このページでは、バックアップからのインスタンスの復元やポイントインタイム リカバリ(PITR)の実行の前に確認すべき情報について説明します。
復元時の動作
Cloud SQL Enterprise エディションと Cloud SQL Enterprise Plus エディションでは、バックアップからインスタンスを復元できます。異なるエディションのインスタンス間でバックアップを復元することもできます。
インスタンスを復元すると、プライマリ インスタンスから次のデータが新しいインスタンスに復元されます。
- データベース
- ユーザー
復元オペレーションを行うと、インスタンスが再起動されます。
ポイントインタイム リカバリ(PITR)
ポイントインタイム リカバリ(PITR)を利用すると、インスタンスを特定の時点の状態に復元できます。たとえば、エラーによってデータが失われた場合に、そのエラーが発生する前の状態にデータベースを復元できます。
PITR は常に新しいインスタンスを作成します。既存のインスタンスに PITR を実行することはできません。新しいインスタンスは、クローン作成と同様に、ソース インスタンスの設定を継承します。
Google Cloud コンソールで Cloud SQL インスタンスを作成すると、PITR はデフォルトで有効になります。PITR では、write-ahead log 書き込み(WAL)のアーカイブが使用されます。デフォルトでは、Cloud SQL Enterprise Plus エディションのインスタンスに対して PITR が有効化されます。
PITR を有効にする前に Cloud SQL インスタンス上でバックアップを復元すると、PITR を使用するためのアーカイブログが失われます。ディスク上の write-ahead log のサイズが原因でインスタンスのパフォーマンスの問題が発生している場合は、PITR を無効にしてから再度有効にしてください。この操作を行うと、確実に新しいログがディスクではなく Cloud Storage に保存されるようになります。PITR を実行する手順については、ポイントインタイム リカバリ(PITR)を使用するをご覧ください。
使用不能なインスタンスを復元する
PITR を使用すると、使用不能の Cloud SQL インスタンスを復元できます。PITR の目標復旧時点(RPO)は一般的に 5 分以下です。
インスタンスが使用不能になった場合は、API を使用して、インスタンスを復元して、その時間まで復元できる最も早い復元時間と最も遅い復元時間を取得できます。インスタンスが構成されているゾーンにアクセスできない場合は、優先ゾーンの値を指定してインスタンスを別のプライマリ ゾーンまたはセカンダリ ゾーンに復元できます。
Cloud SQL インスタンスが午後 4 時(EST)に利用できなくなったとします。最新の復元時刻が午後 3 時 55 分(EST)であれば、この時点までインスタンスを復元できます。
PITR を使用して削除したインスタンスを復元する
PITR を使用すると、削除後に Cloud SQL インスタンスを復元できます。この機能を使用するには、インスタンスが削除される前に、インスタンスで PITR と保持されたバックアップが有効になっている必要があります。有効にすると、インスタンスを削除した後も PITR ログが保持されます。
