En esta página se explica cómo resolver problemas relacionados con el balanceo de carga en clústeres de Google Kubernetes Engine (GKE) mediante recursos de Service, Ingress o Gateway.
No se ha encontrado BackendConfig
Este error se produce cuando se especifica un BackendConfig para un puerto de servicio en la anotación de servicio, pero no se encuentra el recurso BackendConfig.
Para evaluar un evento de Kubernetes, ejecuta el siguiente comando:
kubectl get event
El siguiente ejemplo de resultado indica que no se ha encontrado tu BackendConfig:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
Para solucionar este problema, asegúrate de que no has creado el recurso BackendConfig en el espacio de nombres incorrecto o de que no has escrito mal su referencia en la anotación Service.
No se ha encontrado la política de seguridad de entrada
Una vez creado el objeto Ingress, si la política de seguridad no se asocia correctamente al servicio LoadBalancer, evalúa el evento de Kubernetes para ver si hay algún error de configuración. Si tu BackendConfig especifica una política de seguridad que no existe, se emitirá periódicamente un evento de advertencia.
Para evaluar un evento de Kubernetes, ejecuta el siguiente comando:
kubectl get event
El siguiente ejemplo de salida indica que no se ha encontrado tu política de seguridad:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
Para solucionar este problema, especifique el nombre de la política de seguridad correcta en su BackendConfig.
Solucionar errores de la serie 500 con NEGs durante el escalado de cargas de trabajo en GKE
