Best practice per lo scaling di Cloud Service Mesh su GKE
Questa guida descrive le best practice per risolvere i problemi di scalabilità per le architetture Cloud Service Mesh gestite su Google Kubernetes Engine. L'obiettivo principale di questi consigli è garantire prestazioni, affidabilità e utilizzo delle risorse ottimali per le tue applicazioni di microservizi man mano che crescono.
Per comprendere le limitazioni alla scalabilità, consulta Limiti di scalabilità di Cloud Service Mesh.
La scalabilità di Cloud Service Mesh su GKE dipende dal funzionamento efficiente dei suoi due componenti principali: il data plane e il control plane. Questo documento si concentra principalmente sullo scaling del data plane.
Identificare i problemi di scalabilità del control plane rispetto al data plane
In Cloud Service Mesh, i problemi di scalabilità possono verificarsi nel control plane o nel data plane. Ecco come identificare il tipo di problema di scalabilità che stai riscontrando:
Sintomi di problemi di scalabilità del control plane
Rilevamento Service Discovery: i nuovi servizi o endpoint impiegano molto tempo per essere rilevati e diventare disponibili.
Ritardi di configurazione:le modifiche alle regole di gestione del traffico o alle norme di sicurezza richiedono molto tempo per essere propagate.
Aumento della latenza nelle operazioni del control plane: operazioni come la creazione, l'aggiornamento o l'eliminazione delle risorse Cloud Service Mesh diventano lente o non rispondono.
Errori relativi a Traffic Director: potresti notare errori nei log di Cloud Service Mesh o nelle metriche del piano di controllo che indicano problemi di connettività, esaurimento delle risorse o limitazione dell'API.
Ambito dell'impatto: i problemi del control plane in genere interessano l'intera mesh, causando un degrado delle prestazioni diffuso.
Sintomi di problemi di scalabilità del data plane
Aumento della latenza nella comunicazione da servizio a servizio:le richieste a un servizio in-mesh riscontrano una latenza o timeout più elevati, ma non si verifica un utilizzo elevato di CPU/memoria nei container del servizio.
Utilizzo elevato della CPU o della memoria nei proxy Envoy:un utilizzo elevato della CPU o della memoria può indicare che i proxy faticano a gestire il carico di traffico.
Impatto localizzato:i problemi del data plane in genere interessano servizi o carichi di lavoro specifici, a seconda dei pattern di traffico e dell'utilizzo delle risorse dei proxy Envoy.
Scalabilità del piano dati
Per scalare il piano dati, prova le seguenti tecniche:
- Configura la scalabilità automatica orizzontale dei pod (HPA)
- Ottimizzare la configurazione del proxy Envoy
- Monitorare e perfezionare
Configura Horizontal Pod Autoscaling (HPA) per i carichi di lavoro
Utilizza la scalabilità automatica orizzontale dei pod (HPA) per scalare dinamicamente i carichi di lavoro con pod aggiuntivi in base all'utilizzo delle risorse. Considera quanto segue quando configuri HPA:
Utilizza il parametro
--horizontal-pod-autoscaler-sync-periodperkube-controller-managerper regolare la frequenza di polling del controller HPA. La frequenza di polling predefinita è di 15 secondi e potresti prendere in considerazione di impostarla su un valore inferiore se prevedi picchi di traffico più rapidi. Per scoprire di più su quando utilizzare HPA con GKE, consulta Scalabilità automatica orizzontale dei pod.Il comportamento di scalabilità predefinito può comportare la distribuzione (o l'interruzione) di un numero elevato di pod contemporaneamente, il che può causare un picco nell'utilizzo delle risorse. Valuta la possibilità di utilizzare norme di scalabilità per limitare la velocità con cui è possibile eseguire il deployment dei pod.
Utilizza EXIT_ON_ZERO_ACTIVE_CONNECTIONS per evitare interruzioni delle connessioni durante la riduzione delle risorse.
