本页面介绍如何将 GKE 推理网关设置从预览版 v1alpha2 API 迁移到正式版 v1 API。
本文档适用于使用 v1alpha2 版 GKE 推理网关并希望升级到 v1 版以使用最新功能的平台管理员和网络专家。
在开始迁移之前,请确保您熟悉 GKE 推理网关的概念和部署。我们建议您查看部署 GKE 推理网关。
准备工作
在开始迁移之前,请确定您是否需要遵循本指南。
检查是否存在 v1alpha2 API
如需检查您是否在使用 v1alpha2 GKE 推理网关 API,请运行以下命令:
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
这些命令的输出结果可确定您是否需要迁移:
- 如果任一命令返回一个或多个
InferencePool或InferenceModel资源,则表示您使用的是v1alpha2API,且必须遵循本指南。 - 如果这两个命令都返回
No resources found,则表示您未使用v1alpha2API。您可以继续安装全新的v1GKE 推理网关。
迁移途径
从 v1alpha2 迁移到 v1 的途径有两种:
- 简单迁移(包含停机时间):此迁移途径更快、更简单,但会产生短暂的停机时间。如果您不需要零停机时间迁移,建议采用此方法。
- 零停机时间迁移:此途径适用于无法承受任何服务中断的用户。这种方法涉及并排运行
v1alpha2和v1堆栈,并逐步转移流量。
简单迁移(包含停机时间)
本部分介绍如何执行包含停机时间的简单迁移。
删除现有
v1alpha2资源:如需删除v1alpha2资源,请选择以下其中一种方法:方法 1:使用 Helm 卸载
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAME方法 2:手动删除资源
如果您未使用 Helm,请手动删除与
v1alpha2部署关联的所有资源:- 更新或删除
HTTPRoute以移除指向v1alpha2InferencePool的backendRef。 - 删除
v1alpha2InferencePool、指向它的所有InferenceModel资源,以及相应的端点选择器 (EPP) 部署和服务。
删除所有
