Spanner は、Google の最も重要なアプリケーションの一部をサポートするために Google のエンジニアが開発した分散データベースです。これは、強整合性を備えたスケーラブルなデータベースです。データベースと分散システムのコミュニティからコアとなる概念を取り入れ、新しい方法に展開しています。Spanner は、内部の Spanner サービスを Google Cloud Platform 上で一般公開のサービスとして提供しています。
Spanner は Google の重要なビジネス アプリケーションが必要とする稼働時間とスケーリング要件に対応する必要があるため、Spanner をゼロから設計し、広範囲に分散したデータベースを構築しました。サービスは、複数のマシン、データセンター、リージョンに分散されます。この分散機能を利用することで、非常に高度な可用性を維持しながら、巨大なデータセットやワークロードを処理しています。Google では、デベロッパーに優れた環境を提供するため、Spanner で他のエンタープライズ クラスのデータベースと同等に厳密な一貫性を実現することを目指しています。行レベルまたはエンティティ レベルの一貫性しかサポートしていないデータベースや、一貫性をまったく保証していないデータベースよりも、強整合性をサポートするデータベース用のアプリケーションを作成するほうがよいことは明らかです。
このドキュメントでは、Spanner で書き込みと読み取りを行う方法について説明します。また、Spanner が強整合性を保証する方法についても説明します。
最初のステップ
単一のマシンでは処理できない大きなデータセットがあります。また、データセットが小さくても、1 台のマシンで処理するにはワークロードが大きすぎる場合もあります。つまり、複数のマシンに保存できるようにデータをいくつかの部分に分割する方法を考えなければなりません。Google では、データベースのテーブルをスプリットという連続したキー範囲に分割しています。1 台のマシンで複数のスプリットを処理できます。特定のキー範囲を処理するマシンは、高速検索サービスによって決まります。Spanner ユーザーがデータの分割方法やスプリットが存在するマシンを意識することはありません。これにより、大規模で負荷の高い読み取りと書き込みの両方でレイテンシが低くなります。
また、障害の発生時にもデータの可用性を保証する必要があります。このため、Google では障害の発生したドメインの複数のマシンに各スプリットを複製しています。 スプリットのコピー間で一貫したレプリケーションを実現するため、レプリケーションは Paxos アルゴリズムで管理されます。Paxos では、スプリットの投票レプリカが稼働している間、これらのレプリカの 1 つがリーダーに選択され、書き込みを処理し、他のレプリカが読み取りを処理します。
Spanner は、読み取り専用トランザクションと読み取り / 書き込みトランザクションに対応しています。前者は、データを変更しないオペレーション(SQL SELECT ステートメントを含む)の優先トランザクション タイプになります。読み取り専用トランザクションは強整合性を提供し、デフォルトではデータの最新のコピーを使用します。内部ロックを行わずに実行できるため、より高速でスケーラブルになります。読み取り / 書き込みトランザクションは、データの挿入、更新、削除を行うトランザクションに使用されます。読み取りの後に書き込みを実行するトランザクションもこのタイプに含まれます。このトランザクションも高度なスケーラビリティを備えていますが、読み取り / 書き込みトランザクションではロックが行われるため、Paxos リーダーによるオーケストレーションが必要になります。Spanner クライアントがロックを意識することはありません。
これまでの分散データベース システムの多くは、コストの高いマシン間通信が必要になるため、強整合性を保証してきませんでした。Spanner は、Google が開発した TrueTime というテクノロジーを利用して、データベース全体で強整合性を持つスナップショットを提供できます。circa-1985 タイムマシンの次元転移装置のように、Spanner の機能を可能にする技術が TrueTime です。この API により、Google データセンターの任意のマシンが非常に小さい誤差(数ミリ秒単位など)でグローバル時間を認識できます。これにより、さまざまな Spanner マシンは(多くの場合、互いに通信しなくても)トランザクション オペレーションの順序を識別でき、それはクライアントが観測した順序と一致します。TrueTime を機能させるには、Google のデータセンターに特別なハードウェア(原子時計)を組み込む必要がありました。これにより、他のプロトコル(NTP など)よりも非常に高い時間精度と正確性を実現しています。特に、Spanner はすべての読み取りと書き込みにタイムスタンプを割り当てます。タイムスタンプ T1 のトランザクションには、T1 より前に発生したすべての書き込みの結果が必ず反映されます。あるマシンが T2 時点での読み取りを行うには、認識されるデータが少なくとも T2 時点までは最新であったことを確認する必要があります。TrueTime のおかげで、この判定は通常、非常に低コストで行われます。データの整合性を確保するためのプロトコルは複雑ですが、Spanner と整合性については、オリジナルの Spanner のドキュメントと、このドキュメントで詳述されています。
