本頁說明如何將 GKE Inference Gateway 設定從搶先版 v1alpha2 API 遷移至正式版 v1 API。
本文適用於使用 v1alpha2 版 GKE Inference Gateway 的平台管理員和網路專家,他們想升級至 v1 版,以便使用最新功能。
開始遷移前,請務必熟悉 GKE Inference Gateway 的概念和部署作業。建議您參閱「部署 GKE 推論閘道」。
事前準備
開始遷移前,請先判斷是否需要按照本指南操作。
檢查現有的 v1alpha2 API
如要檢查是否使用 v1alpha2 GKE Inference Gateway API,請執行下列指令:
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
這些指令的輸出內容會決定是否需要遷移:
- 如果任一指令傳回一或多個
InferencePool或InferenceModel資源,表示您使用的是v1alpha2API,請按照本指南操作。 - 如果這兩個指令都傳回
No resources found,表示您並未使用v1alpha2API。您可以繼續重新安裝v1GKE 推論閘道。
遷移路徑
從 v1alpha2 遷移至 v1 的方式有兩種:
- 簡單遷移 (會停機):這個路徑較快且簡單,但會導致短暫停機。如果您不需要零停機時間遷移,建議採用這個方法。
- 零停機時間遷移:如果使用者無法承受任何服務中斷,請選擇這個路徑。也就是同時執行
v1alpha2和v1堆疊,並逐步轉移流量。
簡易遷移 (會停機)
本節說明如何執行簡單的遷移作業 (會造成停機)。
刪除現有
v1alpha2資源:如要刪除v1alpha2資源,請選擇下列其中一個選項:方法 1:使用 Helm 解除安裝
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAME選項 2:手動刪除資源
如果您未使用 Helm,請手動刪除與
v1alpha2部署作業相關聯的所有資源:- 更新或刪除
HTTPRoute,移除指向v1alpha2InferencePool的backendRef。 - 刪除
v1alpha2InferencePool、指向該資源的任何InferenceModel資源,以及對應的端點選擇器 (EPP) 部署作業和服務。
刪除所有
