Neste tutorial, mostramos como usar o Cloud Scheduler e as funções do Cloud Run para programar backups manuais de um banco de dados do Cloud SQL.
Este tutorial leva aproximadamente 30 minutos para ser concluído.
Primeiro, configure o ambiente clonando um repositório Git que contém bancos de dados de teste e armazenando esses bancos de dados em um bucket do Cloud Storage.
Em seguida, crie uma instância de banco de dados do Cloud SQL para PostgreSQL e importe os bancos de dados de teste do bucket do Cloud Storage para a instância.
Depois de configurar o ambiente, crie um job do Cloud Scheduler que poste uma mensagem do gatilho de backup em uma data e hora programadas em um tópico do Pub/Sub. A mensagem contém informações sobre o nome da instância do Cloud SQL e o ID do projeto. A mensagem aciona uma das funções do Cloud Run. A função usa a API Cloud SQL Admin para iniciar um backup do banco de dados no Cloud SQL. No diagrama a seguir, veja esse fluxo de trabalho.
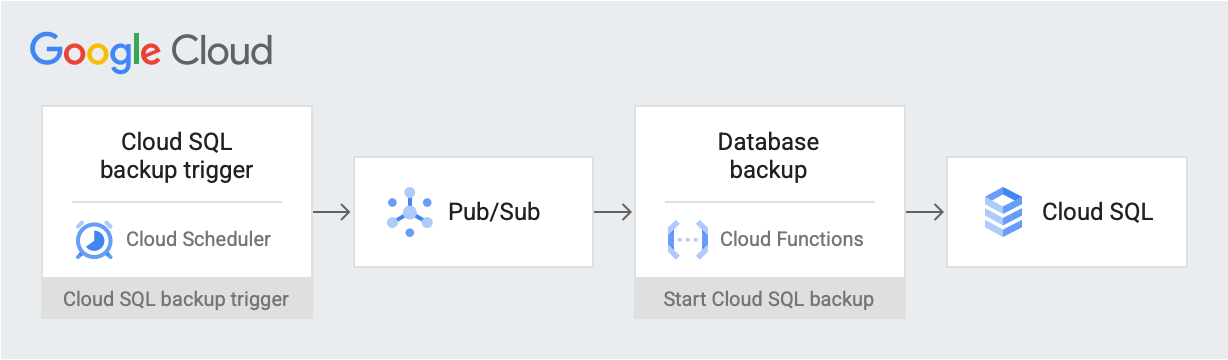
Google Cloud componentes
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
- Cloud Storage: armazena os bancos de dados de teste importados para o Cloud SQL.
- Instância do Cloud SQL: contém o banco de dados para backup.
- Cloud Scheduler: publica mensagens em um tópico do Pub/Sub em uma programação definida.
- Pub/Sub: contém mensagens enviadas do Cloud Scheduler.
- Funções do Cloud Run: se inscrevem no tópico do Pub/Sub e, quando acionadas, fazem uma chamada de API à instância do Cloud SQL para iniciar o backup.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Para mais informações, consulte Limpeza.
Antes de começar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
No console Google Cloud , acesse a página APIs e ative as seguintes APIs:
- API Cloud SQL Admin
- API Funções do Cloud Run
- API Cloud Scheduler
- API Cloud Build
- API App Engine Admin
Ao longo deste tutorial, você executará todos os comandos do Cloud Shell.
configure o ambiente
Para começar, faça primeiro um clone do repositório que contém os dados de amostra. Em seguida, configure o ambiente e crie papéis personalizados com as permissões necessárias para este tutorial.
É possível fazer tudo neste tutorial no Cloud Shell.