実用的な例
では、実用的な例を使って機能を説明します。
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
この例では、簡単な整数値の主キーが設定されたテーブルを使用します。
| 分割 | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3,224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
上の ExampleTable スキーマでは、主キー空間がスプリットに分割されています。たとえば、ExampleTable に Id が 3700 の行がある場合、その行はスプリット 8 に存在します。前述のように、スプリット 8 は複数のマシンに複製されています。
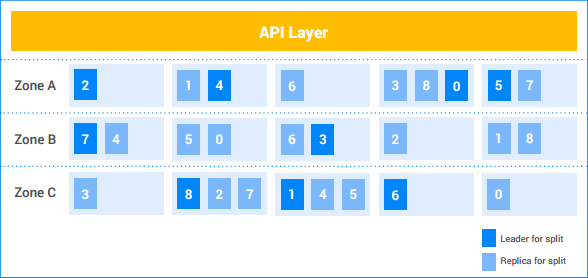
この例の Spanner インスタンスでは、5 つのノードが存在し、インスタンスが 3 つのゾーンに複製されています。0~8 の 9 個のスプリットがあり、濃い影の付いたスプリットが Paxos リーダーに選択されています。これらのスプリットのレプリカ(薄い影の付いた部分)が各ゾーンに存在します。ノード間でのスプリットの分布はゾーンによって異なり、Paxos リーダーが同じゾーンに存在するとは限りません。この柔軟性により、特定の負荷プロファイルや障害に対する Spanner の堅牢性が増します。
単一のスプリットの書き込み
クライアントが新しい行 (7, "Seven") を ExampleTable に挿入する場合について考えてみましょう。
- API レイヤが、
7を含むキー範囲を所有するスプリットを検索します。これはスプリット 1 に存在します。 - API レイヤがスプリット 1 に書き込みリクエストを送信します。
- リーダーがトランザクションを開始します。
- リーダーが行
Id=7に対する書き込みロックの取得を試みます。これは、ローカルで実行されます。別の同時実行の読み取り / 書き込みトランザクションがこの行を読み込んでいる場合、他のトランザクションは読み取りロックを取得します。書き込みロックを取得できるまで現在のトランザクションがブロックされます。- トランザクション B が所有するロックをトランザクション A が待機しているときに、トランザクション A が所有するロックをトランザクション B が待機している場合もあります。どちらのトランザクションもすべてのロックを取得するまでロックを解放しないため、デッドロックが発生します。Spanner は、トランザクションの処理を妨げないように、標準の wound-wait デッドロック防止アルゴリズムを使用しています。新しいトランザクションは古いトランザクションが所有するロックを待機しますが、古いトランザクションはリクエストしたロックを所有する新しいトランザクションを停止します。このため、ロックの待機によるデッドロックは発生しません。
- ロックを取得すると、TrueTime に基づいてリーダーがトランザクションにタイムスタンプを割り当てます。
- このタイムスタンプは、以前にデータを操作して commit したトランザクションよりも大きくなります。これにより、トランザクションの順序(クライアントの観測順)とデータ変更の順序を一致させています。
- リーダーがスプリット 1 のレプリカにトランザクションの情報とタイムスタンプを通知します。 これらのレプリカの大半が、安定したストレージ(分散ファイルシステム内)にトランザクションのミューテーションを保存すると、トランザクションが commit されます。これにより、一部のマシンで障害が発生してもトランザクションを回復することができます。レプリカは、データのコピーにミューテーションをまだ適用していません。
リーダーは、トランザクションのタイムスタンプがリアルタイムで渡されるまで待機します。通常、TrueTime タイムスタンプの不確実性を解消するまで数ミリ秒かかります。これにより、強整合性を実現しています。クライアントがトランザクションの結果を確認すると、他のすべての読み取りでトランザクションの結果を確認できます。この commit 待機は、上記のステップでレプリカの通信と同時に実行されるため、実際のレイテンシ コストは最小限になります。詳細については、このドキュメントをご覧ください。