Síntoma:
Cuando usas NEGs aprovisionados de GKE para el balanceo de carga, es posible que se produzcan errores 502 o 503 en los servicios durante la reducción de la carga de trabajo. Los errores 502 se producen cuando los pods se terminan antes de que se cierren las conexiones existentes, mientras que los errores 503 se producen cuando el tráfico se dirige a pods eliminados.
Este problema puede afectar a los clústeres si usas productos de balanceo de carga gestionados de GKE que utilizan NEGs, como Gateway, Ingress y NEGs independientes. Si sueles escalar tus cargas de trabajo, tu clúster corre un mayor riesgo de verse afectado.
Diagnóstico:
Si eliminas un pod en Kubernetes sin vaciar su endpoint y sin quitarlo primero del NEG, se producirán errores de la serie 500. Para evitar problemas durante la finalización de los pods, debes tener en cuenta el orden de las operaciones. En las siguientes imágenes se muestran situaciones en las que BackendService Drain Timeout no está definido y en las que BackendService Drain Timeout está definido con BackendConfig.
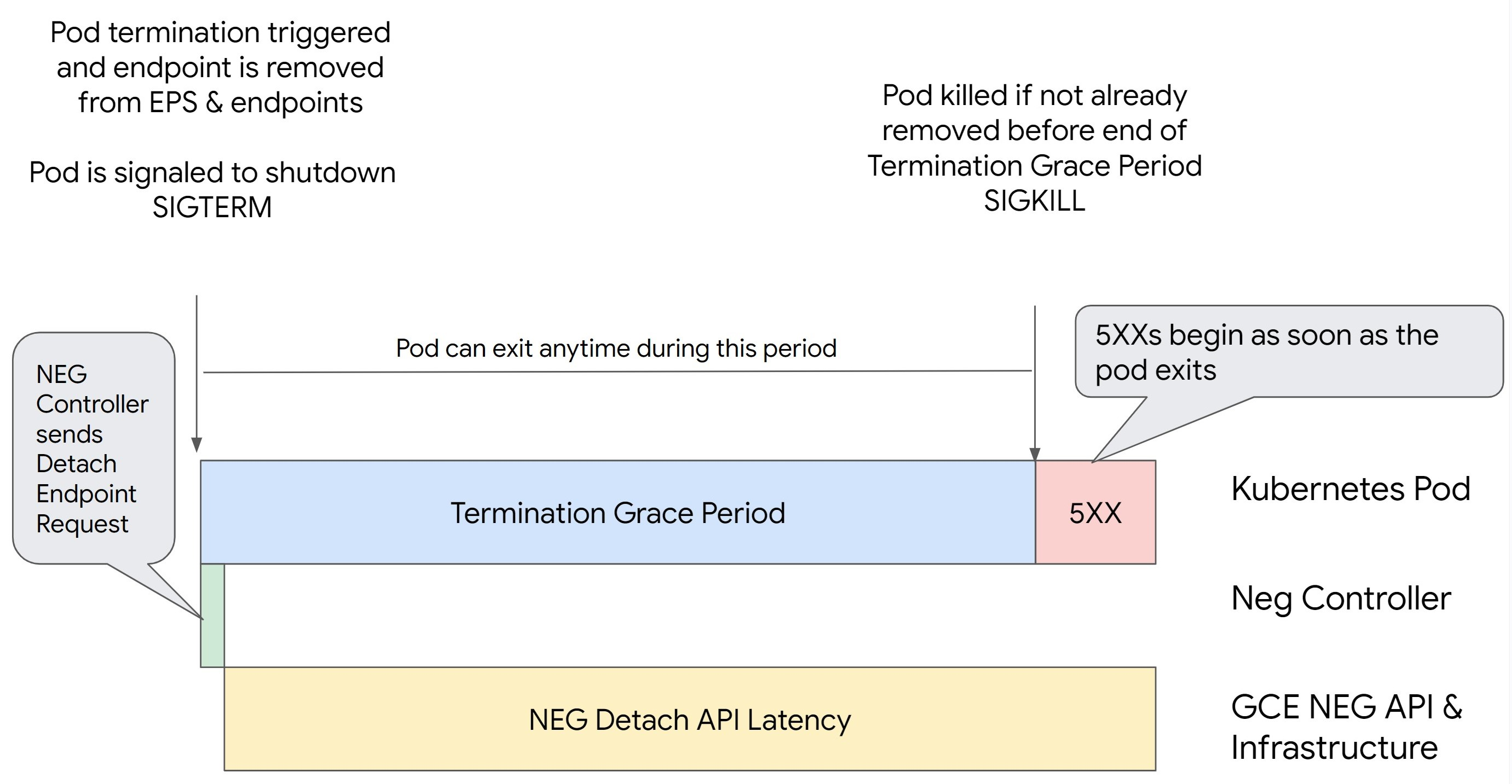
Situación 1: BackendService Drain Timeout no está definida.
En la siguiente imagen se muestra un caso en el que BackendService Drain Timeout no está definido.
Situación 2: se ha definido BackendService Drain Timeout.
En la siguiente imagen se muestra un caso en el que se ha definido el BackendService Drain Timeout.
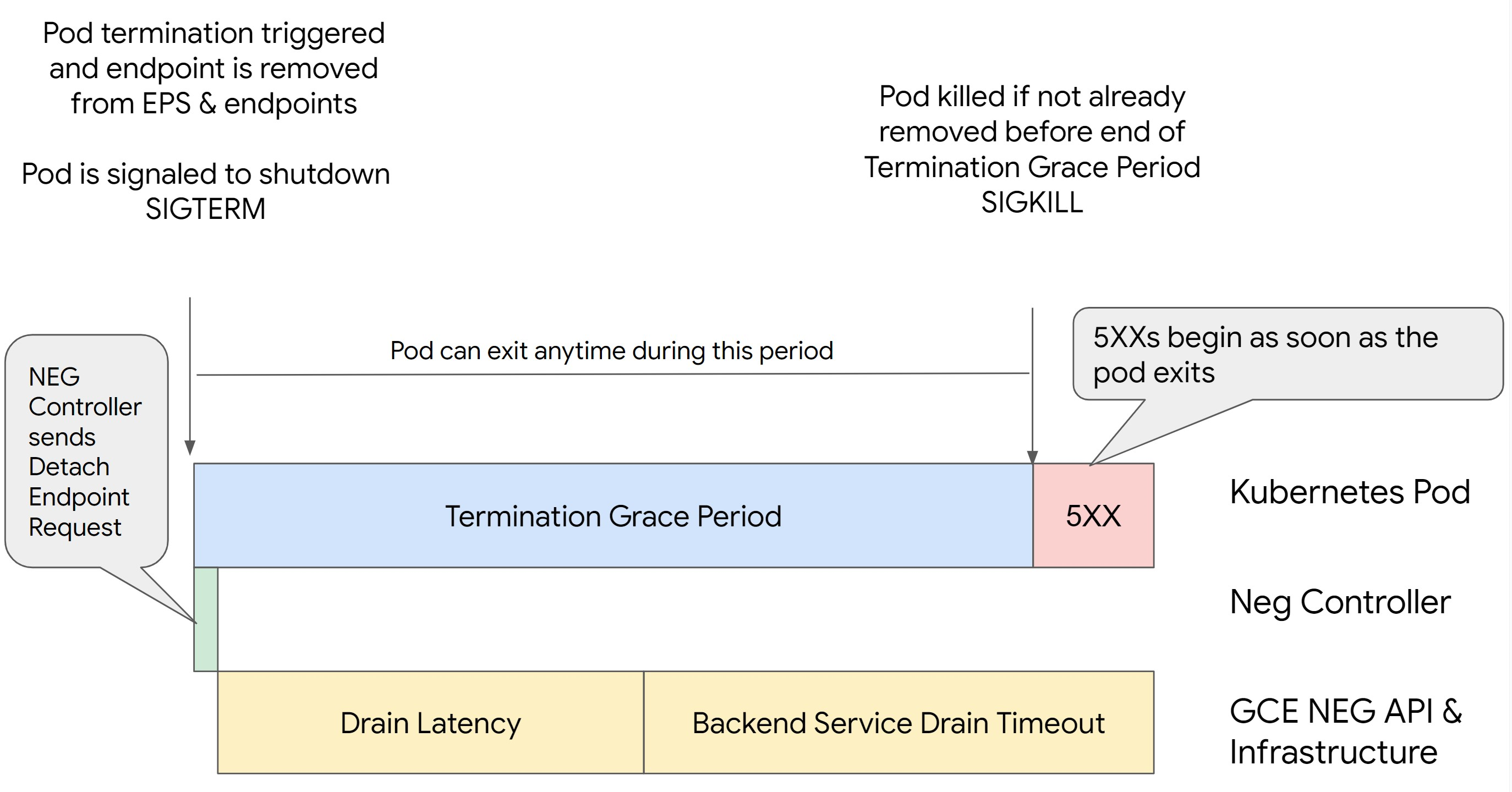
El momento exacto en el que se producen los errores de la serie 500 depende de los siguientes factores:
