축을 따라 세로로 드래그합니다. 확대/축소 작업을 되돌리려면 확대/축소 재설정을 클릭합니다. 또는 대시보드 상단에 있는 사전 정의된 기간 중 하나를 클릭합니다. 확대/축소 작업은 대시보드의 모든 차트에 동시 적용됩니다.
추가 옵션을 보려면 more_vert 차트 옵션 더보기를 클릭합니다. 대부분의 차트에서 다음 옵션을 제공합니다.
차트를 전체 화면 모드로 보려면 전체 화면 보기를 클릭합니다. 전체 화면 모드를 종료하려면 취소를 클릭합니다.
범례를 숨기거나 접습니다.
차트의 PNG 또는 CSV 파일을 다운로드합니다.
측정항목 탐색기에서 보기. 측정항목 탐색기에서 측정항목을 봅니다. Cloud SQL 데이터베이스 리소스 유형을 선택하면 측정항목 탐색기에서 다른 Cloud SQL 측정항목을 볼 수 있습니다.
커스텀 대시보드를 만들려면 edit 대시보드 맞춤설정을 클릭하고 이름을 지정합니다. 또는 사전 정의됨 메뉴를 펼치고 기존 커스텀 대시보드를 선택합니다.
측정항목 차트의 데이터를 자세히 보려면 query_stats 데이터 탐색을 클릭합니다. 여기에서 특정 측정항목을 필터링하고 차트 표시 방식을 선택할 수 있습니다.
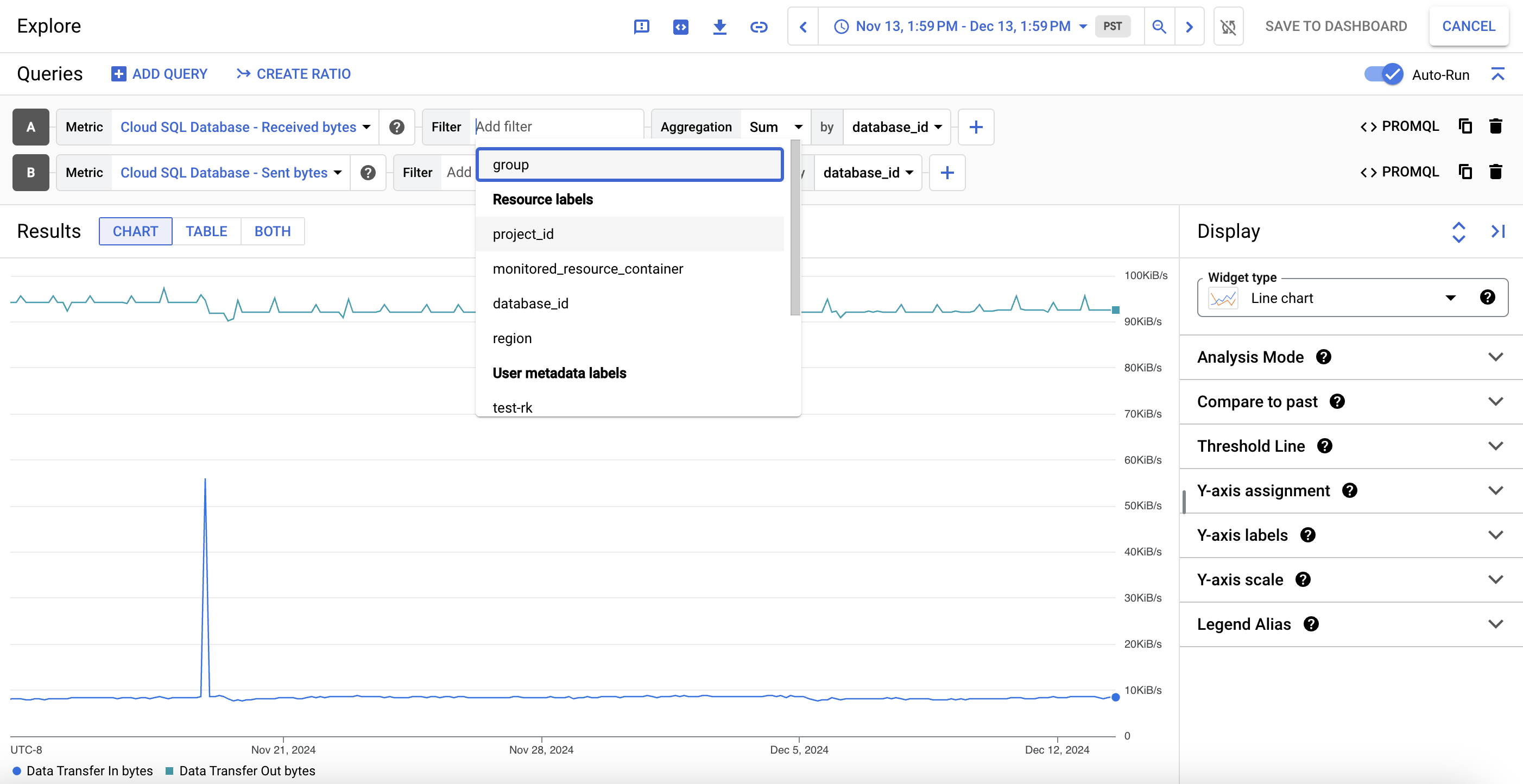
이 맞춤설정된 뷰를 측정항목 차트로 저장하려면 대시보드에 저장을 클릭합니다.
기본 측정항목
다음 표에서는 Cloud SQL 시스템 통계 대시보드에 기본적으로 표시되는 Cloud SQL 측정항목을 설명합니다.
측정항목 유형 문자열은 cloudsql.googleapis.com/database/ 프리픽스를 따릅니다.
다음 측정항목의 최신 출시 단계 사용 가능 여부는 Google Cloud 측정항목을 참고하세요.
| 측정항목 이름 및 유형 | 설명 |
|---|---|
초당 새로운 연결postgresql/new_connection_count
|
PostgreSQL용 Cloud SQL 인스턴스에서 만드는 새 연결 수의 초당 속도입니다. Cloud SQL은 데이터베이스별로 이 측정항목을 계산하고 표시합니다. 이 측정항목은 PostgreSQL 버전 14 이상에서 사용할 수 있습니다. |
대기 이벤트 유형
postgresql/backends_in_wait
|
PostgreSQL용 Cloud SQL 인스턴스에서 각 대기 이벤트 유형에 대한 연결 수입니다. |
대기 이벤트postgresql/backends_in_wait
|
PostgreSQL용 Cloud SQL 인스턴스의 대기 이벤트 수입니다. 대시보드에 이 측정항목이 대기 이벤트 이름:대기 이벤트 유형으로 표시됩니다. |
트랜잭션 수postgresql/transaction_count
|
PostgreSQL용 Cloud SQL 인스턴스의 |
메모리 구성요소memory/components
|
데이터베이스에서 사용할 수 있는 메모리 구성요소입니다. 각 메모리 구성요소의 값은 데이터베이스에서 사용할 수 있는 총 메모리의 비율로 계산됩니다. |
