Google Kubernetes Engine(GKE)의 부하 분산 문제로 인해 HTTP 502 오류와 같은 서비스 중단이 발생하거나 애플리케이션에 대한 액세스가 차단될 수 있습니다.
이 문서를 사용하여 외부 인그레스의 502 오류를 해결하는 방법과 부하 분산기 로그 및 check-gke-ingress와 같은 진단 도구를 사용하여 문제를 식별하는 방법을 알아보세요.
이 정보는 GKE에서 부하 분산 서비스를 구성하고 유지보수하는 플랫폼 관리자, 운영자, 애플리케이션 개발자에게 중요합니다. Google Cloud 콘텐츠에서 참조하는 일반적인 역할과 예시 태스크에 대한 자세한 내용은 일반 GKE 사용자 역할 및 태스크를 참조하세요.
BackendConfig를 찾을 수 없음
이 오류는 서비스 포트의 BackendConfig가 서비스 주석에 지정되었지만 실제 BackendConfig 리소스를 찾을 수 없을 때 발생합니다.
Kubernetes 이벤트를 평가하려면 다음 명령어를 실행합니다.
kubectl get event
다음 출력 예시는 BackendConfig를 찾을 수 없음을 나타냅니다.
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
이 문제를 해결하려면 잘못된 네임스페이스에 BackendConfig 리소스를 생성하지 않았거나 서비스 주석에서 참조 철자를 잘못 쓰지 않았는지 확인합니다.
인그레스 보안 정책을 찾을 수 없음
인그레스 객체가 생성된 다음 보안 정책이 LoadBalancer 서비스와 올바르게 연결되지 않은 경우, Kubernetes 이벤트에서 구성 실수가 있는지 확인합니다. BackendConfig에 존재하지 않는 정책이 지정되면 경고 이벤트가 주기적으로 발생합니다.
Kubernetes 이벤트를 평가하려면 다음 명령어를 실행합니다.
kubectl get event
다음 출력 예시는 보안 정책을 찾을 수 없음을 나타냅니다.
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
이 문제를 해결하려면 BackendConfig에서 올바른 보안 정책 이름을 지정합니다.
GKE에서 워크로드 확장 중에 NEG로 500 시리즈 오류 해결
증상:
부하 분산에 GKE 프로비저닝 NEG를 사용하면 워크로드 축소 중에 서비스에 502 또는 503 오류가 발생할 수 있습니다. 기존 연결이 종료되기 전에 포드가 종료되면 502 오류가 발생하고 트래픽이 삭제된 포드로 전달되면 503 오류가 발생합니다.
이 문제는 게이트웨이, 인그레스, 독립형 NEG를 포함하여 NEG를 사용하는 GKE 관리형 부하 분산 제품을 사용하는 경우 클러스터에 영향을 줄 수 있습니다. 워크로드를 자주 확장하면 클러스터가 영향을 받을 위험이 커집니다.