インスタンスが削除された後も、PITR ログは、インスタンスが稼働していたときに定義された保持設定に従います。PITR ログは、インスタンスの削除後、保持設定に基づいて段階的に期限切れになります。ローリング期間は、削除前のインスタンスに設定された PITR 保持期間に基づいて定義されます。たとえば、Cloud SQL Enterprise Plus エディションのインスタンスで PITR の保持期間が 14 日に設定されている場合、インスタンスの削除から 14 日後に最新の PITR ログが削除されます。PITR ログの有効期限が切れると、復元できなくなります。
インスタンス名は Cloud SQL でインスタンスが削除された後に再利用できるため、保持された PITR ログは Google Cloud で次のフィールドを使用して識別できます。
instance_deletion_timelog_retention_days
これらのフィールドを使用すると、PITR ログが削除されたインスタンスに属しているかどうかを特定できます。
PITR 復元ウィンドウは、PITR を使用してインスタンスを復元するために使用できる最も早い復元時間と最も遅い復元時間として定義されます。削除したインスタンスの復元可能な最も古い時刻と最も新しい時刻を確認するには、復元可能な最も古い時刻と最も新しい時刻を取得するをご覧ください。
インスタンスの削除後に PITR を使用してインスタンスを復元するには、削除されたインスタンスで PITR を実行するをご覧ください。
復元の実行についての全般的なヒント
バックアップから同じインスタンスや別のインスタンスにインスタンスを復元する場合は、次の点に留意してください。
- 復元オペレーションは、ターゲット インスタンスのすべてのデータを上書きします。
- 復元オペレーション中は既存の接続が失われるため、ターゲット インスタンスは接続に使用できません。
- リードレプリカがあるインスタンスに復元する場合は、すべてのレプリカを削除し、復元オペレーションの完了後に再作成する必要があります。
- 復元オペレーションによってインスタンスが再起動されます。
復元する方法の詳細については、次のリンク先をご覧ください。
別のインスタンスへの復元のヒントと要件
別のインスタンスにバックアップを復元する場合は、次の制限やベスト プラクティスに留意してください。
ターゲット インスタンスのデータベースは、バックアップの取得元であるインスタンスのデータベースと同じバージョン、同じエディションである必要があります。
Cloud SQL は常に、ターゲット インスタンスのストレージ容量を、構成されたディスクとバックアップ ディスクの両方のサイズの最大値に設定します。バックアップ ディスクは、バックアップ取得時のディスクのサイズになります。
ターゲット インスタンスのストレージ容量は、バックアップされるインスタンスの容量と同じかそれ以上である必要があります。使用中のストレージ容量は関係ありません。インスタンスのストレージ容量は、コンソールの Cloud SQL インスタンス ページで確認できます。
ターゲット インスタンスは
RUNNABLEの状態であることが必要です。ターゲット インスタンスは、バックアップが取られたインスタンスとはコアの数が異なっていたり、メモリの量が異なっていたりしても構いません。
