Questa pagina mostra come risolvere i problemi relativi al bilanciamento del carico nei cluster Google Kubernetes Engine (GKE) utilizzando risorse Service, Ingress o Gateway.
BackendConfig non trovato
Questo errore si verifica quando viene specificato un BackendConfig per una porta di servizio nell'annotazione di servizio, ma non è stato possibile trovare la risorsa BackendConfig effettiva.
Per valutare un evento Kubernetes, esegui questo comando:
kubectl get event
Il seguente output di esempio indica che BackendConfig non è stato trovato:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
Per risolvere il problema, assicurati di non aver creato la risorsa BackendConfig nello spazio dei nomi errato o di non aver digitato in modo errato il riferimento nell'annotazione di servizio.
Policy di sicurezza in entrata non trovata
Dopo aver creato l'oggetto Ingress, se la norma di sicurezza non è associata correttamente al servizio LoadBalancer, valuta l'evento Kubernetes per verificare se è presente un errore di configurazione. Se BackendConfig specifica un criterio di sicurezza inesistente, viene generato periodicamente un evento di avviso.
Per valutare un evento Kubernetes, esegui questo comando:
kubectl get event
Il seguente output di esempio indica che il criterio di sicurezza non è stato trovato:
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
Per risolvere il problema, specifica il nome corretto della norma di sicurezza in BackendConfig.
Risoluzione degli errori della serie 500 con i NEG durante lo scaling dei workload in GKE
Sintomo:
Quando utilizzi i NEG di GKE di cui è stato eseguito il provisioning per il bilanciamento del carico, potresti riscontrare errori 502 o 503 per i servizi durante lafare lo scale downe del workload. Gli errori 502 si verificano quando i pod vengono terminati prima della chiusura delle connessioni esistenti, mentre gli errori 503 si verificano quando il traffico viene indirizzato ai pod eliminati.
Questo problema può interessare i cluster se utilizzi prodotti di bilanciamento del carico gestito da GKE che utilizzano i NEG, tra cui Gateway, Ingress e NEG autonomi. Se esegui spesso lo scale dei carichi di lavoro, il rischio che il cluster venga interessato è maggiore.
Diagnosi:
La rimozione di un pod in Kubernetes senza svuotare il relativo endpoint e rimuoverlo dal
NEG prima comporta errori della serie 500. Per evitare problemi durante l'interruzione del pod, devi considerare l'ordine delle operazioni. Le seguenti immagini
mostrano gli scenari quando BackendService Drain Timeout non è impostato e
BackendService Drain Timeout è impostato con BackendConfig.
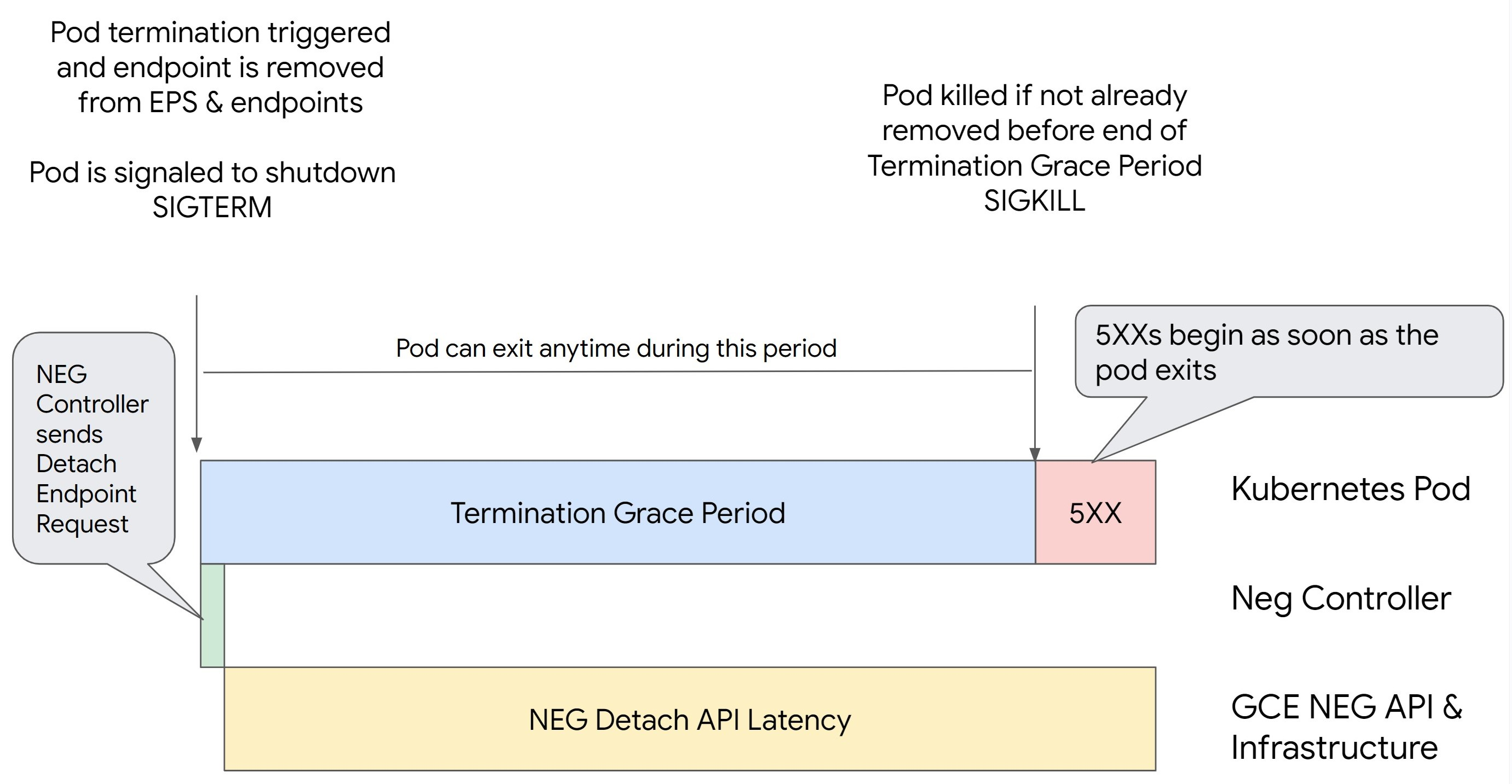
Scenario 1: BackendService Drain Timeout non è impostato.
L'immagine seguente mostra uno scenario in cui BackendService Drain Timeout non è
impostato.
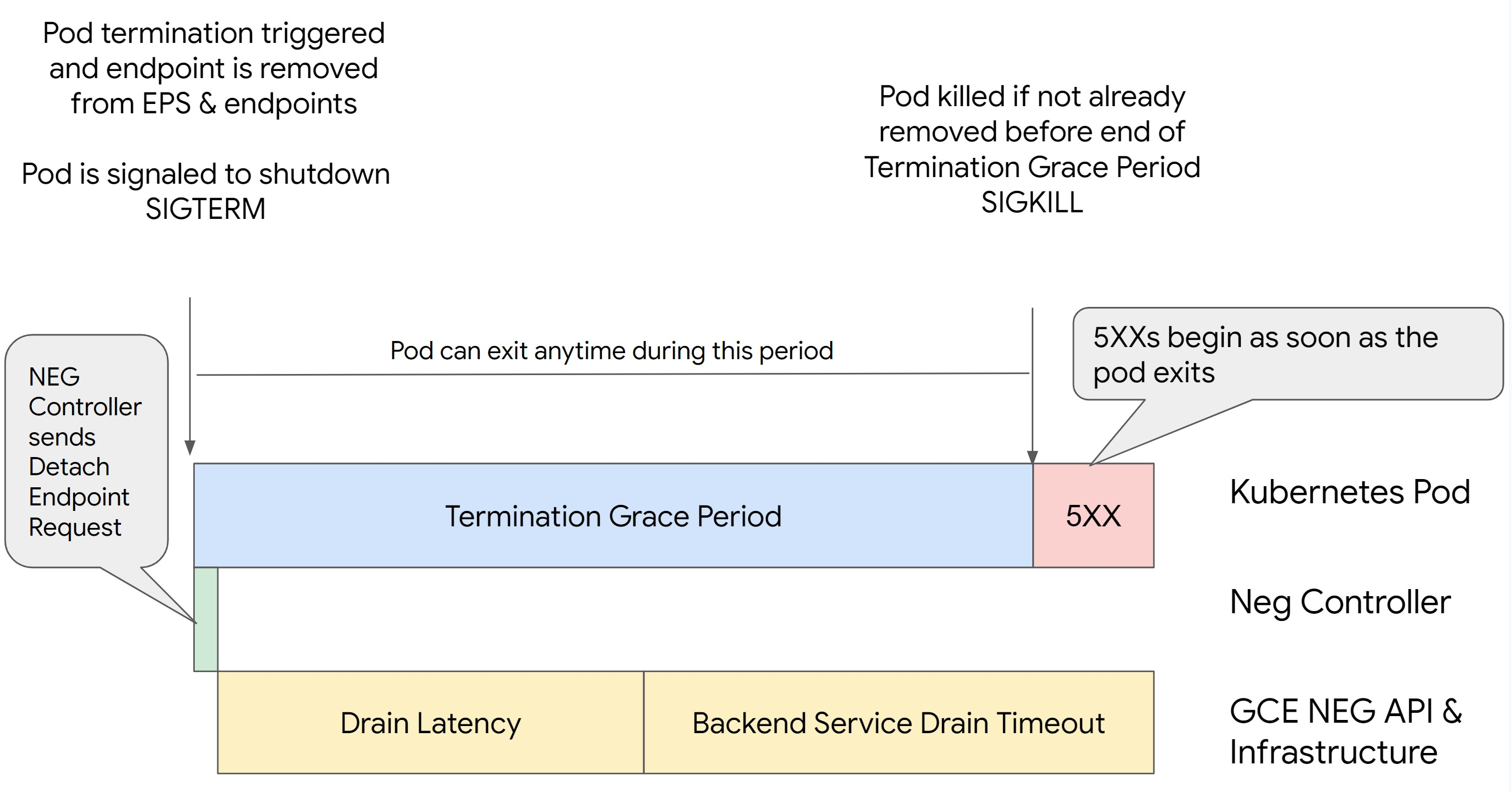
Scenario 2: BackendService Drain Timeout è impostato.
L'immagine seguente mostra uno scenario in cui è impostato BackendService Drain Timeout.
Il momento esatto in cui si verificano gli errori della serie 500 dipende dai seguenti fattori:
Latenza di distacco dell'API NEG: la latenza di distacco dell'API NEG rappresenta il tempo attuale impiegato per finalizzare l'operazione di distacco in Google Cloud. Questo è influenzato da una serie di fattori esterni a Kubernetes, tra cui il tipo di bilanciatore del carico e la zona specifica.
Latenza di svuotamento: la latenza di svuotamento è il tempo impiegato dal bilanciatore del carico per iniziare a reindirizzare il traffico lontano da una particolare parte del sistema. Dopo l'avvio dello svuotamento, il bilanciatore del carico smette di inviare nuove richieste all'endpoint, ma esiste ancora una latenza nell'attivazione dello svuotamento (latenza di svuotamento) che può causare errori 503 temporanei se il pod non esiste più.
Configurazione del controllo di integrità: soglie di controllo di integrità più sensibili riducono la durata degli errori 503, in quanto possono segnalare al bilanciatore del carico di interrompere l'invio di richieste agli endpoint anche se l'operazione di distacco non è terminata.
Periodo di tolleranza per l'interruzione: il periodo di tolleranza per l'interruzione determina il tempo massimo concesso a un pod per uscire. Tuttavia, un pod può uscire prima del completamento del periodo di tolleranza prima di arrestarsi. Se un pod impiega più tempo di questo periodo, viene forzato a uscire al termine del periodo. Si tratta di un'impostazione del pod e deve essere configurata nella definizione del workload.
Potenziale soluzione:
Per evitare questi errori 5XX, applica le seguenti impostazioni. I valori di timeout sono indicativi e potresti doverli modificare per la tua applicazione specifica. La sezione seguente illustra la procedura di personalizzazione.