Latencia de separación de la API NEG: representa el tiempo que tarda en finalizar la operación de separación en Google Cloud. Esto depende de varios factores ajenos a Kubernetes, como el tipo de balanceador de carga y la zona específica.
Latencia de purga: es el tiempo que tarda el balanceador de carga en empezar a dirigir el tráfico lejos de una parte concreta de tu sistema. Una vez que se inicia el drenaje, el balanceador de carga deja de enviar nuevas solicitudes al endpoint. Sin embargo, sigue habiendo una latencia en el activador del drenaje (latencia del drenaje), lo que puede provocar errores 503 temporales si el pod ya no existe.
Configuración de la comprobación del estado: los umbrales de comprobación del estado más sensibles reducen la duración de los errores 503, ya que pueden indicar al balanceador de carga que deje de enviar solicitudes a los endpoints aunque la operación de separación no haya finalizado.
Periodo de gracia de finalización: determina el tiempo máximo que se le da a un pod para salir. Sin embargo, un pod puede salir antes de que finalice el periodo de gracia de finalización. Si un pod tarda más de este periodo, se le obliga a salir al final del mismo. Este es un ajuste del pod y debe configurarse en la definición de la carga de trabajo.
Posible solución:
Para evitar esos errores 5XX, aplica los siguientes ajustes. Los valores de tiempo de espera son orientativos y puede que tengas que ajustarlos a tu aplicación específica. En la siguiente sección se explica el proceso de personalización.