진단:
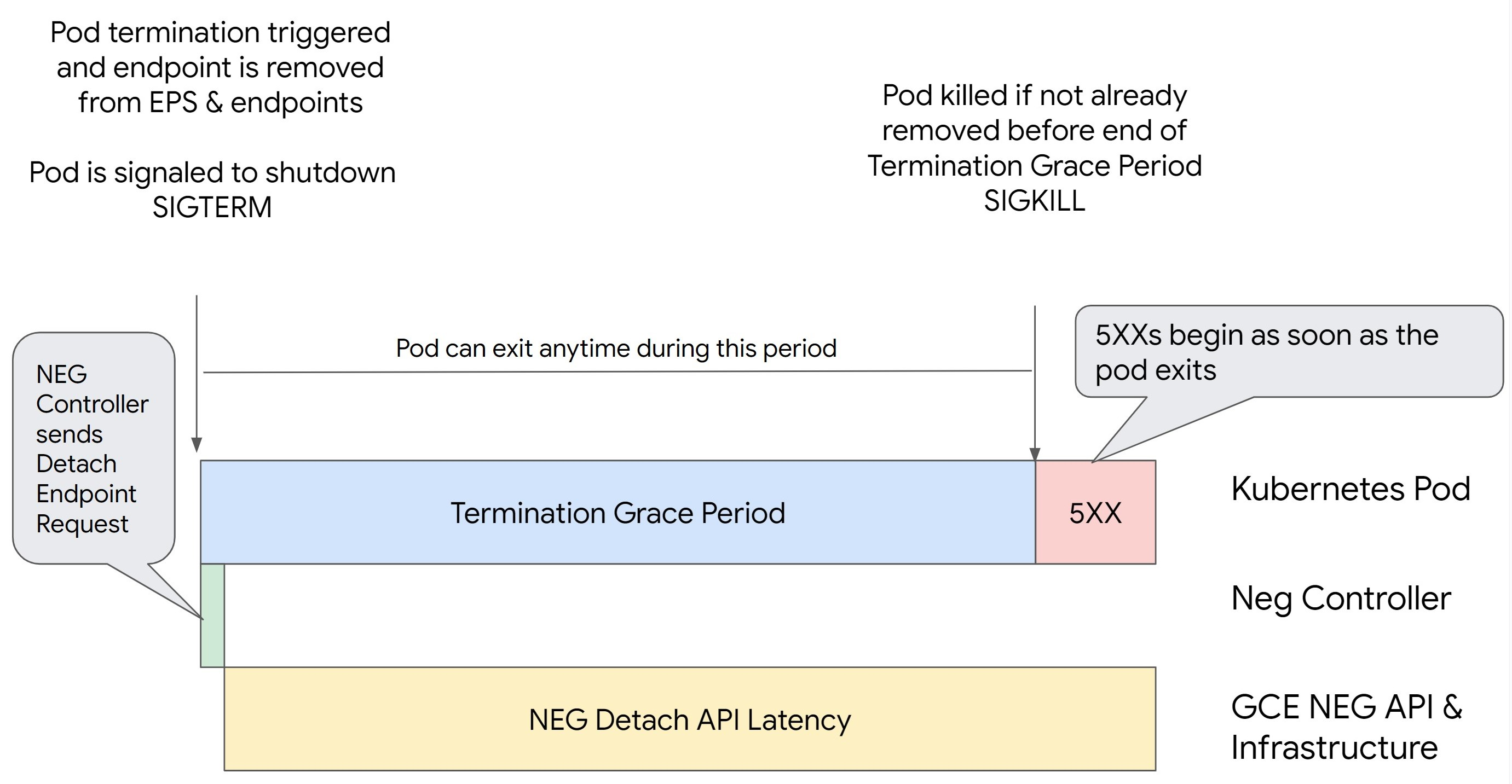
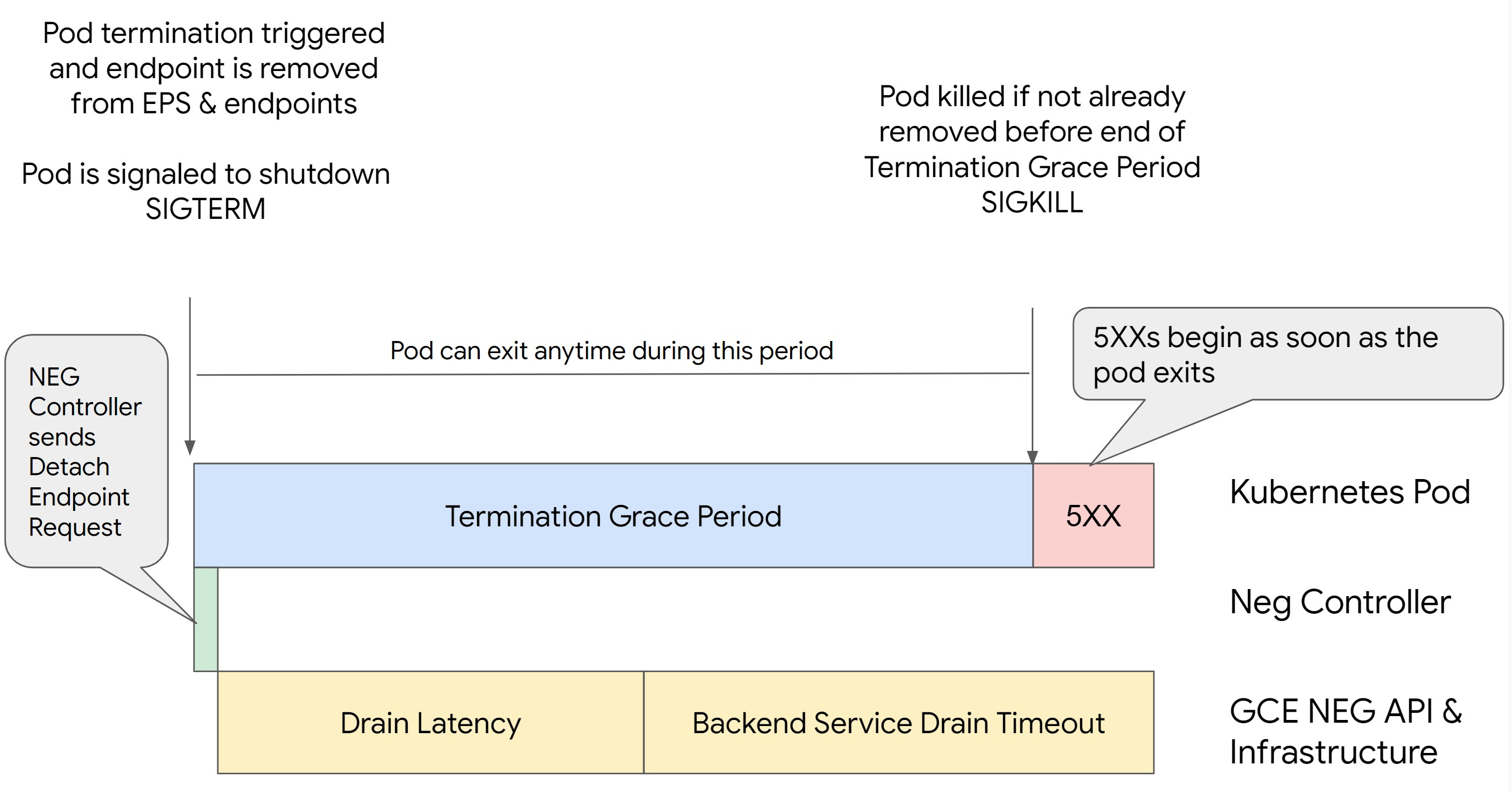
엔드포인트를 드레이닝하지 않고 Kubernetes에서 포드를 삭제하고 먼저 NEG에서 제거하면 500 시리즈 오류가 발생합니다. 포드 종료 중에 문제가 발생하지 않도록 하려면 작업 순서를 고려해야 합니다. 다음 이미지에서는 BackendService Drain Timeout이 설정되지 않았을 때와 BackendConfig를 사용하여 BackendService Drain Timeout이 설정되었을 때의 시나리오를 보여줍니다.
시나리오 1: BackendService Drain Timeout이 설정되지 않음
다음 이미지는 BackendService Drain Timeout이 설정되지 않은 시나리오를 보여줍니다.
시나리오 2: BackendService Drain Timeout이 설정됨
다음 이미지는 BackendService Drain Timeout이 설정된 시나리오를 보여줍니다.
500 시리즈 오류가 발생하는 정확한 시간은 다음 요인에 따라 달라집니다.