v1alpha2自定义资源后,从集群中移除自定义资源定义 (CRD):kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- 更新或删除
安装 v1 资源:清理旧资源后,安装
v1GKE 推理网关。此过程包括以下内容:- 安装新的
v1自定义资源定义 (CRD)。 - 创建新的
v1InferencePool和相应的InferenceObjective资源。InferenceObjective资源仍在v1alpha2API 中定义。 - 创建新的
HTTPRoute,将流量定向到新的v1InferencePool。
- 安装新的
验证部署:几分钟后,验证新的
v1堆栈是否在正确处理流量。确认网关状态为
PROGRAMMED:kubectl get gateway -o wide输出应类似于以下内容:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m通过发送请求来验证端点:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'确保您收到包含
200响应代码的成功响应。
零停机时间迁移
此迁移途径专门面向无法承受任何服务中断的用户。下图展示了 GKE 推理网关如何帮助部署多个生成式 AI 模型,这是零停机时间迁移策略的关键方面。
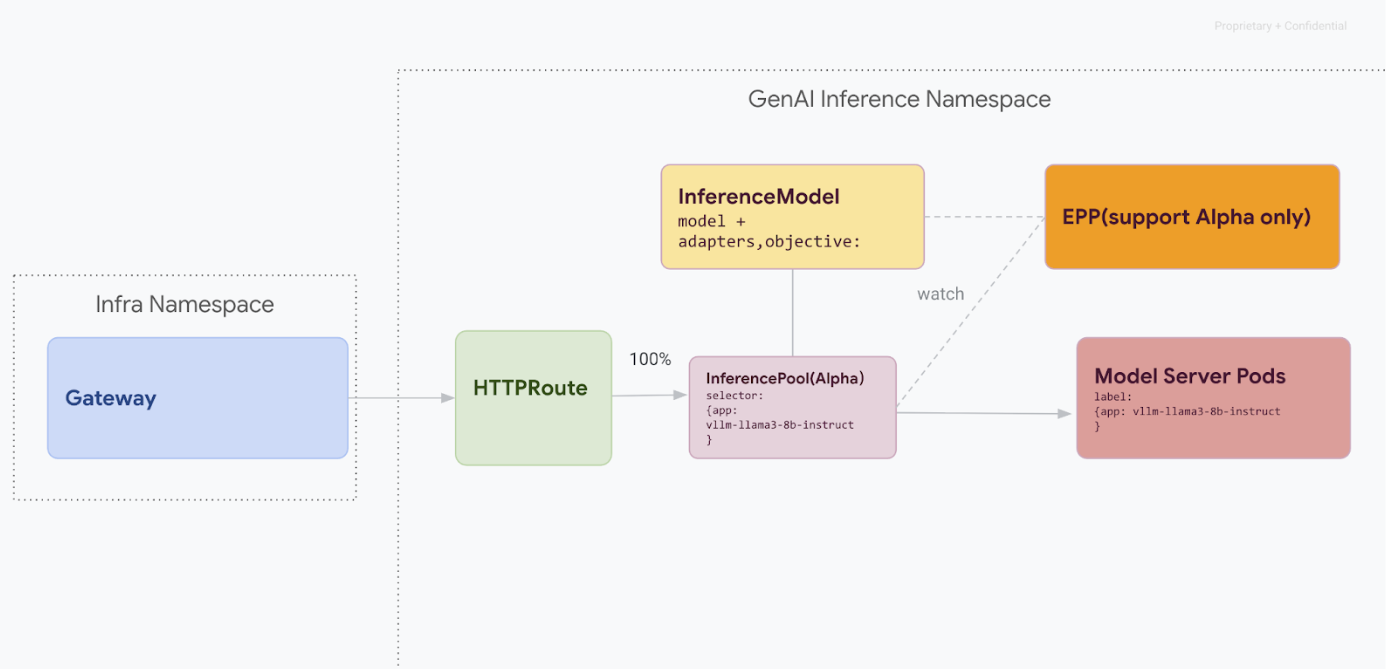
使用 kubectl 区分 API 版本
在零停机时间迁移期间,v1alpha2 和 v1 CRD 都会安装在您的集群中。使用 kubectl 查询 InferencePool 资源时,这可能会引起歧义。为确保您与正确的版本交互,您必须使用完整资源名称:
对于
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.io对于
v1:kubectl get inferencepools.inference.networking.k8s.io
v1 API 还提供了一个便捷的简称 (infpool),您可以使用该名称专门查询 v1 资源:
kubectl get infpool
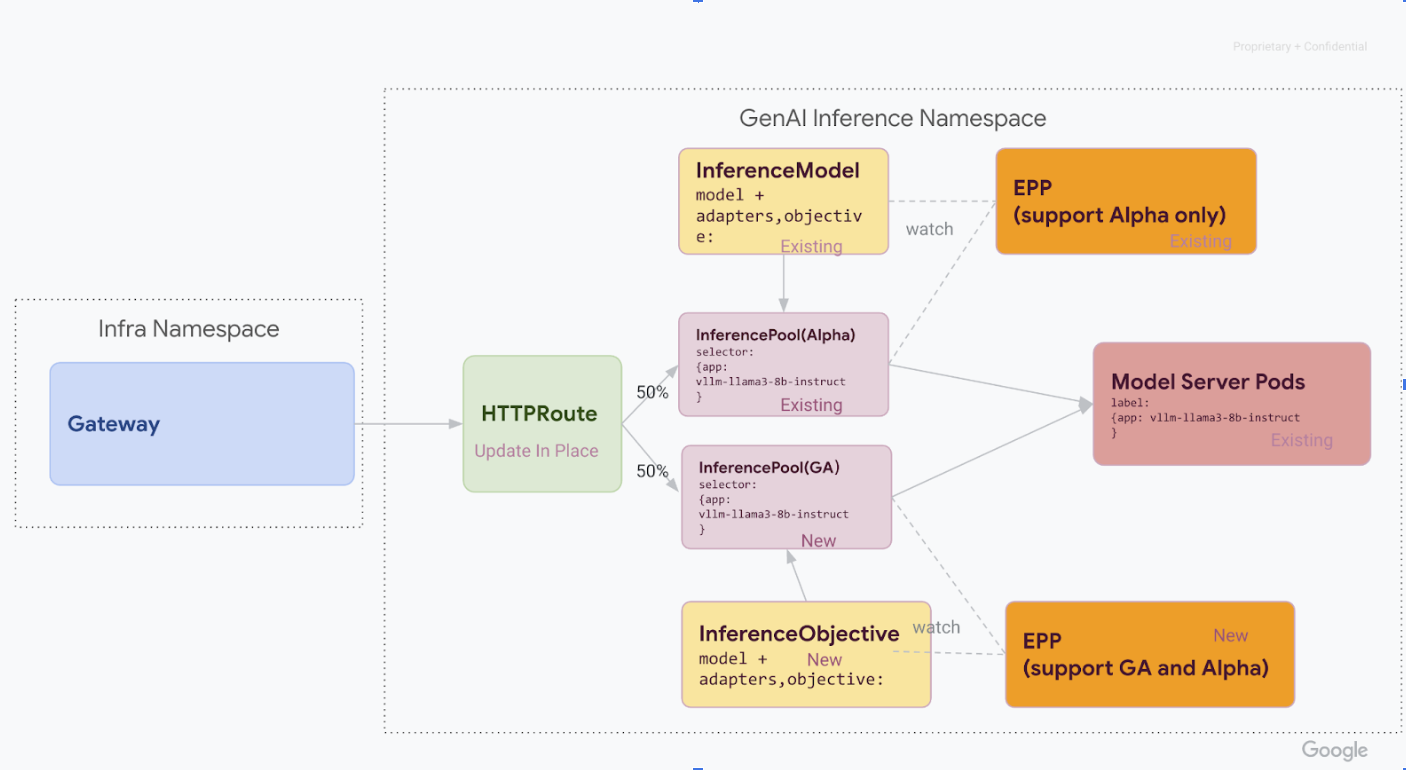
第 1 阶段:并排部署 v1