リーダーがクライアントに応答し、トランザクションが commit されたことを通知します。トランザクションの commit タイムスタンプを報告する場合もあります。
クライアントへの応答と同時に、トランザクションのミューテーションがデータに適用されます。
- リーダーがデータのコピーにミューテーションを適用し、トランザクション ロックを解放します。
- また、スプリット 1 の他のレプリカに、ミューテーションをデータのコピーに適用するように通知します。
- ミューテーションの結果を確認する必要がある読み取り / 書き込みトランザクションまたは読み取り専用トランザクションは、ミューテーションが適用されるまで待機します。適用後、データの読み取りを試みます。読み取り / 書き込みトランザクションの場合、読み取りロックを取得する必要があるため、この処理を実行します。読み取り専用トランザクションの場合、読み取りのタイムスタンプと最後に適用されたデータのタイムスタンプを比較し、この処理を実行します。
これらの処理はすべて数ミリ秒で行われます。この書き込みは、1 つのスプリットしか関係していないため、Spanner が実行する書き込みの中で最も安価になります。
複数のスプリットの書き込み
複数のスプリットが関連する場合、別の調整が必要になります(標準の 2 フェーズ commit アルゴリズムを使用)。
では、4,000 行のテーブルについて考えてみましょう。
| 1 | "1" |
| 2 | 「two」 |
| … | … |
| 4000 | "4,000" |
クライアントが 1 つのトランザクションで行 1000 の値を読み取り、2000、3000、4000 行に値を書き込むとします。この処理は、次のように読み取り / 書き込みトランザクションで実行します。
- クライアントが読み取り / 書き込みトランザクション t を開始します。
- クライアントが、行 1000 に対する読み取りリクエストを API レイヤに送信し、t の一部としてタグを付けます。
- API レイヤがキー
1000を所有するスプリットを検索します。これはスプリット 4 に存在します。 API レイヤがスプリット 4 のリーダーに読み取りリクエストを送信し、t の一部としてタグを付けます。
スプリット 4 のリーダーが行
Id=1000に対する読み取りロックの取得を試みます。これは、ローカルで実行されます。別の同時実行トランザクションがこの行に対して書き込みロックを保持している場合、ロックを取得できるまで現在のトランザクションがブロックされます。ただし、この読み取りロックは、他のトランザクションによる読み取りロックの取得をブロックしません。- 単一スプリットの場合と同様に、wound-wait でデッドロックを回避します。
リーダーは
Id1000(「1,000」)の値を検索し、読み取り結果をクライアントに返します。
後でクライアントがトランザクション t. に Commit リクエストを送信します。この commit リクエストには 3 つのミューテーション(
[2000, "Dos Mil"]、[3000, "Tres Mil"]および[4000, "Quatro Mil"])が含まれています。- トランザクションに関連するすべてのスプリットがトランザクションの参加者になります。このケースでは、スプリット 4(キー
1000の読み取り)、スプリット 7(キー2000のミューテーションの処理)、スプリット 8(キー3000とキー4000のミューテーションの処理)が参加者になります。
- トランザクションに関連するすべてのスプリットがトランザクションの参加者になります。このケースでは、スプリット 4(キー
参加者の 1 つがコーディネーターになります。このケースでは、スプリット 7 のリーダーがコーディネーターとなります。コーディネーターは、すべての参加者の間でトランザクションが自動的に commit または中止されるように調整します。1 つの参加者で commit され、別の参加者で中止されることはありません。
- 参加者とコーディネーターの処理は、これらのスプリットのリーダーのマシンで実行されます。
参加者がロックを取得します。これが 2 フェーズの最初の段階になります。
- スプリット 7 がキー
2000に対する書き込みロックを取得します。 - スプリット 8 がキー
3000とキー4000に対する書き込みロックを取得します。 - スプリット 4 が、キー
1000に対する読み取りロックを保持していることを確認します(マシンのクラッシュや wound-wait アルゴリズムでロックを失っていないことを確認します)。 - それぞれの参加者のスプリットが、大半のスプリットのレプリカにロックを複製し、一連のロックを記録します。これにより、サーバーで障害が発生してもロックを維持することができます。
