En esta página se describe cómo usar el panel de control Información valiosa sobre las consultas para detectar y analizar problemas de rendimiento de las consultas.
Introducción
La función Información valiosa sobre las consultas te ayuda a detectar, diagnosticar y evitar problemas de rendimiento de las consultas en las bases de datos de Cloud SQL. Cuenta con funciones de monitorización intuitivas y proporciona información de diagnóstico que puede ayudarte a identificar la causa principal del problema de rendimiento.
Con Estadísticas de las consultas, puedes monitorizar el rendimiento a nivel de aplicación y rastrear la fuente de una consulta problemática en toda la pila de la aplicación por modelo, vista, controlador, ruta, usuario y host. La herramienta Estadísticas de las consultas se puede integrar con tus herramientas y servicios de monitorización de aplicaciones (APM) mediante APIs y estándares abiertos. Google CloudDe esta forma, puedes monitorizar y solucionar problemas con las consultas usando tu herramienta favorita.
Información valiosa sobre las consultas le ayuda a mejorar el rendimiento de las consultas de Cloud SQL guiándole por los siguientes pasos:
- Ver la carga de la base de datos de las consultas principales
- Identificar una consulta o una etiqueta que pueda dar problemas
- Examina la consulta o la etiqueta para identificar los problemas
- Analizar un rastreo generado por una consulta de ejemplo
Estadísticas de consultas de la edición Enterprise Plus de Cloud SQL
Si usas la edición Enterprise Plus de Cloud SQL, puedes acceder a funciones adicionales de información útil sobre las consultas para realizar diagnósticos avanzados del rendimiento de las consultas. Además de las funciones estándar del panel de control Estadísticas de consultas, la función Estadísticas de consultas de la edición Cloud SQL Enterprise Plus le permite hacer lo siguiente:
- Captura y analiza los eventos de espera de todas las consultas ejecutadas.
- Filtra la carga de la base de datos agregada por dimensiones adicionales, como consultas, etiquetas, tipos de eventos de espera y más.
- Captura los planes de consulta de todas las consultas ejecutadas.
- Muestrea hasta 200 planes de consulta por minuto.
- Captura textos de consulta más largos, de hasta 1 MB.
- Obtener actualizaciones de métricas casi en tiempo real (en el orden de segundos).
- Mantener una retención de métricas de 30 días.
- Obtener recomendaciones de índices de Index Advisor.
- Finaliza una sesión o una transacción de larga duración en consultas activas.
- Acceder a la solución de problemas con IA (vista previa).
En la siguiente tabla se comparan los requisitos funcionales y las funciones de Información útil sobre las consultas para la edición Cloud SQL Enterprise con los de Información útil sobre las consultas para la edición Cloud SQL Enterprise Plus.
| Área de comparación | Información útil sobre las consultas de la edición Enterprise de Cloud SQL | Estadísticas de consultas de la edición Enterprise Plus de Cloud SQL |
|---|---|---|
| Versiones de bases de datos admitidas | MySQL 5.7 o una versión posterior | MySQL 8.0 o versiones posteriores |
| Tipos de máquinas admitidos | Compatible con todos los tipos de máquinas | No se admite en instancias que usen un tipo de máquina de núcleo compartido. |
| Regiones admitidas | Ubicaciones regionales de Cloud SQL | Ubicaciones regionales de la edición Cloud SQL Enterprise Plus |
| Periodo de conservación de métricas | 7 días | 30 días |
| Límite máximo de longitud de consulta | 4500 bytes | 1 MB |
| Máximo de ejemplos de planes de consultas | 20 | 200 |
| Análisis de eventos de espera | No disponible | Disponible |
| Recomendaciones de Asesor de índices | No disponible | Disponible |
| Finalizar sesiones o transacciones de larga duración en consultas activas | No disponible | Disponible |
| Solución de problemas asistida por IA (vista previa) | No disponible | Disponible |
Habilitar Información útil sobre las consultas en la edición Enterprise Plus de Cloud SQL
Para habilitar Información útil sobre las consultas en la edición Enterprise Plus de Cloud SQL, selecciona Habilitar funciones de Enterprise Plus cuando habilites Información útil sobre las consultas en tu instancia de la edición Enterprise Plus de Cloud SQL.
Precios
No hay ningún coste adicional por usar Estadísticas de consultas en instancias de Cloud SQL Enterprise o Cloud SQL Enterprise Plus.
Requisitos de almacenamiento
Información útil sobre las consultas de la edición Enterprise de Cloud SQL no ocupa espacio de almacenamiento en tu instancia de Cloud SQL. Las métricas se almacenan en Cloud Monitoring. Para obtener información sobre las solicitudes de API, consulta la página de precios de Cloud Monitoring. Cloud Monitoring tiene un nivel que puedes usar sin coste adicional.
Información útil sobre las consultas de la edición Enterprise Plus de Cloud SQL almacena datos de métricas en el mismo disco conectado a tu instancia de Cloud SQL y requiere que mantengas habilitada la opción de aumento automático del almacenamiento.
El requisito de almacenamiento para siete días de datos es de aproximadamente 45 GB. Para 30 días, necesitas aproximadamente 180 GB. Información útil sobre las consultas de la edición Enterprise Plus de Cloud SQL usa hasta 130 MB de RAM. Las métricas deberían estar disponibles en Estadísticas de las consultas en un plazo de un minuto después de que se complete la consulta. Se aplican las tarifas de almacenamiento correspondientes.Limitaciones
Las siguientes limitaciones se aplican a las estadísticas de consultas de las instancias de la edición Enterprise Plus de Cloud SQL:
- Si tu instancia está sometida a una carga del sistema elevada, cuando consultes datos de métricas en el panel Estadísticas de las consultas, las consultas pueden tardar en cargarse o agotarse el tiempo de espera.
- Si vuelves a crear una réplica de lectura, esta no conservará su historial de métricas anterior.
- Si restauras una instancia con una copia de seguridad antigua, puedes perder las métricas entre el momento en que se creó la copia de seguridad y el momento en que restauraste la instancia para Estadísticas de consultas de la edición Enterprise Plus de Cloud SQL. Por ejemplo, si restauras tu instancia el 30 de abril con una copia de seguridad creada el 25 de abril, es posible que pierdas todas las métricas entre el 25 y el 30 de abril.
Antes de empezar
Antes de usar Estadísticas de consultas, haz lo siguiente.
- Añade los roles y permisos necesarios.
- Habilita la API Cloud Trace.
- Si usas Estadísticas de consultas para la edición Enterprise Plus de Cloud SQL, asegúrate de que la opción Habilitar aumentos automáticos del almacenamiento esté habilitada en la instancia.
Roles y permisos necesarios
Para obtener los permisos que necesitas para acceder a los datos históricos de ejecución de consultas en el panel de control Estadísticas de consultas, pide a tu administrador que te conceda los siguientes roles de gestión de identidades y accesos en el proyecto que aloja la instancia de Cloud SQL:
-
Visor de monitorización de estadísticas de bases de datos (
roles/databaseinsights.monitoringViewer) -
Lector de Cloud SQL (
roles/cloudsql.viewer)
Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar acceso a proyectos, carpetas y organizaciones.
También puedes conseguir los permisos necesarios a través de roles personalizados u otros roles predefinidos.
Habilitar la API de Cloud Trace
Para ver los planes de consulta y sus vistas completas, tu Google Cloud proyecto debe tener habilitada la API Cloud Trace. Esta opción permite que tu proyecto deGoogle Cloud reciba datos de traza de fuentes autenticadas sin coste adicional. Estos datos pueden ayudarte a detectar y diagnosticar problemas de rendimiento en tu instancia.
Para confirmar que la API Cloud Trace está habilitada, sigue estos pasos:
- En la Google Cloud consola, vaya a APIs y servicios:
- Haz clic en Habilitar APIs y servicios.
- En la barra de búsqueda, escribe
Cloud Trace API. - Si se muestra API habilitada, significa que esta API está habilitada y no tienes que hacer nada. De lo contrario, haz clic en Habilitar.
Habilitar aumentos automáticos de almacenamiento
Si usas Estadísticas de consultas en la edición Enterprise Plus de Cloud SQL, asegúrate de que el ajuste de la instancia para habilitar los aumentos automáticos de almacenamiento siga habilitado. De forma predeterminada, esta opción está habilitada en las instancias de Cloud SQL.
Si has inhabilitado este ajuste de instancia y quieres habilitar Estadísticas de consultas para la edición Enterprise Plus de Cloud SQL, primero debes volver a habilitar los aumentos automáticos de almacenamiento. No puedes desactivar los aumentos automáticos de almacenamiento y habilitar Información útil sobre las consultas en la edición Enterprise Plus de Cloud SQL.
Habilitar estadísticas de consultas
Cuando habilitas las estadísticas de las consultas, todas las demás operaciones se suspenden temporalmente. Estas operaciones incluyen comprobaciones del estado, registro, monitorización y otras operaciones de instancias.
Consola
Habilitar Información valiosa sobre las consultas en una instancia
-
En la Google Cloud consola, ve a la página Instancias de Cloud SQL.
- Para abrir la página Overview (Resumen) de una instancia, haz clic en su nombre.
- En la tarjeta Configuración, haz clic en Editar configuración.
- En la sección Personalizar tu instancia, amplía Estadísticas de consultas.
- Seleccione la casilla Habilitar Información valiosa sobre las consultas.
- Opcional: Selecciona funciones adicionales para tu instancia. Algunas funciones solo están disponibles en la edición Cloud SQL Enterprise Plus.