Faça um clone do repositório que contém os dados de amostra:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst.gitUse os dados do repositório
training-data-analystpara criar um banco de dados com alguns registros simulados.Configure as seguintes variáveis de ambiente:
export PROJECT_ID=`gcloud config get-value project` export DEMO="sql-backup-tutorial" export BUCKET_NAME=${USER}-PostgreSQL-$(date +%s) export SQL_INSTANCE="${DEMO}-sql" export GCF_NAME="${DEMO}-gcf" export PUBSUB_TOPIC="${DEMO}-topic" export SCHEDULER_JOB="${DEMO}-job" export SQL_ROLE="sqlBackupCreator" export STORAGE_ROLE="simpleStorageRole" export REGION="us-west2"Crie dois papéis personalizados que tenham apenas as permissões necessárias para este tutorial:
gcloud iam roles create ${STORAGE_ROLE} --project ${PROJECT_ID} \ --title "Simple Storage role" \ --description "Grant permissions to view and create objects in Cloud Storage" \ --permissions "storage.objects.create,storage.objects.get"gcloud iam roles create ${SQL_ROLE} --project ${PROJECT_ID} \ --title "SQL Backup role" \ --description "Grant permissions to backup data from a Cloud SQL instance" \ --permissions "cloudsql.backupRuns.create"Esses papéis reduzem o escopo de acesso das contas de serviço de serviços do Cloud Run e do Cloud SQL, seguindo o princípio de privilégio mínimo.
crie uma instância do Cloud SQL
Nesta seção, você criará um bucket do Cloud Storage e uma instância do Cloud SQL para PostgreSQL. Em seguida, faça upload do banco de dados de teste para o bucket do Cloud Storage e importe o banco de dados para a instância do Cloud SQL.
Criar um bucket do Cloud Storage
Use a CLI gcloud para criar um bucket do Cloud Storage.
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
Crie uma instância do Cloud SQL e conceda permissões à conta de serviço
Em seguida, crie uma instância do Cloud SQL e conceda à conta de serviço as permissões para criar execuções de backup.
Crie uma instância do Cloud SQL para PostgreSQL:
gcloud sql instances create ${SQL_INSTANCE} --database-version POSTGRES_13 --region ${REGION}Essa operação leva alguns minutos para ser concluída.
Verifique se a instância do Cloud SQL está em execução:
gcloud sql instances list --filter name=${SQL_INSTANCE}A resposta será semelhante a:
NAME DATABASE_VERSION LOCATION TIER PRIMARY_ADDRESS PRIVATE_ADDRESS STATUS sql-backup-tutorial POSTGRES_13 us-west2-b db-n1-standard-1 x.x.x.x - RUNNABLE
Conceda à sua conta de serviço do Cloud SQL as permissões para exportar dados para o Cloud Storage com o papel de armazenamento simples:
export SQL_SA=(`gcloud sql instances describe ${SQL_INSTANCE} \ --project ${PROJECT_ID} \ --format "value(serviceAccountEmailAddress)"`) gcloud storage buckets add-iam-policy-binding gs://${BUCKET_NAME} \ --member=serviceAccount:${SQL_SA} \ --role=projects/${PROJECT_ID}/roles/${STORAGE_ROLE}
Preencher a instância do Cloud SQL com dados de amostra
Agora é possível fazer upload de arquivos para o bucket e criar e preencher o banco de dados de amostra.
Acesse o repositório que você clonou:
cd training-data-analyst/CPB100/lab3a/cloudsqlFaça o upload dos arquivos do diretório para o novo bucket:
gcloud storage cp * gs://${BUCKET_NAME}Crie um banco de dados de amostra; no prompt "Do you want to continue (Y/n)?", digite Y (Sim) para continuar.
gcloud sql import sql ${SQL_INSTANCE} gs://${BUCKET_NAME}/table_creation.sql --project ${PROJECT_ID}Preencha o banco de dados no prompt "Do you want to continue (Y/n)?", digite Y (Sim) para continuar.
gcloud sql import csv ${SQL_INSTANCE} gs://${BUCKET_NAME}/accommodation.csv \ --database recommendation_spark \ --table Accommodationgcloud sql import csv ${SQL_INSTANCE} gs://${BUCKET_NAME}/rating.csv \ --database recommendation_spark \ --table Rating
Criar um tópico, uma função e um job do programador
Nesta seção, você cria uma conta de serviço do IAM personalizada e a vincula ao papel SQL personalizado que você criou em Configurar seu ambiente. Em seguida, crie um tópico do Pub/Sub e uma função do Cloud Run que se inscreva no tópico e use a API Cloud SQL Admin para iniciar um backup. Por fim, você cria um job do Cloud Scheduler para postar uma mensagem no tópico do Pub/Sub periodicamente.