ターゲット インスタンスは、ソース インスタンスとは異なるリージョンに存在する場合があります。
停止中でも、特定のプロジェクトのバックアップ リストを取得できます。停止時にバックアップを表示するをご覧ください。
復元のレート制限
1 つのプロジェクト、1 つのリージョン、1 つのインスタンスにつき、30 分ごとに最大 3 つの復元オペレーションが許可されます。復元オペレーションが失敗した場合、この割り当てにカウントされません。上限に達するとオペレーションは失敗し、オペレーションの再実行が可能となるタイミングを示すエラー メッセージが表示されます。
では、Cloud SQL が復元のレート制限をどのように実行しているのか見てみましょう。
Cloud SQL は、バケットからのトークンを使用して、一度に実行可能な復元オペレーションの数を決定します。各バックアップには、ターゲット プロジェクトとターゲット リージョンごとに 1 つのバケットがあります。同じリージョンにある場合、同じプロジェクトのターゲット インスタンスは 1 つのバケットを共有します。各バケットには、復元オペレーションに使用できるトークンが最大で 3 つあります。10 分ごとに新しいトークンがバケットに追加されます。バケットがいっぱいの場合、トークンはオーバーフローします。
復元オペレーションのたびに、バケットからトークンが付与されます。オペレーションが成功すると、バケットからトークンが削除されます。失敗した場合、トークンがバケットに返されます。次の図は、この仕組みを示しています。

たとえば、次の図では、Backup1、Backup2、Backup3 が同じソース インスタンスのバックアップです。
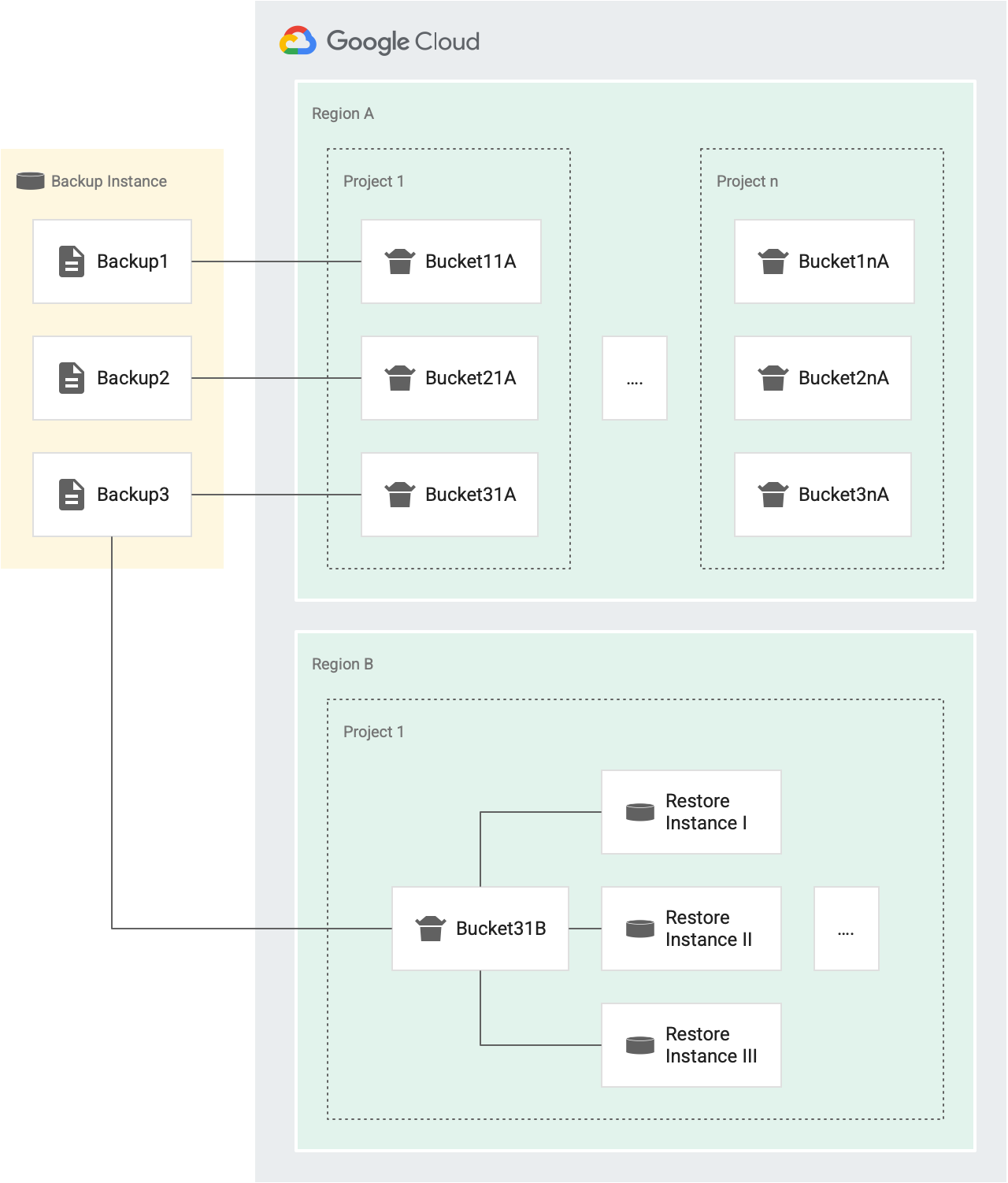
- 各バックアップ(Backup1、Backup2、Backup3)には、リージョン A のプロジェクト 1 の異なるインスタンスをターゲットとする復元オペレーション用のトークン バケットがあります(Bucket11A、Bucket21A、Bucket31A)。各バックアップには独自のバケットがあるため、30 分ごとに各バックアップを同じインスタンスに 3 回、復元できます。
- 各バックアップには、プロジェクトとリージョンごとに 1 つのバケットがあります。たとえば、リージョンに 5 つのプロジェクトがある場合、そのリージョンにバックアップ用のバケットが 5 つあります(プロジェクトごとに 1 つずつ)。上の図では、リージョン A にプロジェクト 1 とプロジェクト n の 2 つのプロジェクトがあります。
- Backup1 には、リージョン A の復元オペレーション用に 2 つのトークン バケットがあります。1 つのバケットはプロジェクト 1 用(Bucket11A)、もう 1 つのバケットはプロジェクト n 用(Bucket1nA)です。
- 同様に、Backup3 には、リージョン A での復元オペレーション用の 2 つのバケットがあります。1 つはプロジェクト 1 用(Bucket31A)、もう 1 つはプロジェクト n 用(Bucket3nA)です。
- 同じターゲット プロジェクトと同じターゲット リージョン内のすべてのインスタンスが 1 つのバケットを共有するため、Backup3 にはリージョン B にプロジェクト 1 用のパケットが 1 つあります。