최대 복제본 바이트 지연postgresql/external_sync/max_replica_byte_lag
|
외부 서버(ES) 복제본의 모든 데이터베이스 간 최대 복제 지연(바이트)입니다. |
쿼리 지연 시간postgresql/insights/aggregate/latencies |
사용자 및 데이터베이스당 P99, P95, P50 기준별로 집계된 쿼리 지연 시간 분포입니다. 쿼리 통계가 사용 설정된 인스턴스에서만 사용할 수 있습니다. |
데이터베이스/사용자/클라이언트 주소당 데이터베이스 로드postgresql/insights/aggregate/execution_time |
데이터베이스, 사용자 또는 클라이언트 주소별로 누적된 쿼리 실행 시간입니다. 쿼리 실행과 관련된 모든 프로세스에 대한 CPU 시간, I/O 대기 시간, 잠금 대기 시간, 프로세스 컨텍스트 전환, 예약의 합계입니다. 쿼리 통계가 사용 설정된 인스턴스에서만 사용할 수 있습니다. |
CPU 사용률cpu/utilization |
현재 CPU 사용률로, 현재 사용 중인 예약된 CPU의 비율로 표시됩니다. |
유형별 디스크 스토리지disk/bytes_used_by_data_type
|
이 측정항목을 사용하면 스토리지 비용을 파악할 수 있습니다. 스토리지 사용 비용에 대한 자세한 내용은 스토리지 및 네트워킹 가격 책정을 참조하세요. point-in-time recovery(PITR)는 미리 쓰기 로그(WAL) 보관처리를 사용합니다. 이 로그는 정기적으로 업데이트되고 저장공간을 사용합니다. 미리 쓰기 로그는 일반적으로 약 7일 후에 관련된 자동 백업과 함께 자동으로 삭제됩니다. 미리 쓰기 로그 크기로 인해 인스턴스에 문제가 발생하면 스토리지 크기를 늘리면 됩니다. 하지만 미리 쓰기 로그 크기에 따른 디스크 사용량 증가가 일시적인 것일 수도 있습니다. PITR을 사용할 때는 예기치 않은 스토리지 문제가 발생하지 않도록 스토리지 자동 증가를 사용 설정하는 것이 좋습니다. 로그를 삭제하고 저장용량을 복구하려면 point-in-time recovery를 중지하면 됩니다. 하지만 사용되는 저장용량을 줄여도 인스턴스에 프로비저닝된 저장용량의 크기가 축소되지 않습니다. 임시 데이터는 스토리지 사용량 측정항목에 포함됩니다. 임시 데이터는 유지보수의 일부로 삭제되며 디스크 용량 부족 이벤트를 방지하기 위해 사용자가 정의한 용량 한도를 초과하여 무료로 늘릴 수 있습니다. 새로 만든 데이터베이스는 시스템 테이블 및 파일을 위해 약 100MB를 사용합니다. |
유형별 디스크 스토리지disk/bytes_used_by_data_type
|