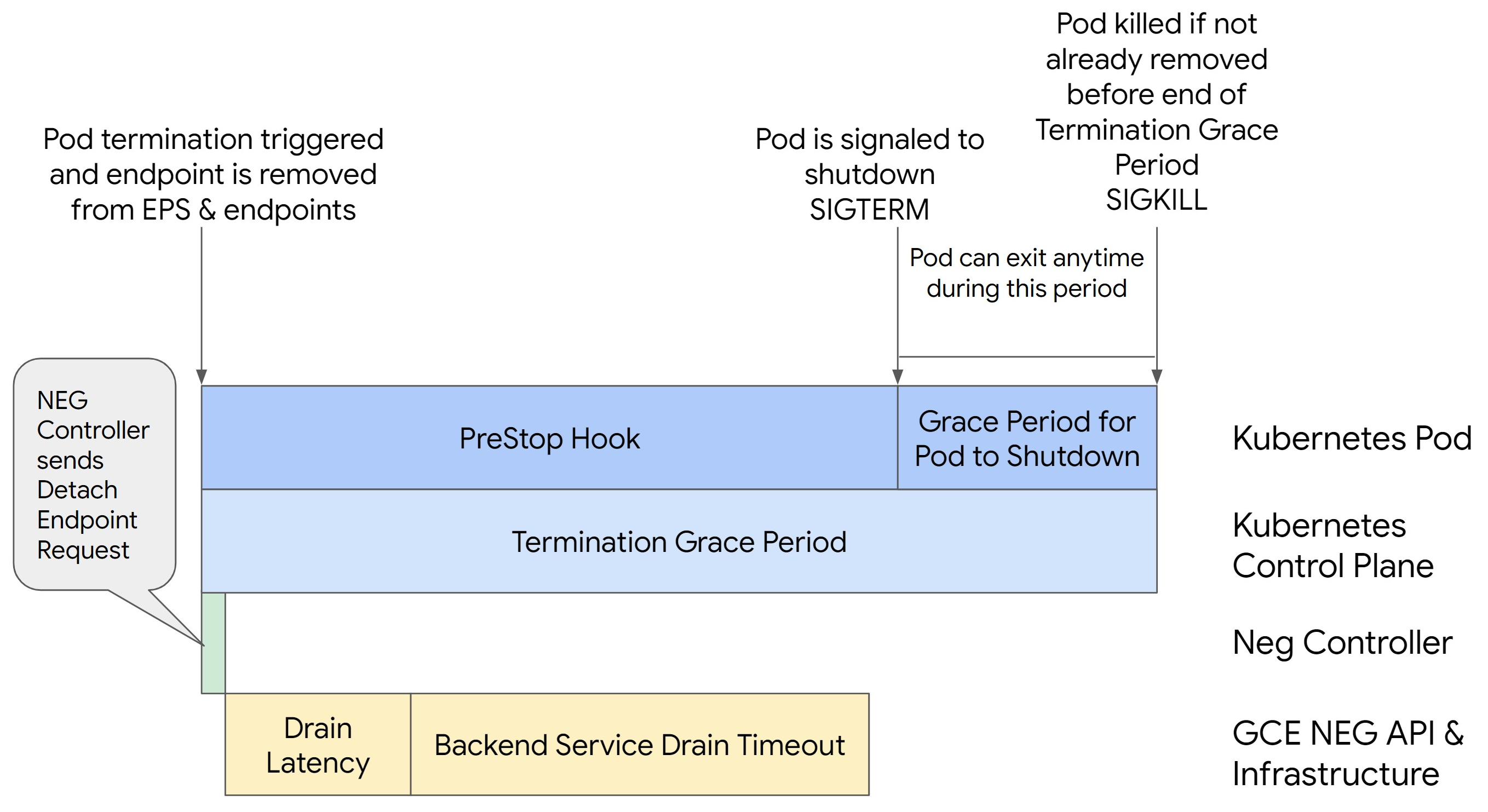
La seguente immagine mostra come mantenere attivo il pod con un gancio preStop:
Per evitare errori della serie 500, segui questi passaggi:
Imposta il
BackendService Drain Timeoutper il tuo servizio su 1 minuto.Per gli utenti Ingress, vedi impostare il timeout su BackendConfig.