在此阶段,您将部署新的 v1 InferencePool 堆栈,同时保留现有的 v1alpha2 堆栈,实现安全、渐进的迁移。
完成此阶段中的所有步骤后,您将拥有下图中的基础设施:
在 GKE 集群中安装所需的自定义资源定义 (CRD):
- 对于
1.34.0-gke.1626000版之前的 GKE 版本,请运行以下命令来安装 v1InferencePool和 Alpha 版InferenceObjectiveCRD:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- 对于 GKE
1.34.0-gke.1626000版或更高版本,仅需安装 Alpha 版InferenceObjectiveCRD,方法是运行以下命令:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- 对于
安装
v1 InferencePool。使用 Helm 安装新的
v1 InferencePool,其版本名称应不同,例如vllm-llama3-8b-instruct-ga。InferencePool必须使用inferencePool.modelServers.matchLabels.app将目标指向与 Alpha 版InferencePool相同的模型服务器 Pod。如需安装
InferencePool,请使用以下命令:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool创建
v1alpha2 InferenceObjective资源。在迁移到 Gateway API 推理扩展程序的 v1.0 版本这一过程中,我们还需要从 Alpha 版
InferenceModelAPI 迁移到新的InferenceObjectiveAPI。应用以下 YAML 以创建
InferenceObjective资源:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
第 2 阶段:流量转移
在两个堆栈都运行的情况下,您可以通过更新 HTTPRoute 来分配流量,从而开始将流量从 v1alpha2 转移到 v1。此示例展示了 50-50 这一比例的分配情况。
更新 HTTPRoute 以进行流量分配。
如需更新