- Haz clic en Guardar.
| Función | Descripción | Edición Enterprise de Cloud SQL | Edición Cloud SQL Enterprise Plus |
|---|---|---|---|
| Habilitar funciones de Enterprise Plus | Selecciona esta casilla para habilitar Información útil sobre las consultas en la edición Enterprise Plus de Cloud SQL. Información valiosa sobre las consultas de la edición Enterprise Plus de Cloud SQL te permite finalizar sesiones y transacciones de larga duración en consultas activas, habilita las recomendaciones del asesor de indexación para ayudarte a acelerar el procesamiento de las consultas y aumenta la conservación de los datos de métricas a 30 días. Las recomendaciones del Asesor de índices se habilitan automáticamente cuando habilitas Información útil sobre las consultas en la edición Enterprise Plus de Cloud SQL. Para inhabilitar las recomendaciones del Asesor de índices, desmarca esta casilla. Debes marcar esta casilla para habilitar las recomendaciones del asesor de índices y la solución de problemas asistida por IA (vista previa). | No disponible | Disponible
Predeterminado: inhabilitado |
| Solución de problemas con IA | Selecciona esta casilla para habilitar la detección de anomalías de rendimiento, el análisis de la causa principal y de la situación, y para obtener recomendaciones sobre cómo solucionar problemas con tus consultas y tu base de datos. Esta función está en versión preliminar y solo se puede habilitar y acceder a ella mediante la Google Cloud consola. Para obtener más información, consulta Observar y solucionar problemas con la ayuda de la IA. | No disponible | Disponible
Predeterminado: inhabilitado |
| Almacenar direcciones IP de cliente | Seleccione esta casilla para habilitar el almacenamiento de direcciones IP de cliente. Cloud SQL puede almacenar las direcciones IP de las consultas y permitirte agrupar esos datos para generar métricas al respecto. Las consultas proceden de más de un host. Revisar los gráficos de las consultas de direcciones IP de clientes puede ayudarte a identificar la fuente de un problema. | Disponible
Predeterminado: inhabilitado |
Disponible
Predeterminado: inhabilitado |
| Almacenar etiquetas de aplicaciones | Seleccione esta casilla para habilitar el almacenamiento de etiquetas de aplicación. Almacenar etiquetas de aplicaciones te ayuda a determinar las APIs y las rutas de controlador de vistas de modelo (MVC) que están realizando solicitudes, así como a agrupar los datos para generar métricas al respecto. Para usar esta opción, debe comentar las consultas con un conjunto específico de etiquetas mediante la biblioteca de instrumentación automática de asignación relacional de objetos (ORM) de código abierto sqlcommenter. Esta información ayuda a la información útil sobre las consultas a identificar el origen de un problema y el MVC del que procede. Las rutas de aplicación te ayudan a monitorizar las aplicaciones. | Disponible
Predeterminado: Inhabilitado |
Disponible
Predeterminado: Inhabilitado |
| Personalizar la longitud de las consultas |
Selecciona esta casilla para personalizar el límite de longitud de una cadena de consulta.
Las longitudes de consulta más altas son más útiles para las consultas analíticas, pero también requieren más memoria.
Las cadenas de consulta que superen el límite especificado se truncarán en la pantalla. Si cambias el límite de longitud de las consultas, debes reiniciar la instancia. Aun así, puede añadir etiquetas a las consultas que superen el límite de longitud. |
Puedes definir el límite en bytes, que puede ser de 256 a 4500 bytes.
Predeterminado: 1024.
|
Puedes especificar un límite en bytes entre 1 y 1048576.
Valor predeterminado: 1024 bytes (1 KB).
|
| Definir la frecuencia de muestreo máxima |
Seleccione esta casilla para definir la frecuencia de muestreo máxima. La frecuencia de muestreo es el número de muestras de planes de consulta ejecutados que se recogen por minuto en todas las bases de datos de la instancia. Si aumentas la frecuencia de muestreo, es probable que obtengas más puntos de datos, pero puede que aumente la sobrecarga del rendimiento.
Para inhabilitar el muestreo, asigna el valor 0.
|
Cambia este valor por un número entre 0 y 20.
Predeterminado: 5.
|
Puedes aumentar el máximo a 200 para proporcionar más puntos de datos.
Predeterminado: 5.
|
Habilitar Estadísticas de consultas en varias instancias
-
En la Google Cloud consola, ve a la página Instancias de Cloud SQL.
- Haz clic en el menú Más acciones de cualquier fila.
- Selecciona Habilitar Información valiosa sobre las consultas.
- En el cuadro de diálogo, marca la casilla Habilitar Estadísticas de las consultas en varias instancias.
- Haz clic en Enable (Habilitar).
- En el cuadro de diálogo siguiente, seleccione las instancias para las que quiera habilitar Estadísticas de las consultas.
- Haz clic en Habilitar Información valiosa sobre las consultas.
gcloud
Para habilitar Información útil sobre las consultas en una instancia de Cloud SQL mediante gcloud, ejecuta gcloud sql instances patch
con la marca --insights-config-query-insights-enabled de la siguiente manera, después de sustituir INSTANCE_ID por el ID de la instancia.
Si habilitas Estadísticas de consultas en una instancia de la edición Enterprise Plus de Cloud SQL, se habilitarán automáticamente las recomendaciones de Asesor de índices.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled
También puedes usar una o varias de las siguientes marcas opcionales:
--insights-config-record-client-addressAlmacena las direcciones IP de los clientes desde las que se envían las consultas y le ayuda a agrupar esos datos para generar métricas al respecto. Las consultas proceden de más de un host. Revisar los gráficos de las consultas de direcciones IP de clientes puede ayudarte a identificar el origen de un problema.
--insights-config-record-application-tagsAlmacena etiquetas de aplicaciones que te ayudan a determinar las APIs y las rutas de controlador de vistas de modelo (MVC) que están realizando solicitudes, y agrupa los datos para generar métricas al respecto. Para usar esta opción, debes comentar las consultas con un conjunto específico de etiquetas. Para ello, puedes usar la biblioteca de instrumentación automática de mapeo relacional de objetos (ORM) de código abierto sqlcommenter. Esta información ayuda a Estadísticas de las consultas a identificar el origen de un problema y el MVC del que procede. Las rutas de aplicación te ayudan a monitorizar las aplicaciones.
--insights-config-query-string-lengthDefine el límite de longitud de consulta predeterminado. Las longitudes de consulta más altas son más útiles para las consultas analíticas, pero también requieren más memoria. Si cambias la longitud de las consultas, debes reiniciar la instancia. Aun así, puede añadir etiquetas a las consultas que superen el límite de longitud. En la edición Enterprise de Cloud SQL, puedes especificar un valor en bytes entre
256y4500. La longitud predeterminada de las consultas es de1024bytes. En la edición Cloud SQL Enterprise Plus, puedes especificar un límite en bytes de1a1048576. El valor predeterminado es1024bytes (1 KB).--insights-config-query-plans-per-minuteDe forma predeterminada, se capturan un máximo de 5 muestras de planes de consulta ejecutados por minuto en todas las bases de datos de la instancia. Si aumentas la frecuencia de muestreo, es probable que obtengas más puntos de datos, pero puede que se añada una sobrecarga de rendimiento. Para inhabilitar el muestreo, asigna el valor
0. En la edición Enterprise de Cloud SQL, puedes cambiar el valor de 0 a 20. En la edición Cloud SQL Enterprise Plus, puedes aumentar el máximo hasta 200 para proporcionar más puntos de datos.
Haz los cambios siguientes:
- INSIGHTS_CONFIG_QUERY_STRING_LENGTH: longitud de la cadena de consulta que se va a almacenar, en bytes.
- API_TIER_STRING: la configuración de instancia personalizada que se va a usar en la instancia.
- REGION: la región de la instancia.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled \ --insights-config-query-string-length=INSIGHTS_CONFIG_QUERY_STRING_LENGTH \ --insights-config-query-plans-per-minute=QUERY_PLANS_PER_MINUTE \ --insights-config-record-application-tags \ --insights-config-record-client-address \ --tier=API_TIER_STRING \ --region=REGION
REST v1
Para habilitar Información útil sobre las consultas en una instancia de Cloud SQL mediante la API REST, llama al método instances.patch con la configuración insightsConfig.
Si habilitas Estadísticas de consultas en una instancia de la edición Enterprise Plus de Cloud SQL, se habilitarán automáticamente las recomendaciones de Asesor de índices.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT_ID: el ID del proyecto
- INSTANCE_ID: el ID de instancia
Método HTTP y URL:
PATCH https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID
Cuerpo JSON de la solicitud:
{
"settings" : {
"insightsConfig" : {
"queryInsightsEnabled" : true,
"recordClientAddress" : true,
"recordApplicationTags" : true,
"queryStringLength" : 1024,
"queryPlansPerMinute" : 20,
}
}
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2025-03-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "OPERATION_ID",
"targetId": "INSTANCE_ID",
"selfLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/operations/OPERATION_ID",
"targetProject": "PROJECT_ID"
}
Terraform
Para usar Terraform y habilitar Información valiosa sobre las consultas en una instancia de Cloud SQL, define la marca query_insights_enabled en true.
Si habilitas Estadísticas de consultas en una instancia de la edición Enterprise Plus de Cloud SQL, se habilitarán automáticamente las recomendaciones de Asesor de índices.
También puedes usar una o varias de las siguientes marcas opcionales:
query_string_length: En Cloud SQL Enterprise Edition, puedes especificar un valor en bytes de256a4500. La longitud predeterminada de las consultas es de1024bytes. En la edición Cloud SQL Enterprise Plus, puedes especificar un límite en bytes de1a1048576. El valor predeterminado es1024bytes (1 KB).record_application_tags: defina el valor comotruesi quiere registrar etiquetas de aplicación de la consulta.record_client_address: asigna el valortruesi quieres registrar la dirección IP del cliente. El valor predeterminado esfalse.-
query_plans_per_minute: En la edición Enterprise de Cloud SQL, puedes definir el valor de0a20. El valor predeterminado es5. En la edición Enterprise Plus de Cloud SQL, puedes aumentar el máximo hasta200para proporcionar más puntos de datos.
Veamos un ejemplo:
resource "google_sql_database_instance" "INSTANCE_NAME" { name = "INSTANCE_NAME" database_version = "MYSQL_VERSION" region = "REGION" root_password = "PASSWORD" deletion_protection = false # set to true to prevent destruction of the resource settings { tier = "DB_TIER" insights_config { query_insights_enabled = true query_string_length = 2048 # Optional record_application_tags = true # Optional record_client_address = true # Optional query_plans_per_minute = 10 # Optional } } }
Para aplicar la configuración de Terraform en un proyecto, sigue los pasos que se indican en las siguientes secciones. Google Cloud
Preparar Cloud Shell
- Abre Cloud Shell.
