This page is an overview of the high availability (HA) configuration for Cloud SQL instances. To configure a new instance for HA, or to enable HA on an existing instance, see Enabling and disabling high availability on an instance.
HA configuration overview
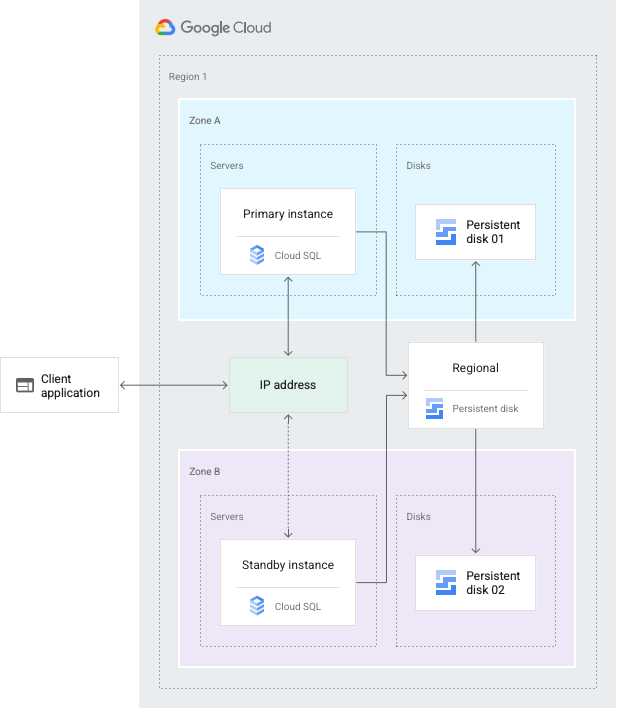
The purpose of an HA configuration is to reduce downtime when a zone or instance becomes unavailable. This might happen during a zonal outage, or when there's a hardware issue. With HA, your data continues to be available to client applications.
The HA configuration provides data redundancy. A Cloud SQL instance configured for HA is also called a regional instance and has a primary and secondary zone within the configured region*. Within a regional instance, the configuration is made up of a primary instance and a standby instance. Through synchronous replication to each zone's persistent disk, all writes made to the primary instance are replicated to disks in both zones before a transaction is reported as committed. In the event of an instance or zone failure, the standby instance becomes the new primary instance. Users are then rerouted to the new primary instance. This process is called a failover.
After a failover, the instance that received the failover continues to be the primary instance, even after the original instance comes back online. After the zone or instance that experienced an outage becomes available again, the original primary instance is destroyed and recreated. Then it becomes the new standby instance. If a failover occurs in the future, the new primary will fail over to the original instance in the original zone.
If you need to have the primary instance in the zone that had the outage, you can do a failback. A failback performs the same steps as the failover, only in the opposite direction, to reroute traffic back to the original instance. To perform a failback, use the procedure in Initiating failover.
Regional persistent disk support for Cloud SQL HA configuration that has at least one dedicated CPU has full Service Level Agreement (SLA) coverage. An HA-configured instance costs twice as much as a standalone instance. This price includes CPU, RAM, and storage. For more information, see the pricing page.
* For more information about region-specific considerations, see Geography and regions.
Read replicas
If availability is a consideration for your read replicas, you can enable HA on the replicas. When you promote such a replica to become a primary instance, it's already set up as a highly available instance.
During a zonal outage, traffic stops to read replicas in that zone. After the zone becomes available again, any read replicas in the zone resume replication from the primary instance. If read replicas are not located in a zone that is undergoing an outage, they connect to the standby instance when it becomes the primary instance.
As a best practice, consider putting some of your read replicas in a different zone from the primary and standby instances. For example, if you have a primary instance in zone A and a standby instance in zone B, put a read replica in zone C to improve your reliability. This practice ensures that read replicas continue to operate even if the zone for the primary instance goes down. You should also add business logic in the client application to send reads to the primary instance when read replicas are unavailable.
Note: The standby instance cannot be used for read queries. This differs from the Cloud SQL for MySQL legacy HA configuration.
Failover overview
If an HA-configured instance becomes unresponsive, Cloud SQL automatically switches to serving data from the standby instance. To see if a failover has occurred, check your operation log failover history.
Learn more about how to build queries in the Logs Explorer. If you need more detailed information about an operation, such as the user who performed the operation, you must enable audit logging.
Click the tabs to see how failover affects your instance.
Normal