En la siguiente imagen se muestra cómo mantener activo el Pod con un gancho preStop:
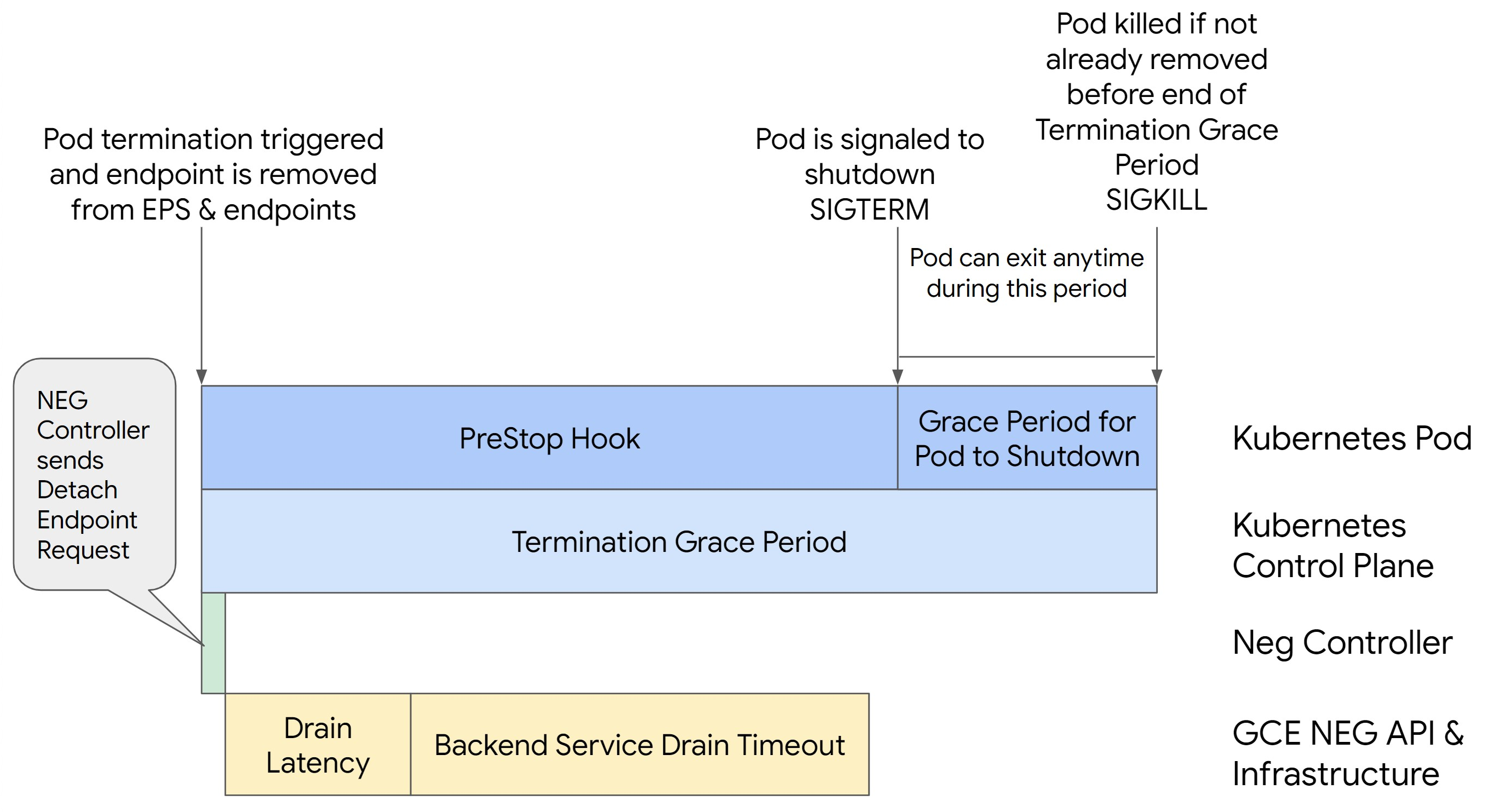
Para evitar errores de la serie 500, sigue estos pasos:
Define el
BackendService Drain Timeoutde tu servicio en 1 minuto.Los usuarios de Ingress pueden consultar cómo definir el tiempo de espera en BackendConfig.