-
Define el Google Cloud proyecto predeterminado en el que quieras aplicar tus configuraciones de Terraform.
Solo tiene que ejecutar este comando una vez por proyecto y puede hacerlo en cualquier directorio.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Las variables de entorno se anulan si defines valores explícitos en el archivo de configuración de Terraform.
Preparar el directorio
Cada archivo de configuración de Terraform debe tener su propio directorio (también llamado módulo raíz).
-
En Cloud Shell, crea un directorio y un archivo nuevo en ese directorio. El nombre del archivo debe tener la extensión
.tf. Por ejemplo,main.tf. En este tutorial, nos referiremos al archivo comomain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si estás siguiendo un tutorial, puedes copiar el código de ejemplo de cada sección o paso.
Copia el código de ejemplo en el archivo
main.tfque acabas de crear.También puedes copiar el código de GitHub. Se recomienda cuando el fragmento de Terraform forma parte de una solución integral.
- Revisa y modifica los parámetros de ejemplo para aplicarlos a tu entorno.
- Guarda los cambios.
-
Inicializa Terraform. Solo tienes que hacerlo una vez por directorio.
terraform init
Si quieres usar la versión más reciente del proveedor de Google, incluye la opción
-upgrade:terraform init -upgrade
Aplica los cambios
-
Revisa la configuración y comprueba que los recursos que va a crear o actualizar Terraform se ajustan a tus expectativas:
terraform plan
Haga las correcciones necesarias en la configuración.
-
Aplica la configuración de Terraform ejecutando el siguiente comando e introduciendo
yesen la petición:terraform apply
Espera hasta que Terraform muestre el mensaje "Apply complete!".
- Abre tu Google Cloud proyecto para ver los resultados. En la Google Cloud consola, ve a tus recursos en la interfaz de usuario para asegurarte de que Terraform los ha creado o actualizado.
Las métricas deberían estar disponibles en Estadísticas de las consultas unos minutos después de que se completen las consultas. Consulta la política de conservación de datos de Cloud Monitoring.
Las trazas de estadísticas de consultas se almacenan en Cloud Trace. Consulta la política de conservación de datos de Cloud Trace.
Ver el panel de control Estadísticas de las consultas
El panel de control Estadísticas de las consultas muestra la carga de las consultas en función de los factores que selecciones. La carga de consultas es una medida del trabajo total de todas las consultas de la instancia en el intervalo de tiempo seleccionado. El panel de control ofrece una serie de filtros que le ayudan a ver la carga de las consultas.
Para abrir el panel de control Estadísticas de las consultas, sigue estos pasos:
- Para abrir la página Overview (Resumen) de una instancia, haz clic en su nombre.
- En el menú de navegación de Cloud SQL, haga clic en Información valiosa sobre las consultas o en Ir a Información valiosa sobre las consultas para obtener detalles sobre las consultas y el rendimiento en la página Resumen de la instancia.
Se abrirá el panel de control Información valiosa sobre las consultas. En función de si usas Información útil sobre las consultas para la edición Enterprise de Cloud SQL o Información útil sobre las consultas para la edición Enterprise Plus de Cloud SQL, el panel de control Información útil sobre las consultas muestra la siguiente información sobre tu instancia:
Edición Cloud SQL Enterprise Plus
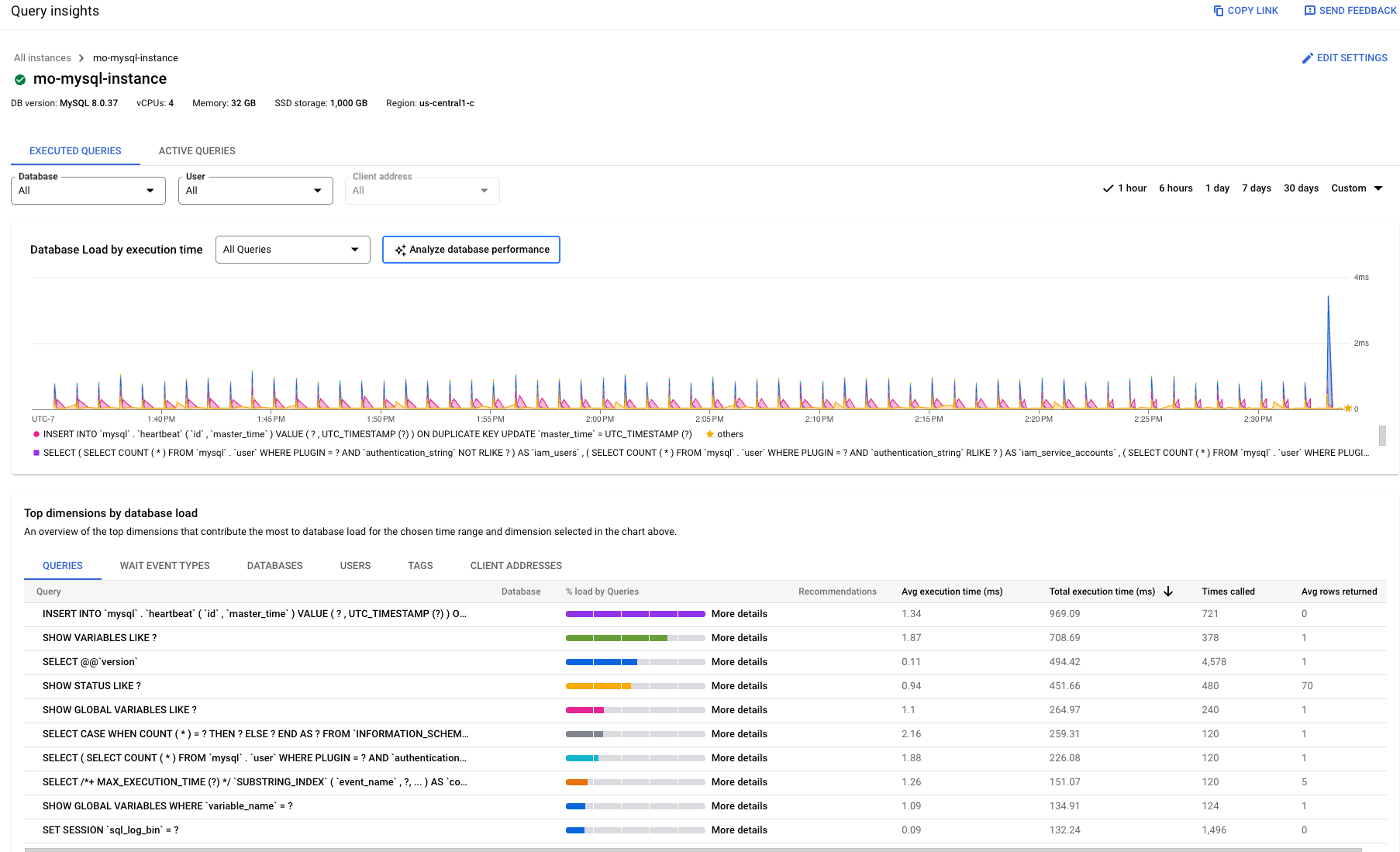
- Todas las consultas: muestra la carga de la base de datos de todas las consultas del periodo seleccionado. Cada consulta tiene un color diferente. Para ver un momento concreto de una consulta específica, mantén el puntero sobre el gráfico de la consulta.
- Base de datos: filtra la carga de consultas en una base de datos específica o en todas las bases de datos.
- Usuario: filtra la carga de consultas de una cuenta de usuario específica.
- Dirección del cliente: filtra la carga de consultas de una dirección IP específica.
- Periodo: filtra la carga de las consultas por periodos, como 1 hora, 6 horas, 1 día, 7 días, 30 días o un periodo personalizado.
- Tipos de eventos de espera: filtra la carga de consultas por tipos de eventos de espera de CPU y de bloqueo.
- Consultas, Tipos de eventos de espera, Bases de datos, Usuarios, Etiquetas y Direcciones de cliente: ordena los datos por las dimensiones principales que más contribuyen a la carga de la base de datos en el gráfico. Consulta Filtrar la carga de la base de datos.