v1alpha2自訂資源後,請從叢集中移除自訂資源定義 (CRD):kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- 更新或刪除
安裝 v1 資源:清除舊資源後,請安裝
v1GKE Inference Gateway。這項程序包括:- 安裝新的
v1自訂資源定義 (CRD)。 - 建立新的
v1InferencePool和對應的InferenceObjective資源。InferenceObjective資源仍定義於v1alpha2API 中。 - 建立新的
HTTPRoute,將流量導向新的v1InferencePool。
- 安裝新的
驗證部署作業:幾分鐘後,確認新的
v1堆疊是否正確提供流量。確認閘道狀態為
PROGRAMMED:kubectl get gateway -o wide輸出內容應與以下所示相似:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m傳送要求來驗證端點:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'請確認您收到
200回應代碼,且回應成功。
完全不必停機的遷移作業
這項遷移路徑適用於無法承受任何服務中斷的使用者。下圖說明 GKE Inference Gateway 如何協助提供多個生成式 AI 模型,這是零停機時間遷移策略的關鍵要素。
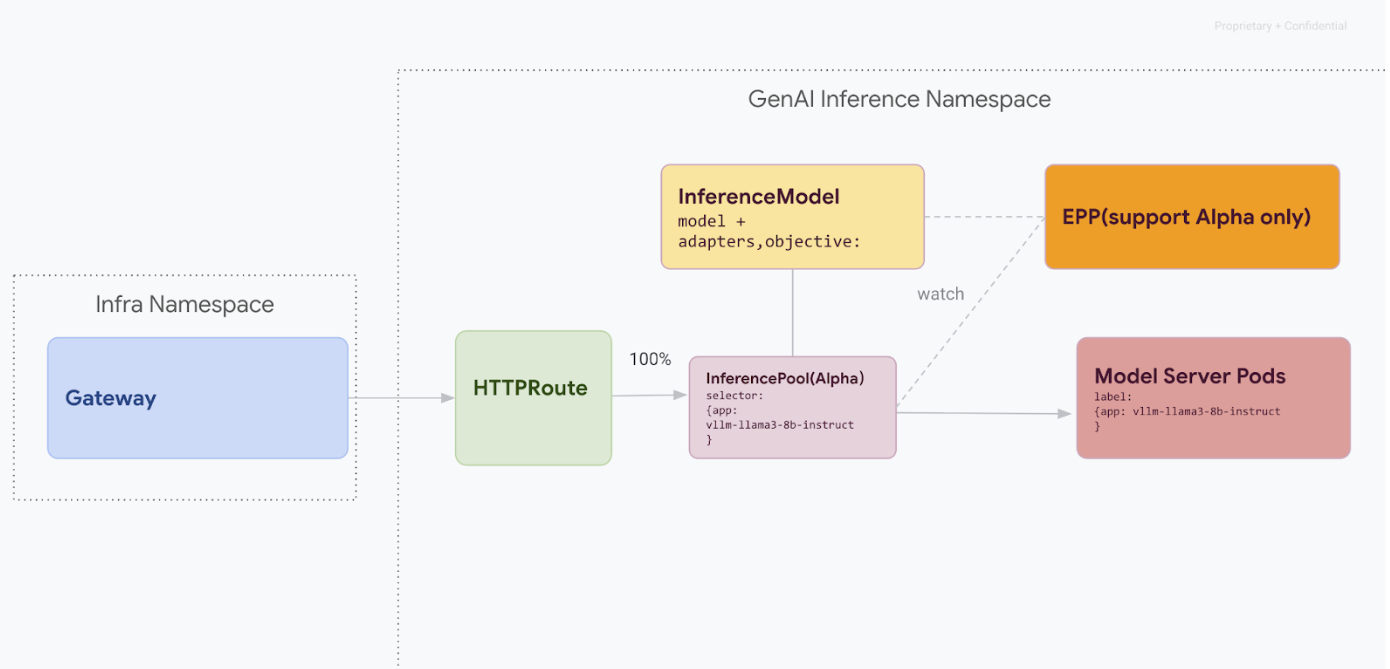
使用 kubectl 區分 API 版本
在零停機時間遷移期間,v1alpha2 和 v1 CRD 都會安裝在叢集上。使用 kubectl 查詢 InferencePool 資源時,可能會造成模稜兩可的情況。為確保您與正確版本互動,請務必使用完整資源名稱:
針對
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.io針對
v1:kubectl get inferencepools.inference.networking.k8s.io
v1 API 也提供方便的簡短名稱 infpool,可用於查詢 v1 資源:
kubectl get infpool
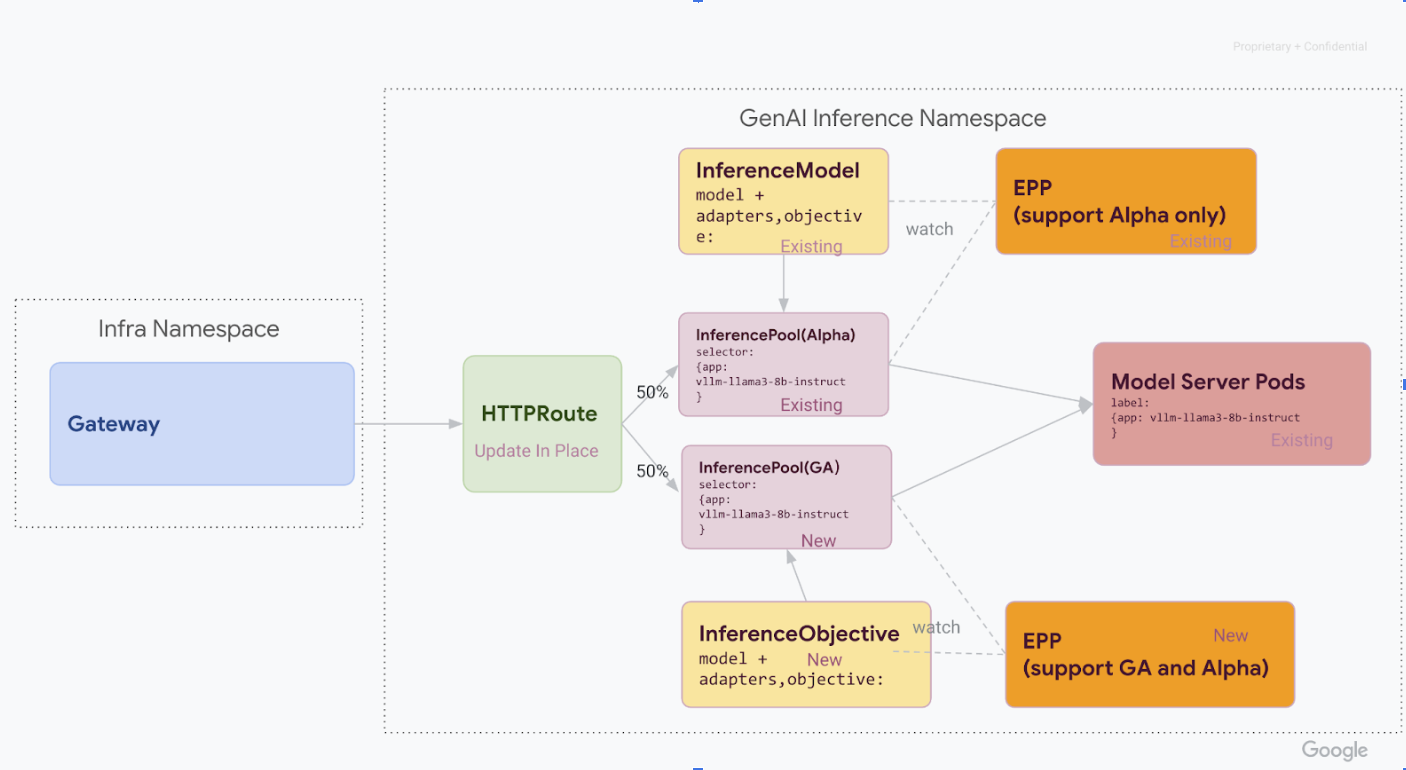
第 1 階段:並行部署 v1