Per gli utenti del gateway, vedi configurare il timeout in GCPBackendPolicy.
Per chi gestisce direttamente i propri BackendService quando utilizza i NEG autonomi, consulta Impostare il timeout direttamente sul servizio di backend.
Estendi
terminationGracePeriodsul pod.Imposta
terminationGracePeriodSecondssul pod su 3,5 minuti. Se combinata con le impostazioni consigliate, questa opzione consente ai pod di avere una finestra di 30-45 secondi per un arresto normale dopo che l'endpoint del pod è stato rimosso dal NEG. Se hai bisogno di più tempo per l'arresto normale, puoi estendere il periodo di tolleranza o seguire le istruzioni riportate nella sezione Personalizzare i timeout.Il seguente manifest del pod specifica un timeout per svuotamento della connessione di 210 secondi (3,5 minuti):
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...Applica un hook
preStopa tutti i contenitori.Applica un hook
preStopche garantisca che il pod rimanga attivo per 120 secondi in più mentre l'endpoint del pod viene svuotato nel bilanciatore del carico e l'endpoint viene rimosso dal NEG.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
Personalizzare i timeout
Per garantire la continuità del pod ed evitare errori della serie 500, il pod deve essere attivo
finché l'endpoint non viene rimosso dal NEG. Nello specifico, per evitare errori 502 e 503, valuta la possibilità di implementare una combinazione di timeout e un hook preStop.
Per mantenere il pod attivo più a lungo durante la procedura di spegnimento, aggiungi un hook preStop
al pod. Esegui l'hook preStop prima che a un pod venga segnalato di uscire, in modo che
l'hook preStop possa essere utilizzato per mantenere attivo il pod finché il relativo
endpoint non viene rimosso dal NEG.
Per estendere la durata di attività di un pod durante la procedura di arresto,
inserisci un hook preStop nella configurazione del pod nel seguente modo:
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
Puoi configurare i timeout e le impostazioni correlate per gestire l'arresto controllato
dei pod durante la riduzione dei carichi di lavoro. Puoi modificare i timeout in base a casi d'uso specifici. Ti consigliamo di iniziare con timeout più lunghi e ridurre la durata in base alle necessità. Puoi personalizzare i timeout configurando
i parametri correlati al timeout e l'hook preStop nei seguenti modi:
Timeout di svuotamento del servizio di backend
Il parametro Backend Service Drain Timeout non è impostato per impostazione predefinita e non ha
alcun effetto. Se imposti il parametro Backend Service Drain Timeout e lo attivi, il bilanciatore del carico interrompe l'instradamento di nuove richieste all'endpoint e attende
il timeout prima di terminare le connessioni esistenti.
Puoi impostare il parametro Backend Service Drain Timeout utilizzando
BackendConfig con Ingress, GCPBackendPolicy con Gateway o manualmente su
BackendService con NEG autonomi. Il timeout deve essere da 1,5 a 2 volte
più lungo del tempo necessario per elaborare una richiesta. In questo modo, se una richiesta
è arrivata subito prima dell'avvio dello svuotamento, verrà completata prima
del completamento del timeout. L'impostazione del parametro Backend Service Drain Timeout su un valore maggiore di 0 contribuisce a ridurre gli errori 503 perché non vengono inviate nuove richieste agli endpoint la cui rimozione è pianificata. Affinché questo timeout sia efficace, devi
utilizzarlo con l'hook preStop per garantire che il pod rimanga
attivo durante lo scaricamento. Senza questa combinazione, le richieste esistenti che
non sono state completate riceveranno un errore 502.
preStop hook time
L'hook preStop deve ritardare l'arresto del pod sufficientemente per consentire il completamento sia della latenza di svuotamento sia del timeout di svuotamento del servizio di backend, garantendo lo svuotamento corretto della connessione e la rimozione dell'endpoint dal NEG prima dell'arresto del pod.
Per risultati ottimali, assicurati che il tempo di esecuzione dell'hook preStop sia maggiore o uguale alla somma della latenza di Backend Service Drain Timeout e di scaricamento.