이 측정항목을 사용하면 스토리지 비용을 파악할 수 있습니다. 스토리지 사용 비용에 대한 자세한 내용은 스토리지 및 네트워킹 가격 책정을 참조하세요. point-in-time recovery에는 미리 쓰기 로깅(WAL) 보관처리가 사용됩니다. point-in-time recovery가 사용 설정된 새 Cloud SQL 인스턴스 또는 Cloud Storage에 WAL을 저장하기 위해 이 기능을 사용할 수 있게 된 다음에 point-in-time recovery를 사용 설정하는 기존 인스턴스의 경우 로그가 더 이상 디스크에 저장되지 않습니다. 대신 인스턴스와 동일한 리전에 있는 Cloud Storage에 저장됩니다. 인스턴스 로그가 Cloud Storage에 저장되었는지 여부를 보려면 인스턴스의 bytes_used_by_data_type 측정항목을 확인합니다. point-in-time recovery가 사용 설정된 모든 다른 기존 인스턴스는 해당 로그가 계속 디스크에 저장됩니다. Cloud Storage에서 로그 저장에 대한 변경은 나중에 사용할 수 있습니다. point-in-time recovery에 사용된 미리 쓰기 로그는 일반적으로 transactionLogRetentionDays에 대해 설정된 값이 충족된 다음에 발생하는 연관된 자동 백업과 함께 자동으로 삭제됩니다. 이것은 Cloud SQL이 point-in-time recovery에 대해 보존하는 트랜잭션 로그 일 수(1~7)입니다. 미리 쓰기 로그가 Cloud Storage에 저장된 인스턴스의 경우 로그가 기본 인스턴스와 동일한 리전에 저장됩니다. 이러한 로그 스토리지(point-in-time recovery의 최대 기간 7일)는 인스턴스당 추가 비용을 발생시키지 않습니다. 인스턴스에 point-in-time recovery가 사용 설정되어 있고 디스크에서 미리 쓰기 로그 크기로 인해 인스턴스 문제가 발생하는 경우에는 point-in-time recovery를 사용 중지하고 다시 사용 설정하여 새 로그가 인스턴스와 동일한 리전의 Cloud Storage에 저장되는지 확인합니다. 이렇게 하면 기존 미리 쓰기 로그가 삭제되므로, point-in-time recovery를 다시 사용 설정한 시간 이전에 point-in-time recovery를 수행할 수 없습니다. 그러나 기존 로그는 삭제되더라도 디스크 크기는 동일하게 유지됩니다. 예기치 않은 스토리지 문제를 방지하려면 PITR(point-in-time recovery)을 사용할 때 모든 인스턴스에 스토리지 용량 자동 증가를 사용 설정하는 것이 좋습니다. 이 권장사항은 인스턴스에 PITR(point-in-time recovery)이 사용 설정되어 있고 로그가 디스크에 저장된 경우에만 적용됩니다. 로그를 삭제하고 저장용량을 복구하려면 point-in-time recovery를 중지하면 됩니다. 그러나 사용되는 미리 쓰기 로그를 줄이면 인스턴스에 프로비저닝된 디스크 크기가 축소되지 않습니다. 임시 데이터는 스토리지 사용량 측정항목에 포함됩니다. 임시 데이터는 유지보수의 일부로 삭제되며 디스크 용량 부족 이벤트를 방지하기 위해 사용자가 정의한 용량 한도를 초과하여 무료로 늘릴 수 있습니다. 새로 만든 데이터베이스는 시스템 테이블 및 파일을 위해 약 100MB를 사용합니다. |
디스크 읽기/쓰기 작업disk/read_ops_count, disk/write_ops_count |