Per ulteriori dettagli sulla HPA, consulta Scalabilità automatica pod orizzontale nella documentazione di Kubernetes.
Ottimizzare la configurazione del proxy Envoy
Per ottimizzare la configurazione del proxy Envoy, tieni presenti i seguenti consigli:
Limiti delle risorse
Puoi definire richieste e limiti delle risorse per i sidecar Envoy nelle specifiche dei pod. Ciò impedisce la contesa delle risorse e garantisce prestazioni coerenti.
Puoi anche configurare i limiti delle risorse predefiniti per tutti i proxy Envoy nel mesh utilizzando le annotazioni delle risorse.
I limiti delle risorse ottimali per i proxy Envoy dipendono da fattori quali il volume di traffico, la complessità del carico di lavoro e le risorse dei nodi GKE. Monitora e perfeziona continuamente il tuo mesh di servizi per garantire prestazioni ottimali.
Considerazione importante:
- Qualità del servizio (QoS): l'impostazione di richieste e limiti garantisce che i proxy Envoy abbiano una qualità del servizio prevedibile.
Definisci l'ambito delle dipendenze del servizio
Valuta la possibilità di ridurre il grafico delle dipendenze della mesh dichiarando tutte le dipendenze tramite l'API Sidecar. Ciò limita le dimensioni e la complessità della configurazione inviata a un determinato carico di lavoro, il che è fondamentale per mesh più grandi.
Ad esempio, di seguito è riportato il grafico del traffico per l'applicazione di esempio boutique online.
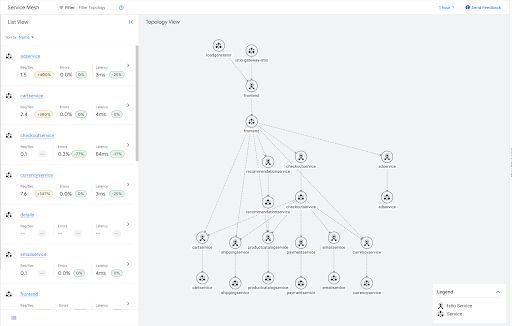
Molti di questi servizi sono foglie nel grafico e, in quanto tali, non devono disporre di informazioni sull'uscita per nessuno degli altri servizi nel mesh. Puoi applicare una risorsa Sidecar che limiti l'ambito della configurazione del sidecar per questi servizi foglia, come mostrato nell'esempio seguente.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
Per informazioni dettagliate su come eseguire il deployment di questa applicazione di esempio, consulta Applicazione di esempio Online Boutique.
Un altro vantaggio dell'ambito sidecar è la riduzione delle query DNS non necessarie. L'ambito delle dipendenze del servizio garantisce che un sidecar Envoy esegua query DNS solo per i servizi con cui comunicherà effettivamente, anziché per ogni cluster nemesh di servizish.
Per tutti i deployment su larga scala che riscontrano problemi con le dimensioni delle configurazioni nei sidecar, l'ambito delle dipendenze del servizio è fortemente consigliato per la scalabilità del mesh.
Per limitare l'ambito di configurazione per tutti i carichi di lavoro all'interno di un singolo spazio dei nomi, crea una risorsa Sidecar in quello spazio dei nomi. In questo modo, tutti i proxy Envoy all'interno di questo spazio dei nomi riceveranno solo la configurazione per i servizi nel proprio spazio dei nomi.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidecar
namespace: my-app
spec:
egress:
- hosts:
- "my-app/*"
Puoi applicare il comportamento predefinito a ogni spazio dei nomi nel mesh applicando una singola risorsa Sidecar allo spazio dei nomi radice, in genere istio-system.
Il seguente sidecar limita il traffico in uscita di ogni sidecar nel mesh ai servizi che si trovano all'interno del proprio spazio dei nomi.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidear
namespace: istio-system
spec:
egress:
- hosts:
- "./*"
Tieni presente che Cloud Service Mesh impone un limite al numero totale di risorse Sidecar che possono essere create all'interno di un'unica mesh. A causa di questo vincolo, la creazione di Sidecar a livello di spazio dei nomi è la pratica consigliata.