Calcola il tempo di esecuzione ideale dell'hook preStop con la seguente formula:
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
Sostituisci quanto segue:
BACKEND_SERVICE_DRAIN_TIMEOUT: l'ora che hai configurato perBackend Service Drain Timeout.DRAIN_LATENCY: un tempo stimato per la latenza di svuotamento. Ti consigliamo di utilizzare un minuto come stima.
Se gli errori 500 persistono, stima la durata totale dell'occorrenza e aggiungi il doppio di questo tempo alla latenza di svuotamento stimata. In questo modo, il Pod ha abbastanza tempo per scaricarsi gradualmente prima di essere rimosso dal servizio. Puoi modificare questo valore se è troppo lungo per il tuo caso d'uso specifico.
In alternativa, puoi stimare la tempistica esaminando il timestamp dell'eliminazione dal pod e il timestamp in cui l'endpoint è stato rimosso dal NEG neCloud Audit Logsud.
Parametro Periodo di tolleranza per la risoluzione
Devi configurare il parametro terminationGracePeriod per consentire un tempo sufficiente
per il completamento dell'hook preStop e per il completamento di un arresto controllato
del pod.
Per impostazione predefinita, se non viene impostato esplicitamente, il valore di terminationGracePeriod è 30 secondi.
Puoi calcolare il terminationGracePeriod ottimale utilizzando la formula:
terminationGracePeriod >= preStop hook time + Pod shutdown time
Per definire terminationGracePeriod all'interno della configurazione del pod nel seguente modo:
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
NEG non trovato durante la creazione di una risorsa Ingress interno
Quando crei un Ingress interno in GKE, potrebbe verificarsi il seguente errore:
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
Questo errore si verifica perché Ingress per i bilanciatori del carico delle applicazioni interni richiede gruppi di endpoint di rete (NEG) come backend.
Negli ambienti VPC condiviso o nei cluster con i criteri di rete abilitati,
aggiungi l'annotazione cloud.google.com/neg: '{"ingress": true}' al manifest del servizio.
504 Gateway Timeout: timeout della richiesta upstream
Quando accedi a un servizio da un Ingress interno in GKE, potrebbe verificarsi il seguente errore:
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
Questo errore si verifica perché il traffico inviato ai bilanciatori del carico delle applicazioni interni viene sottoposto a proxy dai proxy Envoy nell'intervallo di subnet solo proxy.
Per consentire il traffico dall'intervallo di subnet solo proxy,
crea una regola firewall
sul targetPort del servizio.
Errore 400: valore non valido per il campo "resource.target"
Quando accedi a un servizio da un Ingress interno in GKE, potrebbe verificarsi il seguente errore:
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
Per risolvere il problema, crea una subnet solo proxy.
Errore durante la sincronizzazione: errore durante l'esecuzione della routine di sincronizzazione del bilanciatore del carico: il bilanciatore del carico non esiste
Quando viene eseguito l'upgrade del control plane GKE o quando modifichi un oggetto Ingress, potrebbe verificarsi uno dei seguenti errori:
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
Oppure:
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
Per risolvere questi problemi, prova i seguenti passaggi:
- Aggiungi il campo
hostsnella sezionetlsdel manifest Ingress, poi elimina Ingress. Attendi cinque minuti affinché GKE elimini le risorse Ingress inutilizzate. Quindi, ricrea l'ingresso. Per maggiori informazioni, vedi Il campo hosts di un oggetto Ingress. - Ripristina le modifiche apportate all'Ingress. A questo punto, aggiungi un certificato utilizzando un'annotazione o un secret Kubernetes.
Ingress esterno genera errori HTTP 502
Utilizza le seguenti indicazioni per risolvere i problemi relativi agli errori HTTP 502 con le risorse Ingress esterne:
- Attiva i log per ogni servizio di backend associato a ogni servizio GKE a cui fa riferimento Ingress.
- Utilizza i dettagli dello stato per identificare le cause delle risposte HTTP 502. I dettagli dello stato che indicano che la risposta HTTP 502 ha avuto origine dal backend richiedono la risoluzione dei problemi all'interno dei pod di pubblicazione, non del bilanciatore del carico.