NEG API 분리 지연 시간: NEG API 분리 지연 시간은 Google Cloud에서 분리 작업이 완료되는 데 걸리는 현재 시간을 나타냅니다. 이는 부하 분산기 유형 및 특정 영역 등 Kubernetes 외부의 다양한 요인에 영향을 받습니다.
드레이닝 지연 시간: 드레이닝 지연 시간은 부하 분산기가 시스템의 특정 부분에서 트래픽을 다른 곳으로 전달하기 시작하는 데 걸리는 시간입니다. 드레이닝이 시작되면 부하 분산기에서 엔드포인트에 새 요청을 더 이상 전송하지 않지만 드레이닝 트리거에 대한 지연 시간(드레이닝 지연 시간)이 계속 있습니다. 이로 인해 포드가 더 이상 존재하지 않으면 임시 503 오류가 발생할 수 있습니다.
상태 점검 구성: 분리 작업이 완료되지 않더라도 부하 분산기가 엔드포인트에 요청 전송을 중지하도록 신호를 보낼 수 있으므로 보다 민감한 상태 점검 임곗값은 503 오류 기간을 완화합니다.
종료 유예 기간: 종료 유예 기간은 포드가 종료되기까지 주어지는 최대 시간을 결정합니다. 하지만 종료 유예 기간이 완료되기 전에 포드가 종료될 수 있습니다. 포드가 이 기간보다 오래 걸리면 이 기간이 끝날 때 포드가 강제로 종료됩니다. 이는 포드의 설정이며 워크로드 정의에서 구성해야 합니다.
잠재적인 해결 방법:
이러한 5XX 오류를 방지하려면 다음 설정을 적용하세요. 제한 시간 값은 제안적이며, 특정 애플리케이션에 맞게 조정해야 할 수도 있습니다. 다음 섹션에서는 맞춤설정 프로세스를 안내합니다.
다음 이미지에서는 preStop 후크를 사용하여 포드를 활성 상태로 유지하는 방법을 보여줍니다.
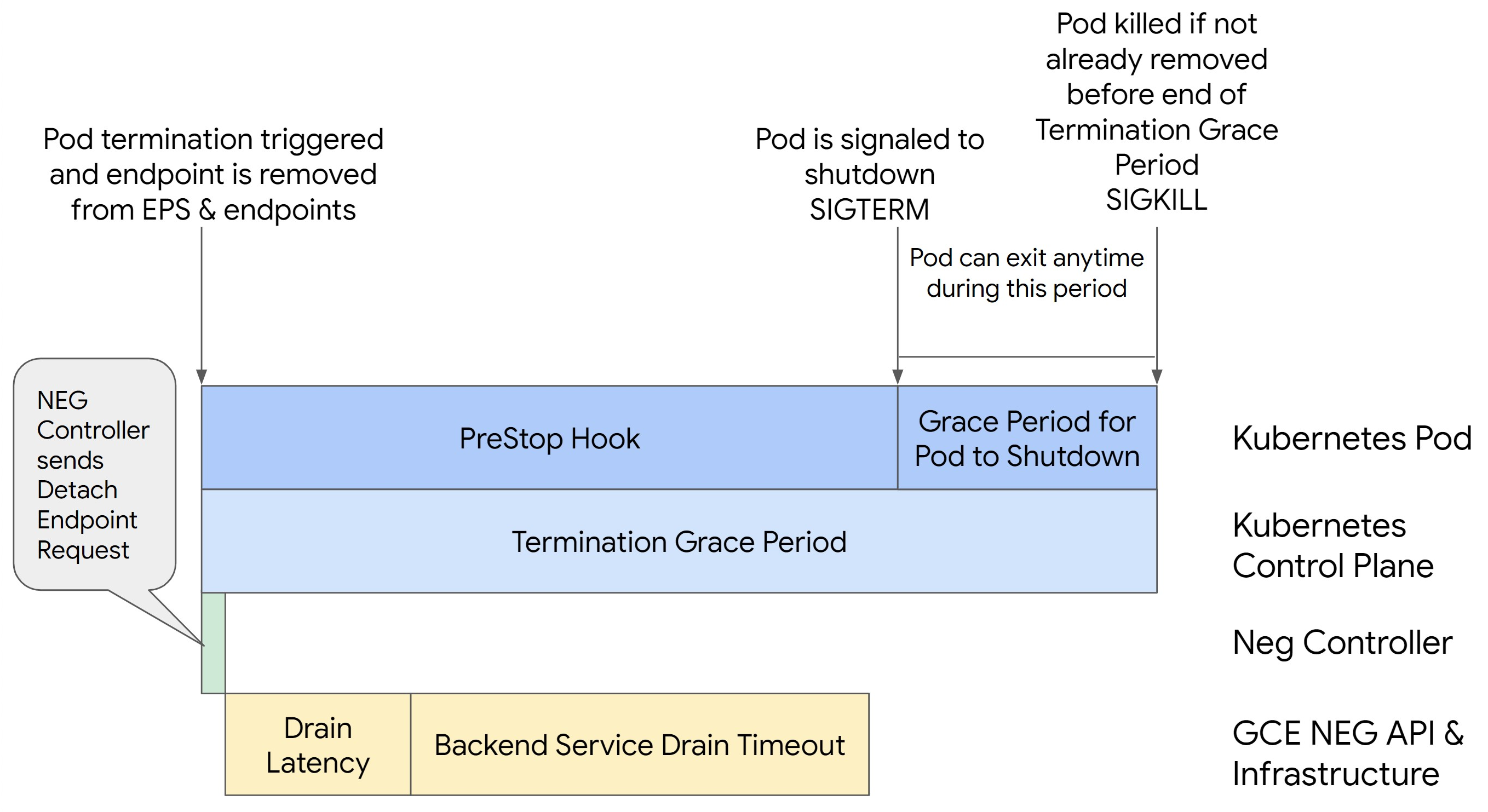
500 시리즈 오류를 방지하려면 다음 단계를 수행합니다.