Monitorare e perfezionare
Dopo aver impostato i limiti iniziali delle risorse, è fondamentale monitorare i proxy Envoy per assicurarsi che funzionino in modo ottimale. Utilizza le dashboard GKE per monitorare l'utilizzo di CPU e memoria e regolare i limiti delle risorse in base alle esigenze.
Per determinare se un proxy Envoy richiede limiti di risorse maggiori, monitora il suo consumo di risorse in condizioni di traffico tipiche e di picco. Ecco cosa cercare:
Utilizzo elevato della CPU:se l'utilizzo della CPU di Envoy si avvicina o supera costantemente il limite, potrebbe avere difficoltà a elaborare le richieste, con conseguente aumento della latenza o interruzione delle richieste. Valuta la possibilità di aumentare il limite della CPU.
In questo caso, potresti essere propenso a scalare utilizzando lo scaling orizzontale, ma se il proxy sidecar non è in grado di elaborare le richieste in modo rapido come il container dell'applicazione, la modifica dei limiti della CPU potrebbe produrre i risultati migliori.
Utilizzo elevato della memoria:se l'utilizzo della memoria di Envoy si avvicina o supera il limite, potrebbe iniziare a interrompere le connessioni o riscontrare errori di esaurimento della memoria (OOM). Aumenta il limite di memoria per evitare questi problemi.
Log degli errori:esamina i log di Envoy per individuare errori correlati all'esaurimento delle risorse, ad esempio errori upstream connect error o disconnect or reset before headers o too many open files. Questi errori potrebbero indicare che il proxy ha bisogno di più risorse. Consulta la documentazione sulla risoluzione dei problemi di scalabilità per altri errori relativi ai problemi di scalabilità.
Metriche sul rendimento:monitora le metriche chiave sul rendimento, come latenza delle richieste, tassi di errore e velocità effettiva. Se noti un peggioramento delle prestazioni correlato a un elevato utilizzo delle risorse, potrebbe essere necessario aumentare i limiti.
Se imposti e monitori attivamente i limiti delle risorse per i proxy del piano dati, puoi assicurarti che la tuamesh di servizih venga scalata in modo efficiente su GKE.
Scalabilità del control plane
Questa sezione descrive le impostazioni da modificare per scalare il control plane.
Selettori di rilevamento
I selettori di rilevamento sono un campo in MeshConfig che consente di specificare l'insieme di spazi dei nomi presi in considerazione dai control plane durante il calcolo degli aggiornamenti della configurazione per i sidecar.
Per impostazione predefinita, Cloud Service Mesh monitora tutti gli spazi dei nomi nel cluster. Questo può essere un collo di bottiglia per i cluster di grandi dimensioni che non devono monitorare tutte le risorse.
Utilizza discoverySelectors per ridurre il carico di calcolo sul control plane
limitando il numero di risorse Kubernetes (come servizi, pod ed
endpoint) monitorate ed elaborate.
Quando utilizzi l'implementazione del control plane TRAFFIC_DIRECTOR,
Cloud Service Mesh crea solo risorse Google Cloud , come servizi di backend e gruppi di endpoint di rete, per le risorse Kubernetes negli spazi dei nomi specificati in discoverySelectors.
Per saperne di più, consulta la sezione Selettori di rilevamento nella documentazione di Istio.
Resilienza integrata
Puoi modificare le seguenti impostazioni per aumentare la resilienza del mesh di servizi:
Rilevamento outlier
Il rilevamento outlier monitora gli host in un servizio upstream e li rimuove dal pool di bilanciamento del carico al raggiungimento di una determinata soglia di errore.