Criar uma conta de serviço para a função do Cloud Run
O primeiro passo é criar uma conta de serviço personalizada e vinculá-la ao papel SQL personalizado que você criou em Configurar seu ambiente.
Crie uma conta de serviço do IAM para ser usada pelas funções do Cloud Run:
gcloud iam service-accounts create ${GCF_NAME} \ --display-name "Service Account for GCF and SQL Admin API"Conceda acesso ao papel SQL personalizado à conta de serviço de funções do Cloud Run:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${GCF_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="projects/${PROJECT_ID}/roles/${SQL_ROLE}"
Criar um tópico do Pub/Sub
A próxima etapa é criar um tópico do Pub/Sub usado para ativar as funções do Cloud Run que interage com o banco de dados do Cloud SQL.
gcloud pubsub topics create ${PUBSUB_TOPIC}
Criar uma função do Cloud Run
Em seguida, crie a função do Cloud Run.
Crie um arquivo
main.pycolando o seguinte no Cloud Shell:cat <<EOF > main.py import base64 import logging import json from datetime import datetime from httplib2 import Http from googleapiclient import discovery from googleapiclient.errors import HttpError from oauth2client.client import GoogleCredentials def main(event, context): pubsub_message = json.loads(base64.b64decode(event['data']).decode('utf-8')) credentials = GoogleCredentials.get_application_default() service = discovery.build('sqladmin', 'v1beta4', http=credentials.authorize(Http()), cache_discovery=False) try: request = service.backupRuns().insert( project=pubsub_message['project'], instance=pubsub_message['instance'] ) response = request.execute() except HttpError as err: logging.error("Could NOT run backup. Reason: {}".format(err)) else: logging.info("Backup task status: {}".format(response)) EOFCrie um arquivo
requirements.txtcolando o seguinte no Cloud Shell:cat <<EOF > requirements.txt google-api-python-client Oauth2client EOFImplante o código:
gcloud functions deploy ${GCF_NAME} \ --trigger-topic ${PUBSUB_TOPIC} \ --runtime python37 \ --entry-point main \ --service-account ${GCF_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Criar um job do Cloud Scheduler
Por fim, você cria um job do Cloud Scheduler para acionar periodicamente a função de backup de dados de hora em hora. O Cloud Scheduler usa uma instância do App Engine para implantação.
Crie uma instância do App Engine para o job do Cloud Scheduler:
gcloud app create --region=${REGION}Crie um job do Cloud Scheduler:
gcloud scheduler jobs create pubsub ${SCHEDULER_JOB} \ --schedule "0 * * * *" \ --topic ${PUBSUB_TOPIC} \ --message-body '{"instance":'\"${SQL_INSTANCE}\"',"project":'\"${PROJECT_ID}\"'}' \ --time-zone 'America/Los_Angeles'
Testar a solução
A etapa final é testar a solução. Para começar, execute o job do Cloud Scheduler.
Execute o job do Cloud Scheduler manualmente para ativar um dump do PostgreSQL do banco de dados.
gcloud scheduler jobs run ${SCHEDULER_JOB}Liste as operações realizadas na instância do PostgreSQL e verifique se há uma operação do tipo
BACKUP_VOLUME:gcloud sql operations list --instance ${SQL_INSTANCE} --limit 1A saída mostra um job de backup concluído, por exemplo:
NAME TYPE START END ERROR STATUS 8b031f0b-9d66-47fc-ba21-67dc20193749 BACKUP_VOLUME 2020-02-06T21:55:22.240+00:00 2020-02-06T21:55:32.614+00:00 - DONE
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste tutorial, siga estas etapas. A maneira mais fácil de evitar o faturamento é excluir o projeto criado para o tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Se você não quiser excluir todo o projeto, exclua cada um dos recursos criados. Para fazer isso, acesse as páginas apropriadas no console do Google Cloud , selecione o recurso e o exclua.
A seguir
- Saiba como programar instâncias de computação com o Cloud Scheduler.
- Saiba mais sobre os backups do Cloud SQL.
- Confira arquiteturas de referência, diagramas e práticas recomendadas sobre Google Cloud. Confira o Centro de arquitetura do Cloud.