Edición Enterprise de Cloud SQL
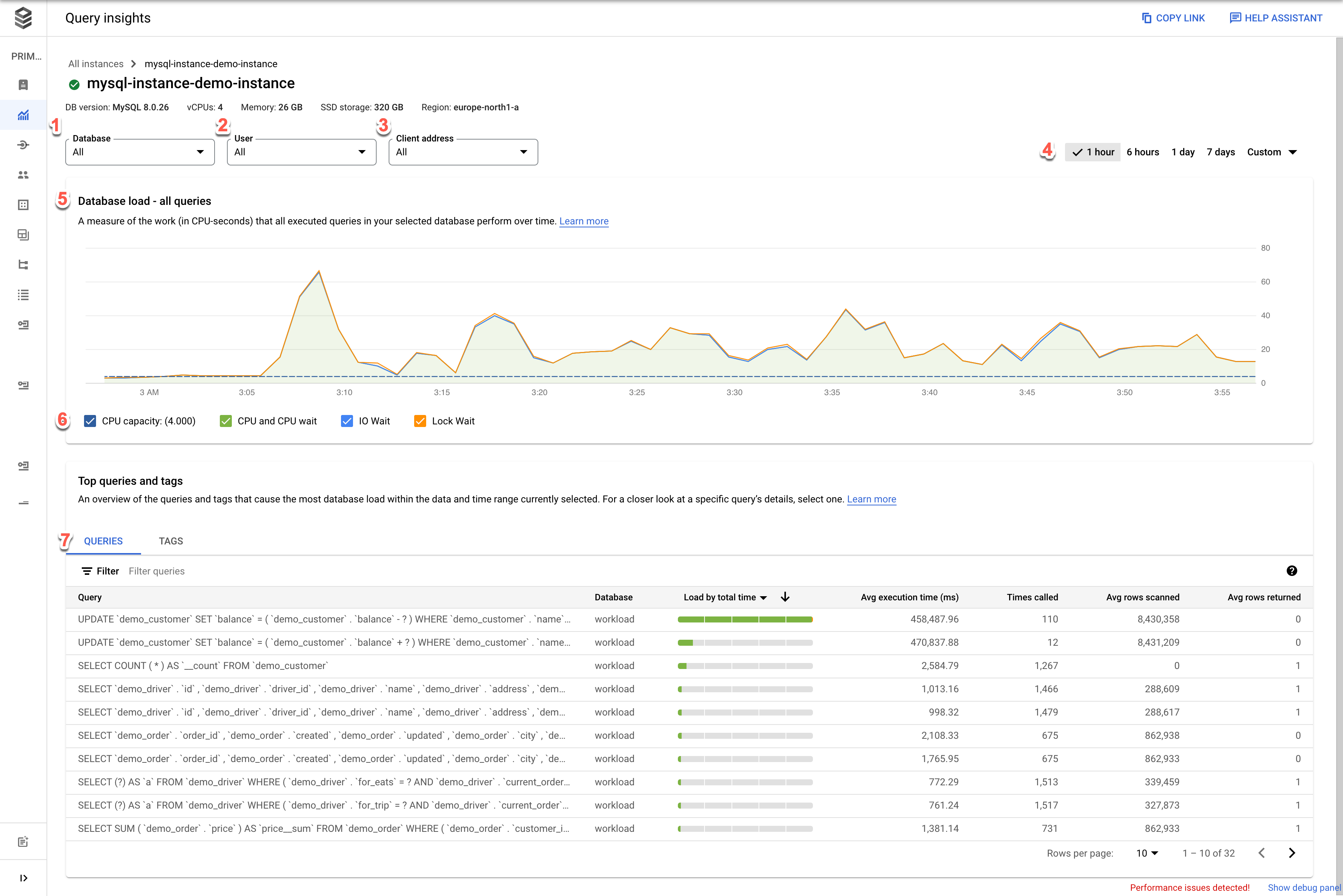
- Base de datos: filtra la carga de consultas en una base de datos específica o en todas las bases de datos.
- Usuario: filtra la carga de consultas de una cuenta de usuario específica.
- Dirección del cliente: filtra la carga de consultas de una dirección IP específica.
- Periodo: filtra la carga de las consultas por periodos, como 1 hora, 6 horas, 1 día, 7 días, 30 días o un periodo personalizado.
- Gráfico de carga de la base de datos: muestra el gráfico de carga de las consultas en función de los datos filtrados.
- Capacidad de CPU, CPU y espera de CPU, espera de E/S y espera de bloqueo: filtra las cargas en función de las opciones que selecciones. Consulta Ver la carga de la base de datos de las consultas principales para obtener información detallada sobre cada uno de estos filtros.
- Consultas y Etiquetas: filtra la carga de consultas por una consulta seleccionada o por una etiqueta de consulta SQL seleccionada. Consulta Filtrar la carga de la base de datos.
Ver la carga de la base de datos de todas las consultas
La carga de consultas de la base de datos es una medida del trabajo (en segundos de CPU) que realizan las consultas ejecutadas en la base de datos seleccionada a lo largo del tiempo. Cada consulta en ejecución usa o espera recursos de CPU, recursos de E/S o recursos de bloqueo. La carga de consultas de la base de datos es la proporción de tiempo que requieren todas las consultas que se completan en un periodo determinado en relación con el tiempo real transcurrido.
El panel de control Estadísticas de consultas de nivel superior muestra el gráfico Carga de la base de datos (todas las consultas principales). Los menús desplegables del panel de control te permiten filtrar el gráfico por una base de datos, un usuario o una dirección de cliente específicos.
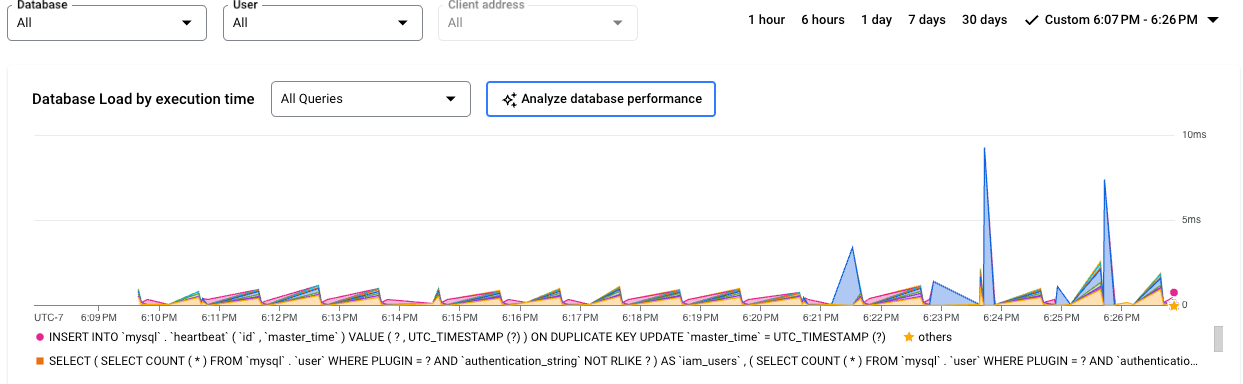
Edición Cloud SQL Enterprise Plus
Edición Enterprise de Cloud SQL
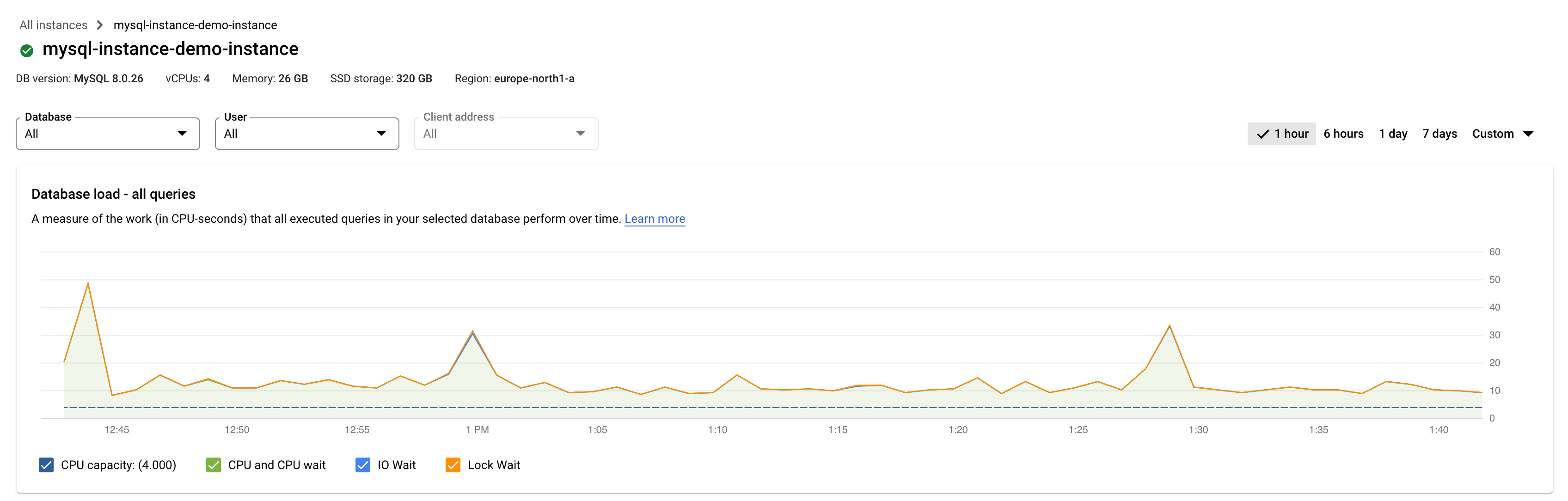
Las líneas de colores del gráfico muestran la carga de consultas, dividida en categorías:
- Capacidad de CPU: el número de CPUs disponibles en la instancia.
- CPU y espera de CPU: la proporción de tiempo que requieren las consultas en estado activo en relación con el tiempo real transcurrido. Las esperas de E/S y de bloqueo no bloquean las consultas que están en estado activo. Esta métrica puede significar que la consulta está usando la CPU o esperando a que el programador de Linux programe el proceso del servidor que ejecuta la consulta mientras otros procesos usan la CPU.
- Espera de E/S: la proporción de tiempo que requieren las consultas que están esperando la E/S en relación con el tiempo real transcurrido. La espera de E/S incluye la espera de E/S de lectura y de escritura. Si quieres ver un desglose de la información sobre las esperas de E/S, puedes consultarlo en Cloud Monitoring. Consulta las métricas de Cloud SQL para obtener más información.
- Espera de bloqueo: la proporción de tiempo que requieren las consultas que están esperando los bloqueos en relación con el tiempo real transcurrido. Incluye las esperas de bloqueo, de LwLock y de BufferPin. Para ver un desglose de la información sobre las esperas de bloqueo, usa Cloud Monitoring. Consulta las métricas de Cloud SQL para obtener más información.
Las líneas de colores del gráfico muestran la carga por base de datos según el tiempo de ejecución. Consulta el gráfico y usa las opciones de filtrado para responder a estas preguntas:
- ¿La carga de consultas es alta? ¿El gráfico muestra picos o valores elevados a lo largo del tiempo? Si no ves una carga alta, significa que el problema no está en tu consulta.
- ¿Cuánto tiempo lleva la carga alta? ¿Solo ahora es alta o lo ha sido durante mucho tiempo? Usa el selector de periodo para seleccionar varios periodos y averiguar cuánto tiempo ha durado el problema. Amplía para ver un periodo en el que se observan picos de carga de consultas. Reduce el zoom para ver hasta una semana de la cronología.
- ¿Qué está provocando la carga elevada? Puede seleccionar opciones para examinar la capacidad de la CPU, la CPU y la espera de la CPU, la espera de bloqueo o la espera de E/S. El gráfico de cada una de estas opciones tiene un color diferente para que puedas identificar la que tiene la carga más alta. La línea azul oscuro del gráfico muestra la capacidad máxima de la CPU del sistema. Te permite comparar la carga de consultas con la capacidad máxima del sistema de la CPU. Esta comparación te ayuda a determinar si una instancia se está quedando sin recursos de CPU.