읽기 수 측정항목은 디스크에서 제공된 읽기 작업 중에서 캐시에서 가져오지 않은 작업의 수를 나타냅니다. 이 측정항목을 사용하여 인스턴스 크기가 사용자 환경에 맞게 지정되었는지 파악할 수 있습니다. 필요한 경우 더 큰 머신 유형으로 전환하여 캐시에서 더 많은 요청을 처리하고 지연 시간을 줄일 수 있습니다. 쓰기 수 측정항목은 디스크에 대한 쓰기 작업 수를 나타냅니다. 쓰기 작업은 애플리케이션이 활성 상태가 아니어도 생성됩니다. Cloud SQL 인스턴스(복제본 제외)는 약 1초 간격으로 시스템 테이블에 쓰기 때문입니다. |
상태별 연결postgresql/num_backends_by_state |
이러한 상태에 대한 자세한 내용은 |
데이터베이스당 연결postgresql/num_backends |
데이터베이스 인스턴스가 보유한 연결 수입니다. |
인그레스/이그레스 바이트network/received_bytes_count, network/sent_bytes_count |
인스턴스와 주고받은 각 인그레스 바이트 수(수신된 바이트) 및 이그레스 바이트 수(전송된 바이트) 측면에서의 네트워크 트래픽입니다. |
유형별 I/O 대기 분석postgresql/insights/aggregate/io_time |
읽기 및 쓰기 유형별 SQL 문에 대한 I/O 대기 시간의 분류입니다. 쿼리 통계가 사용 설정된 인스턴스에서만 사용할 수 있습니다. |
데이터베이스별 교착 상태 수postgresql/deadlock_count |
데이터베이스별 교착 상태 수입니다. |
블록 읽기 수postgresql/blocks_read_count |
디스크 및 버퍼 캐시에서 초당 읽은 블록 수입니다. |
작업별 처리된 행postgresql/tuples_processed_count |
작업별로 초당 처리되는 행 수입니다. |
상태별 데이터베이스의 행postgresql/tuple_size |
각 데이터베이스 상태의 행 수입니다. Cloud SQL은 인스턴스의 데이터베이스 수가 50개 미만일 때 이 측정항목을 보고합니다. |
기간별 가장 오래된 트랜잭션postgresql/vacuum/oldest_transaction_age |
VACUUM 작업을 차단하는 가장 오래된 트랜잭션의 기간입니다. |
WAL 보관처리replication/log_archive_success_count, replication/log_archive_failure_count |
분당 보관처리가 완료되거나 실패한 미리 쓰기 로그 파일 수입니다. |
트랜잭션 ID 사용률postgresql/transaction_id_utilization |
인스턴스에서 사용된 트랜잭션 ID의 비율입니다. |
애플리케이션 이름별 연결 수postgresql/num_backends_by_application |
애플리케이션별로 그룹화된 Cloud SQL 인스턴스에 대한 연결 수입니다. |
가져온 행, 반환된 행, 작성된 행 비교
|