- コーディネーターがすべての参加者からロック保持の通知を受け取ると、トランザクション全体が commit できる状態になります。トランザクションが必要とするロックがすべて保持された時点でトランザクションが commit されるため、トランザクションの順序を正しく設定することができます。
- ロックが取得できない場合もあります(wound-wait アルゴリズムでデッドロックが回避される場合など)。参加者がトランザクションを commit できないことを通知すると、トランザクション全体が中止されます。
- スプリット 7 がキー
すべての参加者とコーディネーターが正常にロックを取得すると、コーディネーター(スプリット 7)がトランザクションの commit を決定します。TrueTime に基づいてトランザクションにタイムスタンプを割り当てます。
- この commit の決定とキー
2000のミューテーションがスプリット 7 のメンバーに複製されます。スプリット 7 のレプリカの大半が、安定したストレージに commit の決定を記録すると、トランザクションが commit されます。
- この commit の決定とキー
コーディネーターがトランザクションの結果をすべての参加者に通知します。これが 2 フェーズ commit の第 2 段階になります。
- 各参加者のリーダーが commit の決定を参加者のスプリットのレプリカに複製します。
トランザクションが commit されると、コーディネーターとすべての参加者がデータにミューテーションを適用します。
- 単一スプリットの場合と同様に、コーディネーターまたは参加者のデータの読み取りは、データが適用されるまで待機します。
コーディネーターのリーダーがクライアントに応答し、トランザクションが commit されたことを通知します。トランザクションの commit タイムスタンプを返す場合もあります。
- 単一スプリットの場合と同様に、強整合性を維持するため、commit の待機後に結果がクライアントに送信されます。
これらの処理はすべて数ミリ秒で行われます。スプリット間での調整が必要になるため、単一スプリットの場合よりも若干長くなります。
強力な読み取り(複数スプリット)
クライアントが読み取り専用のトランザクションの一部として、Id >= 0 で Id < 700 の行を読み取るとします。
- API レイヤが、範囲が
[0, 700)のキーを所有するスプリットを検索します。 これらの行は、スプリット 0、スプリット 1、スプリット 2 で所有されています。 - ここでは、複数のマシン間で読み取りを行うため、API レイヤは現在の TrueTime を使用して読み取りタイムスタンプを取得します。これにより、両方の読み取りがデータベースの同じスナップショットのデータを返します。
- 他の読み取り(ステイル読み取りなど)では、読み取り時にもタイムスタンプを取得します(ただし、タイムスタンプが古い可能性があります)。
- API レイヤが、スプリット 0、スプリット 1、スプリット 2 の一部のレプリカに読み取りリクエストを送信します。また、前のステップで選択した読み取りタイムスタンプも含まれます。
強力な読み取りの場合、通常サービス レプリカは、リーダーに RPC を行って、適用する必要がある最後のトランザクションのタイムスタンプを問い合わせ、そのトランザクションが適用されると読み取りを続行できます。レプリカがリーダーであるか、レプリカが内部状態と TrueTime からリクエストを処理するのに十分な状態であると判断した場合、読み取りを直接行います。
レプリカからの結果が結合され、API レイヤ経由でクライアントに返されます。
読み取り専用トランザクションでは、読み取りでロックが取得されません。特定のスプリットの最新のレプリカから読み取りデータが提供されると、システムの読み取りスループットが非常に高くなる可能性があります。クライアントが 10 秒以上前の読み取りを実行できる場合、読み取りスループットがさらに高くなる可能性があります。通常、リーダーは 10 秒ごとに最新のタイムスタンプでレプリカを更新しているため、古いタイムスタンプの読み取りデータによってリーダーに追加の RPC が行われない場合があります。
まとめ
強力なトランザクションを保証する場合、すべてのマシン間で通信が必要になるため、多額の費用が必要になると分散データベースの設計者は考えています。Spanner では、柔軟なスケーリングと分散により、トランザクションのコスト削減を実現しています。TrueTime により、多くのタイプの調整でマシン間の通信が少なくなっています。エンジニアリングとパフォーマンスを慎重に調整した結果、保証を強化しながら高パフォーマンスを提供できるシステムが構築されました。保証の弱い他のデータベース システムと比べると、Spanner では非常に簡単にアプリケーションを開発できます。アプリケーション デベロッパーは、データの競合状態や不整合を心配することなく、高品質のアプリケーションを作成して配布することに集中できます。