- ¿Qué base de datos está experimentando la carga? Seleccione diferentes bases de datos en el menú desplegable Bases de datos para encontrar las bases de datos con las cargas más altas.
- ¿Hay usuarios o direcciones IP concretos que provoquen cargas más altas? Seleccione diferentes usuarios y direcciones en los menús desplegables para identificar los que están provocando cargas más elevadas.
Filtrar la carga de la base de datos
Puedes filtrar la carga de la base de datos por consultas o etiquetas. Si usas Estadísticas de las consultas para la edición Enterprise Plus de Cloud SQL, puedes personalizar el gráfico de carga de la base de datos para desglosar los datos mostrados mediante cualquiera de las siguientes dimensiones:Todas las consultas
Tipos de eventos de espera
Bases de datos
Usuarios
Etiquetas
Direcciones de cliente
Para personalizar el gráfico de carga de la base de datos, seleccione una dimensión en el menú desplegable Carga de la base de datos por tiempo de ejecución.
Ver los principales colaboradores de la carga de la base de datos
Para ver los principales colaboradores de la carga de la base de datos, puede usar la tabla Principales dimensiones por carga de la base de datos. En la tabla Principales dimensiones por carga de la base de datos se muestran los principales colaboradores del periodo y la dimensión que selecciones en el desplegable Carga de la base de datos por tiempo de ejecución. Puede modificar el periodo o la dimensión para ver los principales colaboradores de otra dimensión u otro periodo.
En la tabla Principales dimensiones por carga de datos, puede seleccionar las siguientes pestañas.
| Tabulador | Descripción |
|---|---|
| Consultas | En la tabla se muestran las consultas normalizadas principales por tiempo de ejecución total.
En cada consulta, los datos que se muestran en las columnas se indican de la siguiente manera:
|
| Tipos de eventos de espera | En la tabla se muestra la lista de los tipos de eventos de espera principales que se han producido durante el periodo seleccionado. Esta tabla solo está disponible para la función Información útil sobre las consultas de la edición Cloud SQL Enterprise Plus.
|
| Bases de datos | En la tabla se muestra la lista de las bases de datos principales que han contribuido a la carga durante el periodo elegido en todas las consultas ejecutadas.
|
| Usuarios | En la tabla se muestra la lista de los usuarios principales del periodo seleccionado en todas las consultas ejecutadas.
|
| Etiquetas | Para obtener información sobre las etiquetas, consulta Filtrar por etiquetas de consulta. |
| Direcciones de cliente | En la tabla se muestra la lista de los usuarios principales del periodo seleccionado en todas las consultas ejecutadas.
|
Filtrar por consultas
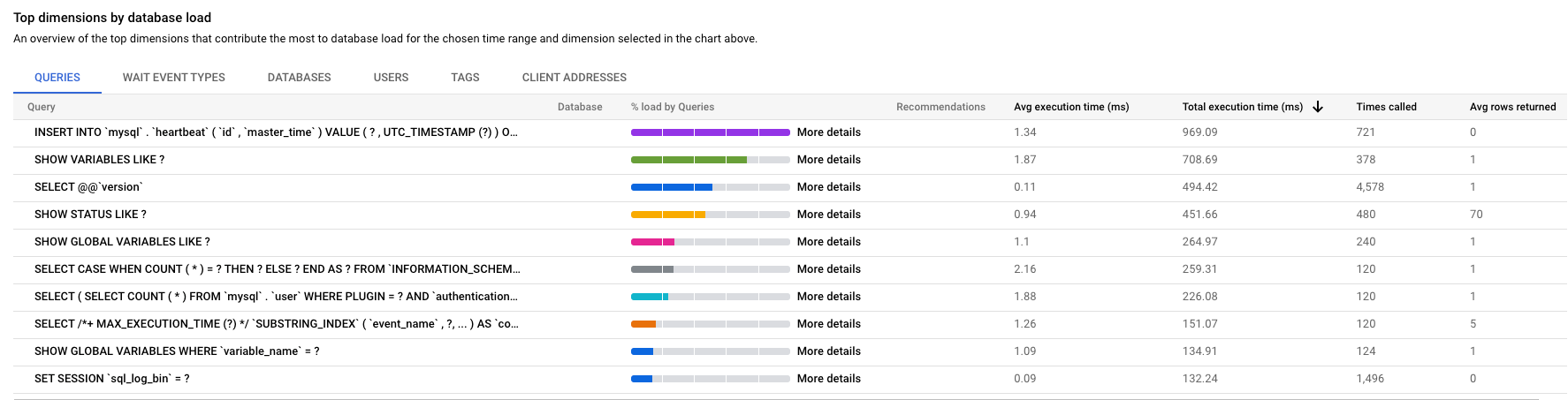
La tabla Principales dimensiones por carga de la base de datos ofrece una descripción general de las consultas que provocan la mayor carga de consultas. En la tabla se muestran todas las consultas normalizadas del periodo y las opciones seleccionadas en el panel de control Estadísticas de las consultas. Ordena las consultas por el tiempo total de ejecución durante el periodo que hayas seleccionado.
Edición Cloud SQL Enterprise Plus
Para ordenar la tabla, selecciona el encabezado de una columna.
Edición Enterprise de Cloud SQL
Para ordenar la tabla, selecciona un encabezado de columna o una propiedad de Filtrar consultas.
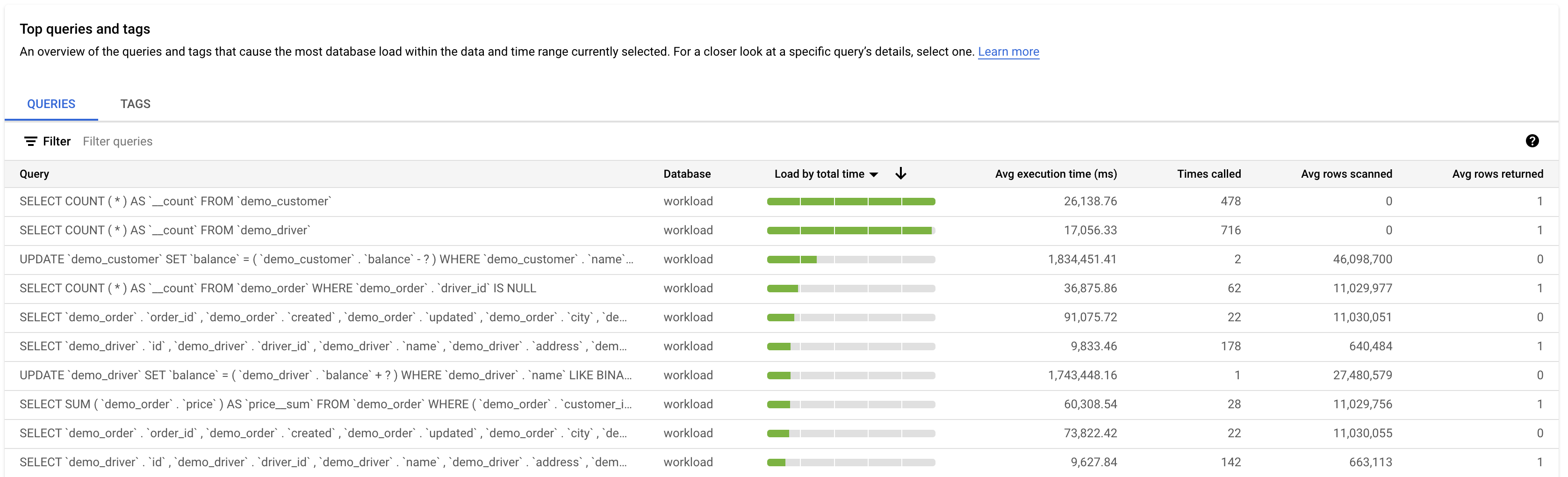
En la tabla se muestran las siguientes propiedades:
- Consulta: la cadena de consulta normalizada. De forma predeterminada, Estadísticas de las consultas solo muestra 1024 caracteres en la cadena de consulta.
Las consultas etiquetadas como
UTILITY COMMANDsuelen incluir comandosBEGIN,COMMITyEXPLAIN, o comandos de envoltorio. - Base de datos: la base de datos en la que se ha ejecutado la consulta.
- Recomendaciones: las recomendaciones sugeridas, como Crear índices, para mejorar el rendimiento de las consultas.
- Carga por tiempo total, Carga por CPU, Carga por espera de E/S o Carga por espera de bloqueo: las opciones por las que puede filtrar consultas específicas para encontrar la carga más grande.
- % de carga por consultas: porcentaje de carga por consulta.
- Analizar latencia: si has habilitado la solución de problemas asistida por IA (vista previa) en esta instancia, puedes hacer clic en este enlace para solucionar problemas de consultas lentas.
- Tiempo de ejecución medio (ms): tiempo medio que tarda en ejecutarse la consulta.
- Número de llamadas: número de veces que la aplicación ha llamado a la consulta.
- Promedio de filas devueltas: número medio de filas devueltas para la consulta.
- Media de filas analizadas: número medio de filas analizadas en la consulta.
Estadísticas de las consultas solo almacena y muestra consultas normalizadas.
De forma predeterminada, Estadísticas de las consultas no recoge direcciones IP ni información de etiquetas. Puede habilitar Estadísticas de las consultas para recoger esta información y, cuando sea necesario, inhabilitar la recogida.
Las trazas del plan de consulta no recogen ni almacenan ningún valor constante y eliminan cualquier información personal identificable que pueda mostrar la constante.
Estadísticas de las consultas muestra consultas normalizadas, es decir, ? sustituye al valor constante literal. En el siguiente ejemplo, se elimina la constante de nombre y se sustituye por ?.
UPDATE "demo_customer" SET "customer_id" = ?::uuid, "name" = ?, "address" = ?, "rating" = ?, "balance" = ?, "current_city" = ?, "current_location" = ? WHERE "demo_customer"."id" = ?