Gruppi di istanze non gestite
Potresti riscontrare errori HTTP 502 con le risorse Ingress esterne se Ingress esterno utilizza backend di gruppi di istanze non gestiti. Questo problema si verifica quando sono soddisfatte tutte le seguenti condizioni:
- Il cluster ha un numero totale elevato di nodi in tutti i node pool.
- I pod di pubblicazione per uno o più servizi a cui fa riferimento Ingress si trovano solo su alcuni nodi.
- Servizi a cui fa riferimento l'utilizzo di Ingress
externalTrafficPolicy: Local.
Per determinare se il tuo Ingress esterno utilizza backend di gruppi di istanze non gestite, svolgi i seguenti passaggi:
Vai alla pagina Ingress nella console Google Cloud .
Fai clic sul nome dell'ingresso esterno.
Fai clic sul nome del bilanciatore del carico. Viene visualizzata la pagina Dettagli bilanciamento del carico.
Controlla la tabella nella sezione Servizi di backend per determinare se il tuo ingress esterno utilizza NEG o gruppi di istanze.
Per risolvere il problema, utilizza una delle seguenti soluzioni:
- Utilizza un cluster nativo di VPC.
- Utilizza
externalTrafficPolicy: Clusterper ogni servizio a cui fa riferimento l'ingresso esterno. Questa soluzione comporta la perdita dell'indirizzo IP client originale nelle origini del pacchetto. - Utilizza l'annotazione
node.kubernetes.io/exclude-from-external-load-balancers=true. Aggiungi l'annotazione ai nodi o ai pool di nodi che non eseguono alcun pod di servizio per qualsiasi servizio a cui fa riferimento qualsiasi Ingress esterno o servizioLoadBalancernel tuo cluster.
Utilizzare i log del bilanciamento del carico per risolvere i problemi
Puoi utilizzare i log del bilanciatore del carico di rete passthrough interno e i log del bilanciatore del carico di rete passthrough esterno per risolvere i problemi relativi ai bilanciatori del carico e correlare il traffico dai bilanciatori del carico alle risorse GKE.
I log vengono aggregati per connessione ed esportati quasi in tempo reale. I log vengono generati per ogni nodo GKE coinvolto nel percorso dei dati di un servizio LoadBalancer, sia per il traffico in entrata che in uscita. Le voci di log includono campi aggiuntivi per le risorse GKE, ad esempio:
- Nome del cluster
- Località del cluster
- Nome servizio
- Spazio dei nomi del servizio
- Nome pod
- Spazio dei nomi pod
Prezzi
Non vengono addebitati costi aggiuntivi per l'utilizzo dei log. A seconda di come importi i log, si applicano prezzi standard per Cloud Logging, BigQuery o Pub/Sub. L'attivazione dei log non influisce sul rendimento del bilanciatore del carico.
Utilizzare gli strumenti di diagnostica per risolvere i problemi
Lo strumento di diagnostica check-gke-ingress esamina le risorse Ingress per individuare configurazioni errate comuni. Puoi utilizzare lo strumento check-gke-ingress nei seguenti modi:
- Esegui lo
strumento a riga di comando
gcpdiagsul tuo cluster. I risultati dell'ingresso vengono visualizzati nella sezionegke/ERR/2023_004della regola di controllo. - Utilizza lo strumento
check-gke-ingressda solo o come plug-in kubectl seguendo le istruzioni riportate in check-gke-ingress.
Passaggi successivi
Se non riesci a trovare una soluzione al tuo problema nella documentazione, consulta la sezione Richiedere assistenza per ulteriore aiuto, inclusi consigli sui seguenti argomenti:
- Aprire una richiesta di assistenza contattando l'assistenza clienti cloud.
- Ricevere assistenza dalla community
ponendo domande su StackOverflow e utilizzando il tag
google-kubernetes-engineper cercare problemi simili. Puoi anche unirti al canale Slack#kubernetes-engineper ulteriore assistenza della community. - Apertura di bug o richieste di funzionalità utilizzando lo strumento di monitoraggio dei problemi pubblico.