- Configurazione chiave:
outlierDetection: Impostazioni che controllano l'eliminazione degli host con problemi di integrità dal pool di bilanciamento del carico.
- Vantaggi:mantiene un insieme integro di host nel pool di bilanciamento del carico.
Per saperne di più, consulta Rilevamento di outlier nella documentazione di Istio.
Nuovi tentativi
Mitiga gli errori temporanei riprovando automaticamente le richieste non riuscite.
- Configurazione chiave:
attempts: numero di tentativi.perTryTimeout: Timeout per tentativo di ripetizione. Imposta questo valore su un periodo più breve rispetto al timeout complessivo. Determina il tempo di attesa per ogni singolo tentativo di ripetizione.retryBudget: Numero massimo di nuovi tentativi simultanei.
- Vantaggi: tassi di successo più elevati per le richieste, impatto ridotto di errori intermittenti.
Fattori da considerare:
- Idempotenza:assicurati che l'operazione di cui viene eseguito un nuovo tentativo sia idempotente, ovvero che possa essere ripetuta senza effetti collaterali indesiderati.
- Max Retries:limita il numero di nuovi tentativi (ad es. massimo 3) per evitare loop infiniti.
- Interruzione del circuito:integra i tentativi con gli interruttori di sicurezza per impedire i tentativi quando un servizio non funziona in modo coerente.
Per saperne di più, consulta la sezione Retries nella documentazione di Istio.
Timeout
Utilizza i timeout per definire il tempo massimo consentito per l'elaborazione delle richieste.
- Configurazione chiave:
timeout: Timeout della richiesta per un servizio specifico.idleTimeout: Tempo durante il quale una connessione può rimanere inattiva prima della chiusura.
- Vantaggi: migliore reattività del sistema, prevenzione delle perdite di risorse, protezione dal traffico dannoso.
Fattori da considerare:
- Latenza di rete:tieni conto del tempo di round trip (RTT) previsto tra i servizi. Lascia un po' di margine per ritardi imprevisti.
- Grafico delle dipendenze del servizio:per le richieste concatenate, assicurati che il timeout di un servizio chiamante sia inferiore al timeout cumulativo delle relative dipendenze per evitare errori a cascata.
- Tipi di operazioni:le attività a lunga esecuzione potrebbero richiedere timeout significativamente più lunghi rispetto ai recuperi di dati.
- Gestione degli errori: i timeout devono attivare una logica di gestione degli errori appropriata (ad es. riprova, fallback, interruzione del circuito).
Per saperne di più, consulta la sezione Timeout nella documentazione di Istio.
Monitorare e perfezionare
Ti consigliamo di iniziare con le impostazioni predefinite per timeout, rilevamento di outlier e tentativi e poi di regolarle gradualmente in base ai requisiti specifici del servizio e ai pattern di traffico osservati. Ad esempio, esamina i dati reali sul tempo che in genere impiegano i tuoi servizi per rispondere. Quindi, regola i timeout in modo che corrispondano alle caratteristiche specifiche di ogni servizio o endpoint.
Telemetria
Utilizza la telemetria per monitorare continuamente il mesh di servizi e regolare la relativa configurazione per ottimizzare le prestazioni e l'affidabilità.
- Metriche:utilizza metriche complete, in particolare volumi di richieste, latenza e tassi di errore. Integra con Cloud Monitoring per la visualizzazione e gli avvisi.
- Tracciamento distribuito:attiva l'integrazione del tracciamento distribuito con Cloud Trace per ottenere informazioni approfondite sui flussi di richieste nei tuoi servizi.
- Logging:configura il logging degli accessi per acquisire informazioni dettagliate su richieste e risposte.
Letture aggiuntive
- Per saperne di più su Cloud Service Mesh, consulta la panoramica di Cloud Service Mesh.
- Per indicazioni generali sulla scalabilità di Site Reliability Engineering (SRE), consulta i capitoli Handling Overload e Addressing Cascading Failures del libro Google SRE.