Filtrar por etiquetas de consulta
Para solucionar los problemas de una aplicación, primero debes añadir etiquetas a tus consultas SQL. Las etiquetas de carga de consultas proporcionan un desglose de la carga de consultas de la etiqueta seleccionada a lo largo del tiempo.
Información valiosa sobre las consultas ofrece una monitorización centrada en las aplicaciones para diagnosticar problemas de rendimiento de las aplicaciones creadas con ORMs. Si eres responsable de toda la pila de aplicaciones, Estadísticas de consultas te ofrece una monitorización de las consultas desde la perspectiva de la aplicación. El etiquetado de consultas te ayuda a encontrar problemas en construcciones de nivel superior, como la lógica empresarial o un microservicio.
Puedes etiquetar las consultas según la lógica empresarial; por ejemplo, las etiquetas de pago, inventario, analíticas empresariales o envío. De esta forma, podrá encontrar la carga de consultas que crea la lógica empresarial. Por ejemplo, puede observar eventos inesperados, como picos en una etiqueta de analíticas de una empresa a las 13:00 o un crecimiento inesperado de un servicio de pago que ha sido tendencia durante la semana anterior.
Para calcular la carga de la base de datos de la etiqueta, Estadísticas de las consultas usa el tiempo que tarda cada consulta que usa la etiqueta que seleccionas. La herramienta calcula la hora de finalización en el límite de minutos mediante la hora del reloj.
En el panel de control Estadísticas de las consultas, seleccione Etiquetas para ver la tabla de etiquetas. La tabla ordena las etiquetas según el tiempo total de carga.

Puede ordenar la tabla seleccionando una propiedad en Filtrar etiquetas o haciendo clic en el encabezado de una columna. En la tabla se muestran las siguientes propiedades:
- Acción, Controlador, Framework, Ruta, Aplicación y Controlador de base de datos: cada propiedad que hayas añadido a tus consultas aparece como una columna. Debe añadir al menos una de estas propiedades si quiere filtrar por etiquetas.
- Carga por tiempo total, Carga por CPU, Carga por espera de E/S o Carga por espera de bloqueo: opciones para filtrar consultas específicas y encontrar la carga más grande de cada opción.
- Tiempo de ejecución medio (ms): tiempo medio que tarda en ejecutarse la consulta.
- Promedio de filas devueltas: número medio de filas devueltas para la consulta.
- Media de filas analizadas: número medio de filas analizadas en la consulta.
- Número de llamadas: número de veces que la aplicación ha llamado a la consulta.
- Base de datos: la base de datos en la que se ha ejecutado la consulta.
Ver los detalles de una consulta o una etiqueta concretas
Para determinar si una consulta o una etiqueta concretas son la causa principal del problema, sigue estos pasos en la pestaña Consultas o Etiquetas, respectivamente:
- Para ordenar la lista de forma descendente, haz clic en el encabezado Carga por tiempo total.
- Haz clic en la consulta o la etiqueta de la parte superior de la lista. Tiene la carga más alta y tarda más que las demás.
Se abrirá la página Detalles de la consulta, donde se mostrarán los detalles de la consulta o la etiqueta seleccionada.
Examinar la carga de una consulta específica
La página Detalles de la consulta de una consulta seleccionada se muestra de la siguiente manera:
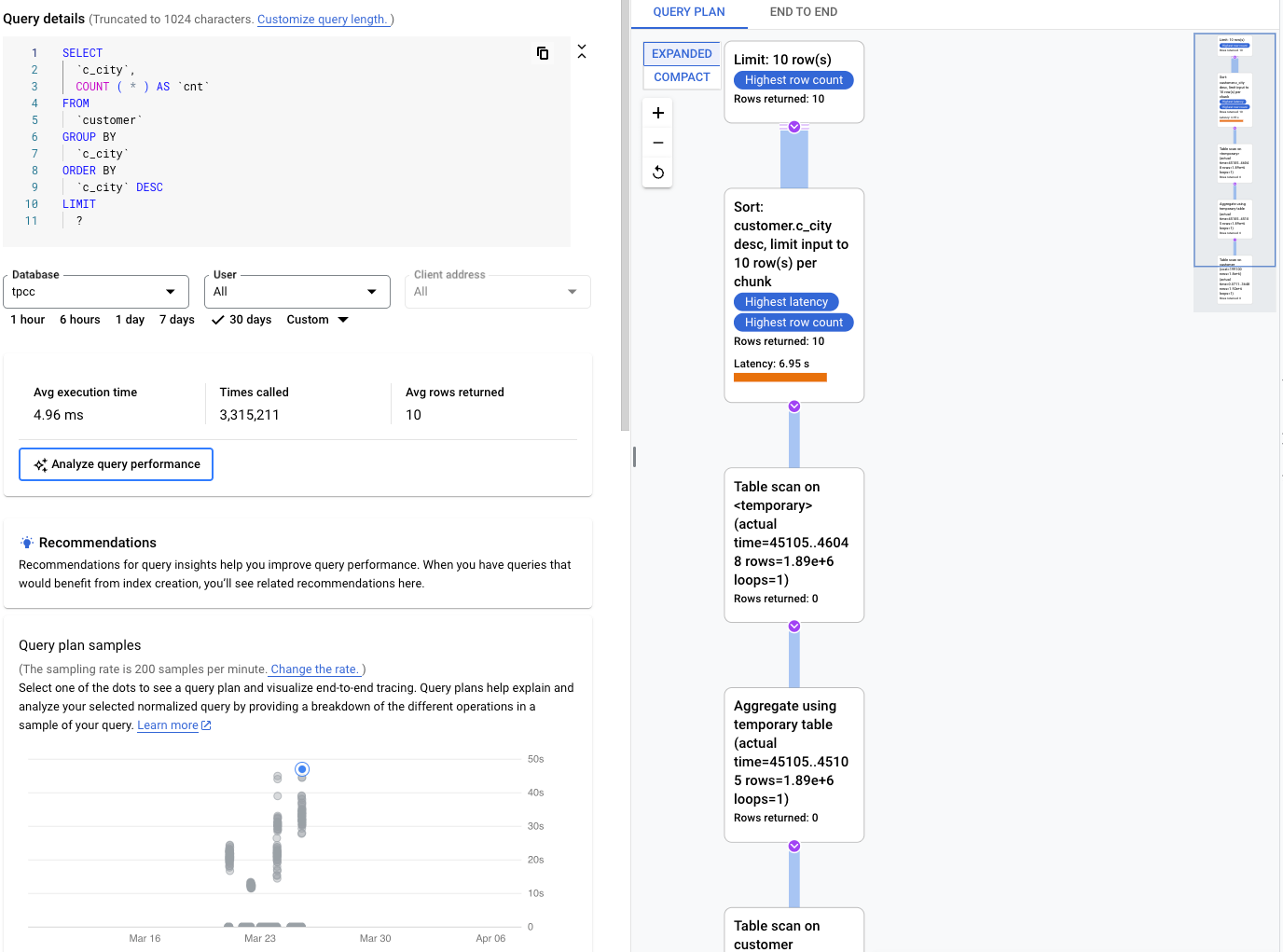
El gráfico Carga de la base de datos: consulta específica muestra una medida del trabajo (en segundos de CPU) que ha realizado la consulta normalizada en la consulta seleccionada a lo largo del tiempo. Para calcular la carga, se usa el tiempo que tardan las consultas normalizadas que se completan en el límite del minuto en relación con el tiempo real transcurrido. En la parte superior de la tabla, se muestran los primeros 1024 caracteres de la consulta normalizada, con los literales eliminados por motivos de agregación e información personal identificable.
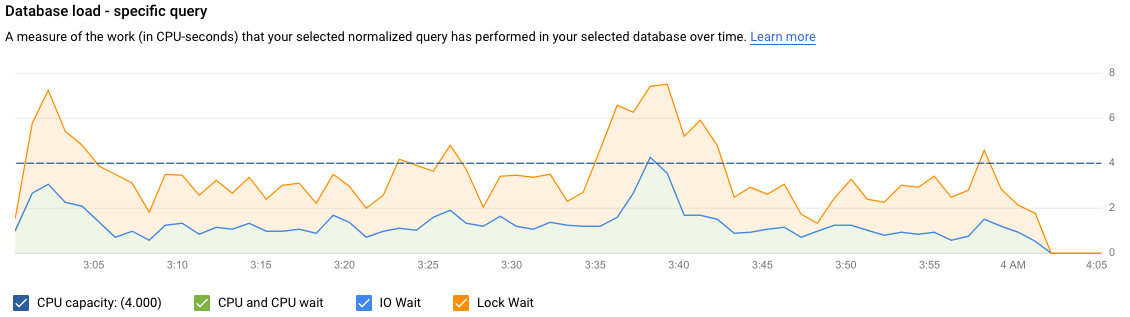
Al igual que en el gráfico de consultas totales, puede filtrar la carga de una consulta específica por Base de datos, Usuario y Dirección del cliente. La carga de las consultas se divide en capacidad de CPU, CPU y espera de CPU, espera de E/S y espera de bloqueo.
Examinar la carga de una consulta etiquetada específica
El panel de control de una etiqueta seleccionada se muestra de la siguiente manera. Por ejemplo, si todas las consultas de un pago de microservicios están etiquetadas como payment, puedes ver la cantidad de carga de consultas que está de moda consultando la etiqueta payment.