HTTPRoute以进行流量分配,请运行以下命令:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOF验证和监控。
应用更改后,监控新
v1堆栈的性能和稳定性。验证inference-gateway网关的PROGRAMMED状态是否为TRUE。
第 3 阶段:收尾工作和清理
确认 v1 InferencePool 处于稳定状态后,您可以将所有流量定向到该资源,并停用旧的 v1alpha2 资源。
将全部流量转移到
v1 InferencePool。如需将全部流量都转移到
v1 InferencePool,请运行以下命令:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOF执行最终验证。
将所有流量定向到
v1堆栈后,验证该堆栈是否按预期处理所有流量。确认网关状态为
PROGRAMMED:kubectl get gateway -o wide输出应类似于以下内容:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m通过发送请求来验证端点:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'确保您收到包含
200响应代码的成功响应。
清理 v1alpha2 资源。
确认
v1堆栈完全正常运转后,安全地移除旧的v1alpha2资源。检查是否还有剩余的
v1alpha2资源。现在,您已迁移到
v1InferencePoolAPI,可以安全地删除旧的 CRD。检查是否存在 v1alpha2 API,确保您不再使用任何v1alpha2资源。如果您仍有部分内容未迁移,可以继续对其执行迁移流程。删除
v1alpha2CRD。删除所有
v1alpha2自定义资源后,从集群中移除自定义资源定义 (CRD):kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml完成所有步骤后,您的基础设施应类似于下图:
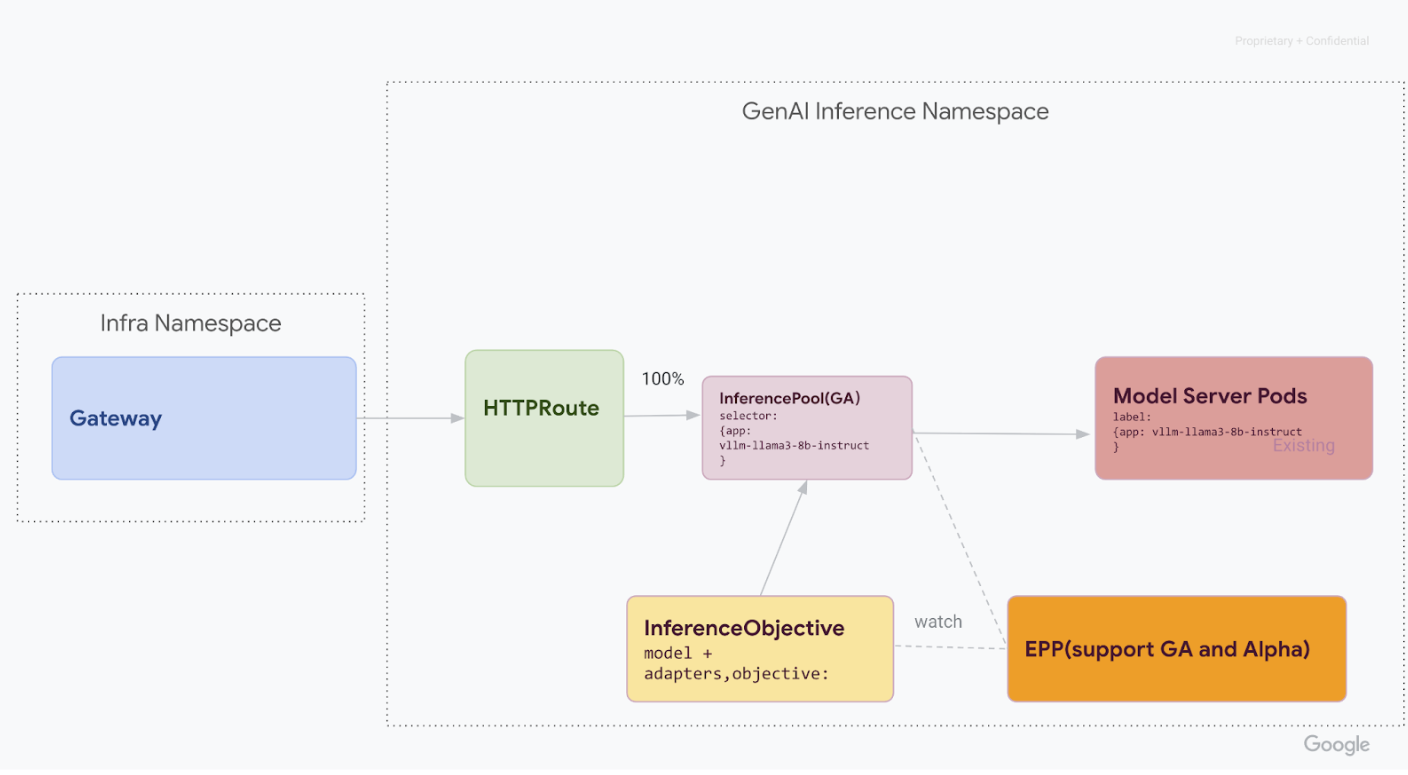
图:GKE 推理网关根据模型名称和优先级将请求路由到不同的生成式 AI 模型
后续步骤
- 详细了解如何部署 GKE 推理网关。
- 探索其他 GKE 网络功能。