En el caso de los usuarios de la pasarela, consulta cómo configurar el tiempo de espera en GCPBackendPolicy.
Si gestionas tus BackendServices directamente al usar NEGs independientes, consulta cómo definir el tiempo de espera directamente en el BackendService.
Prolonga la
terminationGracePerioden el Pod.Define el
terminationGracePeriodSecondsen el Pod en 3,5 minutos. Si se combina con los ajustes recomendados, tus pods tendrán entre 30 y 45 segundos para apagarse correctamente después de que se haya eliminado el endpoint del pod del NEG. Si necesitas más tiempo para el cierre gradual, puedes ampliar el periodo de gracia o seguir las instrucciones que se indican en la sección Personalizar tiempos de espera.El siguiente manifiesto de Pod especifica un tiempo de espera hasta la desconexión de 210 segundos (3,5 minutos):
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Aplica un hook de
preStopa todos los contenedores.Aplica un gancho
necesario.preStopque asegure que el pod esté activo durante 120 segundos más mientras se agota el punto final del pod en el balanceador de carga y se elimina del NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Personalizar los tiempos de espera
Para asegurar la continuidad del pod y evitar errores de la serie 500, el pod debe estar activo hasta que se elimine el endpoint del NEG. Para evitar los errores 502 y 503, te recomendamos que implementes una combinación de tiempos de espera y un gancho preStop.
Para que el Pod siga funcionando durante más tiempo durante el proceso de apagado, añade un preStop hook
al Pod. Ejecuta el hook preStop antes de que se le indique a un pod que salga, de modo que el hook preStop se pueda usar para mantener activo el pod hasta que se quite su endpoint correspondiente del NEG.
Para ampliar el tiempo que un Pod permanece activo durante el proceso de cierre, inserta un hook preStop en la configuración del Pod de la siguiente manera:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
Puedes configurar los tiempos de espera y los ajustes relacionados para gestionar el cierre correcto de los pods durante las reducciones de escala de las cargas de trabajo. Puedes ajustar los tiempos de espera en función de casos prácticos específicos. Te recomendamos que empieces con tiempos de espera más largos y que reduzcas la duración según sea necesario. Puedes personalizar los tiempos de espera configurando los parámetros relacionados con el tiempo de espera y el gancho preStop de las siguientes formas:
Tiempo de espera de drenaje del servicio de backend
El parámetro Backend Service Drain Timeout no está definido de forma predeterminada y no tiene ningún efecto. Si define el parámetro Backend Service Drain Timeout y lo activa, el balanceador de carga dejará de enrutar nuevas solicitudes al endpoint y esperará el tiempo de espera antes de finalizar las conexiones.
Puedes definir el parámetro Backend Service Drain Timeout mediante BackendConfig con Ingress, GCPBackendPolicy con Gateway o manualmente en BackendService con NEGs independientes. El tiempo de espera debe ser entre 1,5 y 2 veces mayor que el tiempo que se tarda en procesar una solicitud. De esta forma, si se recibe una solicitud justo antes de que se inicie el drenaje, se completará antes de que finalice el tiempo de espera. Si asigna al parámetro Backend Service Drain Timeout un valor superior a 0, se reducen los errores 503 porque no se envían nuevas solicitudes a los endpoints que se van a retirar. Para que este tiempo de espera sea efectivo, debes usarlo con el hook preStop para asegurarte de que el pod permanezca activo mientras se produce el drenaje. Sin esta combinación, las solicitudes que no se hayan completado recibirán un error 502.
preStop Tiempo de enganche
El hook preStop debe retrasar el cierre del pod lo suficiente para que se completen tanto la latencia de drenaje como el tiempo de espera de drenaje del servicio backend, lo que asegura que se produzca un drenaje de conexión adecuado y que se elimine el endpoint del NEG antes de que se cierre el pod.