서비스의
BackendService Drain Timeout을 1분으로 설정합니다.인그레스 사용자는 BackendConfig에서 제한 시간 설정을 참조하세요.
게이트웨이 사용자는 GCPBackendPolicy에서 제한 시간 구성을 참조하세요.
독립형 NEG를 사용할 때 직접 BackendServices를 관리하는 사용자는 백엔드 서비스에서 직접 제한 시간 설정을 참조하세요.
포드에서
terminationGracePeriod를 확장합니다.포드의
terminationGracePeriodSeconds를 3.5분으로 설정합니다. 권장 설정과 함께 사용하면 포드의 엔드포인트가 NEG에서 삭제된 후 포드가 30~45초 동안 단계적으로 종료되도록 합니다. 단계적 종료에 더 많은 시간이 필요한 경우 유예 기간을 연장하거나 제한 시간 맞춤설정 섹션에 설명된 안내를 따를 수 있습니다.다음 포드 매니페스트는 연결 드레이닝 제한 시간을 210초(3.5분)로 지정합니다.
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...preStop후크를 모든 컨테이너에 적용합니다.포드의 엔드포인트가 부하 분산기에서 드레이닝되고 엔드포인트가 NEG에서 삭제되는 동안
preStop후크를 적용합니다. 그러면 포드가 120초 동안 활성 상태로 유지됩니다.spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
제한 시간 맞춤설정
포드 연속성을 보장하고 500 시리즈 오류를 방지하기 위해서는 NEG에서 엔드포인트가 삭제될 때까지 포드가 활성 상태여야 합니다. 특히 502 및 503 오류를 방지하려면 제한 시간과 preStop 후크의 조합을 구현하는 것이 좋습니다.