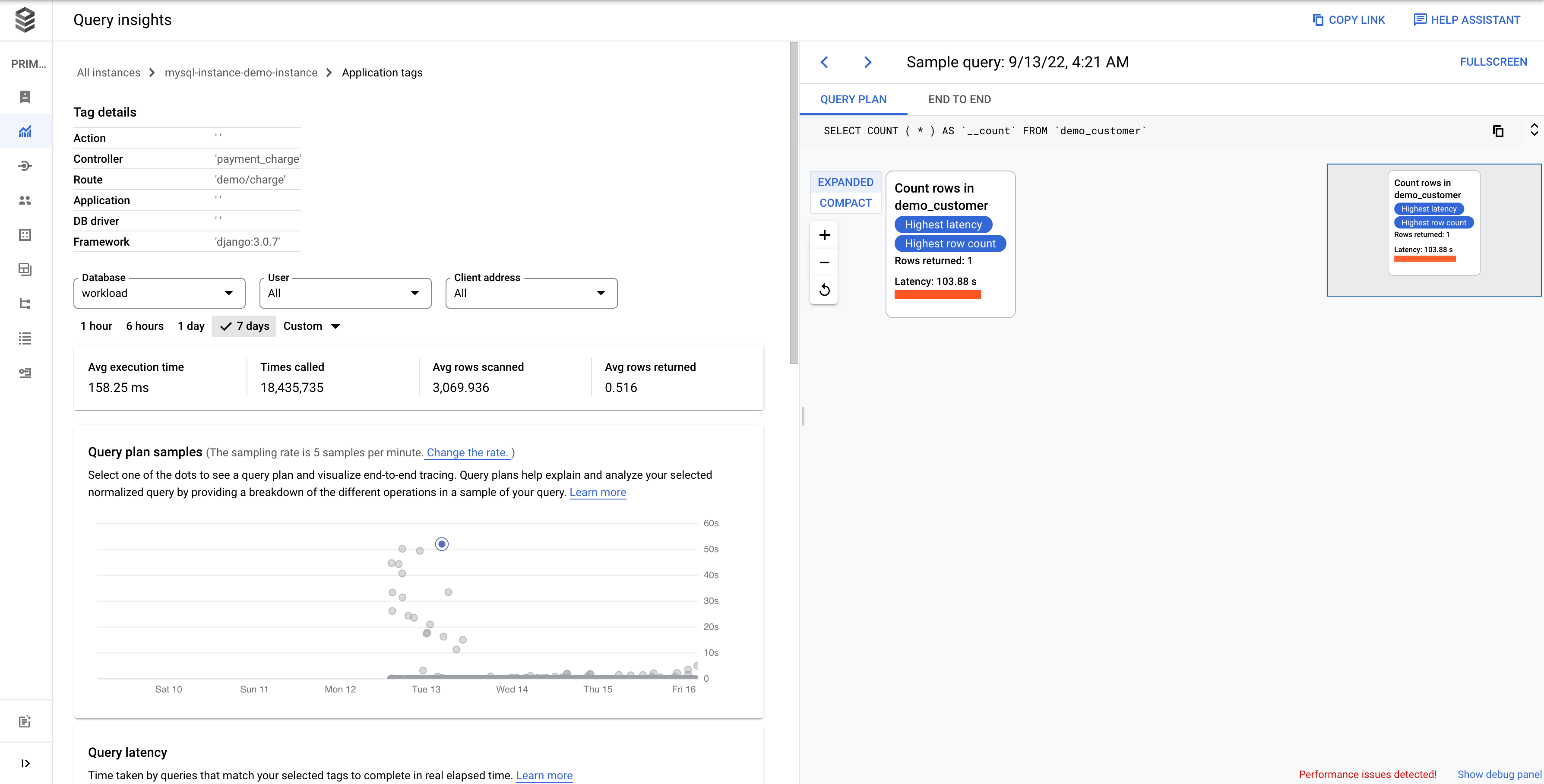
El gráfico Carga de la base de datos: etiquetas específicas muestra una medida del volumen de trabajo (medido en segundos de CPU) que las consultas que coinciden con las etiquetas seleccionadas han realizado en la base de datos elegida a lo largo del tiempo. Al igual que en el gráfico de consultas totales, puede filtrar la carga de una etiqueta específica por Base de datos, Usuario y Dirección del cliente.
Examinar las operaciones de un plan de consultas muestreado
Un plan de consultas toma una muestra de tu consulta y la desglosa en operaciones individuales. Explica y analiza cada operación de la consulta.
MySQL 5.7 proporciona un plan de consulta estimado con la vista EXPLAIN, mientras que MySQL 8.0 y versiones posteriores proporcionan un plan de consulta ejecutado con la vista EXPLAIN ANALYZE. Un plan de consultas estimado indica el tiempo de ejecución estimado de una consulta, mientras que un plan de consultas ejecutado proporciona información en tiempo real de cada paso de ejecución de una consulta determinada.
Los planes de consulta de MySQL 5.7 se admiten en las siguientes consultas que admite la instrucción EXPLAIN:
- En el caso de las tablas individuales, se pueden usar las instrucciones INSERT, SELECT, UPDATE y DELETE.
- En varias tablas: SELECT, UPDATE y DELETE.
Puedes generar planes de consulta en MySQL 8.0 y versiones posteriores para todas las consultas compatibles con EXPLAIN ANALYZE. Esta herramienta muestra dónde dedica MySQL el tiempo en tus consultas SELECT para una o varias tablas. Cloud SQL no admite la generación de planes de consulta del lenguaje de manipulación de datos (LMD) de varias tablas porque EXPLAIN ANALYZE no admite estas consultas.
El plan de consultas de ejemplo proporciona una vista EXPLAIN ANALYZE de las muestras del plan de consultas relacionadas con la consulta normalizada. Se trata de planes de consultas ejecutados que proporcionan un desglose del tiempo activo que requiere cada operación del plan de consultas.
El gráfico Ejemplos de plan de consulta muestra todos los planes de consulta que se ejecutan en momentos concretos y el tiempo que tarda en ejecutarse cada plan. Puede cambiar la frecuencia con la que se capturan muestras del plan de consulta por minuto. Consulta Habilitar Información valiosa sobre las consultas.
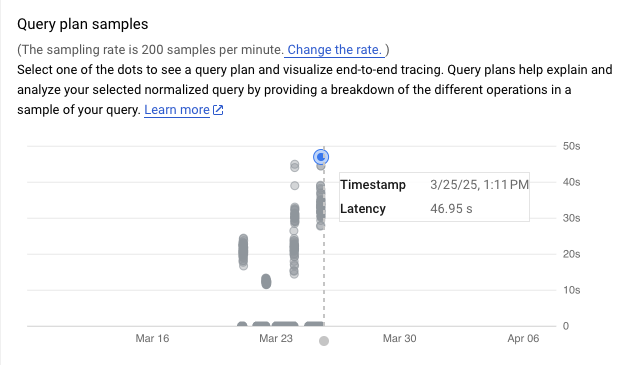
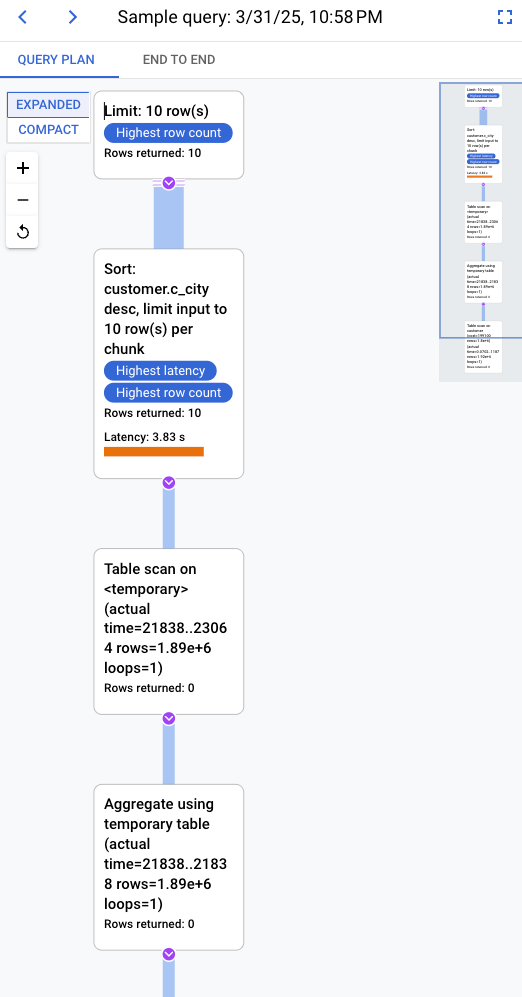
De forma predeterminada, el panel de la derecha muestra los detalles del ejemplo de plan de consulta que tarda más tiempo, tal como se puede ver en el gráfico Ejemplos de planes de consultas. Para ver los detalles de otro plan de consulta de ejemplo, haz clic en el círculo correspondiente del gráfico. En los detalles ampliados se muestra un modelo de todas las operaciones del plan de consulta.
En cada operación se muestra la latencia, las filas devueltas y el coste de la operación. Cuando seleccionas una operación, puedes ver más detalles, como bloques de aciertos compartidos, el tipo de esquema, bucles y filas de planes.
Intenta acotar el problema respondiendo a las siguientes preguntas:
- ¿Cuál es el consumo de recursos?
- ¿Qué relación tiene con otras consultas?
- ¿El consumo cambia con el tiempo?
Examinar un rastreo generado por una consulta de ejemplo
Además de ver el plan de consultas de ejemplo, puede usar Estadísticas de consultas para ver una traza de aplicación integral y contextual de una consulta de ejemplo. Este seguimiento puede ayudarte a identificar el origen de una consulta problemática mostrando la actividad de la base de datos de una solicitud específica. Además, las entradas de registro que la aplicación envía a Cloud Logging durante la solicitud se vinculan al rastreo, lo que te ayuda con tu investigación.
Para ver el rastreo contextual, sigue estos pasos:
- En la pantalla Consulta de ejemplo, haga clic en la pestaña Trace de extremo a extremo. En esta pestaña se muestra un gráfico de Gantt que detalla los intervalos, que son registros de operaciones individuales, de la traza generada por la consulta.
- Para ver más detalles sobre cada intervalo, como los atributos y los metadatos, selecciona el intervalo.
También puede ver el rastreo en la página Explorador de rastreos. Para hacerlo, haz clic en Ver en Cloud Trace. Para obtener información sobre cómo usar la página Explorador de trazas para explorar los datos de trazas, consulta Buscar y explorar trazas.
Examinar la latencia
La latencia es el tiempo que tarda en completarse la consulta normalizada, medido en tiempo real. Usa el gráfico Latencia para examinar la latencia de la consulta o la etiqueta. El panel de control de latencia muestra las latencias de los percentiles 50, 95 y 99 para detectar comportamientos atípicos.