Failover

Post-Failover

Failback
Process
The following process occurs:
The primary instance or zone fails.
Each second, the heartbeat system detects whether the primary instance is healthy. If multiple heartbeats aren't detected, failover is initiated.
The standby instance now serves data upon reconnection.
Through a shared static IP address with the primary instance, the standby instance now serves data from the secondary zone.
Requirements
For Cloud SQL to allow a failover, the configuration must meet the following requirements:
- The primary instance must be in a normal operating state (not stopped, undergoing maintenance, or performing a long-running Cloud SQL instance operation such as a backup operation).
- The secondary zone and standby instance must both be in a healthy state. When the standby instance is unresponsive, failover operations are blocked. After Cloud SQL repairs the standby instance and the secondary zone is available, Cloud SQL allows failover.
Backup and restore
Automated backups and point-in-time recovery must be enabled for high-availability instances, excluding read replicas.
Recovery options for standalone instances
Cloud SQL doesn't recover standalone instances from a zonal outage automatically. To re-establish an instance that isn't configured for high availability to a healthy zone, you must restore any zonal instances manually. You can recover a standalone instance from a zonal outage manually by using one of the following options:
Perform point-in-time recovery on the instance to a new instance that you create. To use this option, you must have enabled PITR on the zonal instance prior to the zonal outage. The transaction logs for the instance must be stored in Cloud Storage. If the transaction logs are stored on disk, then you can switch them to Cloud Storage. To use this option, follow the steps in Perform PITR on an unavailable instance.
If the instance has a read replica in a different zone, then you can promote that read replica to replace the standalone instance that's experiencing the zonal outage. To use this option, follow the steps in Promote a replica
For both options, the following considerations apply:
Some recent transactions committed on the primary instance might not appear on the newly recovered instance. The interval of time where transactions might have been lost is the recovery point objective (RPO).
- For PITR recovery, the RPO is typically five minutes or less.
- For read replica promotion, the RPO varies based on the database workload. For more information on how to monitor and reduce replication lag, see Replication lag.
After you perform either of the restoration options, you must reconfigure any clients of the instances that experience the zonal outage because the recovered instances will have different IP addresses and connection names.
Applications and instances
There is no difference in working with non-HA and HA instances, so your application does not need to be configured in any particular way. When failover occurs, any existing connections to the primary instance and read replicas are closed, and it will take approximately 60 seconds for connections to the primary instance to be reestablished. Your application reconnects using the same connection string or IP address, so you do not need to update your application after failover.
To see exactly how your applications are affected by failover, manually initiate failover.
Maintenance downtime
Maintenance events affect primary instances configured with HA in the same way as other instances. You can expect primary instances to be down for a brief period of time. For more information on how maintenance affects HA instances, see How maintenance works. To minimize impact to your service, change maintenance settings to control when downtime occurs.
Performance
Regional persistent disk performance depends on many factors. Your input/output operations per second (IOPS) might be reduced with regional persistent disk in comparison to the zonal persistent disk. Look at VM instance type size and your workload input and output. Another metric to note is that the latency for regional persistent disk with solid-state drives (SSD) is higher than it would be for a zonal persistent disk with SSD. This implies that that if your workload is not a streaming workload and is latency sensitive, it can't reach the IOPS limit as regional persistent disk with SSD has higher latency than a zonal persistent disk with SSD. This is because of the synchronous replication of the data across multiple zones involved in a regional persistent disk to provide multiple copies of data across the zones in a region.
Legacy MySQL high availability option
The legacy process for adding high availability to MySQL instances uses a failover replica. The legacy functionality isn't available in the Google Cloud console. See Legacy configuration: Creating a new instance configured for high availability or Legacy configuration: Configuring an existing instance for high availability.
What's next
- Enable and disable high availability on an instance.
- Initiate failover.
- Learn more about managing your database connections.
- Learn more about regions and zones in Cloud SQL.