Para obtener resultados óptimos, asegúrate de que el tiempo de ejecución del preStop hook sea mayor o igual que la suma de la latencia de Backend Service Drain Timeout y la latencia de drenaje.
Calcula el tiempo de ejecución ideal de tu preStop hook con la siguiente fórmula:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Haz los cambios siguientes:
BACKEND_SERVICE_DRAIN_TIMEOUT: la hora que hayas configurado paraBackend Service Drain Timeout.DRAIN_LATENCY: tiempo estimado de latencia de vaciado. Te recomendamos que uses un minuto como estimación.
Si persisten 500 errores, estima la duración total de la incidencia y añade el doble de ese tiempo a la latencia de purga estimada. De esta forma, te aseguras de que tu Pod tenga tiempo suficiente para agotar las pilas correctamente antes de que se retire del servicio. Puedes ajustar este valor si es demasiado largo para tu caso práctico específico.
También puedes estimar el tiempo examinando la marca de tiempo de eliminación del pod y la marca de tiempo en la que se quitó el endpoint del NEG en los registros de auditoría de Cloud.
Parámetro de periodo de gracia de rescisión
Debes configurar el parámetro terminationGracePeriod para que el hook preStop tenga tiempo suficiente para finalizar y el pod pueda completar un cierre ordenado.
De forma predeterminada, si no se define explícitamente, el valor de terminationGracePeriod es de 30 segundos.
Puedes calcular el terminationGracePeriod óptimo con la siguiente fórmula:
terminationGracePeriod >= preStop hook time + Pod shutdown time
Para definir terminationGracePeriod en la configuración del pod, haz lo siguiente:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
No se ha encontrado ningún NEG al crear un recurso Internal Ingress
Puede producirse el siguiente error al crear un Ingress interno en GKE:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
Este error se produce porque Ingress para balanceadores de carga de aplicaciones internos requiere grupos de puntos de conexión de red (NEGs) como backends.
En los entornos de VPC compartida o en los clústeres con políticas de red habilitadas, añade la anotación cloud.google.com/neg: '{"ingress": true}' al manifiesto de Service.
504 Gateway Timeout: tiempo de espera de la solicitud upstream agotado
Puede producirse el siguiente error al acceder a un servicio desde un Ingress interno en GKE:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
Este error se produce porque el tráfico enviado a los balanceadores de carga de aplicaciones internos se envía a través de proxies Envoy en el intervalo de subredes de solo proxy.
Para permitir el tráfico del intervalo de la subred de solo proxy, crea una regla de cortafuegos en el targetPort del servicio.
Error 400: Invalid value for field 'resource.target' (Valor no válido para el campo "resource.target")
Puede producirse el siguiente error al acceder a un servicio desde un Ingress interno en GKE:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
Para solucionar este problema, crea una subred de solo proxy.
Error durante la sincronización: error al ejecutar la rutina de sincronización del balanceador de carga: el balanceador de carga no existe
Puede producirse uno de los siguientes errores cuando se actualiza el plano de control de GKE o cuando se modifica un objeto Ingress:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
O:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
Para solucionar estos problemas, sigue estos pasos:
- Añade el campo
hostsen la seccióntlsdel manifiesto de Ingress y, a continuación, elimina el Ingress. Espera cinco minutos a que GKE elimine los recursos de Ingress no utilizados. A continuación, vuelve a crear el Ingress. Para obtener más información, consulta El campo hosts de un objeto Ingress. - Deshace los cambios que hayas hecho en el Ingress. A continuación, añade un certificado mediante una anotación o un secreto de Kubernetes.
Ingress externo genera errores HTTP 502
Sigue estas instrucciones para solucionar los errores HTTP 502 con recursos de Ingress externos:
- Habilita los registros de cada servicio de backend asociado a cada servicio de GKE al que haga referencia el Ingress.