En la siguiente imagen se muestra el gráfico de carga de la base de datos en el percentil 50 de una consulta específica con filtros seleccionados para la capacidad de CPU, la CPU y la espera de CPU, la espera de E/S y la espera de bloqueo.
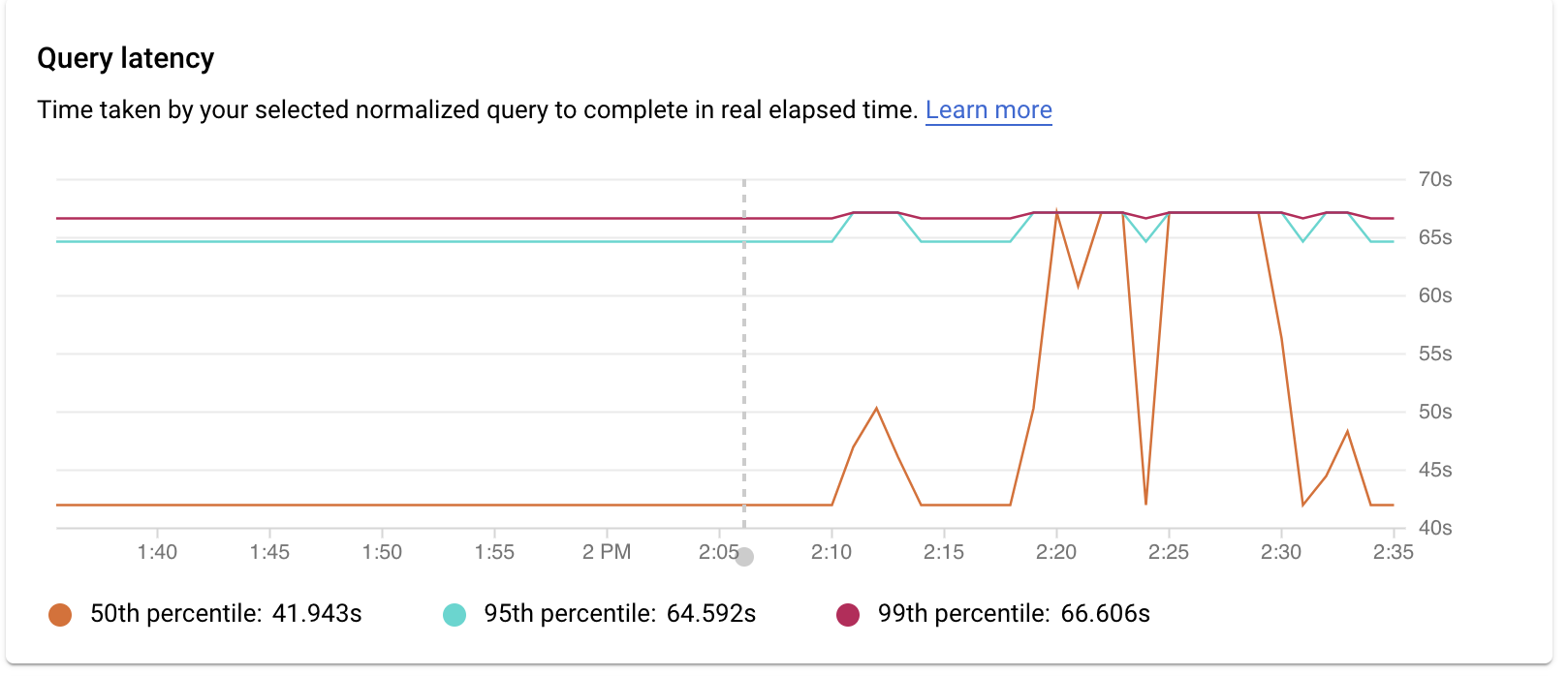
La latencia de las consultas paralelas se mide en tiempo de reloj, aunque la carga de la consulta puede ser mayor debido a que se usan varios núcleos para ejecutar parte de la consulta.
Intenta acotar el problema respondiendo a las siguientes preguntas:
- ¿Qué está provocando la carga elevada? Selecciona las opciones para consultar la capacidad de la CPU, la CPU y la espera de la CPU, la espera de E/S o la espera de bloqueo.
- ¿Cuánto tiempo lleva la carga alta? ¿Solo es alto ahora? ¿O ha estado alto durante mucho tiempo? Cambia el intervalo de tiempo para encontrar la fecha y la hora en las que el proceso de carga empezó a funcionar mal.
- ¿Ha habido picos de latencia? Cambia el periodo para estudiar la latencia histórica de la consulta normalizada.
Añadir etiquetas a consultas de SQL
Etiquetar consultas SQL simplifica la solución de problemas de las aplicaciones. Puedes usar sqlcommenter para añadir etiquetas a tus consultas SQL de forma automática o manual.
Usar sqlcommenter con ORM
Si usas ORM en lugar de escribir directamente consultas SQL, es posible que no encuentres el código de aplicación que está causando problemas de rendimiento. También puede tener problemas para analizar cómo afecta el código de su aplicación al rendimiento de las consultas. Para solucionar este problema, Query Insights proporciona una biblioteca de código abierto llamada sqlcommenter. Esta biblioteca es útil para los desarrolladores y administradores que usan herramientas ORM para detectar qué código de aplicación está causando problemas de rendimiento.
Si usa ORM y sqlcommenter juntos, las etiquetas se crearán automáticamente. No es necesario añadir ni cambiar código en tu aplicación.
Puedes instalar sqlcommenter en el servidor de aplicaciones. La biblioteca de instrumentación permite que la información de la aplicación relacionada con tu framework MVC se propague a la base de datos junto con las consultas como comentario SQL. La base de datos recoge estas etiquetas y empieza a registrar y agregar estadísticas por etiquetas, que son ortogonales a las estadísticas agregadas por consultas normalizadas. Información útil sobre las consultas muestra las etiquetas para que sepas qué aplicación está provocando la carga de consultas y puedas encontrar el código de la aplicación que está causando problemas de rendimiento.
Cuando examinas los resultados en los registros de la base de datos SQL, aparecen de la siguiente manera:
SELECT * from USERS /action='run+this', controller='foo%3', traceparent='00-01', tracestate='rojo%2'/
Entre las etiquetas admitidas se incluyen el nombre del controlador, la ruta, el framework y la acción.
El conjunto de herramientas ORM de sqlcommenter es compatible con los siguientes lenguajes de programación:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
| PHP |
|
Para obtener más información sobre sqlcommenter y cómo usarlo en tu framework ORM, consulta la documentación de sqlcommenter.
Usar sqlcommenter para añadir etiquetas
Si no usas ORM, debes añadir manualmente etiquetas o comentarios de sqlcommenter en el formato de comentario SQL correcto a tu consulta SQL. También debe aumentar cada instrucción SQL con un comentario que contenga un par clave-valor serializado. Usa al menos una de las siguientes teclas:
action=''controller=''framework=''route=''application=''db driver=''
Query Insights elimina todas las demás claves.
Inhabilitar Información valiosa sobre las consultas
Consola
Para inhabilitar Información útil sobre las consultas en una instancia de Cloud SQL mediante la consola de Google Cloud , sigue estos pasos:
-
En la Google Cloud consola, ve a la página Instancias de Cloud SQL.
- Para abrir la página Overview (Resumen) de una instancia, haz clic en su nombre.
- En la tarjeta Configuración, haz clic en Editar configuración.
- En la sección Opciones de configuración, despliega Estadísticas de las consultas.
- Desmarca la casilla Habilitar Información valiosa sobre las consultas.
- Haz clic en Guardar.
gcloud
Para inhabilitar Información útil sobre las consultas en una instancia de Cloud SQL mediante gcloud, ejecuta gcloud sql instances patch
con la marca --no-insights-config-query-insights-enabled de la siguiente manera, después de sustituir INSTANCE_ID por el ID de la instancia.
gcloud sql instances patch INSTANCE_ID \ --no-insights-config-query-insights-enabled
REST
Para inhabilitar la función Información útil sobre las consultas en una instancia de Cloud SQL mediante la API REST, llama al método instances.patch con queryInsightsEnabled definido como false, tal como se muestra a continuación.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- project-id: el ID del proyecto.
- instance-id: el ID de instancia.
Método HTTP y URL:
PATCH https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id
Cuerpo JSON de la solicitud:
{
"settings" : { "insightsConfig" : { "queryInsightsEnabled" : false } }
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2021-01-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "operation-id",
"targetId": "instance-id",
"selfLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/operations/operation-id",
"targetProject": "project-id"
}
Inhabilitar Información útil sobre las consultas en la edición Enterprise Plus de Cloud SQL
Para inhabilitar Estadísticas de consultas en la edición Enterprise Plus de Cloud SQL, haz lo siguiente:
-
En la Google Cloud consola, ve a la página Instancias de Cloud SQL.
- Para abrir la página Overview (Resumen) de una instancia, haz clic en su nombre.
- Haz clic en Editar.
- En la sección Personalizar tu instancia, amplía Estadísticas de consultas.
- Desmarca la casilla Habilitar funciones de Enterprise Plus.
- Haz clic en Guardar.
Siguientes pasos
- Entrada de blog de lanzamiento: Solve database bottlenecks faster with the latest query insights for Cloud SQL Enterprise Plus edition (Resuelve los cuellos de botella de las bases de datos más rápido con las últimas estadísticas de consultas de la edición Enterprise Plus de Cloud SQL)
- Consulta las Google Cloud métricas.
- Blog: Mejora tus habilidades para solucionar problemas de rendimiento de consultas con Cloud SQL Insights
- Vídeo: Presentación de Cloud SQL Insights
- Pódcast: Información valiosa de Cloud SQL
- Codelab Estadísticas
- Optimizar el uso elevado de la CPU
- Optimizar el uso elevado de memoria
- Blog: Presentamos Sqlcommenter: una biblioteca de instrumentación automática de ORM de código abierto
- Blog: Habilitar el etiquetado de consultas con Sqlcommenter