반환된 행과 가져온 행 간의 차이가 너무 커서 해당 값이 동일한 배율로 표시되지 않으면 가져온 행 값이 반환된 행 값에 비해 무시 가능하므로 0으로 표시됩니다. |
임시 데이터 크기postgresql/temp_bytes_written_count |
쿼리 실행과 조인 및 정렬 등의 알고리즘 수행에 사용되는 총 데이터 양(바이트)입니다. |
임시 파일postgresql/temp_files_written_count |
쿼리 실행과 조인 및 정렬 등의 알고리즘 수행에 사용되는 임시 파일 수입니다. |
또한 Cloud Logging 측정항목인 심각도별 로그 항목(logging.googleapis.com/log_entry_count)에는 오류 및 경고 로그 항목의 총 수가 표시됩니다.
이 수는 데이터베이스 로그인 postgres.log와 데이터 액세스 정보가 포함된 pgaudit.log에서 추출됩니다.
자세한 내용은 Cloud SQL 측정항목을 참조하세요.
이벤트 타임라인
대시보드에는 다음 이벤트의 세부정보가 제공됩니다.
| 이벤트 이름 | 설명 | 작업 유형 |
|---|---|---|
Instance restart |
Cloud SQL 인스턴스를 다시 시작합니다. | RESTART |
Instance failover |
기본 인스턴스가 되는 고가용성(HA) 기본 인스턴스를 대기 인스턴스로 수동 장애 조치를 시작합니다. | FAILOVER |
Instance maintenance |
인스턴스가 현재 유지보수 중임을 나타냅니다. 유지보수로 인해 일반적으로 1~3분 동안 인스턴스를 사용할 수 없습니다. | MAINTENANCE |
Instance backup |
인스턴스 백업을 수행합니다. | BACKUP_VOLUME |
Instance update |
Cloud SQL 인스턴스의 설정을 업데이트합니다. | UPDATE |
Promote replica |
Cloud SQL 복제본 인스턴스를 승격합니다. | PROMOTE_REPLICA |
Start replica |
Cloud SQL 읽기 복제본 인스턴스에서 복제를 시작합니다. | START_REPLICA |
Stop replica |
Cloud SQL 읽기 복제본 인스턴스에서 복제를 중지합니다. | STOP_REPLICA |
Recreate replica |
Cloud SQL 복제본 인스턴스에 대한 리소스를 다시 만듭니다. | RECREATE_REPLICA |
Create replica |
Cloud SQL 복제본 인스턴스를 만듭니다. | CREATE_REPLICA |
Data import |
Cloud SQL 인스턴스로 데이터를 가져옵니다. | IMPORT |
Instance export |
Cloud SQL 인스턴스에서 Cloud Storage 버킷으로 데이터를 내보냅니다. | EXPORT |
Restore backup |
Cloud SQL 인스턴스의 백업을 복원합니다. 이 작업으로 인스턴스가 다시 시작될 수 있습니다. | RESTORE_VOLUME |