종료 프로세스 중 포드를 더 오래 활성 상태로 유지하려면 preStop 후크를 포드에 추가합니다. 포드가 종료 신호를 받기 전에 preStop 후크를 실행합니다. 그러면 preStop 후크를 사용하여 해당 엔드포인트가 NEG에서 삭제될 때까지 포드를 활성 상태로 유지할 수 있습니다.
종료 프로세스 중에 포드가 활성 상태로 유지되는 기간을 확장하려면 다음과 같이 preStop 후크를 포드 구성에 삽입합니다.
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
제한 시간 및 관련 설정을 구성하여 워크로드 축소 중에 포드의 단계적 종료를 관리할 수 있습니다. 특정 사용 사례에 따라 제한 시간을 조정할 수 있습니다. 더 긴 제한 시간으로 시작하고 필요에 따라 기간을 줄이는 것이 좋습니다. 다음과 같은 방법으로 제한 시간 관련 파라미터와 preStop 후크를 구성하여 제한 시간을 맞춤설정할 수 있습니다.
백엔드 서비스 드레이닝 제한 시간
Backend Service Drain Timeout 매개변수는 기본적으로 설정 해제되며 효과가 없습니다. Backend Service Drain Timeout 매개변수를 설정하고 활성화하면 부하 분산기가 엔드포인트에 대한 새 요청 라우팅을 중지하고 기존 연결을 종료하기 전에 제한 시간을 기다립니다.
인그레스와 함께 BackendConfig를 사용하고, 게이트웨이와 GCPBackendPolicy를 사용하거나 독립형 NEG와 함께 BackendService에서 수동으로 Backend Service Drain Timeout 매개변수를 설정할 수 있습니다. 제한 시간은 요청을 처리하는 데 걸리는 시간보다 1.5~2배 더 길어야 합니다. 이렇게 하면 드레이닝이 시작되기 직전에 요청이 수신되면 제한 시간이 끝나기 전에 완료됩니다. Backend Service Drain Timeout 파라미터를 0보다 큰 값으로 설정하면 새 요청이 삭제되도록 예약된 엔드포인트로 전송되지 않으므로 503 오류가 완화됩니다. 이 제한 시간을 적용하려면 드레이닝이 발생하는 동안 포드가 활성 상태를 유지하도록 preStop 후크와 함께 사용해야 합니다. 이 조합을 사용하지 않으면 완료되지 않은 기존 요청에 502 오류가 수신됩니다.
preStop 후크 시간
포드가 종료되기 전에 NEG에서 적절한 연결 드레이닝과 엔드포인트 삭제가 수행되도록 드레이닝 지연 시간과 백엔드 서비스 드레이닝 제한 시간 모두 완료될 때까지 preStop 후크에서 포드 종료를 충분히 지연시켜야 합니다.
최적의 결과를 얻으려면 preStop 후크 실행 시간이 Backend Service Drain Timeout 및 드레이닝 지연 시간의 합계보다 크거나 같아야 합니다.
다음 수식을 사용하여 이상적인 preStop 후크 실행 시간을 계산합니다.
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
다음을 바꿉니다.
BACKEND_SERVICE_DRAIN_TIMEOUT:Backend Service Drain Timeout에 구성된 시간입니다.DRAIN_LATENCY: 예상 드레인 지연 시간입니다. 예상 시간으로 1분을 사용하는 것이 좋습니다.
500 오류가 지속되면 총 발생 기간을 추정하고 해당 시간을 두 배로 예상 드레이닝 지연 시간에 추가합니다. 그러면 포드가 서비스에서 삭제되기 전에 정상적으로 드레이닝할 수 있는 충분한 시간이 확보됩니다. 특정 사용 사례에 너무 길면 이 값을 조정할 수 있습니다.
또는 포드의 삭제 타임스탬프와 Cloud 감사 로그의 NEG에서 엔드포인트가 삭제된 타임스탬프를 검사하여 타이밍을 예측할 수 있습니다.