在這個階段,您會將新的 v1 InferencePool 堆疊部署到現有的 v1alpha2 堆疊旁,以便安全地逐步遷移。
完成這個階段的所有步驟後,您會擁有下圖所示的基礎架構:
在 GKE 叢集中安裝必要的自訂資源定義 (CRD):
- 如果是
1.34.0-gke.1626000之前的 GKE 版本,請執行下列指令,同時安裝 v1InferencePool和 Alpha 版InferenceObjectiveCRD:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- 如果是
1.34.0-gke.1626000以上版本的 GKE,請只安裝 Alpha 版InferenceObjectiveCRD,方法是執行下列指令:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- 如果是
安裝
v1 InferencePool。使用 Helm 安裝具有不同發布名稱的新
v1 InferencePool,例如vllm-llama3-8b-instruct-ga。InferencePool必須使用inferencePool.modelServers.matchLabels.app,以與 Alpha 版InferencePool相同的 Model Server Pod 為目標。如要安裝
InferencePool,請使用下列指令:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool建立
v1alpha2 InferenceObjective資源。遷移至 Gateway API Inference Extension 的 v1.0 版本時,我們也需要從 Alpha 版
InferenceModelAPI 遷移至新的InferenceObjectiveAPI。套用下列 YAML 來建立
InferenceObjective資源:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
階段 2:轉移流量
兩個堆疊都執行後,您就可以更新 HTTPRoute 來拆分流量,開始將流量從 v1alpha2 轉移至 v1。這個範例顯示 50/50 的分配比例。
更新 HTTPRoute 以拆分流量。
如要更新流量分配的