- Usa los detalles del estado para identificar las causas de las respuestas HTTP 502. Los detalles de estado que indican que la respuesta HTTP 502 procede del backend requieren que se resuelvan los problemas en los pods de servicio, no en el balanceador de carga.
Grupos de instancias sin gestionar
Es posible que se produzcan errores HTTP 502 con recursos Ingress externos si tu Ingress externo usa back-ends de grupos de instancias no gestionados. Este problema se produce cuando se cumplen todas las condiciones siguientes:
- El clúster tiene un número total de nodos elevado entre todos los grupos de nodos.
- Los pods de servicio de uno o varios servicios a los que hace referencia el Ingress se encuentran en solo unos pocos nodos.
- Los servicios a los que hace referencia el Ingress usan
externalTrafficPolicy: Local.
Para determinar si tu Ingress externo usa back-ends de grupos de instancias no gestionados, haz lo siguiente:
Ve a la página Entrada de la Google Cloud consola.
Haz clic en el nombre de tu Ingress externo.
Haz clic en el nombre del balanceador de carga. Se muestra la página Detalles del balanceo de carga.
Consulta la tabla de la sección Servicios de backend para determinar si tu Ingress externo usa NEGs o grupos de instancias.
Para solucionar este problema, utiliza una de las siguientes soluciones:
- Usa un clúster nativo de VPC.
- Usa
externalTrafficPolicy: Clusterpara cada servicio al que haga referencia el Ingress externo. Con esta solución, se pierde la dirección IP del cliente original en los orígenes del paquete. - Usa la anotación
node.kubernetes.io/exclude-from-external-load-balancers=true. Añade la anotación a los nodos o grupos de nodos que no ejecuten ningún pod de servicio para ningún servicio al que haga referencia ningún Ingress externo oLoadBalancerservicio de tu clúster.
Usar registros de balanceadores de carga para solucionar problemas
Puedes usar los registros de balanceadores de carga de red de paso a través internos y los registros de balanceadores de carga de red de paso a través externos para solucionar problemas con los balanceadores de carga y correlacionar el tráfico de los balanceadores de carga con los recursos de GKE.
Los registros se agregan por conexión y se exportan casi en tiempo real. Se generan registros para cada nodo de GKE que participa en la ruta de datos de un servicio LoadBalancer, tanto para el tráfico de entrada como para el de salida. Las entradas de registro incluyen campos adicionales para los recursos de GKE, como los siguientes:
- Nombre del clúster
- Ubicación del clúster
- Nombre del servicio
- Espacio de nombres del servicio
- Nombre del pod
- Espacio de nombres de pod
Precios
No se aplican cargos adicionales por usar los registros. En función de cómo ingieras los registros, se aplicarán los precios estándar de Cloud Logging, BigQuery o Pub/Sub. Habilitar los registros no afecta al rendimiento del balanceador de carga.
Usar herramientas de diagnóstico para solucionar problemas
La herramienta de diagnóstico check-gke-ingress inspecciona los recursos de entrada para detectar errores de configuración habituales. Puedes usar la herramienta check-gke-ingress de las siguientes formas:
- Ejecuta la
gcpdiagherramienta de línea de comandos en tu clúster. Los resultados de entrada aparecen en la seccióngke/ERR/2023_004de comprobación de reglas. - Usa la herramienta
check-gke-ingresssola o como complemento de kubectl siguiendo las instrucciones de check-gke-ingress.
Siguientes pasos
Si no encuentras una solución a tu problema en la documentación, consulta la sección Obtener asistencia para obtener más ayuda, incluidos consejos sobre los siguientes temas:
- Abrir un caso de asistencia poniéndose en contacto con el equipo de Atención al Cliente de Cloud.
- Obtener asistencia de la comunidad haciendo preguntas en Stack Overflow
y usando la etiqueta
google-kubernetes-enginepara buscar problemas similares. También puedes unirte al#kubernetes-enginecanal de Slack para obtener más ayuda de la comunidad. - Abrir errores o solicitudes de funciones mediante el seguimiento de problemas público.