종료 유예 기간 매개변수
preStop 후크가 완료되고 포드가 단계적 종료를 완료할 수 있는 충분한 시간이 확보되도록 terminationGracePeriod 파라미터를 구성해야 합니다.
기본적으로 terminationGracePeriod를 명시적으로 설정하지 않으면 30초입니다.
다음 수식을 사용하여 최적의 terminationGracePeriod를 계산할 수 있습니다.
terminationGracePeriod >= preStop hook time + Pod shutdown time
다음과 같이 포드 구성 내에서 terminationGracePeriod를 정의합니다.
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
내부 인그레스 리소스를 만들 때 NEG를 찾을 수 없음
GKE에서 내부 인그레스를 만들 때 다음 오류가 발생할 수 있습니다.
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
내부 애플리케이션 부하 분산기용 인그레스에 백엔드로 네트워크 엔드포인트 그룹(NEG)이 필요하기 때문에 이 오류가 발생합니다.
네트워크 정책이 사용 설정된 공유 VPC 환경 또는 클러스터에서 서비스 매니페스트에 cloud.google.com/neg: '{"ingress": true}' 주석을 추가합니다.
504 게이트웨이 시간 초과: 업스트림 요청 시간 제한
GKE의 내부 인그레스에서 서비스에 액세스할 때 다음 오류가 발생할 수 있습니다.
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
이 오류는 내부 애플리케이션 부하 분산기로 전송된 트래픽이 프록시 전용 서브넷 범위의 Envoy 프록시에서 프록시되기 때문에 발생합니다.
프록시 전용 서브넷 범위로부터 트래픽을 허용하려면 서비스의 targetPort에 방화벽 규칙을 만듭니다.
오류 400: 'resource.target' 필드 값이 잘못됨
GKE의 내부 인그레스에서 서비스에 액세스할 때 다음 오류가 발생할 수 있습니다.
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
이 문제를 해결하려면 프록시 전용 서브넷을 생성합니다.
동기화 중 오류: 부하 분산기 동기화 루틴 실행 중 오류: loadbalancer가 존재하지 않음
GKE 제어 영역이 업그레이드되거나 인그레스 객체를 수정할 때 다음 오류 중 하나가 발생할 수 있습니다.
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
또는
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
이 문제를 해결하려면 다음 단계를 시도해 보세요.
- 인그레스 매니페스트의
tls섹션에hosts필드를 추가한 후 인그레스를 삭제합니다. GKE가 사용되지 않는 인그레스 리소스를 삭제할 때까지 5분 정도 기다립니다. 그런 다음 인그레스를 다시 만듭니다. 자세한 내용은 인그레스 객체의 호스트 필드를 참조하세요. - 인그레스의 변경사항을 되돌립니다. 그런 다음 주석 또는 Kubernetes 보안 비밀을 사용하여 인증서를 추가합니다.
외부 인그레스에서 HTTP 502 오류 발생
외부 인그레스 리소스에서 HTTP 502 오류를 문제 해결하려면 다음 안내를 따르세요.
- 인그레스에서 참조되는 각 GKE 서비스와 연관된 각 백엔드 서비스에 대해 로그를 사용 설정합니다.
- 상태 세부정보를 사용하여 HTTP 502 응답의 원인을 식별합니다. 백엔드에서 시작된 HTTP 502 응답을 나타내는 상태 세부정보는 부하 분산기가 아니라 제공 상태의 포드 내에서 문제 해결이 필요합니다.
비관리형 인스턴스 그룹
외부 인그레스에 비관리형 인스턴스 그룹 백엔드가 사용되는 경우 외부 인그레스 리소스에 HTTP 502 오류가 발생할 수 있습니다. 이 문제는 다음 조건 중 모두가 충족될 때 발생합니다.
- 모든 노드 풀 간에 클러스터에 대량의 노드 수가 포함되어 있습니다.