HTTPRoute,請執行下列指令:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOF驗證及監控。
套用變更後,請監控新
v1堆疊的效能和穩定性。確認inference-gateway閘道的PROGRAMMED狀態為TRUE。
第 3 階段:完成及清理
確認 v1 InferencePool 穩定後,即可將所有流量導向該資源,並停用舊的 v1alpha2 資源。
將 100% 的流量轉移至
v1 InferencePool。如要將 100% 的流量轉移至
v1 InferencePool,請執行下列指令:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOF完成最終驗證。
將所有流量導向
v1堆疊後,請確認堆疊是否能如預期處理所有流量。確認閘道狀態為
PROGRAMMED:kubectl get gateway -o wide輸出內容應與以下所示相似:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m傳送要求來驗證端點:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'請確認您收到
200回應代碼,且回應成功。
清除 v1alpha2 資源。
確認
v1堆疊完全正常運作後,請安全地移除舊的v1alpha2資源。檢查剩餘的
v1alpha2資源。現在您已遷移至
v1InferencePoolAPI,可以放心刪除舊版 CRD。檢查現有的 v1alpha2 API,確保您不再使用任何v1alpha2資源。如果還有一些資料尚未遷移,可以繼續遷移。刪除 CRD。
v1alpha2刪除所有
v1alpha2自訂資源後,請從叢集中移除自訂資源定義 (CRD):kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml完成所有步驟後,基礎架構應如下圖所示:
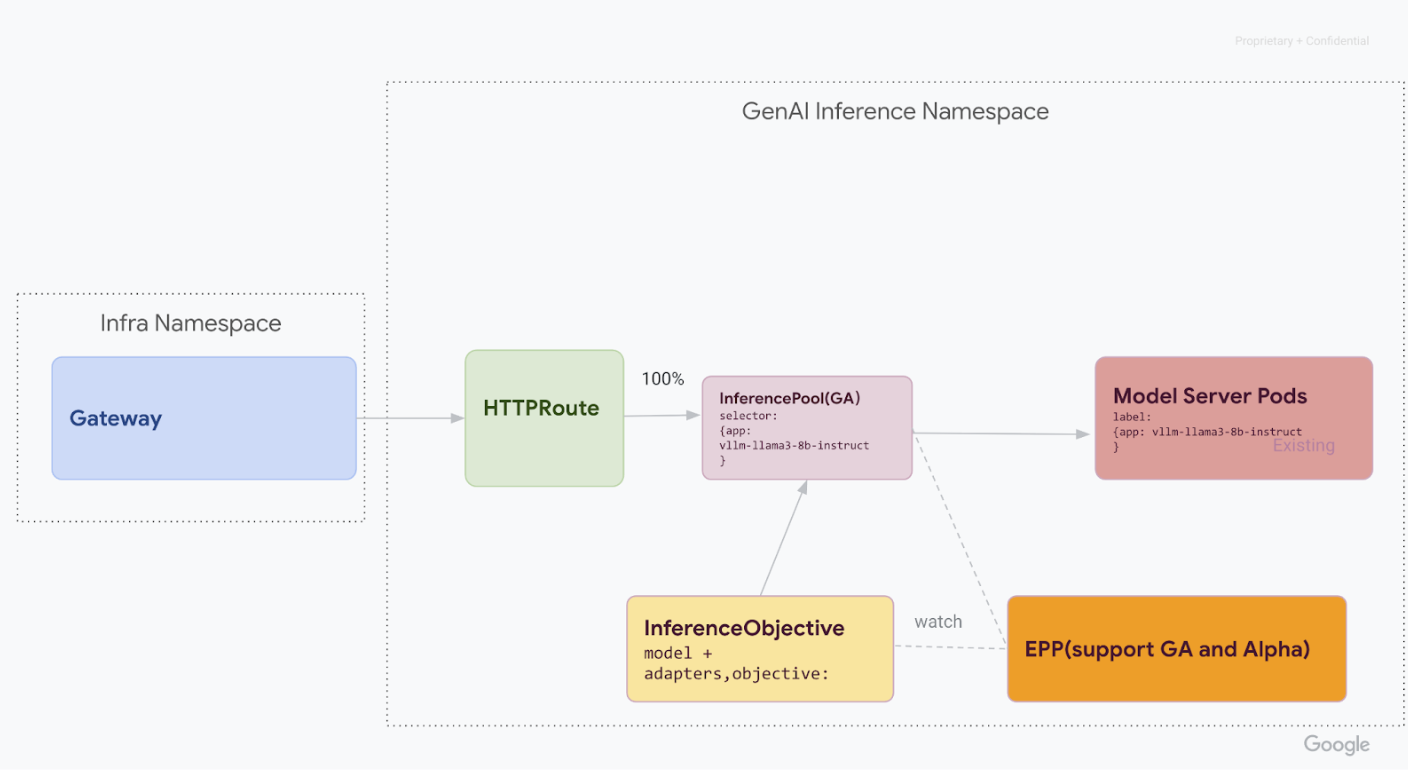
圖: GKE Inference Gateway 會根據模型名稱和優先順序,將要求轉送至不同的生成式 AI 模型
後續步驟
- 進一步瞭解如何部署 GKE Inference Gateway。
- 探索其他 GKE 網路功能。