- 인그레스에서 참조되는 하나 이상의 서비스에 대한 제공 상태의 포드가 단 몇 개의 노드에만 있습니다.
- 인그레스에서 참조되는 서비스에
externalTrafficPolicy: Local이 사용됩니다.
외부 인그레스에 비관리형 인스턴스 그룹 백엔드가 사용되는지 확인하려면 다음을 수행합니다.
Google Cloud 콘솔에서 인그레스 페이지로 이동합니다.
외부 인그레스의 이름을 클릭합니다.
부하 분산기 이름을 클릭합니다. 부하 분산 세부정보 페이지가 표시됩니다.
백엔드 서비스 섹션의 테이블에서 외부 인그레스에 NEG 또는 인스턴스 그룹이 사용되는지 확인합니다.
이 문제를 해결하려면 다음 솔루션 중 하나를 사용하세요.
- VPC 기반 클러스터를 사용합니다.
- 외부 인그레스에서 참조되는 각 서비스에 대해
externalTrafficPolicy: Cluster를 사용합니다. 이 솔루션을 사용하면 패킷 소스에서 원래 클라이언트 IP 주소가 손실됩니다. node.kubernetes.io/exclude-from-external-load-balancers=true주석을 사용합니다. 외부 인그레스에서 참조하는 서비스 또는 클러스터의LoadBalancer서비스에 대해 제공 상태의 포드를 실행하지 않는 노드 또는 노드 풀에 주석을 추가합니다.
부하 분산기 로그를 사용하여 문제 해결
내부 패스 스루 네트워크 부하 분산기 로그 및 외부 패스 스루 네트워크 부하 분산기 로그를 사용하여 부하 분산기 문제를 해결하고 부하 분산기에서 GKE 리소스로 전송되는 트래픽의 상관관계를 파악할 수 있습니다.
로그는 연결별로 집계되고 거의 실시간으로 내보내집니다. 로그는 인그레스 및 이그레스 트래픽 모두에 대해 LoadBalancer 서비스의 데이터 경로와 관련된 각 GKE 노드에 대해 생성됩니다. 로그 항목에는 다음과 같은 GKE 리소스의 추가 필드가 포함됩니다.
- 클러스터 이름
- 클러스터 위치
- 서비스 이름
- 서비스 네임스페이스
- 포드 이름
- 포드 네임스페이스
가격 책정
로그 사용에 대한 추가 요금은 발생하지 않습니다. 로그 수집 방법에 따라 Cloud Logging, BigQuery, Pub/Sub의 표준 가격이 적용됩니다. 로그를 사용 설정해도 부하 분산기의 성능은 영향을 받지 않습니다.
진단 도구를 사용하여 문제 해결
check-gke-ingress 진단 도구는 인그레스 리소스에 일반적인 구성 오류가 있는지 검사합니다. 다음과 같은 방법으로 check-gke-ingress 도구를 사용할 수 있습니다.
- 클러스터에서
gcpdiag명령줄 도구를 실행합니다. 인그레스 결과가 확인 규칙gke/ERR/2023_004섹션에 표시됩니다. - check-gke-ingress의 안내에 따라
check-gke-ingress도구를 단독으로 사용하거나 kubectl 플러그인으로 사용합니다.
다음 단계
문서에서 문제 해결 방법을 찾을 수 없으면 지원 받기를 참조하여 다음 주제에 대한 조언을 포함한 추가 도움을 요청하세요.
- Cloud Customer Care에 문의하여 지원 케이스를 엽니다.
- StackOverflow에서 질문하고
google-kubernetes-engine태그를 사용하여 유사한 문제를 검색해 커뮤니티의 지원을 받습니다.#kubernetes-engineSlack 채널에 가입하여 더 많은 커뮤니티 지원을 받을 수도 있습니다. - 공개 Issue Tracker를 사용하여 버그나 기능 요청을 엽니다.